Presented by: Elaheh Barati
elaheh@wayne.edu
Wayne State University
Multi-view CNN for Face Verification in Videos
Objective:
- Our goal is to perform video based face verification using a stream based CNN
Face
Verification

Face Verification System
Same or Not?


Video-based Face Verification
feed a video as a
sequence of frames
feed video directly into the ConvNets as an input
Video-based Face Verification
feed a video as a
sequence of frames
feed video directly into the ConvNets as an input
Combine information from a sequence of frames using a CNN architecture with stream pooling and fully connected layers.
Our approach:
Data Pre-processing:
- Face Detection
- Face Tracking
[1] Zhang, Kaipeng, Zhanpeng Zhang, Zhifeng Li, and Yu Qiao. "Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks." IEEE Signal Processing Letters 23, no. 10 (2016): 1499-1503.
[1]

original
Positive
Negative
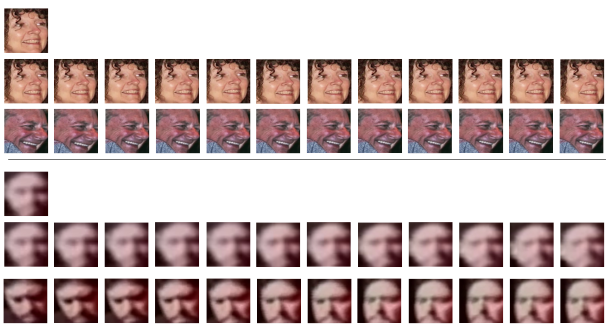
Original
Positive
Negative
Original
Positive
Negative
Video Face DataSet
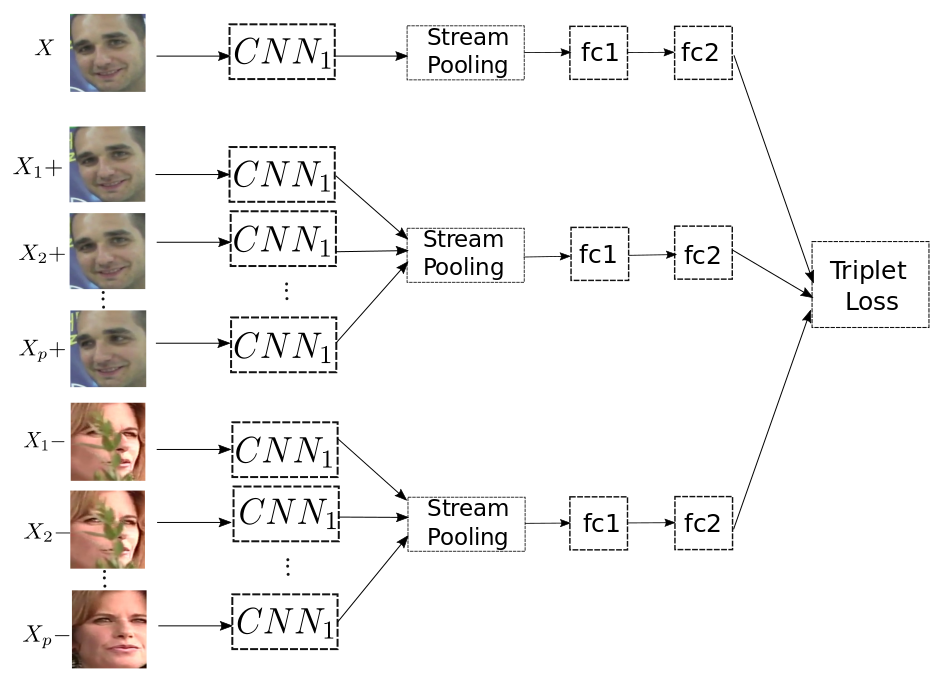
Network Architecture
CNN1:
-
Alex-Net Architecture
- input size : 227 x 227
- Initialize the weights of convolutional layers with the weights from Alex-Net model which was trained on the ImageNet
Triplet Loss:
The Triplet Loss minimizes the distance between an anchor and a positive, both of which have the same identity, and maximizes the distance between the anchor and a negative of a different identity
Works to be done
- Train with more data
- IJB-A dataset
- Video to video face verification
- Testing on 3D face images
