Choose Your Own Adventure for client web services
With
Dave Anderson
@dvndrsn



before the adventure
A little bit about me
PROLOGUE TO THE ADVENTURE
What to expect on your journey...






Choose GraphQL or REST
Review examples
Advanced Considerations
Chapter 1
API Architecture and Design
You are a developer.
If you choose a REST, advance to the next section.





One things is for sure: you need a robust API.
What do you choose?
If you choose GraphQL, advance to the following section.
Choose Rest
Architecture and Design
You choose to build your API using REST web service architecture.

Choosing REST is a familiar design decision.
Choose Rest
Architecture and Design
You use HTTP verbs semantically to describe operations on your resources
GET /api/v1/stories/
POST /api/v1/stories/
GET /api/v1/stories/{id}/
PUT /api/v1/stories/{id}/
DELETE /api/v1/stories/{id}/Choose Rest
Architecture and Design
You build many different endpoints, for each resource.
GET, POST /api/v1/stories/
GET, PATCH, DELETE /api/v1/stories/{id}/
GET, POST /api/v1/stories/{id}/passages/
GET, PATCH, DELETE /api/v1/stories/{id}/passages/{id}/
GET, POST /api/v1/stories/{id}/passages/{id}/choices/
GET, PATCH, DELETE /api/v1/stories/{id}/passages/{id}/choices/{id}/Choose Rest
Architecture and Design
You choose how to structure your response.
// Hypermedia as the Engine of the Application State
// HATEAOS
// GET api/v1/stories/
{
"id": 1,
"title": "REST",
"author": "Dave A.",
"description": "Can have many response structures",
"links": [
{
"href": "1/passages/",
"type": "GET",
"rel": "passages
},
// ... etc
]
}Choose Rest
Architecture and Design
You receive many requests to add new fields to the API.
..but now some clients are fetching fields that they don't need.
You want to deprecate old fields or refactor the structure of the API by introducing a new set of versioned endpoints.
..but now you're supporting multiple versions of each API resource forever.
Choose Rest
Architecture and Design
You are attacked by a sea monster with as many arms as your API has endpoints and versions.
You die.
Wait, wait, wait.. let's skip back and choose GraphQL.


Choose GraphQL
Architecture and Design
GraphQL is a query language for your API.
It allows clients
to ask questions of your server
and only get the data they need
in a single request.

Choose GraphQL
Architecture and Design
You define a schema...
type Story {
id: ID,
title: String,
author: String,
passages: [Passage]
}
type Passage {
id: ID,
name: String,
description: String,
is_ending: Boolean,
choices: [Choice]
}
type Choice {
id: ID,
description: String,
toPassage: Passage
}
type Query {
story(id: ID): Story
}Choose GraphQL
Architecture and Design
Then you write queries against that schema..
query myStory {
story(id:1) {
id
title
passages {
id
name
description
}
}
}Choose GraphQL
Architecture and Design
And you get a JSON response.
{
"story": {
"id": "1",
"title": "Choose Your Own Adventure with GraphQL",
passages: [
{
"id": "1",
"name": "Beginning",
description: "Your adventure begins",
},
{
"id": "2",
"name": "GraphQL Architecture",
description: "Choose GraphQL!",
},
// ...
]
}
}Choose GraphQL
Architecture and Design
If you need to change data, write a mutation!
mutation newStory {
createStory (input: {
title: "GraphQL",
author: "Dave A",
description: "Its pretty cool"
}) {
story{
id
title
description
author
}
}
}Choose GraphQL
Architecture and Design
Open sourced by Facebook in 2015.
Since open sourcing, we now have a lot of choice!
Which platform do you choose?
If you choose a Python, advance to the next section.
Seriously, choose Python, advance to the next section.

Choose Python + Graphene
Architecture and Design
You choose to use the Graphene framework in Python.

Choose Python + Graphene
Architecture and Design
Graphene Django provides some nice built in Views to handle parsing GraphQL requests.
urlpatterns = [
...
path(
'graphql/',
GraphQLView.as_view(schema=schema,graphiql=True)
),
...
]
Choose Python + Graphene
Architecture and Design
You write your schema.
class StoryType(graphene.ObjectType):
class Meta:
interfaces = (graphene.Node, )
title = graphene.String()
description = graphene.String()
author = graphene.String()
passages = graphene.List(PassageType)
...
class Query(graphene.ObjectType):
story = graphene.Node.Field(StoryType)
...
schema = graphene.Schema(query=Query)query myStory {
story(id:1) {
id
title
passages {
id
name
description
}
}
}Choose Python + Graphene
Architecture and Design
You write resolvers for each of the fields.
class StoryType(graphene.ObjectType):
...
def resolve_title(self, info, **args):
return self.title
...
class Query(graphene.ObjectType):
...
def resolve_story(self, info, **args):
id = args.get("id")
return Story.objects.get(id=id)
...query myStory {
story(id:1) {
id
title
passages {
id
name
description
}
}
}Choose Python + Graphene
Architecture and Design
You write mutations for any requests that result in changes to data.
class StoryInput(graphene.InputObjectType):
title = graphene.String(required=True)
description = graphene.String()
author = graphene.String()
class CreateStory(graphene.Mutation):
class Arguments:
input = StoryInput(required=True)
story = graphene.Field(StoryType)
@classmethod
def mutate_and_get_payload(cls, root, info, **input):
story = Story.objects.create(*input)
return cls(story=story)
class Mutation(grapene.ObjecctType):
create_story = graphene.Field(CreateStory)
...
schema = graphene.Schema(
query=Query,
mutation=Mutation
)mutation newStory {
createStory (input: {
title: "GraphQL",
author: "Dave A",
description: "Its pretty cool"
}) {
story{
id
title
description
author
}
}
}Choose Python + Graphene
Architecture and Design
You add new fields easily.
Advance to the next section to go for a space jog.

You signal for fields to be depreciated with annotations on your schema.
You modify existing fields without worrying about breaking clients.
Chapter 2
Scaling and Performance
Performance tuning can be more challenging with GraphQL.
If you choose to prefetch data, advance to the next section.
If you choose dig into other methods, advance to the following section.

StackOverflow posts are scarce in the depths of space..
Unlike REST, it is not generally possible to do HTTP level request caching.
What will be your approach?
Choose PREFETCHING DATA
Scaling and Performance
As a Django developer, prefetching data feels like the natural first step...

But it can be hard to decide
where to optimize the query...
Choose PREFETCHING
Scaling and Performance
What does an N+1 GraphQL query look like?
Stories
Story 1 passages
Story 2 -author, passages, etc..
Passage 1 - Choices
Choice 1 - To Passage
Passage 2 - Choices, etc..
Etc..
Time
query allStories {
stories {
id
title
author {
name
}
passages {
id
description
choices {
id
description
toPassage {
id
description
}
}
}
}
}Story 1 author
Choose PREFETCHING DATA
Scaling and Performance
Let's optimize and split the difference between stories and passages..
class StoryType(graphene.ObjectType):
...
def resolve_passages(self, info, **kwargs):
return Passage.objects.filter(story=self.id) \
.prefetch_related('to_choices__to_passage')
...
class Query(graphene.ObjectType):
...
def resolve_story(self, info, **kwargs):
return Story.objects.all() \
.select_related('author')
...query allStories {
stories {
id
title
author {
name
}
passages {
id
description
choices {
id
description
toPassage {
id
description
}
}
}
}
}Choose PREFETCHING
Scaling and Performance
What might our performance look like now?
Stories + author
Story 1 passages +
choices + to passage
Story 2 passages +
choices + to passage
Etc..
Etc..
Time
query allStories {
stories {
id
title
author {
name
}
passages {
id
description
choices {
id
description
toPassage {
id
description
}
}
}
}
}There must be a better way.. let's try to dig deeper.
query allStoriesOverview {
stories {
id
title
passages {
id
description
}
}
}Choose DATALOADERS
Scaling and Performance
Looking more closely, you find that the Facebook-preferred approach is to use DataLoaders.
Graphene provides us with an implementation of both DataLoader and Promise.

Choose DATALOADERS
Scaling and Performance
DataLoaders allow for batching and caching of requested data.
class PassagesFromStoryLoader(DataLoader):
def batch_load_fn(self, story_ids):
return Promise.resolve(self.get_passages(story_ids))
def get_passages(self, story_ids):
passages = Passage.objects \
.filter(story_id__in=story_ids)
lookup = defaultdict(list)
for passage in passages:
lookup[passage.story_id].append(passage)
return [lookup[story_id] for story_id in story_ids]
class StoryType(graphene.ObjectType):
...
def resolve_passages(self, info, **kwargs):
return info.context.passages_from_story_loader \
.load(self.id)
...
Choose DataLoaders
Scaling and Performance
Batching and caching helps scale performance!
Stories
Passages (batched across Stories)
Choices (batched across Passages)
To Passage (batched across choices)
Time
query allStories {
stories {
id
title
author {
name
}
passages {
id
description
choices {
id
description
toPassage {
id
description
}
}
}
}
}Author (cached, batched across Stories)
Choose DataLoaders
Scaling and Performance
DataLoaders add some complexity, but are great for scaling performance through batching and caching.
Let's look at some client side concerns.

Our API is finally performant and humming along.
Chapter 3
Building a client web application
Your API is now built, scaled up and ready to share with the world.
Let's chose to build an application with Apollo and React, advance to the next section.

Now its time to build a rich web client application.
Apollo and Relay are the two most popular JavaScript libraries.
Apollo is a powerful framework that allows you to focus on writing application code.

Choose APOLLO
Building a client web application



const Story = ({ loading, error, data }) => {
if (loading) {
return (<div>Loading the story!</div>)
}
if (error) {
return (<div>There was an error: {error.message}!</div>)
}
return (
<div>
<div>Title: {data.story.title}</div>
<div>Author: {data.story.author}</div>
<div>Description: {data.story.description}</div>
</div>
)
}
const client = new ApolloClient({
uri: 'MY_COOL_GRAPHQL_URL'
});
ReactDOM.render(
<ApolloProvider client={client}>
<StoryWithData storyId={1} />
</ApolloProvider>,
root
)const query = gql`
query myStory ($storyId: String) {
story(id:$storyId) {
id
title
passages {
id
name
description
}
}
}
`
const options = (props) => ({
variables: {
storyId: props.storyId,
}
})
const withStoryData = graphql(query, {
alias: 'withStoryData',
options,
})
const StoryContainer = withStoryData(
Story
)Choose APOLLO
Building a client web application
const withCreateStory = graphql(mutation, {
alias: 'withCreateStory',
props: mapMutationToProps,
})
const StoryFormContainer = connect(
withStoryData,
withCreateStory,
)(StoryForm)
// callback is available in StoryForm component now!
// Pass in values to call the mutation.
const StoryForm = ({ handleCreateStory }) => ({
<button
onClick={() => handleCreateStory(
'Title',
'Author',
'Description',
)}
>
Create a story!
</button>
})const mutation = gql`
mutation newStory ($input: StoryInput) {
createStory (input: $input) {
story{
id
title
description
author
}
}
}
`
const mapMutationToProps = ({ mutate }) => ({
handleCreateStory: (
title,
author,
description
) => {
mutate({
variables: {
input: { title, author, description },
}
// optimisticResponse: ...,
// update: ...,
})
}
})
Choose APOLLO
Building a client web application
You make more efficient requests from your server.
You write less boilerplate code.
You can easily improve perceived performance through caching and optimistic mutations.
Choose APOLLO
Building a client web application

Turn to the next section to find out.
Hopefully there are no bugs lurking around here though..
Choose Apollo
API Design for Client Side Caching
As your single page app grows, you may see more caching bugs..

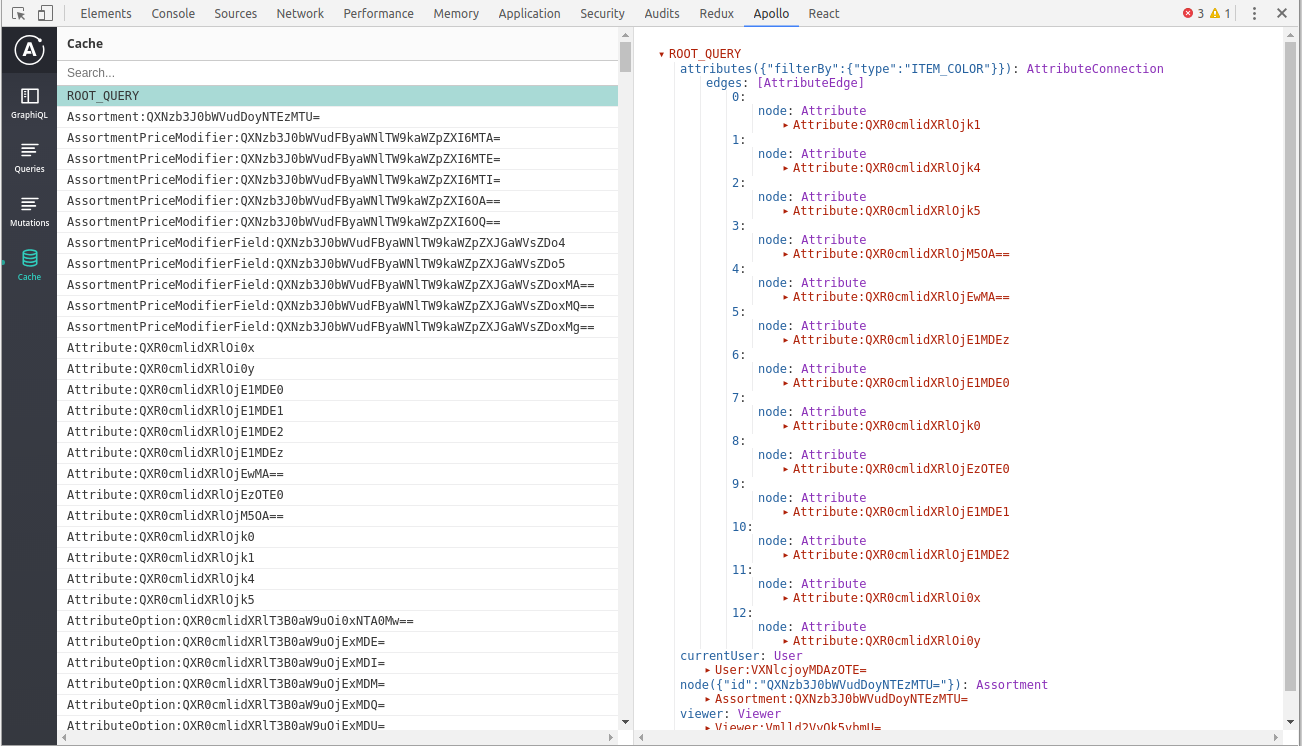
query storiesForAuthor {
author(id: "1") {
id
firstName
lastName
stories {
id
title
}
}
}query listOfAuthors {
authors {
id
firstName
lastName
}
}mutation changeStory {
updateStory(input:{
id:"1",
title: "Update this!"
}) {
story {
id
title
}
}
}Choose Apollo
API Design for Client Side Caching
...we ensure that the cache will be updated properly.
As we add more queries and mutations, If all objects have a globally unique ID...
When removing items from lists...
Choose Apollo
API Design for Client Side Caching
query storiesForAuthors {
author(id: "1") {
id
firstName
lastName
stories {
id
title
}
}
}mutation removeStory {
removeStory(input:{
authorId:"1",
storyId: "6"
}) {
story { # RETURNS REMOVED STORY DATA
id
title
}
}
}...you may not see them properly removed on the page.
<Mutation
mutation={REMOVE_STORY}
update={(cache, { data: { removeStory } }) => {
const { stories } = cache.readQuery({ query: GET_STORIES });
cache.writeQuery({
query: GET_STORIES,
data: {
stories: stories.filter(
(stories) => story.id == removeStory.story.id
) },
});
}}
>
...Choose Apollo
API Design for Client Side Caching
Apollo provides a mechanism for manually upating the cache...
...but this can be hard to reason about and test.
<Mutation
mutation={REMOVE_STORY}
refetchQueries={['allStories']}
>
...Choose Apollo
API Design for Client Side Caching
We could also more simply just refetch any affected queries...
...but as your page grows, it can be hard to maintain a full list of queries and can be expensive to refetch!
query storiesForAuthors {
author(id: "1") {
id
firstName
lastName
stories {
id
title
}
}
}mutation removeStory {
removeStory(input:{
authorId:"1",
storyId:"6"
}) {
story {
id
title
}
author {
id
stories {
id
}
}
}
}Choose Apollo
API Design for Client Side Caching
...the cached list of stories for our author will be updated automatically!
If we design our mutation payload correctly..
query storiesForAuthors {
author(id: "1") {
id
firstName
lastName
stories {
id
title
description
}
}
}mutation addPost {
addPost(input:{
authorId:"1",
title: "Stuff"
}) {
post {
id
title
}
author {
id
stories {
id
}
}
}
}Choose Apollo
API Design for Client Side Caching
When adding to a list with a mutation...
We'll face errors in Apollo due to missing fields in our new post.
query postsForAuthors {
author(id: "1") {
id
firstName
lastName
story {
...allStoryFields
}
}
}
fragment allStoryFields on Story {
id
title
description
}mutation removePost {
addStory(input:{
authorId:"1",
title: "Stuff"
}) {
story {
...allStoryFields
}
author {
id
stories {
id
}
}
}
}Choose Apollo
API Design for Client Side Caching
Fragments can help us ensure that all fields are fetched when adding an item to a list.
The web application with GraphQL and Apollo is really coming together.


Everyone shares some cake and pie in the space break room to celebrate.
Mmm, mm.. Turn to the next section.
Choose APOLLO
Building a client web application
EPILOGUE TO Your Adventure
A parting word before the next adventure
It was long, hard work, but you built a robust web application and API backend.
GraphQL is useful as a general purpose API with productive frameworks for development.
But REST is still a proven and scalable solution.
Next time what will you choose?
Maybe you'll choose to build a REST API...
Or maybe you'll choose to build a flexible API with GraphQL!

The end
Thanks for listening!
Questions?
@dvndrsn
The Rabbit Hole Podcast: http://bit.ly/2Jous2O
Stride Consulting: https://www.stridenyc.com/careers

Dave Anderson
References
Thanks for listening!
Icons8 (open source icons):
Open Clip Art:
Code Sample:
https://github.com/dvndrsn/cyoa-story
Graphene (Python):
http://docs.graphene-python.org/en/latest/
Apollo (JavaScript):