Building Evolutionary API In Python
With
Dave Anderson
@dvndrsn



before the adventure
A little bit about me

before the adventure
A little bit about You






before the adventure
A little bit about You
Meet your neighbor!
- What they're looking to get out of this tutorial
- What they're unfamiliar with, be it Django, testing, git or some other technology
- If there's a way we can help each other to meet our goals.
Introduction
In this tutorial!

What is GraphQL?
-
GraphQL is a query language for your API
-
Specification, implemented in many languages and frameworks.
-
Provides a system of constraints that helps us drive a constantly evolving API.

Introduction
In this tutorial!
Our focus today
-
What is GraphQL and what are its benefits?
-
How do I get started with GraphQL in Python?
-
What does it mean for an API to be Relay-compliant?
- What kinds of changes are safe to make to my API as clients begin consuming it?
- How can I ensure my GraphQL API performs well?
- How should I design mutation responses for my GraphQL API to serve client needs?
- Why GraphQL?
Introduction
Why GraphQL?
Ask for what you need, get exactly that
-
Avoid data over-fetching by clients
-
Easy for clients to express precise field-by-field data requirements, lazily evaluated on the server
-
Encourages concentration of business logic and domain model in API and backend
-
Keep clients lean, focused on presentation of data
-
Easier to pivot or add a new platform in the future

Introduction
One request for all your data needs
-
Avoid N+1 requests for resources in clients
-
Most data can be fetched on page load in one request or catered to specific components or user interactions
-
Single endpoint increases discoverability and avoids versioning more endpoints than a squid has arms

Why GraphQL?
Introduction
Describe what's possible with a type system
-
GraphQL specification requires a schema, every field defined and typed
- Introspection of GraphQL API provide documentation, powerful tooling and a contract with clients
- Clients request the data they want with static queries against a static schema, ensuring a safe contract in dangerous waters

Why GraphQL?
Introduction
Evolve your API without versions
-
GraphQL schema provides a safe guide for evolving over time
-
Confidence in making changes encourages building only what you need now
-
Embrace You-Ain't-Gonna-Need-It
-
Evolve as needs become more
clear -
Provides first class tools for deprecation and controlled changes to APIs

Why GraphQL?
Introduction
GraphQL!
Move faster with powerful developer tools
-
Static schema typing and runtime introspection enables tooling to help you move faster
-
IDE-like editors for rapid prototyping of queries for clients
-
Robust clients manage concerns like caching and asynchronous actions letting you focus on the code that matters

Introduction
GraphQL!
Bring your own data and code
-
Broad support across languages.
-
Python community growing!


Introduction
GraphQL!
Unifying API for any kind of data source
-
Leverage as glue for other data
sources and API -
Backend for frontend for
everything. One size
fits most.

Introduction
Logistics!
Workshop schedule!
- Pomodoro
- 25 minutes on
- 5 minutes off
- Lectures + Exercises
- GraphQL + Graphene basics
- Relay Compliance
- Schema Evolution
- Performance
- Mutations + Client side concerns

Introduction
Logistics!
Principles!
- Pair Programming
- Collaborate and discuss exercises with someone else!
- Coding Practices
- Keep API code simple
- Drive solutions for exercises with tests
- Model our domain in the API and core application code

Introduction
Logistics!
Branch Checkouts!
- Each chapter has at least one branch in the git repo
- We'll start with the branch: chapter-1
- Some chapters have multiple branches
- We'll indicate which branch should be checked out for each exercise!

Project setup - see README.md.
# 0. Install Python (Target 3.6+), `invoke` and git
# 1. Clone repo
$ git clone https://github.com/dvndrsn/graphql-python-tutorial.git
$ cd graphql-python-tutorial
# 2. Checkout Chapter 1
$ git checkout chapter-1
# 3. Setup dependencies (pipenv, graphene, django, etc.) and fixture data (sqlite) using `invoke`
$ pip install invoke
$ invoke setup
# 4. Check setup - lint and test code
$ invoke check
# 5. Start Django Server
$ invoke start
# 6. Open GraphiQL - in your web browser
$ xdg-open http://localhost:8000/graphql
Introduction
Logistics!
Introduction
Dependencies and References!
Version control
# checkout a chapter branch
$ git checkout chapter-1
# save work in progress
$ git add .
$ git commit -m 'my cool commit message here'
# If you get into a state where things seem too hard to correct ...
# get rid of work in progress
$ git reset --hard
# git rid of work in progress and reset chapter the original state
$ git reset --hard origin/HEAD
# stash work in progress (temporary save)
$ git stash
# apply last stash
$ git stash popIntroduction
Dependencies and References!
Python environment
# Most of our build commands use `pipenv run` to execute in the context
# of the active virtual environment.
# install dependencies
$ pipenv install
# "activate" virtual environment in terminal shell
$ pipenv shell
# "deactive" virtual environment in terminal shell
(graphql-python-tutorial) $ exit
# Run a predefined scripts in virtual environment
$ pipenv run setup
# OR
$ pipenv run <script> # See Pipfile [scripts] for more.Introduction
Dependencies and References!
Task Runner & Build scripts
# list of build commands
$ invoke -l
# check style, types and tests
$ invoke check
# just run the tests
$ invoke test
# OR
$ pipenv run test
# run the django web server
$ make start
# OR
$ pipenv run start
# run a django shell to play with some code
$ invoke shell
# OR
$ pipenv run django_shellIntroduction
Dependencies and References!
Linting and tests
- Testing - unittest (Pre-written for each exercise)
- Code style - pylint
- Type Annotations - MyPy
# sample function annotated for MyPy
# ...
@staticmethod
def resolve_author_name(
root: models.Story, # argument: type
info: graphene.ResolveInfo,
display: str,
) -> str: # -> return_type
return root.author.full_name(display)
# ...Introduction
Dependencies and References!
Web framework
# Example ORM commands for reading data
# Select a single author
author = Author.objects.get(pk=2)
# Quereyset - Select all Authors
all_authors = Author.objects.all()
# Queryset - Select only stories with matching criteria
stories = Story.objects.filter(author__in=author)
first_story = stories[0]
# Many-to-one - access model across foreign key
first_story.author
# One-to-many - access model across foreign key
author.stories.all()Introduction
Dependencies and References!
GraphQL + Python
-
Graphene (our focus today)
- Code-first, established library
-
Ariadne
- Schema-first, supports asyncio
-
Strawberry
- Code-first, asyncio, Dataclass-based
Chapter 1
Schema, Query and Response
Let's start with a small API, just one resource for listing stories.
- How would we get a list of titles and authors for those stories with REST and GraphQL?

Chapter 1
Schema, Query and Response
To get story titles and authors with REST...
Schema? Documented in Swagger? README?{
"data": [{
"id": "1"
"title": "Game of Thrones"
"subtitle": "A Song of Ice and Fire - Book 1",
"description": "Some really long text here...",
"authorName": "George R. R. Martin",
"passageCount": 52,
"averageRating": 4.7,
"links": [{
"href": "1/passages",
"rel": "passages",
"type" : "GET"
}]
}, {
"id": "2",
"title": "Romeo and/or Juliet",
"subtitle": "A Choosable Path Adventure",
"description": "Some really long text here...",
"authorName": "Ryan North",
"passageCount": 300,
"averageRating": 4.5,
"links": [{
"href": "2/passages",
"rel": "passages",
"type" : "GET"
}]
}]
}GET /api/v1/stories?display=FIRST_LASTChapter 1
Schema, Query and Response
Now let's query for story titles and authors with GraphQL...
type Query {
stories: [StoryType]
}
enum AuthorDisplayNameEnum {
FIRST_LAST
LAST_FIRST
}
type StoryType {
id: ID!
title: String
subtitle: String
passageCount: Int
averageRating: Float
authorName(
display: AuthorDisplayNameEnum = FIRST_LAST
): String
}query myFirstQuery {
stories {
id
title
authorName(display:LAST_FIRST)
}
}{
"data": {
"stories": [{
"id": "1"
"title": "Game of Thrones"
"authorName": "Martin, George R. R."
}, {
"id": "2"
"title": "Romeo and/or Juliet"
"authorName": "North, Ryan"
}]
}
}type Query {
stories: [StoryType]
}
enum AuthorDisplayNameEnum {
FIRST_LAST
LAST_FIRST
}
type StoryType {
id: ID!
title: String
subtitle: String
passageCount: Int
averageRating: Float
authorName(
display: AuthorDisplayNameEnum = FIRST_LAST
): String
}Schema Definition Language is a way to describe our API...
- Root Query
- Object Types
- Scalar Types
- Required Fields !
- Arguments (...)
- Array Fields [...]
- Enum
Chapter 1
Schema, Query and Response
Write queries against that schema..
- Optional query keyword
- Optional operation name
- Fields on Root Query
- Selection set {...} of fields on Objects
- Fields in our Selection set
- Arguments & values (...)
query myFirstQuery {
stories {
id
title
authorName(display:LAST_FIRST)
}
}Chapter 1
Schema, Query and Response
query myFirstQuery {
stories {
id
title
authorName(display:LAST_FIRST)
}
}When we execute the query, we get JSON results.
- Same shape as query
- Only fields from our query's selection set are evaluated
{
"data": {
"stories": [{
"id": "1"
"title": "Game of Thrones"
"authorName": "Martin, George R. R."
}, {
"id": "2"
"title": "Romeo and/or Juliet"
"authorName": "North, Ryan"
}]
}
}Schema, Query and Response
Chapter 1
If you need to change data, write a mutation!
mutation newStory {
createStory (input: {
title: "GraphQL",
author: "Dave A",
description: "Its pretty cool"
}) {
story{
id
title
description
author
}
}
}Schema, Query and Response
Chapter 1
input CreateStoryInput {
title: String
author: String
description: String
}
type CreateStoryPayload {
story: StoryType
}
type Mutation {
createStory(input: CreateStoryInput): CreateStoryPayload
}{
"data": {
"createStory": {
"story": {
"id": 1,
"title": "GraphQL",
"description": "It's pretty cool",
"author": "Dave A"
}
}
}
}Define a schema...
- Send mutation
- Pass input
- Do an operation
- Return query data
GraphiQL is a tool for exploring your API.
Exploring GraphQL
- Query Editor
- Query Results
- Variable Editor
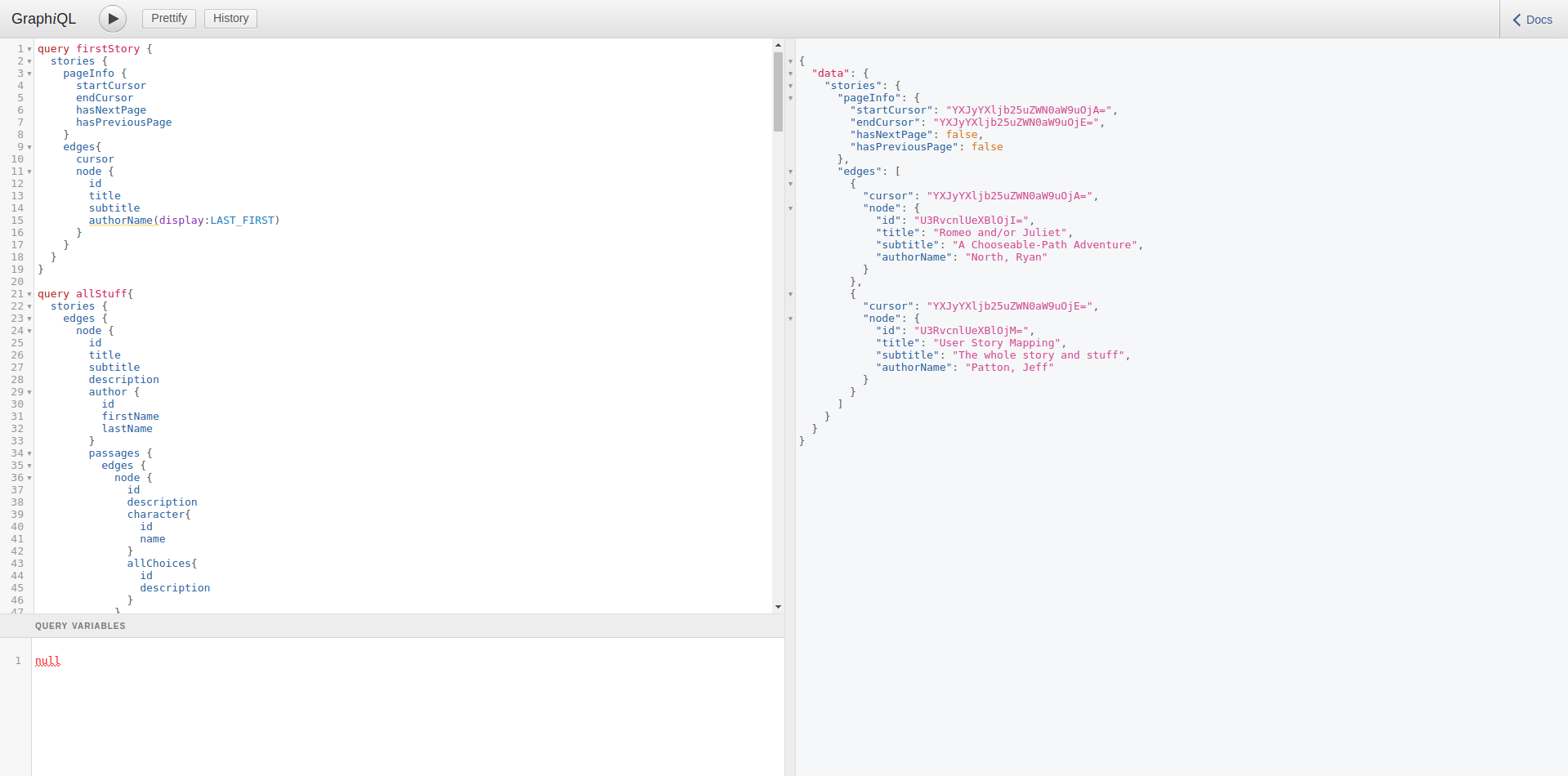
Chapter 1
- Run Query / Operation Selection
- Prettify
- History
- Documentation
Exploring GraphQL
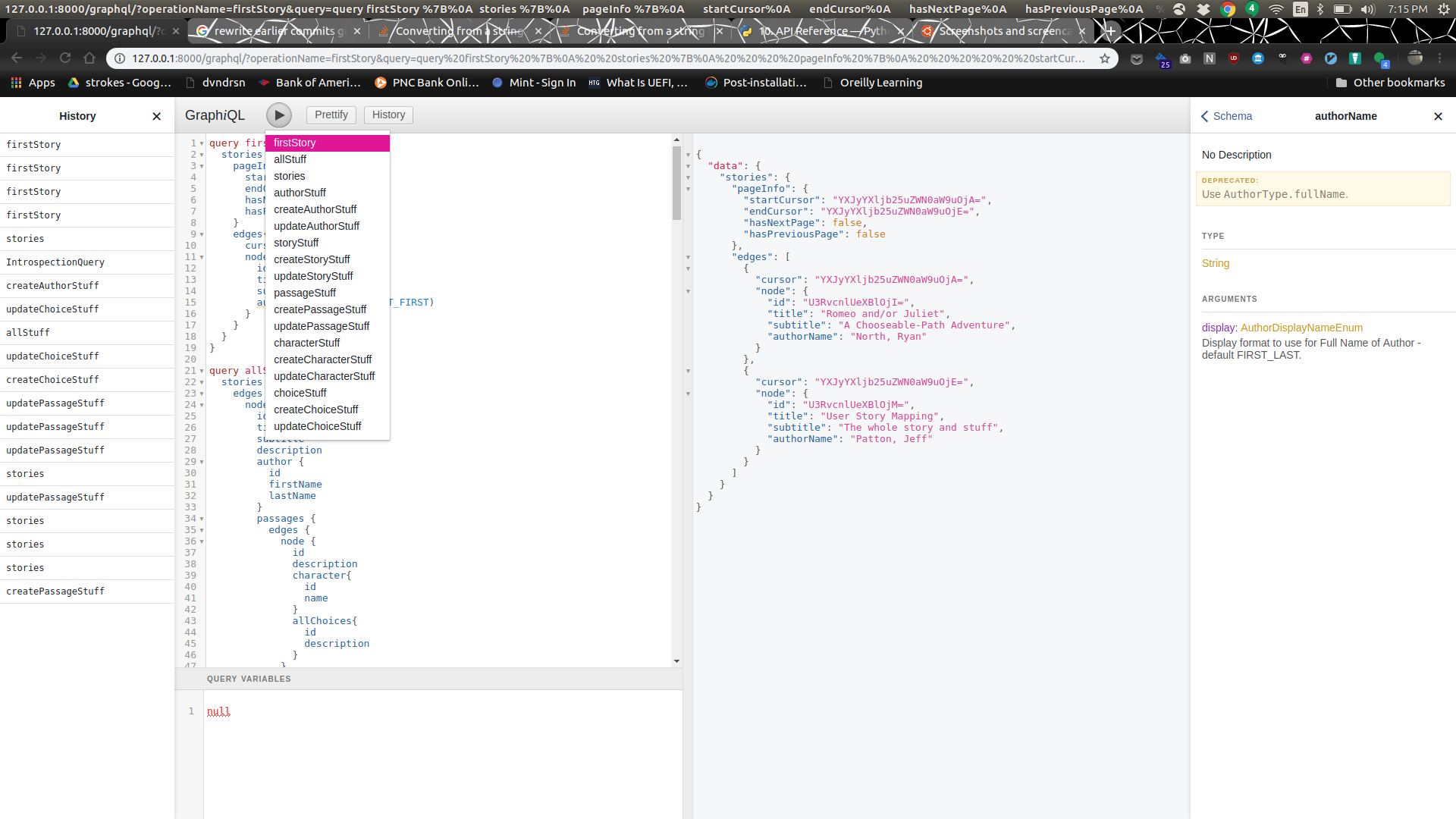
Chapter 1
It provides powerful features to rapidly prototype queries to your API.
GraphiQL POWER USER TIPS
Ctrl + Space: Auto-completion hint.
Can be used for fields, arguments, inputs, enum values.
Ctrl + Enter: Run query under cursor.
Bonus: can autocomplete some fields in selection set for object types.
Exploring GraphQL
Chapter 1

Exercise
- Find a pair!
- Ensure you're on branch chapter-1
- Open api/queries.graphql for some sample queries and instructions to get started!
- Run queries! Add some new fields!
- Change the argument for
`authorName`! - Explore documentation!
- Use power user shortcuts!
- Change the argument for
Exploring GraphQL
Chapter 1


Increasing diversity in GraphQL Python ecosystem with code-first and schema-first approaches.
- Graphene provides a feature-complete code-first GraphQL implementation.
- Bindings provided for Django
and many other popular web frameworks and ORM.
GraphQL + Python
Chapter 2

Graphene Django provides a View for parsing GraphQL requests.
- One endpoint, processes GET or POST
- View takes a schema defined through code
- GraphiQL support built-in!
# cyoa/urls.py
urlpatterns = [
...
path(
'graphql/',
GraphQLView.as_view(schema=schema, graphiql=True)
),
...
]GraphQL + Python
Chapter 2
Schema is defined through Graphene.
- Fields auto-camelCased by default
class StoryType(graphene.ObjectType):
id = graphene.ID()
title = graphene.String()
subtitle = graphene.String()
author_name = graphene.String(
args={
'display': graphene.Argument(
AuthorDisplayNameEnum,
default_value=AuthorDisplayNameEnum.FIRST_LAST,
)
}
)
class Query(graphene.ObjectType):
stories = graphene.List(StoryType)
...
schema = graphene.Schema(query=Query)type Query {
stories: [StoryType]
}
type StoryType {
id: ID!
title: String
subtitle: String
authorName(display:
AuthorDisplayNameEnum = FIRST_LAST
): String
}GraphQL + Python
Chapter 2
- The field author_name is provided data from resolve_author_name.
- The value object being resolved is always the first argument of the resolver.
- Here root is a model object.
- Graphene allows implicit resolvers if the field name matches the attribute of the root value object.
- The query context info is always the second argument.
- Any further parameters are GraphQL arguments from the field passed as keywords.
class StoryType(graphene.ObjectType):
subtitle = graphene.String()
author_name = graphene.String(
# ...
)
@staticmethod
def resolve_subtitle(
root: models.Story,
info: graphene.ResolveInfo
) -> str:
return root.subtitle
@staticmethod
def resolve_author_name(
root: models.Story,
info: graphene.ResolveInfo,
display: str
) -> str:
return root.author.full_name(display)
GraphQL + Python
Chapter 2
Each field in our schema has a resolver function.
Resolver functions help us answer Queries.
- Queries are first parsed and validated against the schema.
- Resolver functions cascade data from the Root Query to individual scalar fields
class StoryType(graphene.ObjectType):
# ...
@staticmethod
def resolve_author_name(
root: models.Story,
info: graphene.ResolveInfo,
display: str
) -> str:
return root.author.full_name(display)
class Query(graphene.ObjectType):
# ...
@staticmethod
def resolve_stories(
root: None,
info: graphene.ResolveInfo
) -> Iterable[models.Story]:
return Story.objects.all()query myFirstQuery {
stories {
id
title
authorName(
display:LAST_FIRST
)
}
}GraphQL + Python
Chapter 2
Let's trace data through an example...
schema = graphene.Schema(query=Query)
class Query(graphene.ObjectType):
stories = graphene.List(StoryType)
@staticmethod
def resolve_stories(
root: None,
info: graphene.ResolveInfo
) -> Iterable[models.Story]:
return Story.objects.all()class StoryType(graphene.ObjectType):
# ...
author_name = graphene.String(...)
@staticmethod
def resolve_author_name(
root: models.Story,
info: graphene.ResolveInfo,
display: str
) -> str:
return root.author.full_name(display)GraphQL + Python
Chapter 2
query
stories
story1
story2
title
id
authorName
title
id
authorName
None
Fields
Root Value
Fields
Root Value
Fields
Exercise
- Find a pair!
- Ensure you're on branch chapter-2
- Open api/query/story.py for further instructions and make changes to the schema.
- Verify your changes through the prepared tests and running sample queries in api/queries.graphql
GraphQL + Python
type StoryType {
# Add fields
description: String
publishedYear: String
}Chapter 2

Why Relay compliance?
- Facebook Standards required by the Relay GraphQL client.
- Not required for other popular clients like Apollo.
- But! the standard includes some useful patterns for GraphQL.
Chapter 3
Relay Compliance

What does it mean for an API to be
Relay Compliant?
-
A mechanism for re-fetching an object.
-
A standard way to page through connections.
-
Structure around mutations to make them predictable.
Relay Compliance
Chapter 3

A mechanism for re-fetching an object.
- Our API only has lists of objects currently.
- What is a good pattern for fetching a single object?
- By adhering to Relay standard, we get that capability through the Node Field and Interface.
Relay: Node
type Query {
stories: [StoryType]
node(id: ID!): Node
}Chapter 3
An interface in GraphQL defines a set of fields which are shared across types that implement the interface.
- Node interface only provides an ID field to a type.
- Interfaces are specified using a Meta class pattern in Graphene.
Relay: Node
interface Node {
id: ID!
}
type StoryType implements Node {
# ...
}
class StoryType(graphene.Object):
class Meta:
interfaces = (graphene.Node,)
# ...Chapter 3
Node Interface
Disambiguating objects with Interface or Union
- is_type_of
- Determine if an object can be resolved with this type
Relay: Node
class StoryType(graphene.Object):
# ...
@classmethod
def is_type_of(
cls,
root: Any,
info: graphene.ResolveInfo
) -> bool:
return isinstance(root, models.Story)
Chapter 3
Querying the node field!
- Variable
- static query with dynamic values
- Field alias
- rename node to something more meaningful
- Inline Fragment
- fetch fields not part of interface
Relay: Node
query storyInfo($storyId: ID!) {
story: node(id: $storyId) {
id
... on StoryType {
title
description
}
}
}
# Variables:
# {"storyId": "U3RvcnlUeXBlOjI="}Chapter 3
The node ID value is meant to be
- non-human readable
- globally unique.
Relay: Node
U3RvcnlUeXBlOjI=
StoryType:2
<GraphQL-Type>:<ID>
Chapter 3
Graphene base-64 encodes ID values:
The node Field returns any type that implements Node matching the provided ID.
- The GraphQL type from the decoded ID is used to defer to the correct Graphene object to load the record
Relay: Node
type Query {
# ...
node(id: ID!): Node
}class Query(graphene.Object):
# ...
node = graphene.Node.Field()Chapter 3
The graphene Node field defers to the correct type to load data.
-
Use the decoded id in get_node class method
Relay: Node
class StoryType(graphene.Object):
# ...
@classmethod
def get_node(
cls,
info: graphene.ResolveInfo,
id_: str
) -> Story:
pk = int(id_)
return Story.objects.get(pk=pk)Chapter 3
Relay: Node
Exercise
- Find a pair!
- Ensure you're on branch chapter-3
- See api/queries.graphql for some examples of queries and instructions to get started.
query dataForOneStory($storyId: ID!) {
story: node(id: $storyId) {
id
... on StoryType {
title
description
}
}
}
# Variables:
# {"storyId": "U3RvcnlUeXBlOjI="}Chapter 3

A standard way to page through connections.
- As the amount of data in our system grows, we need to consider pagination for long lists of results.
- Relay Connection provides a easy to implement pagination solution using Graphene.
Relay: Connection
type Query {
stories: [StoryType]
stories(first: Int, after: String, last: int, before: String): StoryConnection
}Chapter 3
Forward pagination using a connection field.
- Page size
- Show records after this cursor
- Can we page forward? What is our next value for $afterCursor?
- Edge and node for each record (graph-like metaphor)
Relay: Connection
query($afterCursor: String) {
stories(first:10, after: $afterCursor) {
pageInfo {
endCursor
hasNextPage
}
edges {
cursor
node {
id
title
subtitle
description
authorName(display: FIRST_LAST)
}
}
}
}
# Variables : {
# "afterCursor": "YXJyYXljb25uZWN0aW9uOjA="
# }Chapter 3
Relay Connections use a Cursor-based pagination API
- Compare with Limit/Offset based API
- Cursor API is opaque to client (base-64 encoded)
- contains all information needed to paginate the results
Relay: Connection
Chapter 3

Graphene uses Cursor based API with Limit/Offset under the hood.
- The Connection arguments `first` and `last` determine Limit
- Cursor is base 64-encoded
- Cursor determines Offset
Relay: Connection
YXJyYXljb25uZWN0aW9uOjA=
arrayconnection:0
<pagination-style>:<offset>
Chapter 3
The Connection API for cursor based pagination provides.
- Pagination parameters
- Connection & Page Info
- Edge for each record
- For paging forward..
- And backward
Relay: Connection
type Query {
stories(
first: int,
after: String,
last: int,
before: String
): StoryConnection
}
type StoryConnection {
pageInfo: PageInfo
edges: [StoryEdge]
}
type PageInfo {
endCursor: String
hasNextPage: Boolean!
startCursor: String
hasPreviousPage: Boolean!
}
type StoryEdge {
cursor: String!
node: StoryType!
}class StoryType(graphene.Object):
# ...
class StoryConnection(graphene.Connection):
class Meta:
node = StoryType
class Query(graphene.ObjectType):
stories = graphene.ConnectionField(StoryConnection)
# ...Chapter 3
Moving from List to Connection is a breaking change for our API consumers!
- Carefully consider which fields require pagination
- Using Connection instead of List requires minimal extra effort
Relay: Connection
Chapter 3

Relay: Connection
Exercise
- Find a pair!
- Ensure you're on branch chapter-3b
- See api/queries.graphql for some examples of queries and more specific instructions
query pageForwardThroughStories($afterCursor: String) {
stories(first:3 , after: $afterCursor) {
pageInfo { endCursor hasNextPage }
edges {
cursor
node {
id
title
subtitle
description
authorName(display: FIRST_LAST)
}
}
}
}
# Variables:
# {"afterCursor": null}Chapter 3

Structure around mutations to make them predictable.
- No big changes to the structure or behavior of mutations to comply with the Relay spec
- Receive arguments -> change data -> send response
- Relay requires a standard way to pass mutation Input.
- And an id to determine which requests have responses...
Relay: Mutations
type Mutation {
createStory(
input: CreateStoryInput
): CreateStoryPayload
}input CreateStoryInput {
# ...
clientMutationId: String
}
type CreateStoryPayload {
# ...
clientMutationId: String
}Chapter 3
Structure around mutations to make them predictable
Relay: Mutations
Chapter 3
mutation newStory {
createStory (input: {
title: "GraphQL",
author: "Dave A",
description: "Its pretty cool",
clientMutationId: "Mutation-1"
}) {
story{
id
title
description
author
}
}
}{
"data": {
"createStory": {
"story": {
"id": 1,
"title": "GraphQL",
"description": "It's pretty cool",
"author": "Dave A"
},
"clientMutationId": "Mutation-1"
}
}
}Graphene provides a simple implementation.
- Client Mutation ID is handled automatically
- Input class mapped as argument to mutation
Relay + Mutations
input CreateStoryInput {
title: String!
author: String!
description: String!
clientMutationId: String
}
type CreateStoryPayload {
story: StoryType
clientMutationId: String
}
type Mutation {
createStory(
input: CreateStoryInput
): CreateStoryPayload
}class CreateStory(graphene.ClientIDMutation):
class Input:
title = graphene.String()
subtitle = graphene.String()
description = graphene.String()
story = graphene.Field('api.query.story.StoryType')
@classmethod
def mutate_and_get_payload(
cls,
root: None,
info: graphene.ResolveInfo,
**input_data: dict
) -> 'CreateStory':
# use input_data to create `story`
# ...
return cls(story=story)Chapter 3
In review
- Relay Compliance is just a standard, with some good GraphQL practices.
- Easy to implement with Graphene!
- Consider carefully if you don't adhere as supporting Connection or Client Mutation
ID later will lead to breaking changes!
Relay Compliance
Chapter 3

Making changes to a public interface can be hard!
- With an API, there may be multiple consumers, from your single page frontend application to android or iOS app.
- The information that tells you if a change is safe to be made is spread thin.
- If your API is public, there are even more considerations that need to be taken to avoid breaking consumers.
- But! There are rules of thumb which can help you evolve the schema without breaking changes!
Chapter 4
Schema Evolution vs. Versioning

Evolution without breaking changes.
- Given a query, with a selection of fields, arguments and variables...
- if it returns same types to a client, before and after a change...
- it will not be a breaking change!
- Types help us make this promise more easily.
- The schema is a contract that isolates the client from implementation on the server.
Chapter 4
Schema Evolution vs. Versioning

Base 64 encoding tokens like ID and Pagination Cursor encourage client safety too.
- A change to the implementation of the server should not affect clients.
- Clients discouraged from parsing and interpreting data used by the server internally.
- However, the interface of how those tokens are used, defined by our schema, does not change.
Chapter 4
Schema Evolution vs. Versioning

Adding a new field
- In GraphQL we have confidence that new fields will not have any impact on existing queries using that type.
- New data is only exposed to a client when a field is used in a query.
- Even with REST, this kind of change is often safe to make as long as we maintain the same schema for other fields.
- However, if the new field is expensive to compute, with GraphQL, we know that performance for existing queries will not be impacted.
Chapter 4
Schema Evolution vs. Versioning

Adding a new argument
- When we add a new argument to a field, we know it will not have any impact on existing queries if it is optional or if it has a default value.
- Even clients on statically typed systems like Android or iOS are typically only impacted by changes that affect the return type of queries.
- However, this may break RPC-style generated code from specific libraries (not common).
Chapter 4
Schema Evolution vs. Versioning

Evolving Any API
- In general the same principals for evolving GraphQL API's apply to REST API or any other public interface.
- Google's API Design Guide codifies this very well.
- This guide is written with REST and gRPC in mind, but the concepts are broadly applicable even to GraphQL.
Chapter 4
Schema Evolution vs. Versioning

Tooling
- In addition to the schema, the GraphQL community has developed useful tooling and techniques.
- For clients with known queries, contract testing using type checking of static queries against static schema definition.
- Resolver-level middleware can be used to track API usage from live production queries on a per field
basis.
Chapter 4
Schema Evolution vs. Versioning

Breaking Changes
- GraphQL's built in deprecation reason can be used to communicate changes to consumers.
- This is used very effectively by GitHub to communicate changes to their API months out, without ever having to version their API.
- Introspection can warn clients using fields marked for depreciation.
Chapter 4
Schema Evolution vs. Versioning
Versioning
- In REST, this is often the default option.
- In GraphQL, not the first choice, but if evolution is too drastic or risky, API versioning can be a useful escape hatch.
- Shopify, a huge proponent of GraphQL, has recently added versioning to their APIs.
Chapter 4
Schema Evolution vs. Versioning

Let's add a new related record for Story, Author to our API.
Chapter 4
Schema Evolution vs. Versioning

In REST, we might add a separate endpoint /v1/authors:
- add links to related records as URL (N+1 on client side)
- OR embed author directly into the story request (maybe overfetching)
- Do we need to bump to a new version for stories endpoint?
Schema Evolution vs. Versioning
Chapter 4

Add Author type and authors field to the root query.
- Safe evolution - only new fields
- Leverage Connection and Node
Schema Evolution vs. Versioning
type Query {
...
authors(before: String, after: String, first: Int, last: Int): AuthorConnection
}
type AuthorType implements Node {
id: ID!
firstName: String
lastName: String
fullName(display: AuthorDisplayNameEnum = FIRST_LAST): String
twitterAccount: String
# ...
}Chapter 4
What should our focus be as we grow the project structure?
- Keep like things together in packages
- Package for Query, Mutation
- Keep module files short and focused
- Module for each type or domain
api/
query/
__init__.py
author.py
story.py
base.py
mutation/
__init__.py
author.py
story.py
base.py
__init__.py
schema.py
# domain models and logic separate from api
application/...Evolving Graphene Schema & Project Structure
Chapter 4
Multiple inheritance for base Query and Mutation in package
- Each module exports root query or Mutation object
Evolving Graphene Schema & Project Structure
# api/query/base.py
class Query(
StoryQuery,
AuthorQuery
):
pass
# api/mutation/base.py
class Mutation(
StoryMutation,
AuthorMutation
):
passChapter 4
Let's evolve the schema!
- Find a pair!
- Ensure you're on branch chapter-4
- Open api/query/author.py and follow instructions to implement changes to the schema.
- Run sample queries found in api/queries.graphql.
type Query {
...
authors(before: String, after: String, first: Int, last: Int): AuthorConnection
}
type AuthorType implements Node {
id: ID!
firstName: String
lastName: String
fullName(display: AuthorDisplayNameEnum = FIRST_LAST): String
twitterAccount: String
# ...
}Evolving Graphene Schema & Project Structure
Chapter 4
Add fields that connect the two types.
- More flexible API. Navigate from a single node to any connected type.
-
In Graphene, use Field and ConnectionField with python module string.
- graphene.Field('api.query.module.Type')
- graphene.ConnectionField(
'api.query.module.ConnectionType')
Schema Evolution vs. Versioning
type AuthorType implements Node {
# ...
stories(before: String, after: String, first: Int, last: Int): StoryConnection
}
type StoryType {
author: AuthorType
# ...
}Chapter 4
Depreciate fields that are no longer required.
- Any Graphene schema object takes `deprecation_reason` keyword argument with the reason text.
Schema Evolution vs. Versioning
type StoryType {
authorName(display: AuthorDisplayNameEnum = FIRST_LAST): String @deprecated(
reason: "Use StoryType.author.fullname"
)
# ...
}Chapter 4
Let's evolve the schema (even more)!
- Find a pair!
- Ensure you're on branch chapter-4b
- Open api/query/author.py and api/query/story.py and follow the instructions to implement changes to the schema.
- Run sample queries found in api/queries.graphql.
type AuthorType implements Node {
# ...
stories(before: String, after: String, first: Int, last: Int): StoryConnection
}
type StoryType {
author: AuthorType
authorName(display: AuthorDisplayNameEnum = FIRST_LAST): String @deprecated(
reason: "Use StoryType.author.fullname"
)
# ...
}Evolving Graphene Schema & Project Structure
Chapter 4
In review..
- GraphQL gives us tools and techniques that help us prefer one unified, evolving API over many versioned endpoints
- As long as the schema used by existing queries does not change, our API can grow
- Scheduled breaking changes through depreciations allows for more drastic change
- The same techniques can be applied to REST or any other public interface with some discipline
Evolving Graphene Schema & Project Structure
Chapter 4

Chapter 5
Scaling and Performance
Over time our API may grow into something surprising.
- Beyond supporting stories and authors, we can represent a choose-your-own style
story with passages and choices. - How do we scale our API's
performance as it grows
more complex?


Chapter 5
Scaling and Performance
Performance tuning can be more challenging with GraphQL.
- Not generally possible to do HTTP level request caching
- The "N+1" problem becomes more
serious as our API grows with more connections

Scaling and Performance
What does a simple N+1 GraphQL query look like?
query storiesWithAuthor {
stories(first: 3) {
edges {
node {
id
title
author {
firstName
}
}
}
}
}
Chapter 5
S
A
S
A
S
A
S
A
S
A
S
A
S
A
{
"data": {
"stories": {
"edges": [
{
"node": {
"id": "U3RvcnlUeXBlOjI=",
"title": "Romeo and/or Juliet",
"author": { "firstName": "Ryan" }
}
},
{
"node": {
"id": "U3RvcnlUeXBlOjM=",
"title": "User Story Mapping",
"author": { "firstName": "Jeff" }
}
},
{
"node": {
"id": "U3RvcnlUeXBlOjQ=",
"title": "Ancillary Justice",
"author": { "firstName": "Ann" }
}
},
...
]
}
}
}Scaling and Performance
This can quickly get out of hand with a more nested query...
Stories
Story 1 passages
Story 2 -author, passages, etc..
Passage 1 - Choices
Choice 1 - To Passage
Passage 2 - Choices, etc..
Etc..
Time
query allStories {
stories {
id
title
author {
name
}
passages {
id
description
choices {
id
description
toPassage {
id
description
}
}
}
}
}Story 1 author
Try a few queries yourself on the chapter-5 branch, monitor the logs for N+1 queries!
Chapter 5
Scaling and Performance
To optimize, we can try to aggressively select related data in our queries..
class StoryType(graphene.ObjectType):
...
def resolve_passages(self, info, **kwargs):
return Passage.objects.filter(story=self.id) \
.prefetch_related('to_choices__to_passage')
...
class Query(graphene.ObjectType):
...
def resolve_story(self, info, **kwargs):
return Story.objects.all() \
.select_related('author')
...query allStories {
stories {
id
title
author {
name
}
passages {
id
description
choices {
id
description
toPassage {
id
description
}
}
}
}
}Chapter 5
Scaling and Performance
Less queries, but risk of overfetching from database!
Stories + author
Story 1 passages +
choices + to passage
Story 2 passages +
choices + to passage
Etc..
Etc..
Time
query allStories {
stories {
id
title
author {
name
}
passages {
id
description
choices {
id
description
toPassage {
id
description
}
}
}
}
}query allStoriesOverview {
stories {
id
title
passages {
id
description
}
}
}Chapter 5
Scaling and Performance with DataLoaders
Using DataLoader is the Facebook-preferred approach.
- Provided in the GraphQL-Python ecosystem
- Batches requests across nodes
- Request level caching for results
Chapter 5

DataLoaders:
- Should live for the context of the request only
- Load based upon a hashable key
- Batch the keys
- Load values in bulk
- Returned in order of input keys
class PassagesFromStoryLoader(DataLoader):
def batch_load_fn(self, story_ids):
return Promise.resolve(self.get_passages(story_ids))
def get_passages(self, story_ids):
passages = Passage.objects \
.filter(story_id__in=story_ids)
lookup = defaultdict(list)
for passage in passages:
lookup[passage.story_id].append(passage)
return [lookup[story_id] for story_id in story_ids]
class StoryType(graphene.ObjectType):
...
def resolve_passages(self, info, **kwargs):
return info.context.loaders.passages_from_story \
.load(self.id)
...
Scaling and Performance with DataLoaders
Chapter 5
Revisiting our simple query performance..
- While resolving each StoryType, DataLoader `load` method called with each author id.
- Batched ids are passed to DataLoader `batch_load_fn` and authors loaded in bulk.
- Author records are only fetched once (cached), even when used in multiple stories.
Scaling and Performance with DataLoaders
Chapter 5
S
A
S
A
S
A
S
A
S
A
S
A
S
A
query storiesWithAuthor {
stories(first: 3) {
edges {
node {
id
title
author {
firstName
}
}
}
}
}
Batching and caching helps scale performance!
Stories
Passages (batched across Stories)
Choices (batched across Passages)
To Passage (cached)
Time
query allStories {
stories {
id
title
author {
name
}
passages {
id
description
choices {
id
description
toPassage {
id
description
}
}
}
}
}Author (cached, batched across Stories)
Try a few queries yourself on the chapter-5b branch, monitor for batched queries!
Scaling and Performance with DataLoaders
Chapter 5
GraphQL's full potential is more realized with a rich client, like a single page javascript app.
Building a client web application
Chapter 6

Apollo is a powerful framework that allows you to focus on writing application code.
- It handles loading...
- errors...
- response normalization..
- and caching.

Building a client web application



Chapter 6
const Stories = () => (
<Query query={STORIES_QUERY}>
{({ loading, error, data }) => {
if (loading) return <p>Loading...</p>;
if (error) return <p>Error :(</p>;
return (
<div>
{data.stories.edges.map(({ node: story }) => (
<div key={story.id}>
{`${story.title} (${story.publishedYear})`} -
{story.author.fullName}
<div/>
))}
</div>
);
}}
</Query>
);
const client = new ApolloClient({
uri: "http://localhost:8000/graphql/"
});
const App = () => (
<ApolloProvider client={client}>
<Stories />
</ApolloProvider>
);const STORIES_QUERY = gql`
query storiesWithAuthor {
stories {
edges {
node {
id
title
publishedYear
author {
id
fullName(
display: FIRST_LAST
)
}
}
}
}
}
`;Building a client web application
Chapter 6
const AddStoryButton = ({ authorId }) => (
<Mutation mutation={ADD_STORY}>
{addStory => {
return (
<div
onClick={() =>
addStory({
variables: {
title: faker.company.companyName(),
subtitle: faker.company.catchPhrase(),
description: faker.company.bs(),
publishedYear: faker.date.past()
.getFullYear(),
authorId: authorId
}
})
}
>
Add story
</div>
);
}}
</Mutation>
);const ADD_STORY = gql`
mutation addStory(
$title: String
$subtitle: String
$description: String
$publishedYear: String
$authorId: ID
) {
createStory(
input: {
title: $title
subtitle: $subtitle
description: $description
publishedYear: $publishedYear
authorId: $authorId
}
) {
story {
id
title
subtitle
description
publishedYear
}
}
}
`;Building a client web application
Chapter 6
{
"data": {
"stories": {
"edges": [
{
"node": {
"id": "U3RvcnlUeXBlOjQ=",
"title": "Ancillary Justice",
"publishedYear": "2013",
"author": {
"id": "QXV0aG9yVHlwZTo2",
"fullName": "Ann Leckie"
}
}
},
{
"node": {
"id": "U3RvcnlUeXBlOjU=",
"title": "Ancillary Sword",
"publishedYear": "2014",
"author": {
"id": "QXV0aG9yVHlwZTo2",
"fullName": "Ann Leckie"
}
}
},
# ...
]
}
}
}query storiesWithAuthor {
stories {
edges {
node {
id
title
publishedYear
author {
id
fullName(
display: FIRST_LAST
)
}
}
}
}
}Building a client web application
Chapter 6
Normalization & Caching
- AuthorType:QXV0aG9yVHlwZTo2
- StoryType:U3RvcnlUeXBlOjQ=
- StoryType:U3RvcnlUeXBlOjU=
- ROOT_QUERY
query storiesForAuthor {
author(id: "1") {
id
firstName
lastName
stories {
id
title
}
}
}query listOfAuthors {
authors {
id
firstName
lastName
}
}mutation changeStory {
updateStory(input:{
id:"1",
title: "Update this!"
}) {
story {
id
title
}
}
}...we ensure that the cache will be updated properly and updated data flows to components.
As we add more queries and mutations, If all objects have a ID...
Chapter 6
Building a client web application
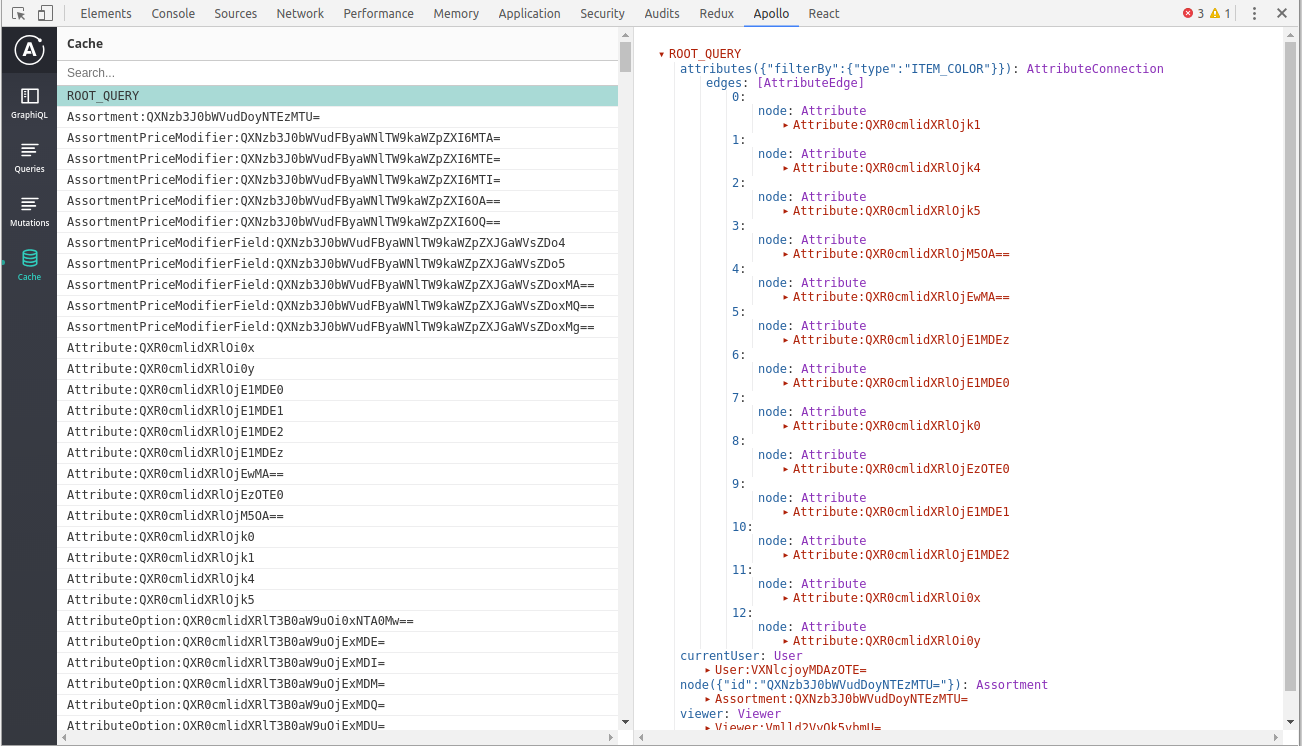
Apollo Development Tools
- Show denormalized cache
- Show active queries & Mutations
Chapter 6
Building a client web application
API Design for Client Side Caching
As your single page app grows, you may see more caching bugs..
- There are some rules of thumb for designing mutations to avoid them!
- And Apollo provides some nice escape hatches for when those won't work.

Chapter 6
When removing items from lists...
API Design for Client Side Caching
query storiesForAuthors {
author(id: "1") {
id
firstName
lastName
stories {
id
title
}
}
}mutation removeStory {
removeStory(input:{
authorId:"1",
storyId: "6"
}) {
story { # RETURNS REMOVED STORY DATA
id
title
}
}
}...you may not see them properly removed on the page.
Chapter 6
<Mutation
mutation={REMOVE_STORY}
update={(cache, { data: { removeStory } }) => {
const { stories } = cache.readQuery({ query: GET_STORIES });
cache.writeQuery({
query: GET_STORIES,
data: {
stories: stories.filter(
(stories) => story.id == removeStory.story.id
) },
});
}}
>
...API Design for Client Side Caching
Apollo provides a mechanism for manually updating the cache...
...but this can be hard to reason about and test.
Chapter 6
<Mutation
mutation={REMOVE_STORY}
refetchQueries={['allStories']}
>
...API Design for Client Side Caching
We could also more simply just refetch any affected queries...
...but as your page grows, it can be hard to maintain a full list of queries and can be expensive to refetch!
Chapter 6
query storiesForAuthors {
author(id: "1") {
id
firstName
lastName
stories {
id
title
}
}
}mutation removeStory {
removeStory(input:{
authorId:"1",
storyId:"6"
}) {
story {
id
title
}
author {
id
stories {
id
}
}
}
}API Design for Client Side Caching
...the cached list of stories for our author will be updated automatically!
If we design our mutation payload correctly..
Chapter 6
query storiesForAuthors {
author(id: "1") {
id
firstName
lastName
stories {
id
title
description
}
}
}mutation addStory {
addStory(input:{
authorId:"1",
title: "Stuff"
}) {
story {
id
title
}
author {
id
stories {
id
}
}
}
}API Design for Client Side Caching
When adding to a list with a mutation...
We'll face errors in Apollo due to missing fields in our new post.
Chapter 6
query storiesForAuthors {
author(id: "1") {
id
firstName
lastName
story {
...allStoryFields
}
}
}
fragment allStoryFields on Story {
id
title
description
}mutation removePost {
addStory(input:{
authorId:"1",
title: "Stuff"
}) {
story {
...allStoryFields
}
author {
id
stories {
id
}
}
}
}API Design for Client Side Caching
Fragments can help us ensure that all fields are fetched when adding an item to a list.
Chapter 6
API Design for Client Side Caching
Chapter 6
Let's fix some caching bugs!
- Find a pair!
- Ensure you're on branch chapter-6 for backend and frontend.
- Ensure your backend and frontend servers are running.
- Open src/AddStoryButton.js on frontend and follow instructions to try to address the caching problems by modifying the query.

EPILOGUE TO Your Adventure
A parting word before the next adventure
Evolution in a nutshell...
- Constraints to build a Minimal, Evolving API
- Static typed schema and queries as a guide
- Focus on Domain Modeling
- Rich backend, lean frontend - fields and arguments describing specific data requirements
- Powerful client, letting you focus on writing the code that matters


The end
Thanks for participating!
Questions?
@dvndrsn
The Rabbit Hole Podcast: http://bit.ly/2Jous2O
Stride Consulting: https://www.stridenyc.com/careers

Dave Anderson

References
Thanks for listening!
Icons8 (open source icons):
Open Clip Art:
VectEasy:
Code Sample:
https://github.com/dvndrsn/graphql-python-tutorial
Graphene (Python):
http://docs.graphene-python.org/en/latest/
Apollo (JavaScript):