CUDA
Cesena Security Network and Application
1. Storia
2. Architettura
3. Codice
4. Gestione e ottimizzazione
5. Unified Memory
Storia
-
Legge di Moore
-
Programmazione Parallela
-
GPGPU
Storia
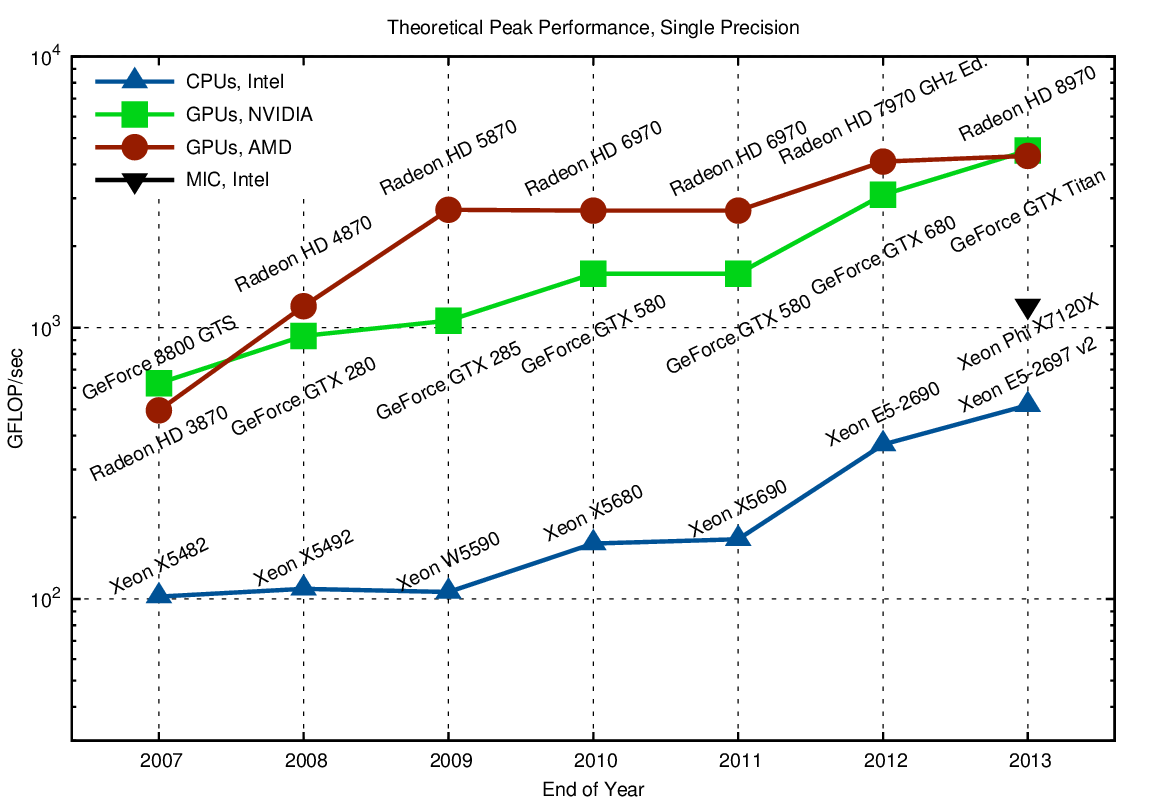
API Grafiche
Brook
CUDA
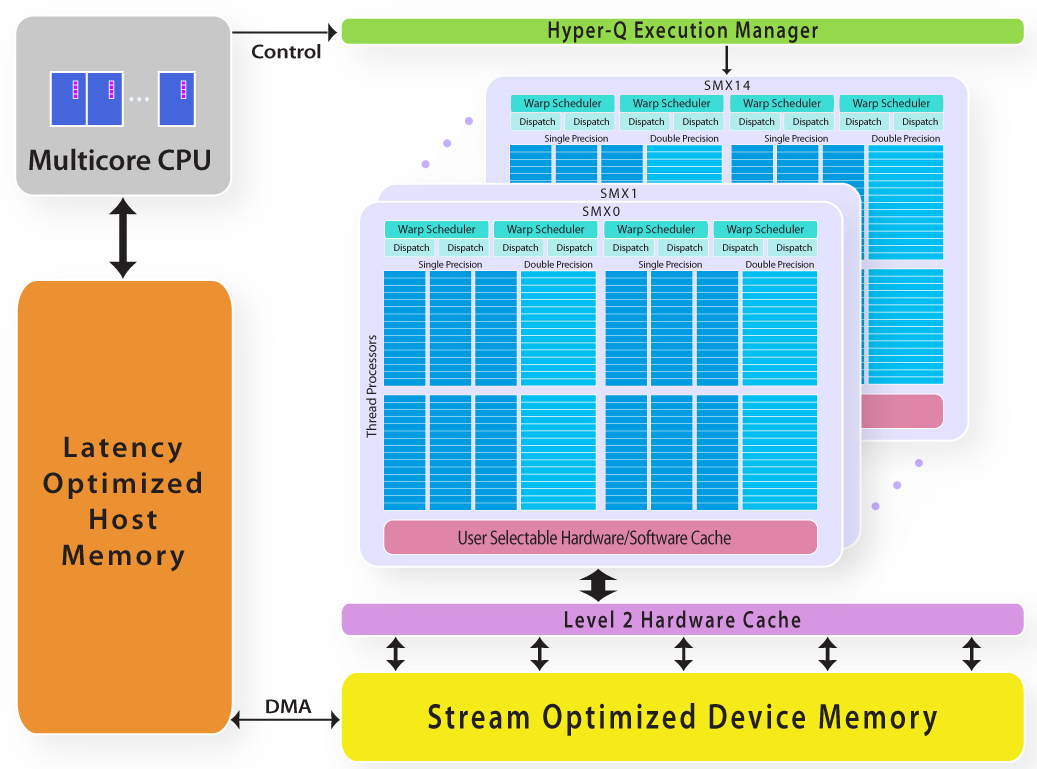
Architettura
Memoria Globale
Streaming Multiprocessors
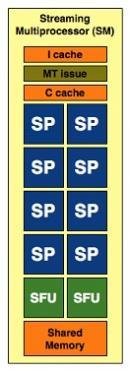
Architettura
Memorie
- Globale
- Locale
- Condivisa
- Costante
- Registri
- Texture
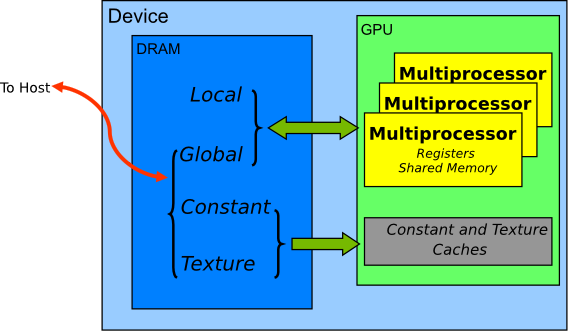
To Host
Architettura
- Host
- Device
- Thread
- Block
- Warp
- Grid
- Kernel
Architettura
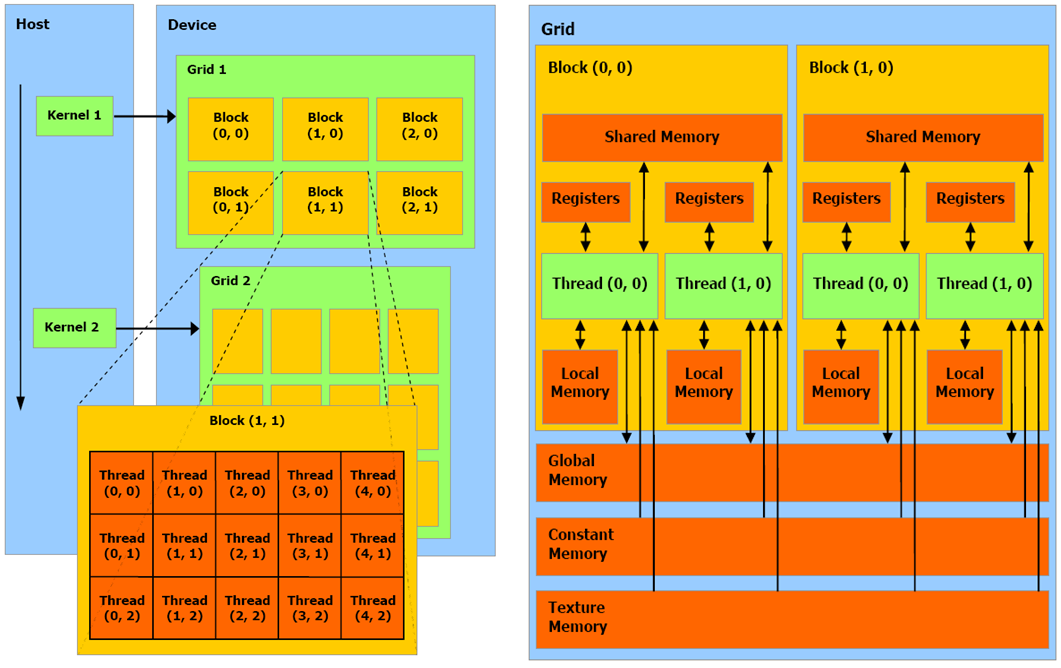
Architettura
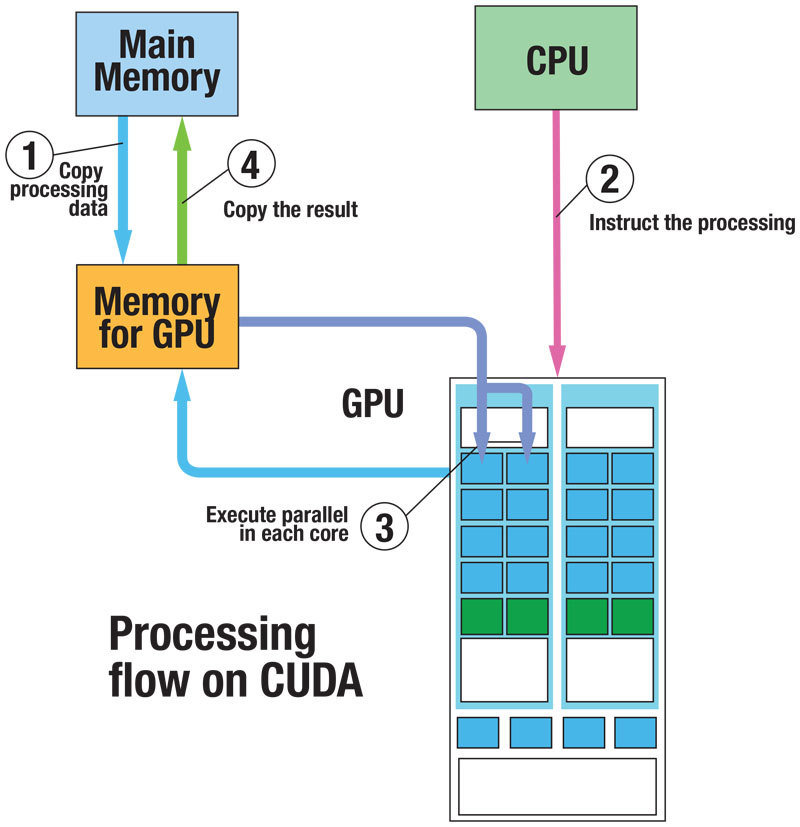
Codice
C C++ Fortran Python Matlab Java
Codice
Sintassi
__global__: kernel GPU lanciato dalla CPU
__device__: può essere invocato dalla GPU
__host__: può essere invocato dal CPU.
nome_kernel <<<DimGriglia, DimBlocco>>> (arg1 [, arg2]);
cudaMalloc((void**) &add, size_t size)
cudaMemcpy(void* dst, void* src, size_t size, enum cudaMemcpyKind type)
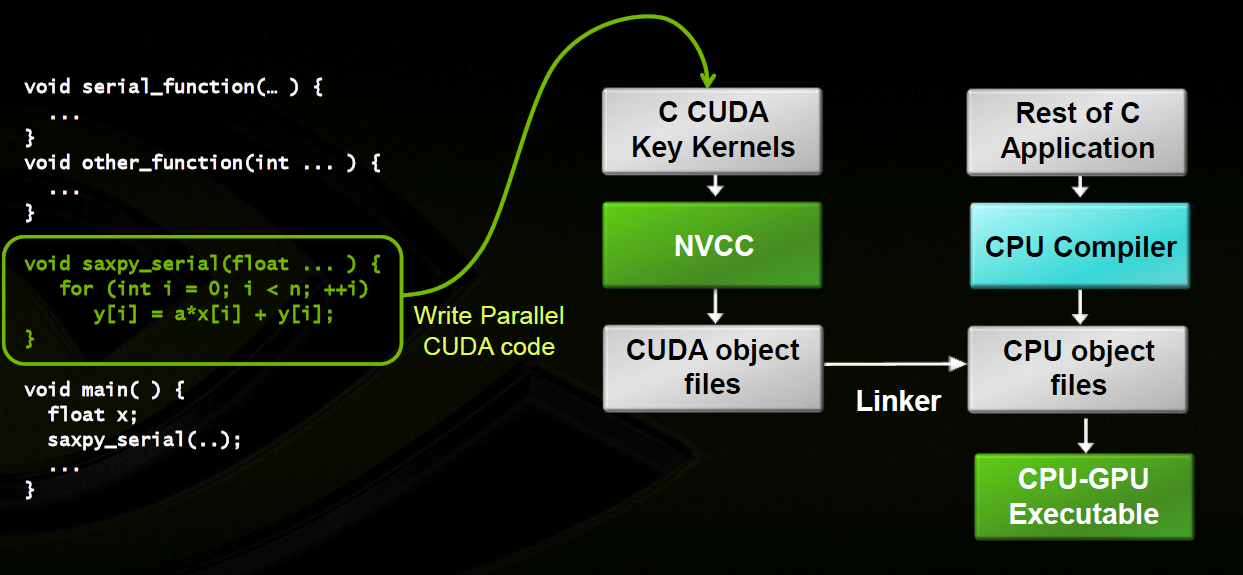
Codice
NVCC
Gestione e ottimizzazione
- 2 Multiprocessori X 48 CUDA Core/MP = 96 CUDA Core;
- Frequenza di clock = 1550 Mhz;
- Numero massimo di thread per multiprocessore = 1536;
- Numero massimo di warp per multiprocessore = 1536/32 = 48;
- Numero massimo di thread per blocco = 1024;
- Dimensione massima per blocco = 1024 x 1024 x 64;
- Dimensione massima per griglia = 65535 x 65535 x 65535;
Occypancy VS Coalescence
| 6 warp | 8 warp | 12 warp | 16 warp | 24 warp
Thread | 192 | 256 | 384 | 512 | 768
Unified Memory
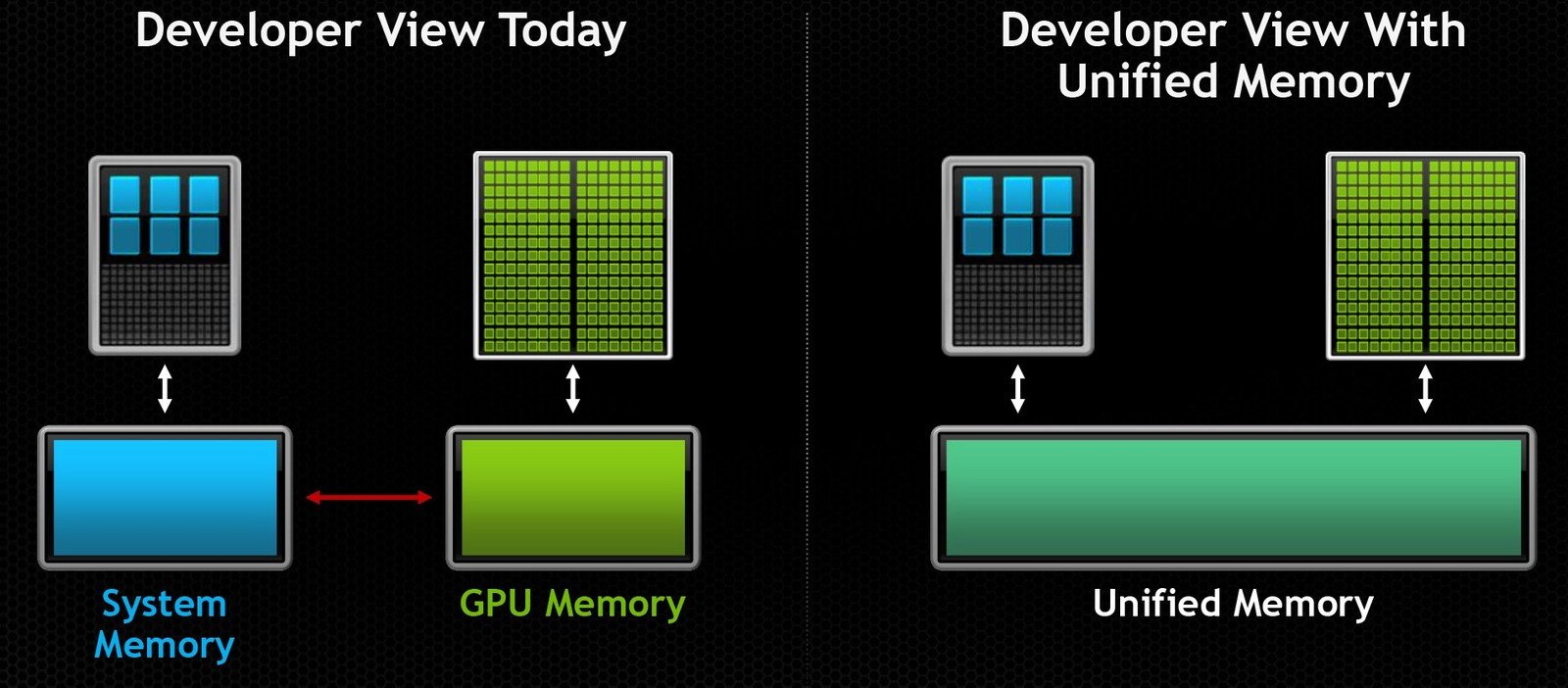

cudaMallocManaged(&data, N);