Espresso AI
Faster, Cheaper, Easier: Choose 3-
Automatically Optimize dbt at Scale
Overview
Overview
- Why we're working on optimizing dbt
- Automatic Query Incrementalization
- dbt Job Scheduling
Who am I?
# Overview
- One of the founders of Espresso AI. We use machine learning to automatically optimize Snowflake
- I used to work on systems performance at Google Cloud, ML at Google Search, and I’ve done research on RL for systems performance optimization with DeepMind.
# Overview
Why Snowflake?
- Snowflake costs are one of today's top IT line items - and growing fast
- We're saving customers up to 70% on their Snowflake bills.
# How it works
How does it work?
- We have a warehouse optimization agent that manages cluster autoscaling. It accesses Snowflake through a Snowflake account.
- Our dbt-specific features use a SQL proxy. The proxy lets us route and optimize queries on the fly.
# How it Works
Why are we focusing on dbt?
# Why dbt?
- dbt is the most popular tool across our customers
- We're working on dbt-specific optimizations to run dbt jobs faster and cheaper.
- We've found one super simple way to speed up dbt on Snowflake. Stay tuned!
# 1. Query Incrementalization
Query Incrementalization
Query Incrementalization
# Query Incrementalization
- You can run ELT jobs massively faster and cheaper by incrementalizing your queries.
- Incrementalizing means taking a query that processes an entire dataset and changing it to reprocess only new data for each run.
select * from {{ ref('events') }}
{% if is_incremental() %}
where event_time >= (select max(event_timestamp)::date from {{ this }})
{% endif %}# Query Incrementalization
Query Incrementalization Example
# Query Incrementalization
Automatic Query Incrementalization
This gets a lot more complicated.
- Joins
- Multiple Joins
- Aggregations
- Filters
- Subqueries
# Query Incrementalization
Automatic Query Incrementalization

# Query Incrementalization
dbt Microbatch incremental models
- Microbatch incremental models are a new dbt feature
- We can leverage microbatch annotations to help generate more complex incremental queries automatically
# Query Incrementalization
Q&A - Incrementalization
# Scheduling
Scheduling
# Scheduling
Scheduling
- dbt jobs produce a DAG of queries for your job
- There are many ways to execute to most DAGs
- We're using schedling theory to find faster execution plans (and maybe cheaper ones.)
# Scheduling
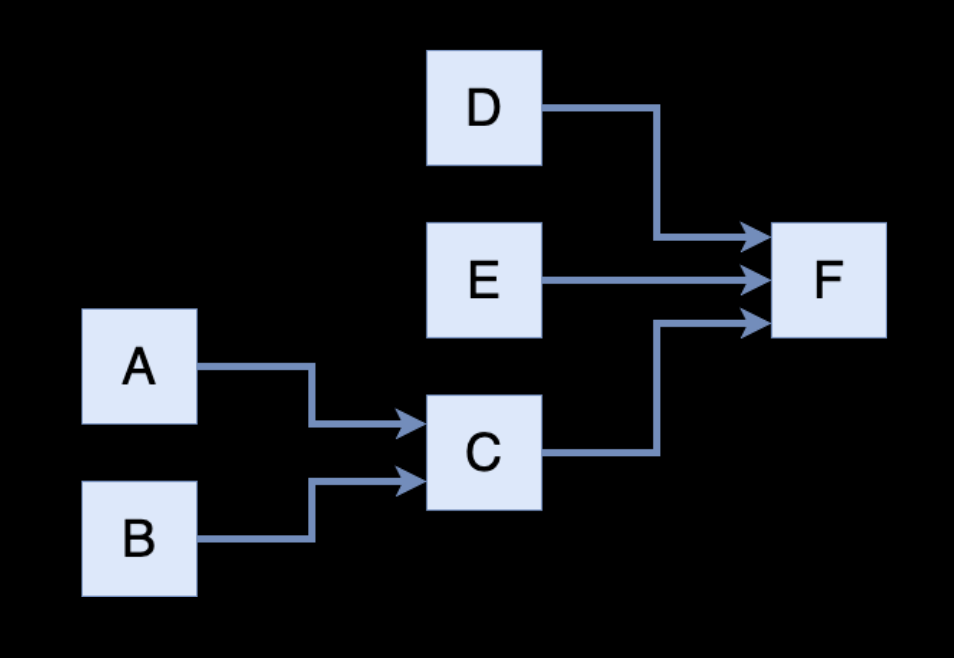
Scheduling - DAG
# Scheduling
Scheduling - DAG
# Scheduling
Scheduling
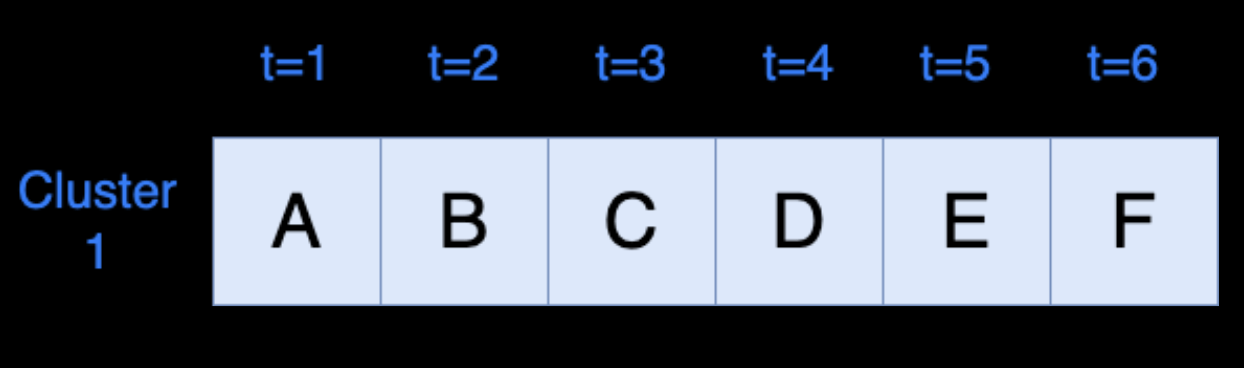
Default Snowflake Runtime:
6 minutes on 1 warehouse
# Scheduling
Scheduling - DAG
# Scheduling
Scheduling - DAG
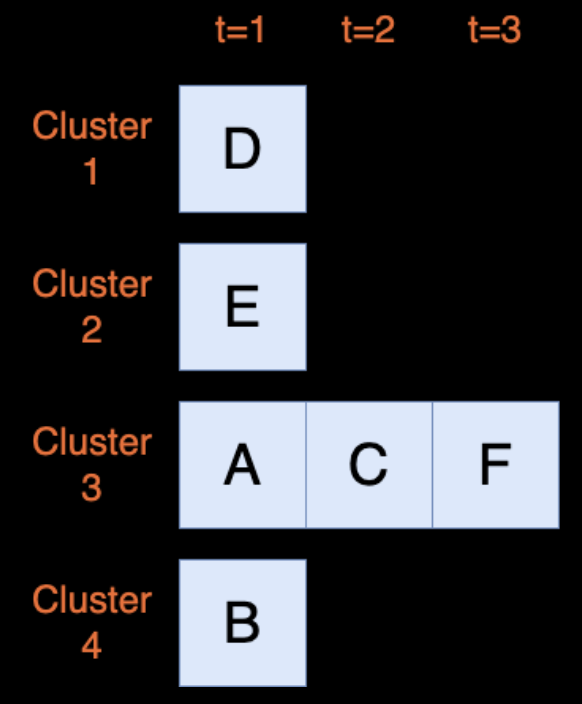
Optimized Runtime:
3 minutes on 4 clusters
# Scheduling
Scheduling - DAG
- De la Vega & Leuker
“Bin packing can be solved within 1 + ε in linear time
-
Békéski & Galambos
“A 5/4 Linear Time Bin Packing Algorithm”
- Bansal, Caprara, & Sviridenko
“Improved approximation algorithms for multidimensional bin packing problem”
# Scheduling
Scheduling - DAG
We're seeing speed-ups of 30% on some customer workloads.
# Scheduling
Where's the ML?
-
We use LLMs to predict query preprocessing time, runtime, scaling, and concurrency
-
Runtime predictions are obviously helpful for scheduling. They also tell us which queries to incrementalize.
-
# Scheduling
Where's the ML?
-
We use LLMs to predict query preprocessing time, runtime, scaling, and concurrency.
-
Scaling (i.e. runtime on different-size clusters) and concurrency (i.e. runtime with multiple queries per cluster) let us reduce runtime and increase utilization.
-
# Scheduling
Where's the ML?
-
We’re building towards an ML-powered runtime scheduler, not just an offline job scheduler.
-
This will work kind of like the borg scheduler or the kubernetes scheduler, but with ML-inferred resource annotations.
# Snowflake dbt Optimization
Snowflake dbt Optimization Advice
If you only take one thing away from this talk:
Increase your dbt threadcount!
-
dbt’s defaults to 4 threads, which means your jobs will block if 4 queries are outstanding.
- Most jobs benefit from more parallelism.
# Snowflake dbt Optimization
Snowflake dbt Optimization Advice
-
Snowflake will queue work for you.
-
No downside for standard warehouses.
-
Can increase costs for multicluster warehouses
-
-
This can increase speed as much as increasing your warehouse a size, and for free.