TextBlob:
Procesamiento de texto simplificado

¿Que Es TextBlob?
TextBlob es una biblioteca Python (2 y 3) para procesar datos textuales. Proporciona una API simple para sumergirse en tareas comunes de procesamiento de lenguaje natural (NLP), como etiquetado de parte del discurso, extracción de frases nominales, análisis de sentimientos, clasificación, traducción y más.
Características:
- Extracción de frases
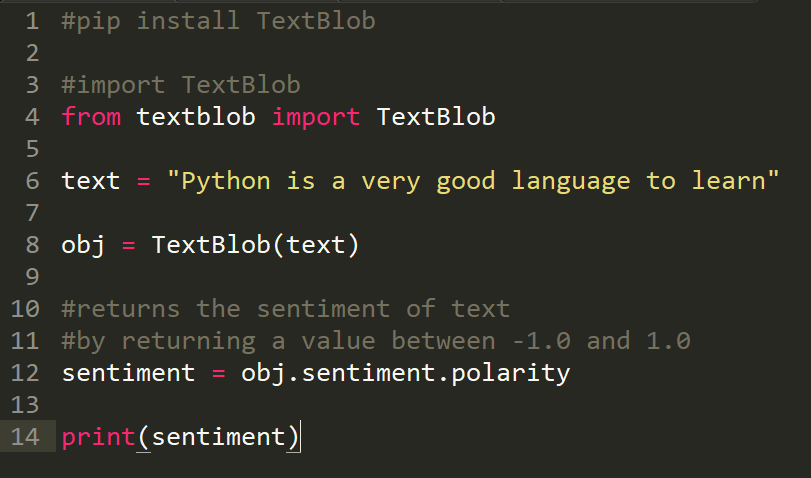
- Etiquetado de parte del discurso
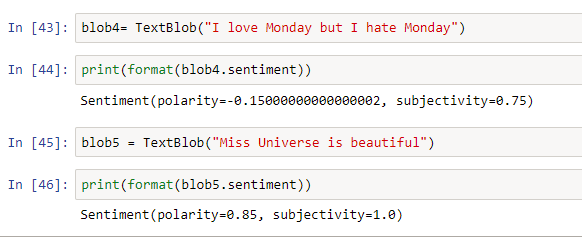
- Análisis de los sentimientos
- Clasificación (Naive Bayes, Árbol de decisiones)
- Traducción y detección de idiomas con Google Translate.
- Tokenización (división del texto en palabras y oraciones)
- Frecuencias de palabras y frases
- Análisis
- n-gramas
- Inflexión de palabras (pluralización y singularización) y lematización.
- Corrección ortográfica
- Añadir nuevos modelos o idiomas a través de extensiones.
- Integración de WordNet

Instalación:
$ pip install -U textblob
$ python -m textblob.download_corporaInstalando / Actualizando desde el PyPI
Esto instalará TextBlob y descargará los cuerpos necesarios de NLTK. Si necesita cambiar el directorio de descarga predeterminado, establezca la NLTK_DATAvariable de entorno.
TextBlob se desarrolla activamente en Github .
Puedes clonar el repositorio público:
git clone https://github.com/sloria/TextBlob.gitImplementacion:
from textblob import TextBlob
Una vez que lo tengamos instalado, lo implementamos en nuestro código de la siguiente manera:
En este caso importamos nuestro modulo previamente instalado, haciendo referencia a el como "TextBlob", y de esta manera python sabrá que vamos a trabajar con dicho modulo.
Ejemplo Básico de Traducción:
from textblob import TextBlob
eb=TextBlob('HELLO WORLD')
una vez importado nuestro modulo, crearemos en este caso un objeto donde almacenaremos el texto a traducir:
Ahora vamos a imprimir directamente el texto de nuestro objeto ya traducido utilizando el argumento "translate" propio del modulo utilizado definiendo cual es el lenguaje del texto introducido y a que lenguaje deseamos traducirlo, en este caso de ingles a español (en-es)
from textblob import TextBlob
eb=TextBlob('HELLO WORLD')
print (eb.translate(from_lang='en', to='es'))Resultado:
Una vez que ejecutemos nuestro codigo en nuestro IDE favorito o directamente en la terminal de python observaremos el resultado final, en este caso yo utilizo THONNY IDE

Como podemos observar el programa se ejecuto sin ningun error y nos arrojo el resultado de nuestro texto traducido del ingles al español
¿Que pasa si no sabemos que lenguaje es el que vamos a traducir?
TextBlob Cuenta con una herramienta diseñada para detectar que lenguaje es el que le estamos introduciendo, y lo podemos implementar de la siguiente manera:
En este caso utilizaremos el argumento "detect_language" propio del modulo, cuya funcion es realizar la detección del lenguaje que se esta introduciendo, tal y como veremos a continuación.
from textblob import TextBlob
eb=TextBlob('Meu coraçao bate feliz quando te ve.')
print (eb.detect_language())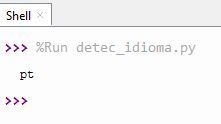
Como podemos observar, nos arroja la palabra "pt" que hace referencia al portugues
Ahora vamos a traducir un Archivo de texto :
Primero que nada debo comentarles que esto solo funciona para archivos de texto en formato (.txt) aunque es bastante efectivo si quieres traducir algo de manera rápida y sencilla.
Importamos nuevamente nuestro modulo, y ahora para abrir un archivo en python utilizaremos el objeto "file=open" y lo leeremos con "file.read" como se observa en el siguiente ejemplo:
from textblob import TextBlob
file=open('text.txt')
t=file.read()
print(t)
trad=TextBlob(t)
print (trad.translate(from_lang='en', to='es'))
NOTA: EL ARCHIVO A TRADUCIR DEBE ESTAR ADENTRO DE LA CARPETA EN LA QUE ESTAMOS TRABAJANDO O BIEN ESPECIFICAR LA RUTA DEL ARCHIVO.
Resultado:
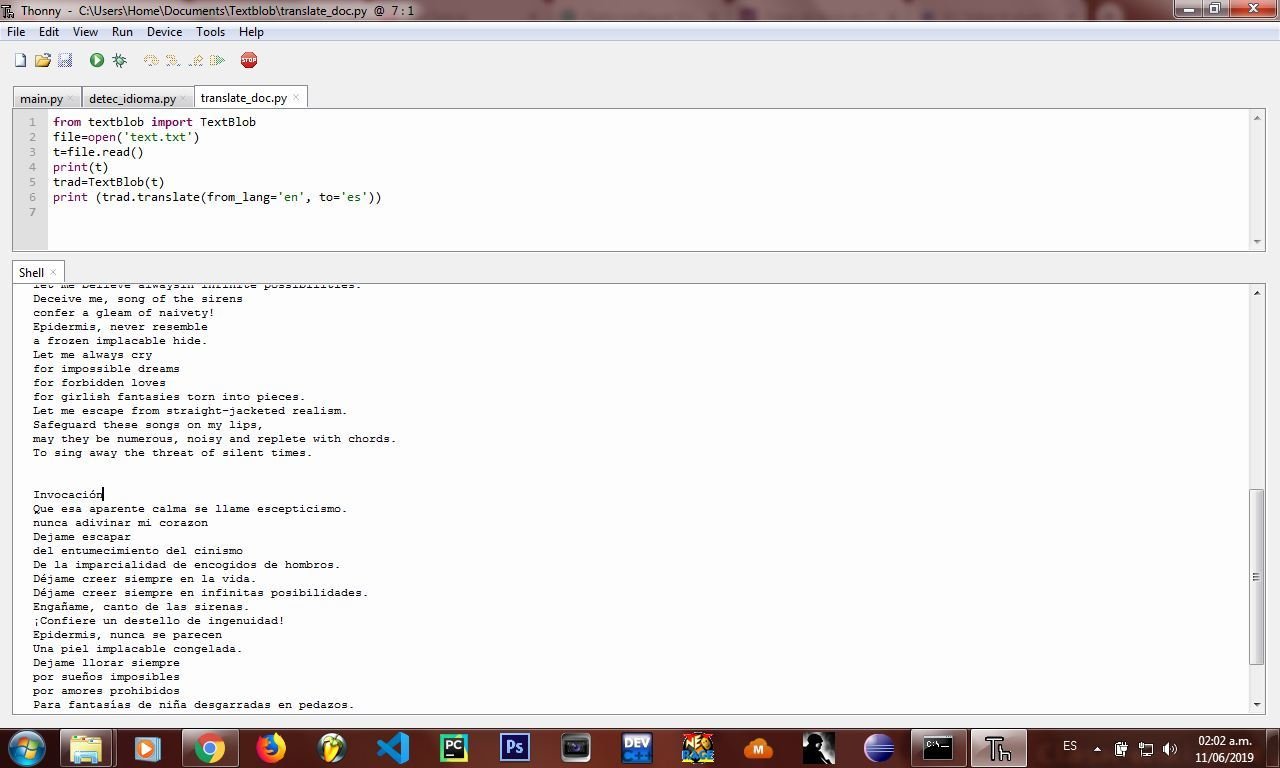
Como podemos observar, se imprime nuestro texto original y nuestro texto ya traducido, en este caso de ingles a español.
Para saber mas de este modulo puedes visitar:
Muchas Gracias

ISC. JUAN LUIS ORDOÑEZ PEREZ
@UNTALMAPAYORK
@ISC_JLOP
ISC. JUAN LUIS ORDOÑEZ PEREZ

@ISC JUAN LUIS