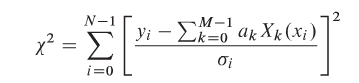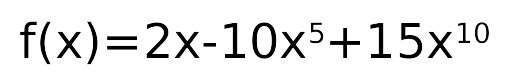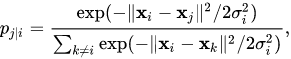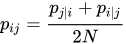Introduction to Machine Learning
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
PHYS188/288: Bayesian Data Analysis And Machine Learning for Physical Sciences
Uroš Seljak
Delivered today by Francois Lanusse
Follow along at https://slides.com/eiffl/intro2ml/live
From some input x, output can be:
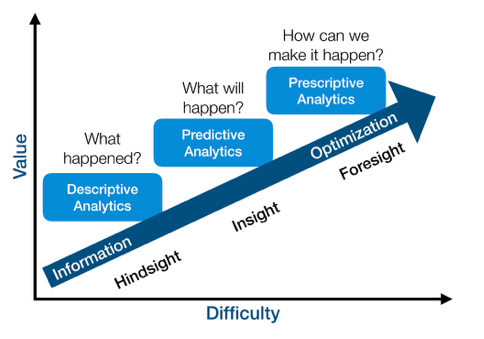
Value vs difficulty (although this view is subjective)
We have some data x and some labels y, such that Y=(x,y). We wish to find some model G(a) and some loss function C(Y, G(a)) that we wish to minimize such that the model explains the data Y.
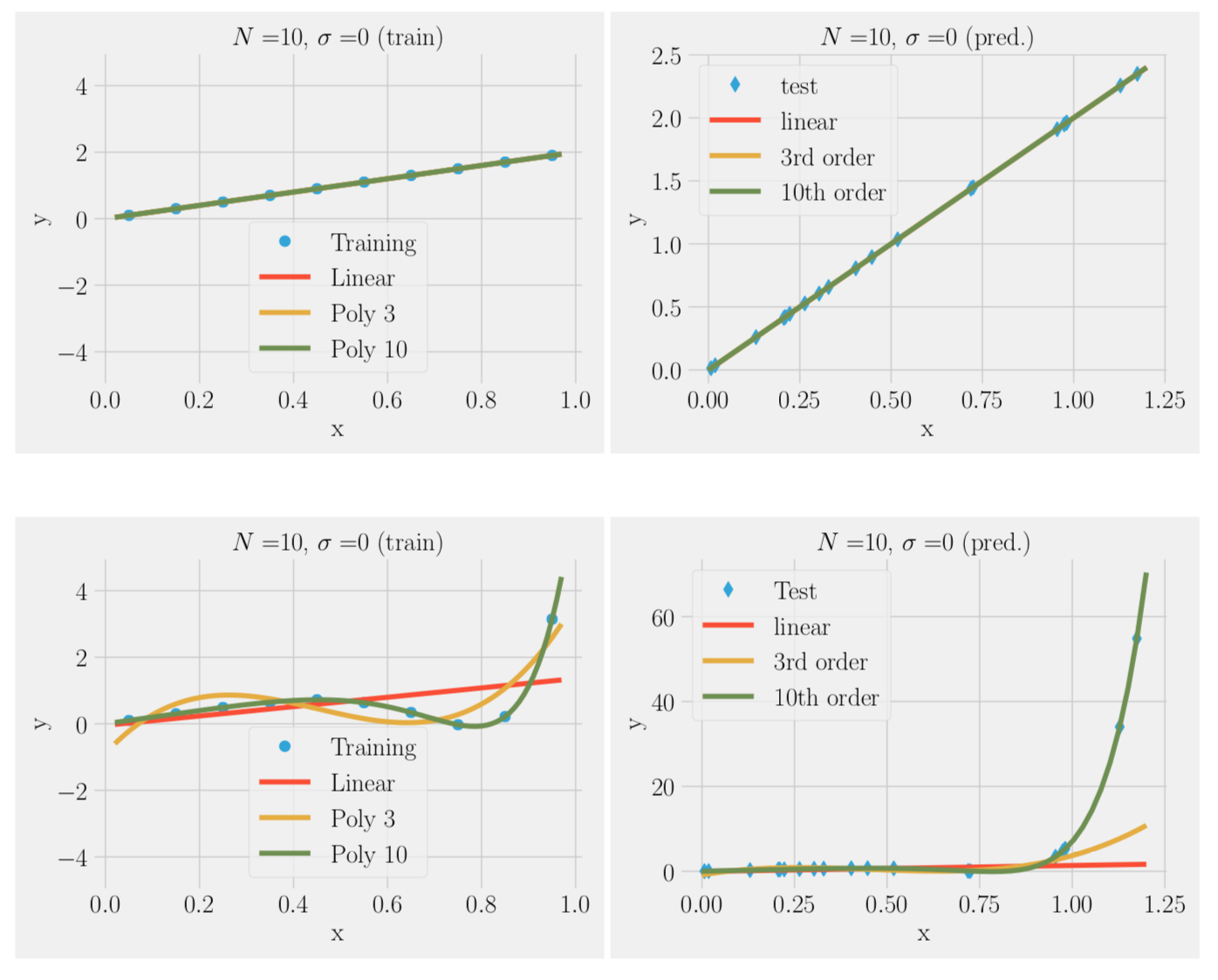
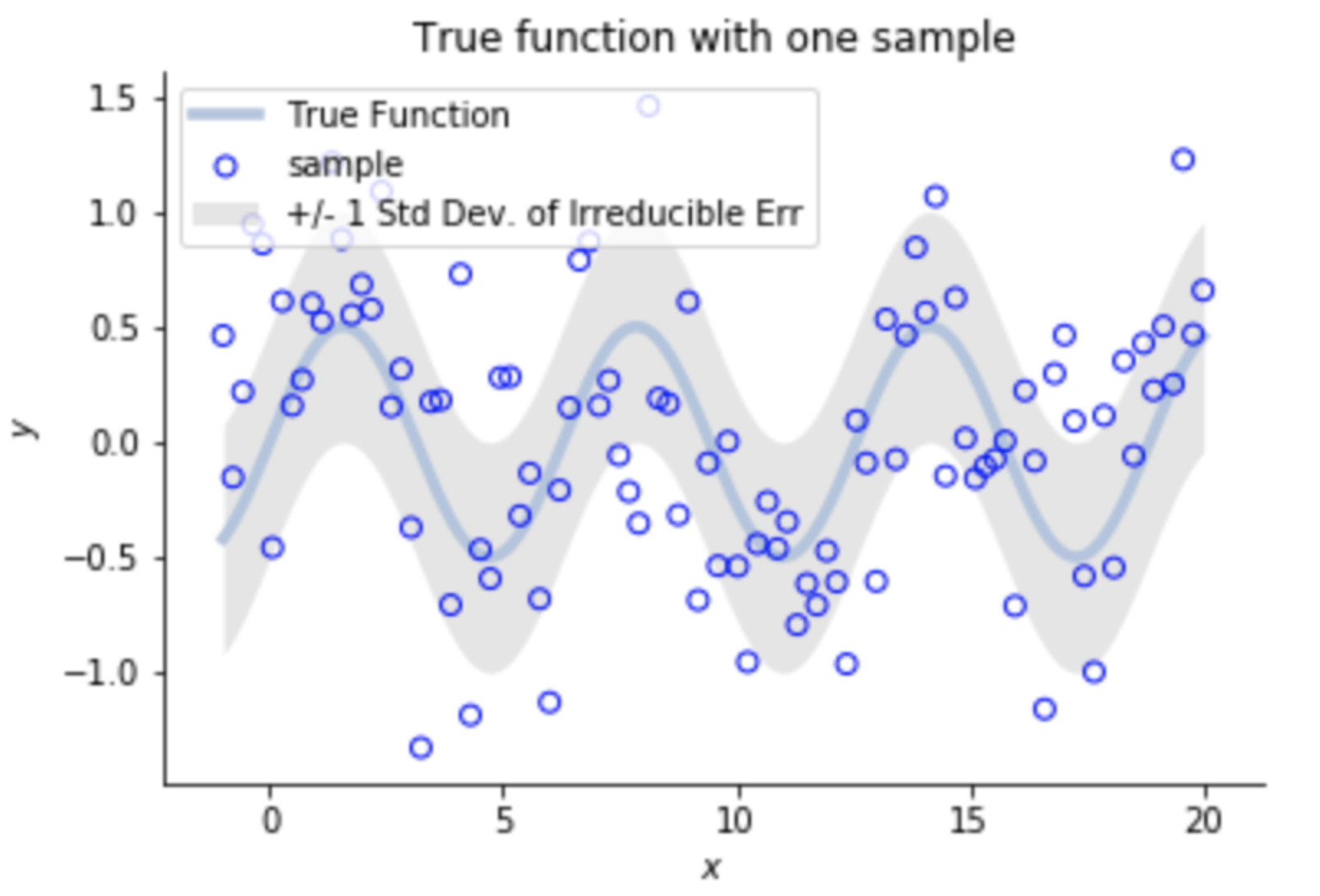
f(x) = 2x, no noise
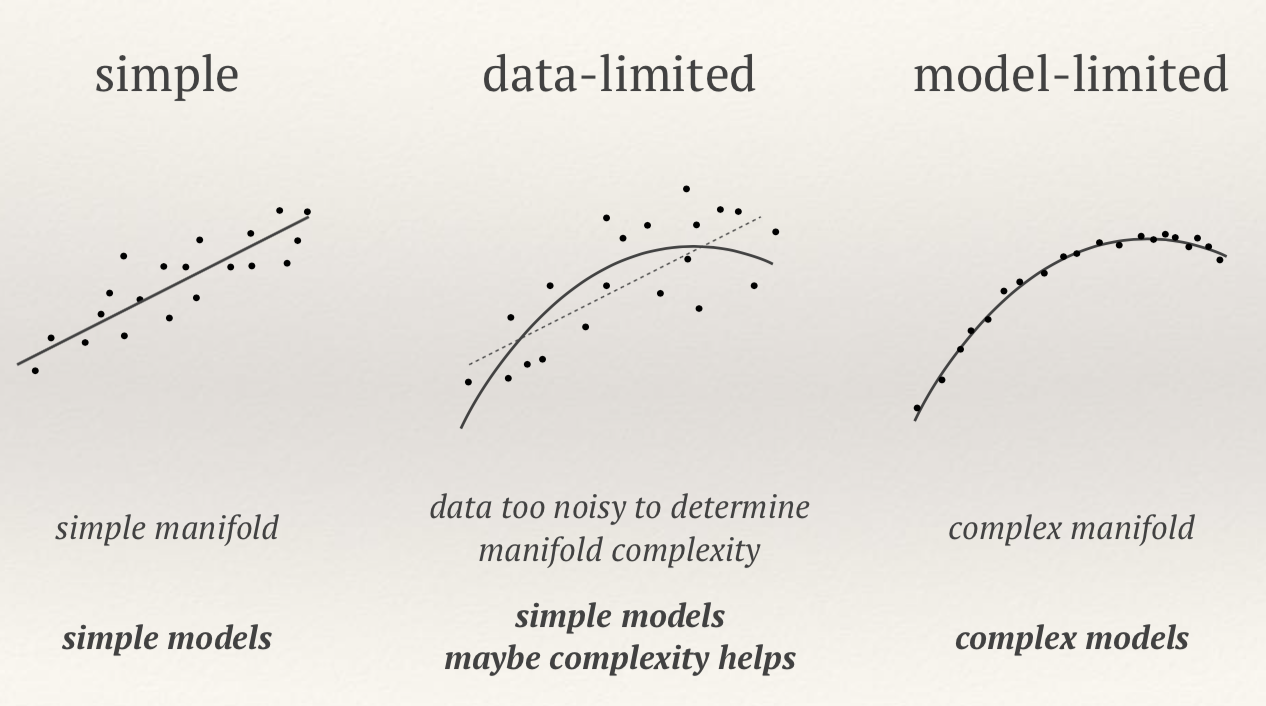
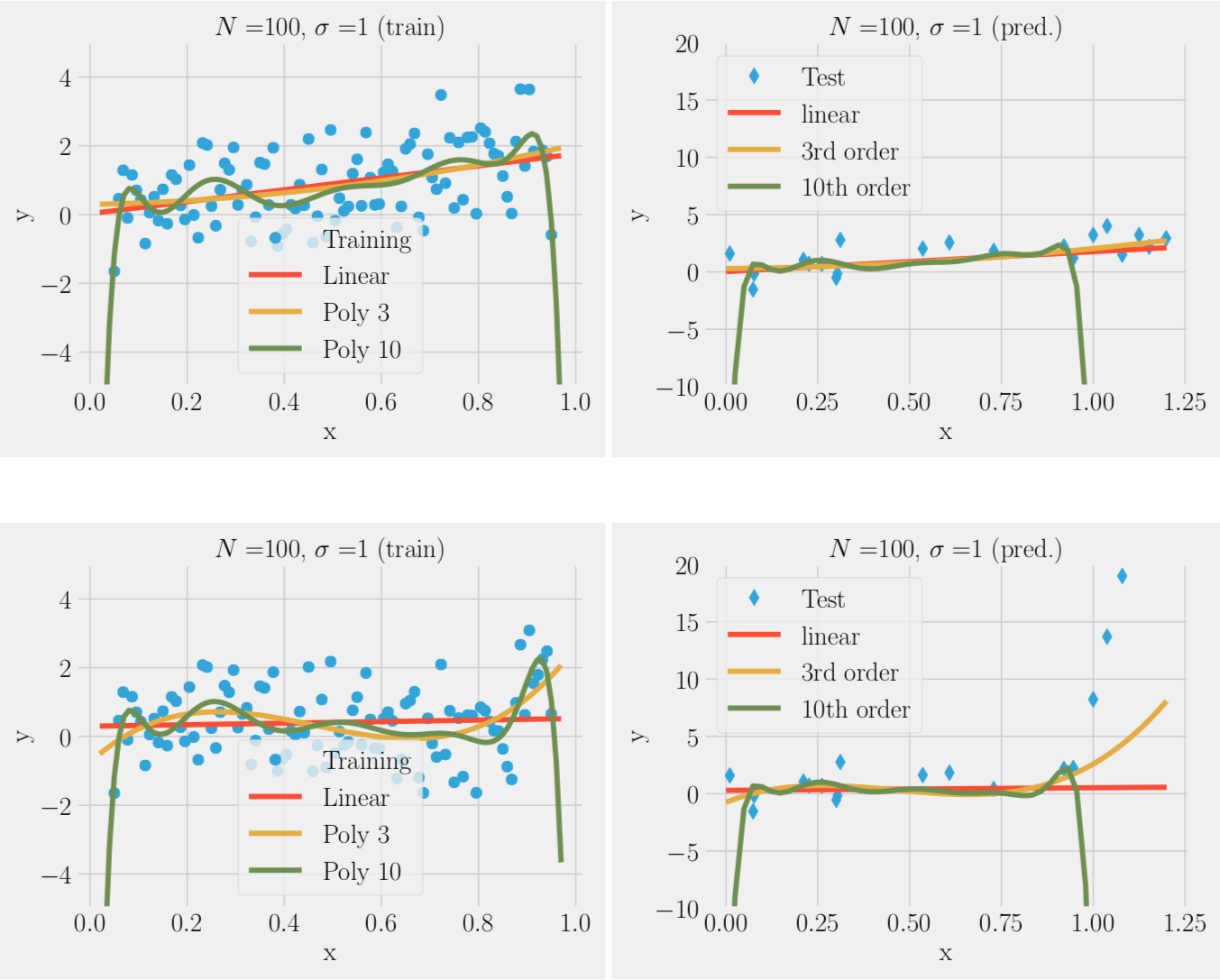
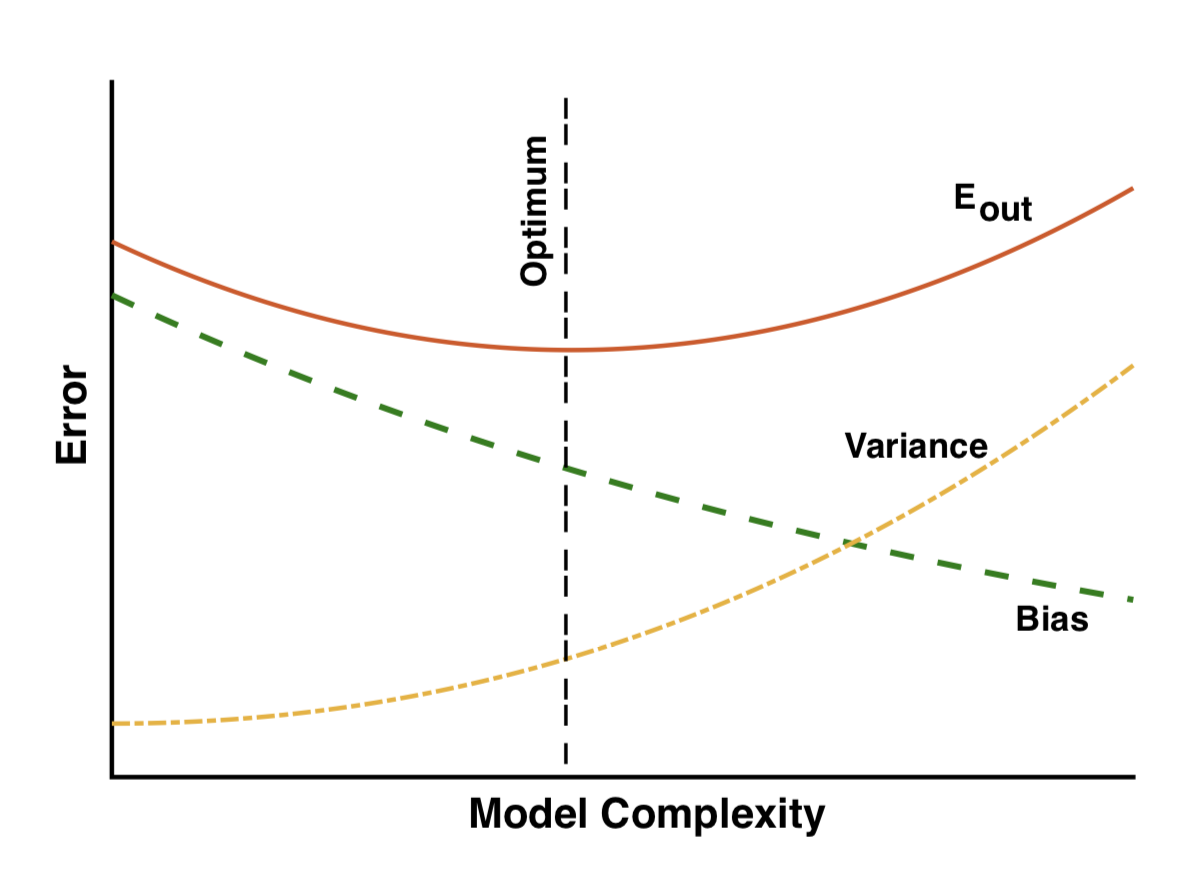
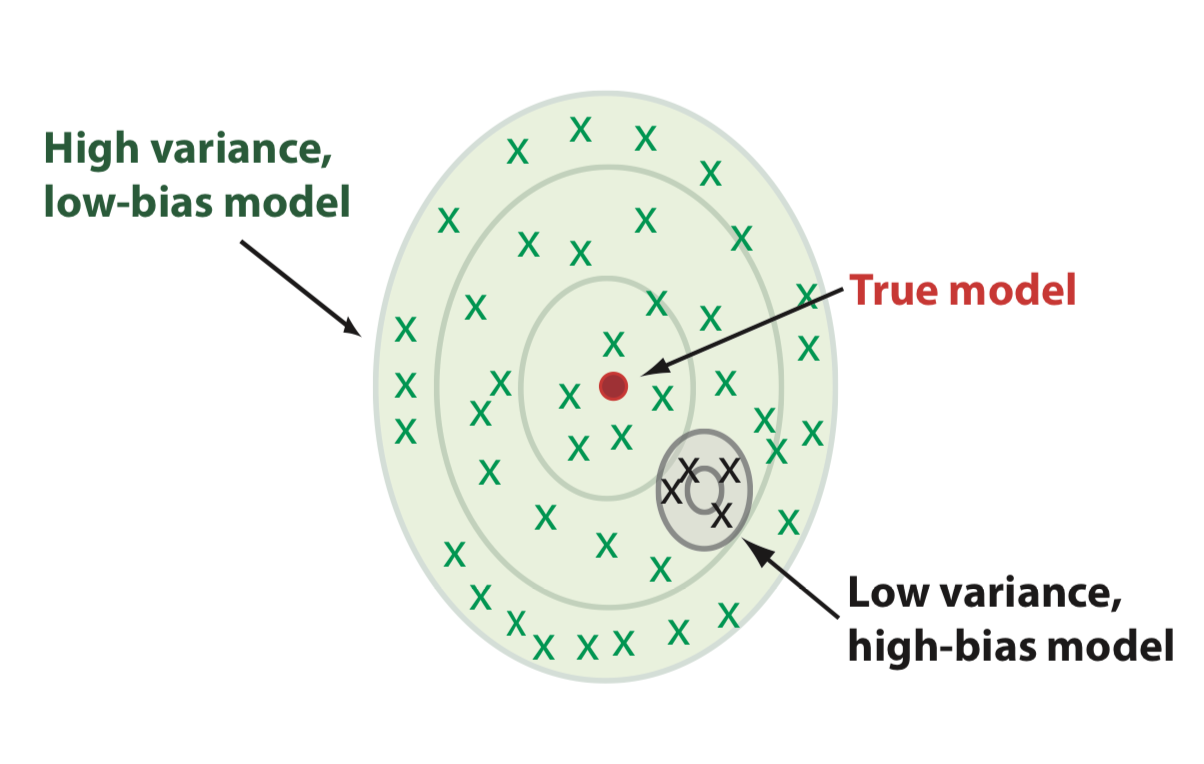
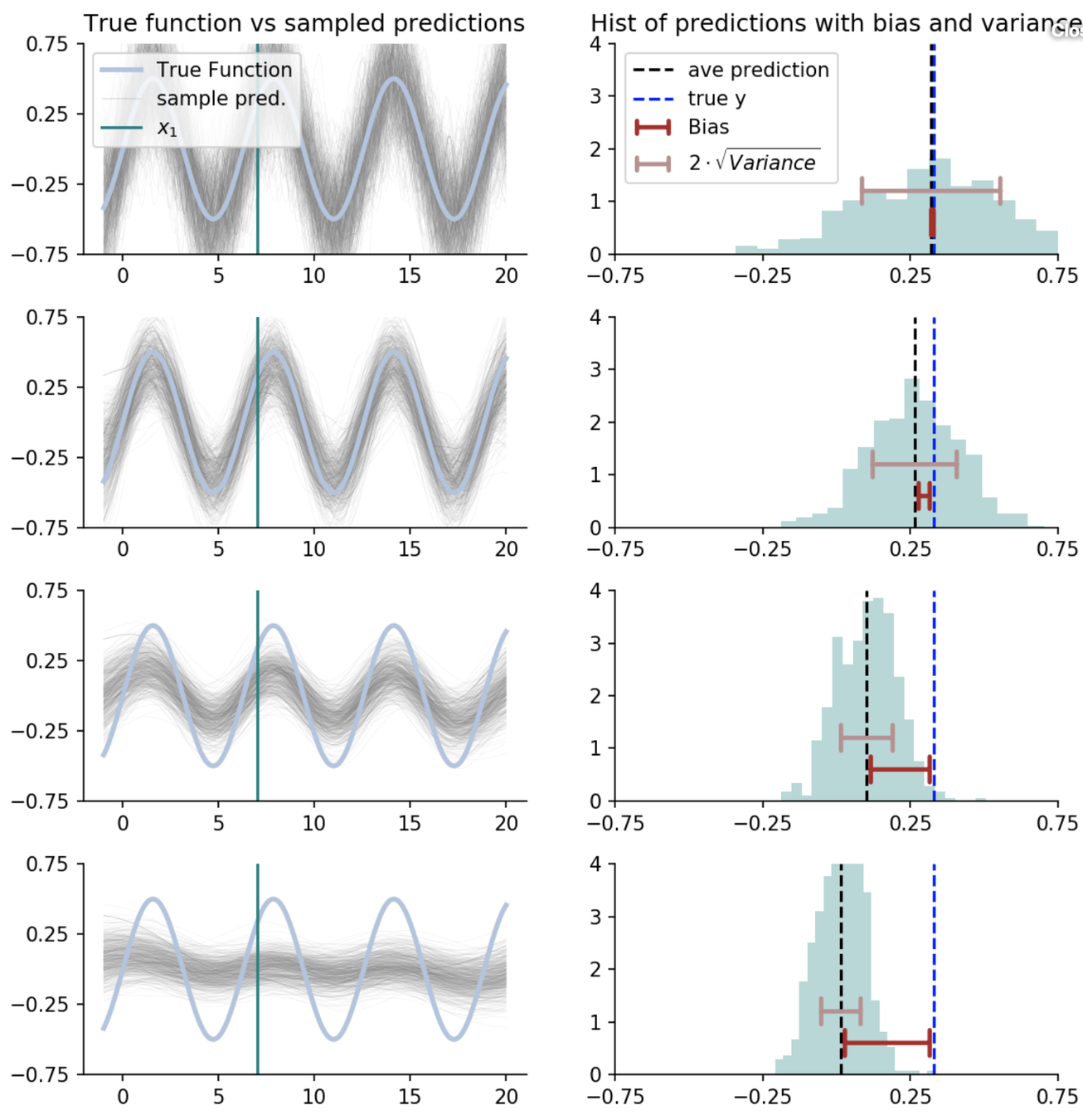
Over-fitting noise with too complex models (bias-variance trade-off)
Let's model the data as:
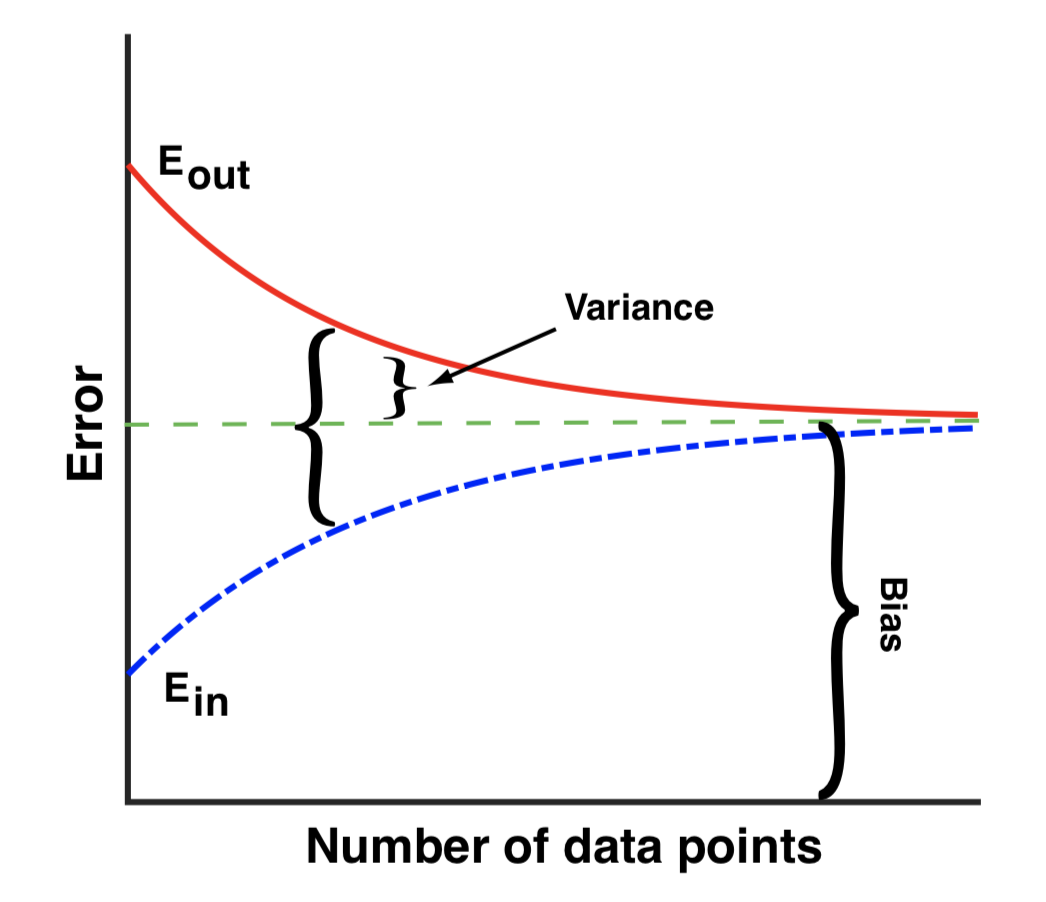
Irreducible Error
Bias²
Variance
In ML we divide data into training data Y_train (e.g. 90%) and test data Y_test (e.g. 10%)
We fit model to the training data: the value of the minimum loss function at a_min is called:
in-sample error E_in=C(Y_train,g(a_min))
We test the results on test data, getting:
out of sample error E_out=C(Y_test,g(a_min)) > E_in
This is called cross-validation technique
If we have different models then test data are called validation data while test data are used to test different models, each trained on training data (3 way split, e.g. 60%, 30%, 10%)
We can fit the training data to a simple model or complex model:
How predictions change as we average over more nearest neighbours?
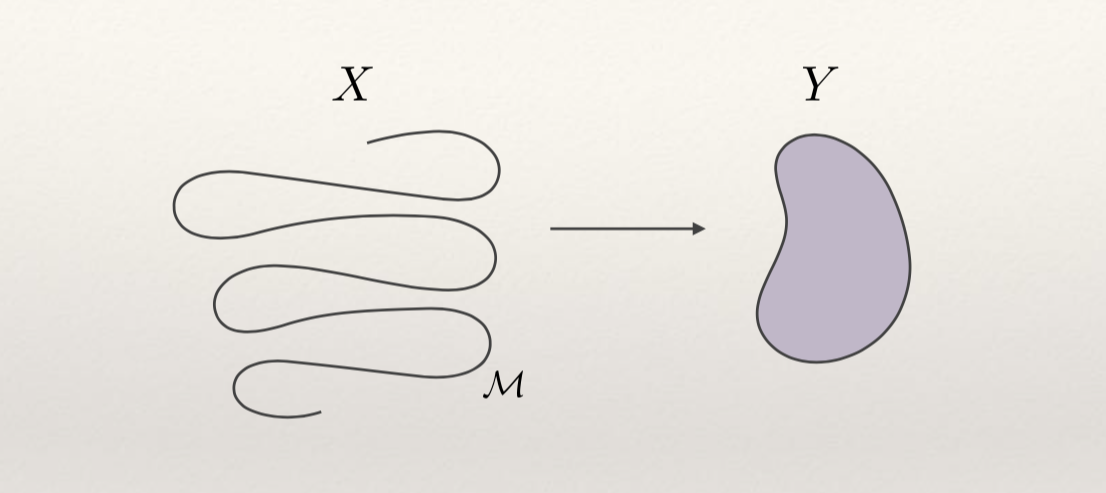
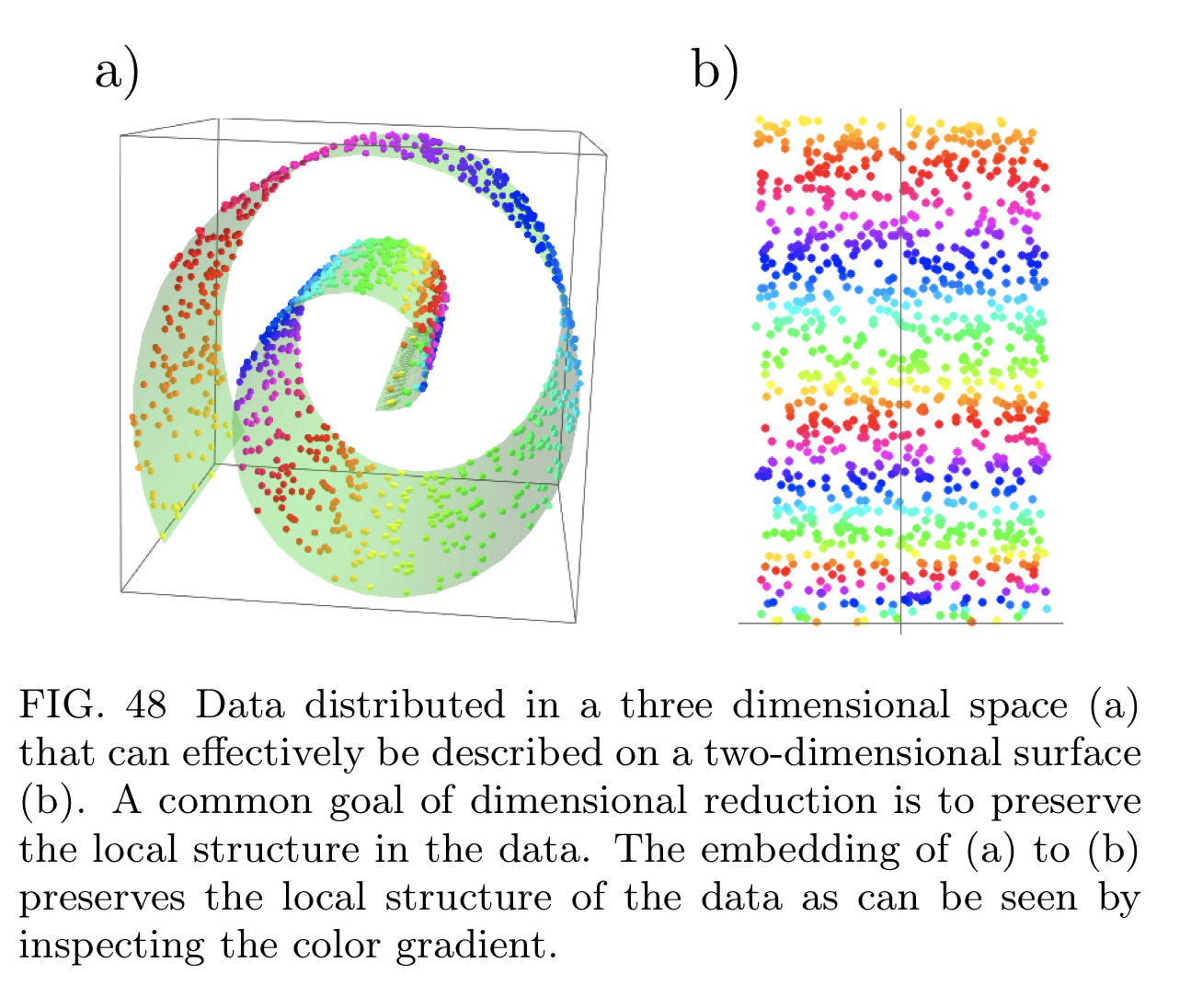
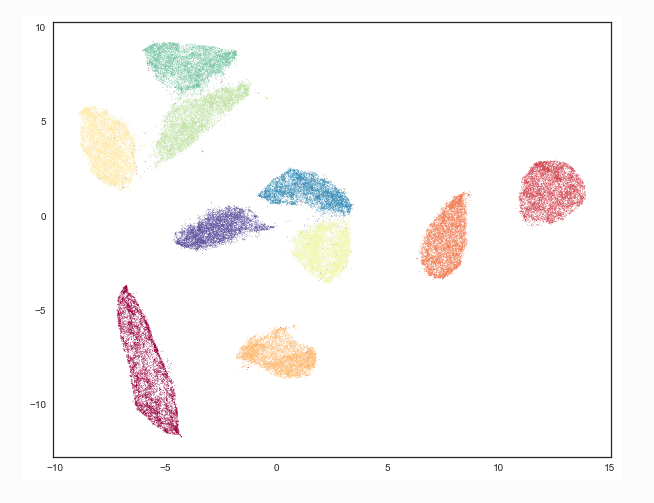
We are learning a manifold M
To learn complex manifolds we need high representational power
We need a universal approximator with good generalization properties (from in-sample to out of sample, i.e. not over-fitting)
This is where neural networks excel: they can fit anything (literally, including pure noise), yet can also generalize
Main idea:
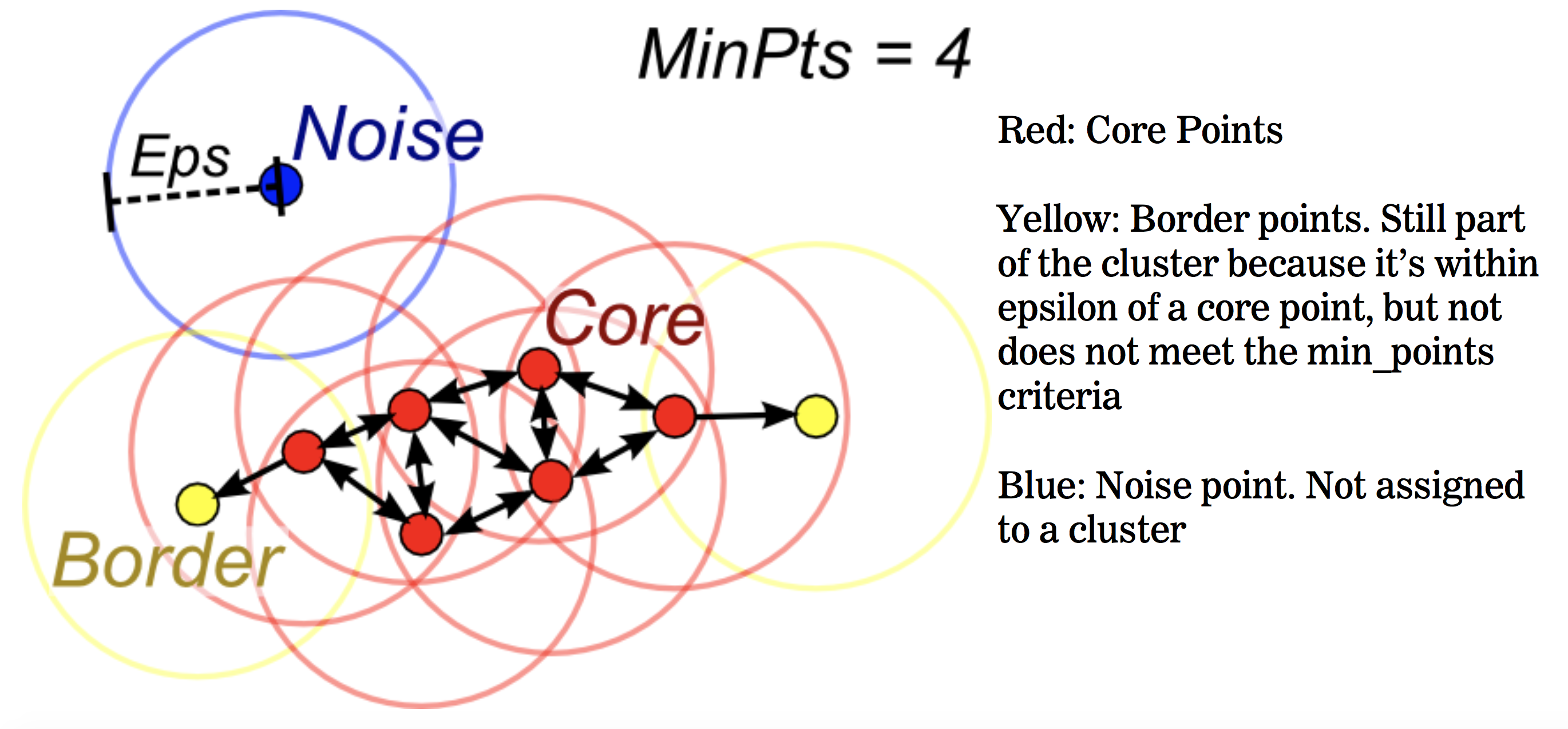
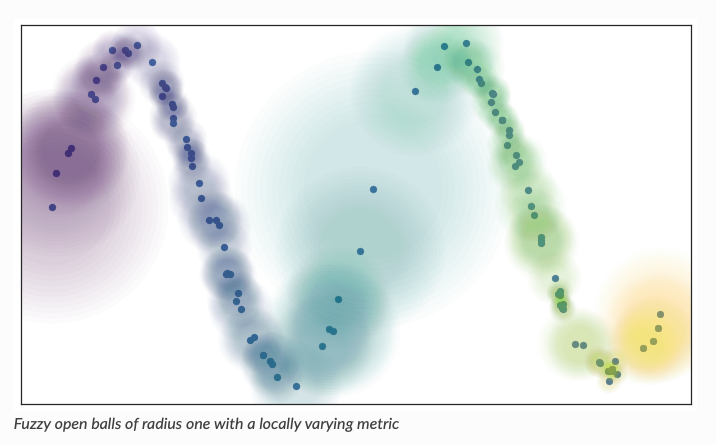
How do we measure this density?
Algorithm outline:
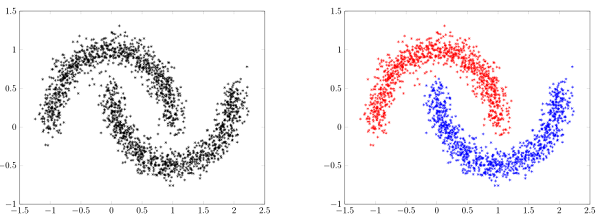
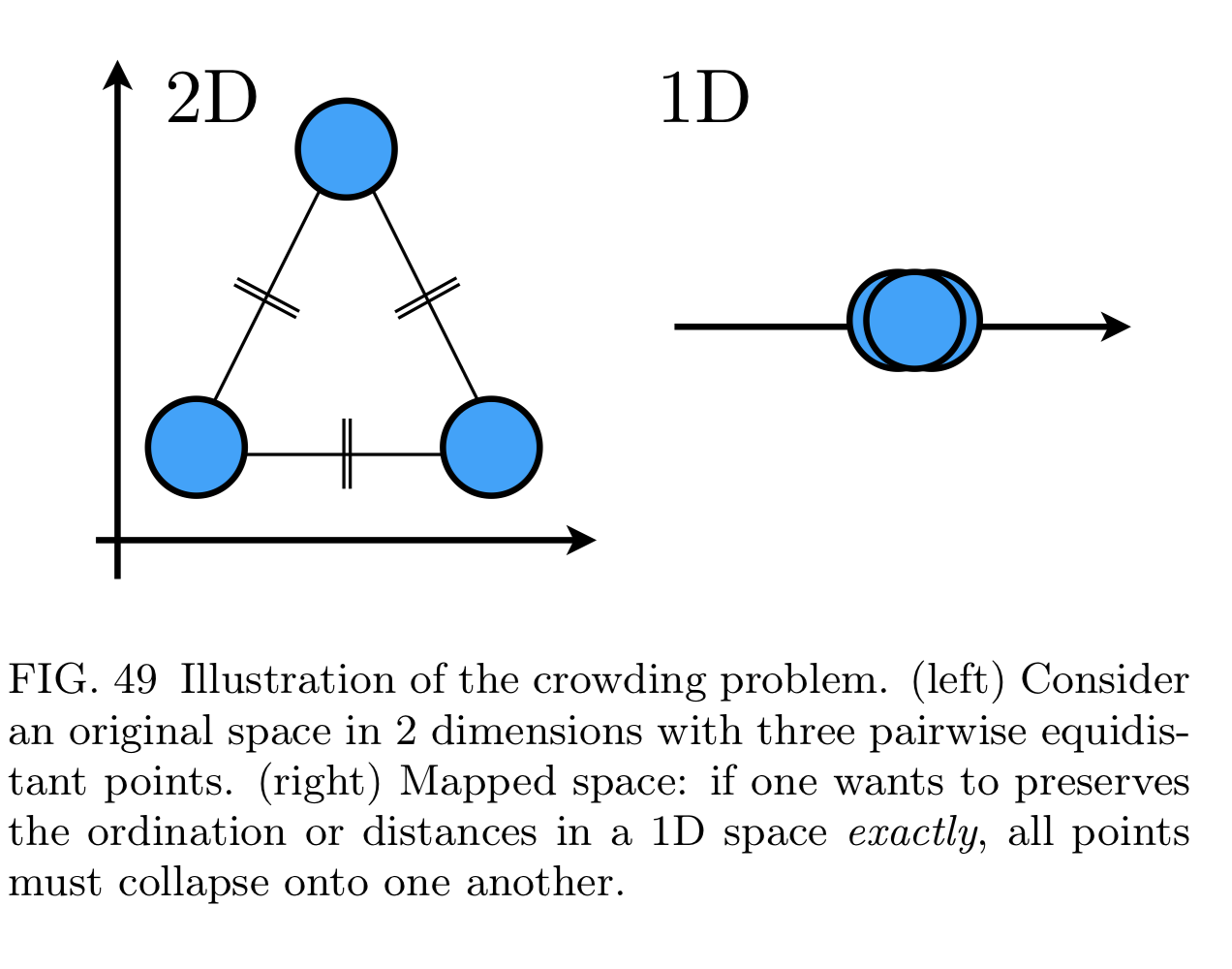
What do we want for good dimensionality reduction?