
elastic B!
Let's say...
What we did, and how, to elasticize our backend.
Developers prefer tutorials more then documentation.
So, here is our experience.
What I need to know?
- [unzip|tar]
- reading english documentation
- writing JSON documents
- [curl|*generic-http-client]
What is elasticsearch?
distributed RESTful search and analytics
What is it, essentially?
a search engine and NoSQL database
Already installed...and now?
- start the daemon
- PUT some JSONs
- POST -or GET- some queries
- enjoy the results
Non-tech people?
This is the end.
A document of ours (part of it) *
{
"updated_date": "2013/05/02 12:05:56",
"publisher": "Glu",
"supplier_id": "alfresco",
"language_list": [
"it"
],
"country_list": [
"it"
],
"customer_id_list": [
"it_playplanet"
],
"born_date": "2012/02/01 15:02:46",
"meta_it_playplanet": {
"updated_date": "2013/05/02 12:05:56",
"category_id_list": [
"dedafd538d9d7cc8a8f3c340b6256109"
]
},
"source_id": "alfresco_AA990000415",
"inserted_date": "2013/05/10 12:05:58"
}
(*) this is what ES stores
Flattened version *
{
"updated_date": "2013/05/02 12:05:56",
"publisher": "Glu",
"supplier_id": "alfresco",
"language_list": [
"it"
],
"country_list": [
"it"
],
"customer_id_list": [
"it_playplanet"
],
"born_date": "2012/02/01 15:02:46",
"meta_it_playplanet.updated_date": "2013/05/02 12:05:56",
"meta_it_playplanet.category_id_list": [
"dedafd538d9d7cc8a8f3c340b6256109"
],
"source_id": "alfresco_AA990000415",
"inserted_date": "2013/05/10 12:05:58"
}
(*) this is what ES really indexes
Core Types
JSON itself already provides us with some typing, with its support for string, integer/long, float/double, boolean, and null.
{
"tweet" {
"user" : "kimchy"
"message" : "This is a tweet!",
"postDate" : "2009-11-15T14:12:12",
"priority" : 4,
"rank" : 12.3
}
}
Explicit mapping for the above JSON tweet can be:
{
"tweet" : {
"properties" : {
"user" : {"type" : "string", "index" : "not_analyzed"},
"message" : {"type" : "string", "null_value" : "na"},
"postDate" : {"type" : "date"},
"priority" : {"type" : "integer"},
"rank" : {"type" : "float"}
}
}
}
Advanced Types
It also supports arrays, objects and nested ones, dates, IP addresses, GEO points and shapes...even binary attachments *!
(*) binary is considered a core type
Default mapping
ES knows how to manage different types with the default mapping. For dates and numbers you'll probably won't add any custom mapping.
Except for strings.
Strings analysis
If you are still here, you probably need to understand what is an analyzer and why we need it.
Analyze API
$ curl -XGET '192.168.124.176:9200/_analyze?analyzer=standard' -d "Luke Skywalker: I want to come with you to Alderaan."
{"tokens":[{"token":"luke","start_offset":0,"end_offset":4,"type":"<ALPHANUM>","position":1},{"token":"skywalker","start_offset":5,"end_offset":14,"type":"<ALPHANUM>","position":2},{"token":"i","start_offset":16,"end_offset":17,"type":"<ALPHANUM>","position":3},{"token":"want","start_offset":18,"end_offset":22,"type":"<ALPHANUM>","position":4},{"token":"come","start_offset":26,"end_offset":30,"type":"<ALPHANUM>","position":6},{"token":"you","start_offset":36,"end_offset":39,"type":"<ALPHANUM>","position":8},{"token":"alderaan","start_offset":43,"end_offset":51,"type":"<ALPHANUM>","position":10}]}
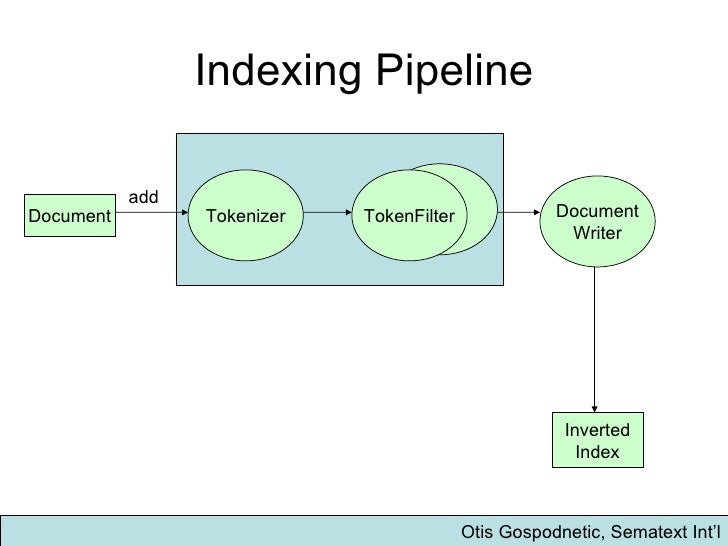
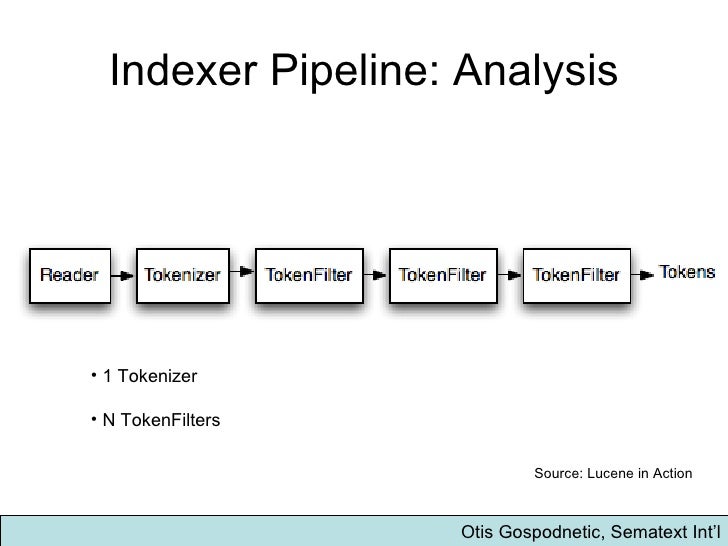

Our mappings
{
"content": {
"dynamic_templates": [
{
"metadata_title": {
"mapping": {
"index_analyzer": "str_index_analyzer",
"search_analyzer": "str_search_analyzer"
},
"path_match": "meta_*.*.title"
}
},
{
"metadata_description": {
"mapping": {
"index_analyzer": "str_index_analyzer",
"search_analyzer": "str_search_analyzer"
},
"path_match": "meta_*.*.description"
}
}
],
[...] // auto-generated mappings
}Our analyzers
index:
analysis:
analyzer:
default:
tokenizer: keyword
filter: [ ]
str_search_analyzer:
type: custom
tokenizer: longstandard
filter: [ standard, asciifolding, lowercase ]
str_index_analyzer:
type: custom
tokenizer: longstandard
filter: [ standard, asciifolding, lowercase, substring ]
filter:
substring:
type: edgeNGram
min_gram: 3
max_gram: 20
tokenizer :
longstandard:
type : standard
max_token_length: 1023
stop: []Our full-text query
query = {
'bool': {
'should': [
{ 'term' : { title: q }, },
{ 'prefix' : { title : q }, },
{ 'fuzzy' : { title: q }, },
{ 'query_string': {'fields':
['%s^5' % title, description],
'query': q, 'minimum_should_match': '30%', 'use_dis_max': False, 'default_operator': 'OR' } },
{ 'term' : { publisher: q }, },
{ 'prefix' : { publisher : q }, },
{ 'fuzzy' : { publisher: q }, },
],
'must': [
{ 'term' : { 'customer_id_list' : customer_id }, },
],
'minimum_number_should_match' : 1,
}
}