awk|grep|sed
and enough regular expressions to get you in trouble.
DSST Lunch & Learn
Thursday, March 10, 2022
History
grep
global search regular expression print (g/re/p)
1973
1974
sed
stream editor
1977
awk
A. Aho
P. Weinberger
B.W. Kernighan
# history
# regex
Regular expression
A pattern describing a certain amount of text where the engine stops after the first appearance of a match.
- a.k.a. "regex", "re", or "regexp"
- Exact rules
- Big possibilities

Literal Characters
# regex
- The most basic regular expression consists of a single literal character, such as a. It matches the first occurrence of that character in the string.
- If the string is Jack is a male, it matches the a after the J.
Non-Printable Characters
# regex
- You can use special character sequences to put non-printable characters in your regular expression.
- \t will match a tab character
- \r will match a carriage return
- \n will match a line feed
Character Class
# regex
- Matches only one out of several characters. To match an a or an e, use [ae]. You could use this in gr[ae]y to match either gray or grey. The order of the characters inside a character class does not matter.
- You can use a hyphen inside a character class to specify a range of characters. [0-9] matches a single digit between 0 and 9. You can use more than one range. [0-9a-fA-F] matches a single hexadecimal digit, case insensitively.
- Typing a caret ^ after the opening square bracket negates the character class. The result is that the character class matches any character that is NOT in the character class. q[^x] matches qu in question.
Shorthand Character Sets
# regex
- \d matches a single character that is a digit
-
\w matches a “word character”
- alphanumeric characters plus underscores
-
\s matches a whitespace character
- includes tabs and line breaks
Dot Matches Most Any Character
# regex
- The dot . matches a single character, except line break characters.
- gr.y matches gray, grey, gr%y, etc.
Anchors
# regex
- Anchors do not match any characters. They match a position.
- ^ matches at the start of the string
- $ matches at the end of the string
Alternation
# regex
- The regular expression equivalent of “or”.
- cat|dog matches cat in About cats and dogs
- If the regex is applied again, it matches dog
- You can add as many alternatives as you want
- cat|dog|mouse|fish
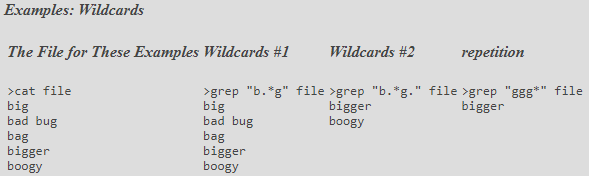
Repetition ? * + { }
# regex
- Question mark ? makes the preceding token in the regular expression optional. colou?r matches colour or color.
- Asterisk * matches the preceding token zero or more times
- Plus + matches the preceding token once or more
- [A-Za-z][0-9]* matches any letter followed by zero or more numbers like Q or Q17
- [A-Za-z][0-9]+ matches any letter followed by one or more numbers like r705, but not just f
- Curly braces { } specify a specific amount of repetition
- [0-9]{3} matches three digits in a row between 000 and 999
- [1-9][0-9]{2,4} matches a number between 100 and 99999
Greedy Repetition
# regex
- The repetition operators are "greedy". They expand the match as far as they can, and only give back if they must to satisfy the remainder of the regex.
- The regex <.+> matches <EM>first</EM> within the string This is a <EM>first</EM> test
Grouping and Backreferences
# regex
- Place parentheses around multiple tokens to group them together
- You can use the backreference \1 to match the same text that was matched by the first capturing group
- ([abc])=\1 matches a=a, b=b, and c=c. It does not match anything else
- If your regex has multiple capturing groups, they are numbered counting their opening parentheses from left to right
Read more at
# regex
awk '{print $1}' file
Print the first (1-indexed) column in the file "file".
awk -F , '{print $3}' some.csv
Everyday awk
# awk
> ls -l
total 594356
-rwxr-x--- 1 earlea users 150314498 Feb 15 16:56 abcd_fastqc01_reformatted.csv
-rw-r--r-- 1 earlea users 309218172 Feb 24 13:57 abcd_fastqc01.txt
drwxrwx--- 7 earlea users 4096 Feb 15 16:47 BIDS
-rw-r--r-- 1 earlea users 149070377 Aug 27 2021 fmriresults01.txt
-rw-rw---- 1 earlea users 2044 Oct 5 15:39 fmriresults01.txt.header
-rw-rw---- 1 earlea users 1938 Oct 5 15:40 fmriresults01.txt.NDAR_INV1L1ZCWL5
> ls -l | awk '{print $9}'
abcd_fastqc01_reformatted.csv
abcd_fastqc01.txt
BIDS
fmriresults01.txt
fmriresults01.txt.header
fmriresults01.txt.NDAR_INV1L1ZCWL5-F value
# awk
- Sets the "field separator", FS, to "value".
- Uses whitespace by default
- Use , for CSV files
- Use \t for TSV files
awk -F \t '{print $1","$2}' file.tsv
# awk
- Output the first field, a comma, and then the second field for all lines from a tab-separated value file
- There are many more ways to use the awk language
- like here: https://en.wikibooks.org/wiki/An_Awk_Primer
grep foo file
Returns all the lines that contain a string matching the expression "foo" in the file "file".
cat file | grep foo > newfile
# grep
Everyday grep
Note the original on the left.
grep -r and -n options
# grep
- -r, --recursive
- Read all files under each directory, recursively, following symbolic links only if they are on the command line.
- -n, --line-number
- Prefix each line of output with the 1-based line number within its input file.
grep "OR" behavior with -v and -e
# grep
> head -n 3 datasets.txt
ds000001
ds000002
ds000003
> wc -l datasets.txt
640 datasets.txt
> grep 3 datasets.txt | wc -l
339
> grep -v 3 datasets.txt | wc -l
301
> grep -e 3 -e 4 datasets.txt | wc -l
434
> grep -v -e 3 -e 4 datasets.txt | wc -l
206grep "AND" behavior using pipes
# grep
> head -n 3 datasets.txt
ds000001
ds000002
ds000003
> wc -l datasets.txt
640 datasets.txt
> grep 3 datasets.txt | wc -l
339
> grep 3 datasets.txt | grep 4 | wc -l
107
> grep 3 datasets.txt | grep -v 4 | wc -l
232sed 's|find|replace|g' file
Finds all regular expression matches for "find" and replaces them with "replace" in the file "file".
cat file | sed 's|a|b|g' > newfile
Everyday sed
# sed
> cat file I have three dogs and two cats > cat file | sed 's|dog|cat|g' I have three cats and two cats
sed -i option
# sed
- Edit files in-place (else sends result to stdout).
- This is a great way to update or change files without ever opening them.
sed delimiters / | : _
# sed
- Any of these delimiters are fine.
sed group matching
# sed
> cat file
I have three dogs and two cats
> cat file | sed 's|.\+\(...s\).\+\(...s\)|\1 \2|g'
dogs cats
Command chaining with the pipe
> head -n 1 abcd_fastqc01_reformatted.csv
collection_id,abcd_fastqc01_id,dataset_id,pGUID,src_subject_id,interview_date,SeriesTime,sex,img03_id,origin_dataset_id,EventName,image_file,ftq_series_id,ABCD_Compliant,ftq_complete,ftq_quality,ftq_recalled,ftq_recall_reason,QC,ftq_notes,collection_title,image_description,image_timestamp
> head -n 1 abcd_fastqc01_reformatted.csv | awk -F, '{print $22}'
image_description
> tail -n +2 abcd_fastqc01_reformatted.csv | awk -F, '{print $22}' | sort -u | head -n 5
ABCD
ABCD-Coil-QA
ABCD-Diffusion-FM
ABCD-Diffusion-FM-AP
ABCD-Diffusion-FM-PA
> tail -n +2 abcd_fastqc01_reformatted.csv | awk -F, '{print $22}' | sort -u | grep -v -e "ABCD\$" -e QA | head -n 3
ABCD-Diffusion-FM
ABCD-Diffusion-FM-AP
ABCD-Diffusion-FM-PA
> tail -n +2 abcd_fastqc01_reformatted.csv | awk -F, '{print $22}' | sort -u | grep -v -e "ABCD\$" -e QA | sed 's|ABCD-||g' | head -n 3
Diffusion-FM
Diffusion-FM-AP
Diffusion-FM-PA# awk|grep|sed
- AT&T Bell Laboratories
- www.regular-expressions.info
- www.grymoire.com
- www.panix.com/~elflord
Special Thanks
