Computational Optimization and Machine Learning
Huang Fang
June 22, 2024
Education background
-
Central University of Finance and Economics, 2011- 2015
- B. S. in Applied Math
-
University of California, Davis. 2015 - 2017
- M.S. in Statistics and Computer Science
- Worked with Prof. Cho-Jui Hsieh
-
University of British Columbia. 2017-2021
- Ph. D. in Computer Science
- Worked with Prof. Michael Friedlander
Industry experience
-
Huawei Vancouver Research Center, 2020-2021
- Developed Huawei's linear programming solver -- OptVerse;
- Research on federated learning.
-
Baidu, 2022 Jan -- Now.
- Research on optimization and knowledge reasoning;
- Motion prediction for auto-driving;
- Training ERNIEBot (pretraining and alignment).
Research plan
-
Efficient and scalable optimization algorithms
- Knowledge reasoning, language modeling, SDP, etc.
-
Optimization with generalization ability
- Language model alignment.
-
ML for algorithm discovery
- Using data-driven principle to find better algorithm, AI for math, etc.
Overview
- Part I: first-order optimization
- Coordinate optimization
- Online mirror descent
- Stochastic subgradient descent
- Part II: optimization for applications
- Computational optimization for knowledge reasoning
- Computational optimization for large language models
Part I: First-order methods
- Optimization is everywhere: machine learning, operation research, data mining, theoretical computer science, etc.
- First-order methods:
- Why first-order methods?
First-order method
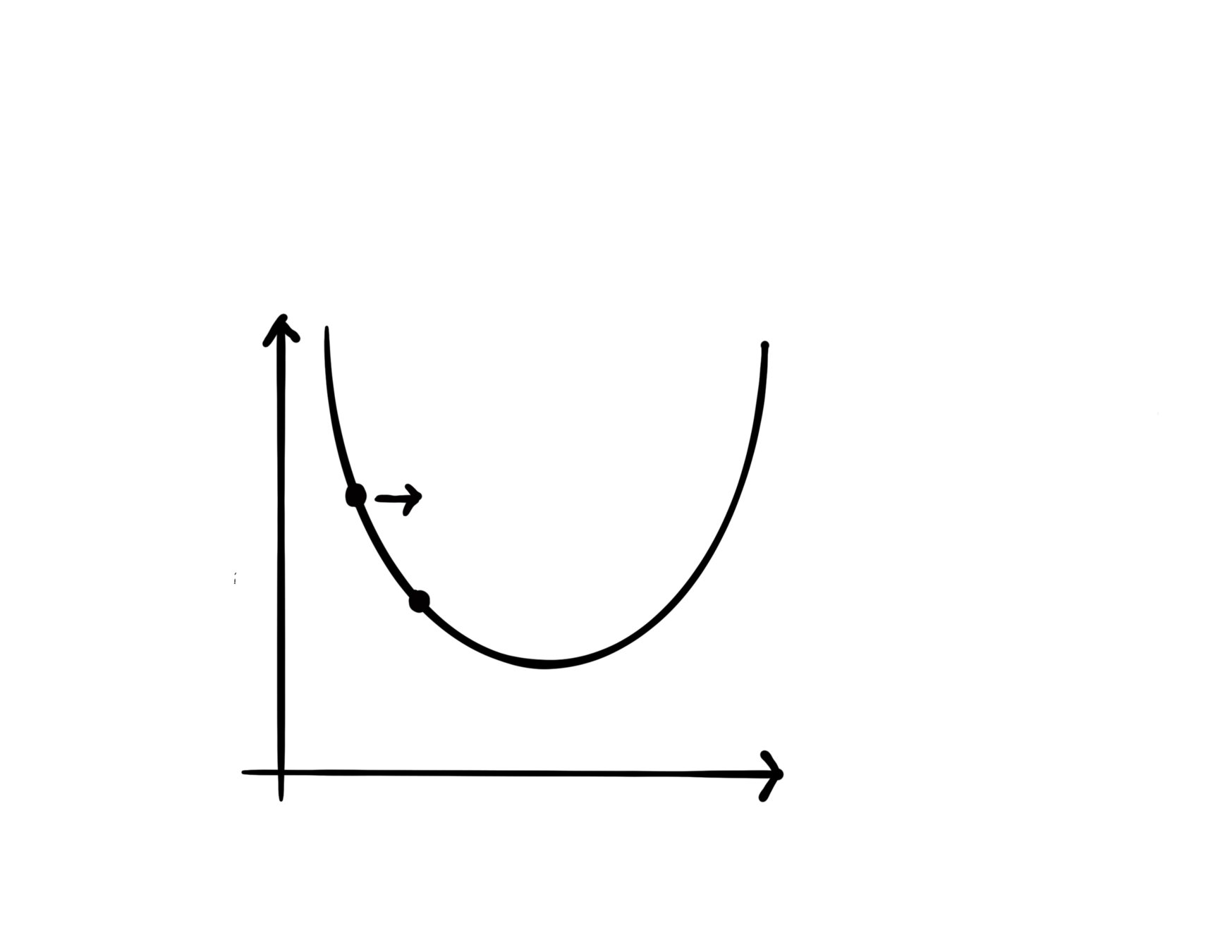
The literature
- Gradient descent can be traced back to Cauchy's work in1847.
- It is gaining increasing interest in the past 3 decades due to its empirical success.
- Fundamental works have been done by pioneering researchers (Bertsekas, Nesterov, etc.).
- There are still gaps between theory and practice.
- Coordinate optimization
- Mirror descent
- Stochastic subgradient method
Coordinate Optimization
Coordinate Descent
For
- Select coordinate
- Update
Different coordinate selection rules:
- Random selection:
- Cyclic selection:
- Random permuted cyclic (the matrix AMGM inequality conjecture is false [LL20, S20])
- Greedy selection (Gauss-Southwell)
Forty-Two Open Problems in the Mathematics of Data Science
GCD for Sparse Optimization
regularizer
- One-norm regularization or nonnegative constraint can promote a sparse solution.
- When initailzed at zero, greedy CD is observed to have an implicit screening ability to select variables that are nonzero at solution.
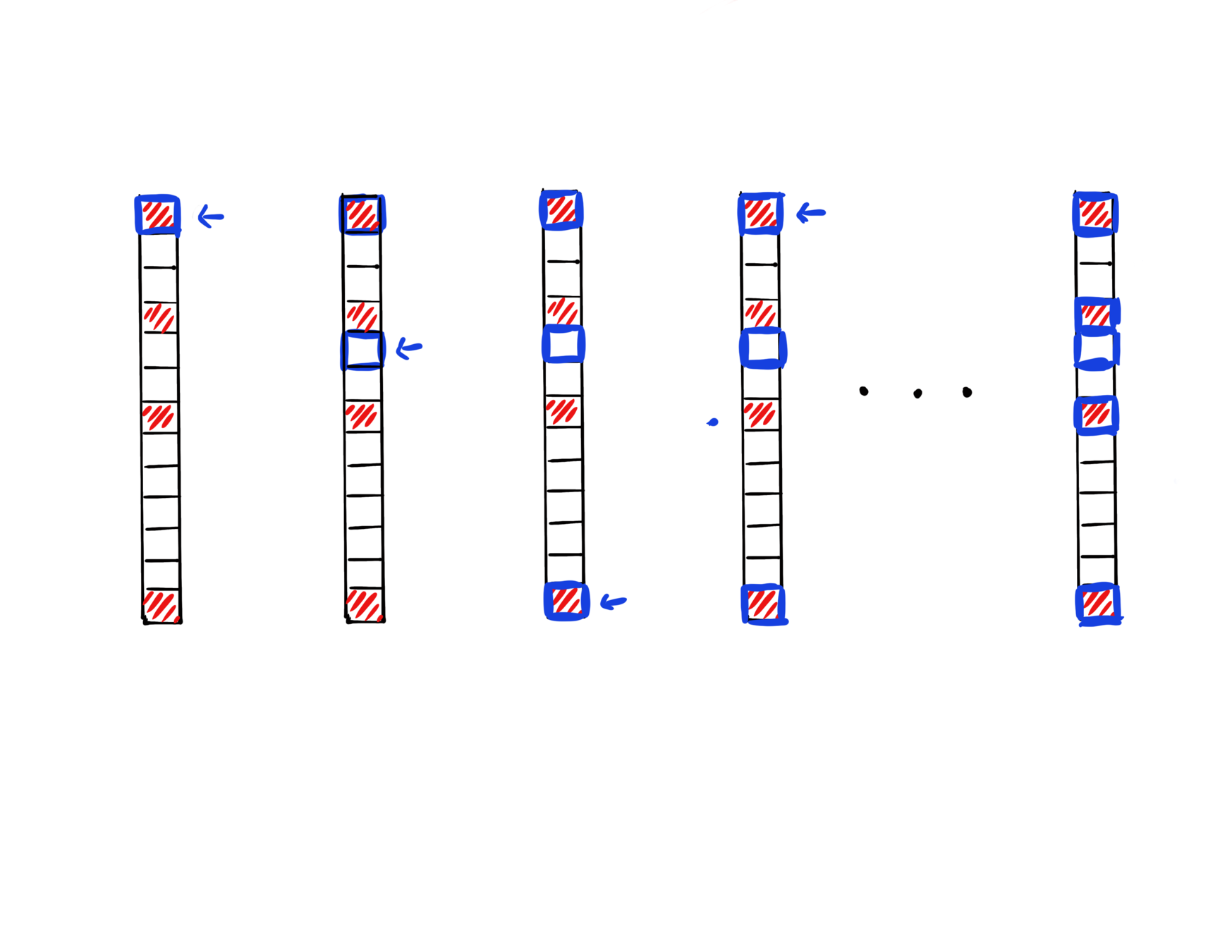
Iter 1
Iter 2
Iter 3
Iter 4
Iter
data fitting
GCD for Sparse Optimization
[FFSF, AISTATS'20]
We provide a theoretical characterization of GCD's screening ability:
- GCD converges fast in first few iterations.
- The iterate is "close" the to solution when the iterate is still sparse, and sparsity pattern will not further expand anymore.
for
From coordinate to atom
Learning a sparse representation of an atomic set :
such that
- sparse vector:
- Low-rank matrix:
Our contribution: how to identify the atoms with nonzero coefficients at solution during the optimization process.
[FFF, OJMO'24]
Online Mirror Descent
Online Convex Optimization
Play a game for rounds, for
- Propose a point
- Suffer loss
The goal of online learning algorithm: obtain sublinear regret
player's loss
competitor's loss
Mirror Descent (MD) and Dual Averaging (DA)
- MD and DA are parameterized by mirror map, they have advantages over the vanilla projected subgradient method.
- When is known in advance or , both MD and DA guarantee regret
- When is unknown in advance and , then MD has rate while DA still guarantees regret.
Our contribution: fix the divergence issue of MD and obtain
regret.
OMD Algorithm
[FHPF, ICML'20, JMLR'22]
Primal
Dual
Bregman projection
Figure accredited to Victor Portella.
Stabilized OMD
[FHPF, ICML'20, JMLR'22]
Primal
Dual
Bregman projection
}
With stabilization, OMD can obtain regret.
(Stochastic) Subgradient Method
Smooth v.s. Nonsmooth Minimization
- Consider minimizing a convex function
- The iteration complexity of gradient descent (GD) and subgradient descent (subGD) for smooth and nonsmooth objectives:
- when is smooth:
- when is nonsmooth:
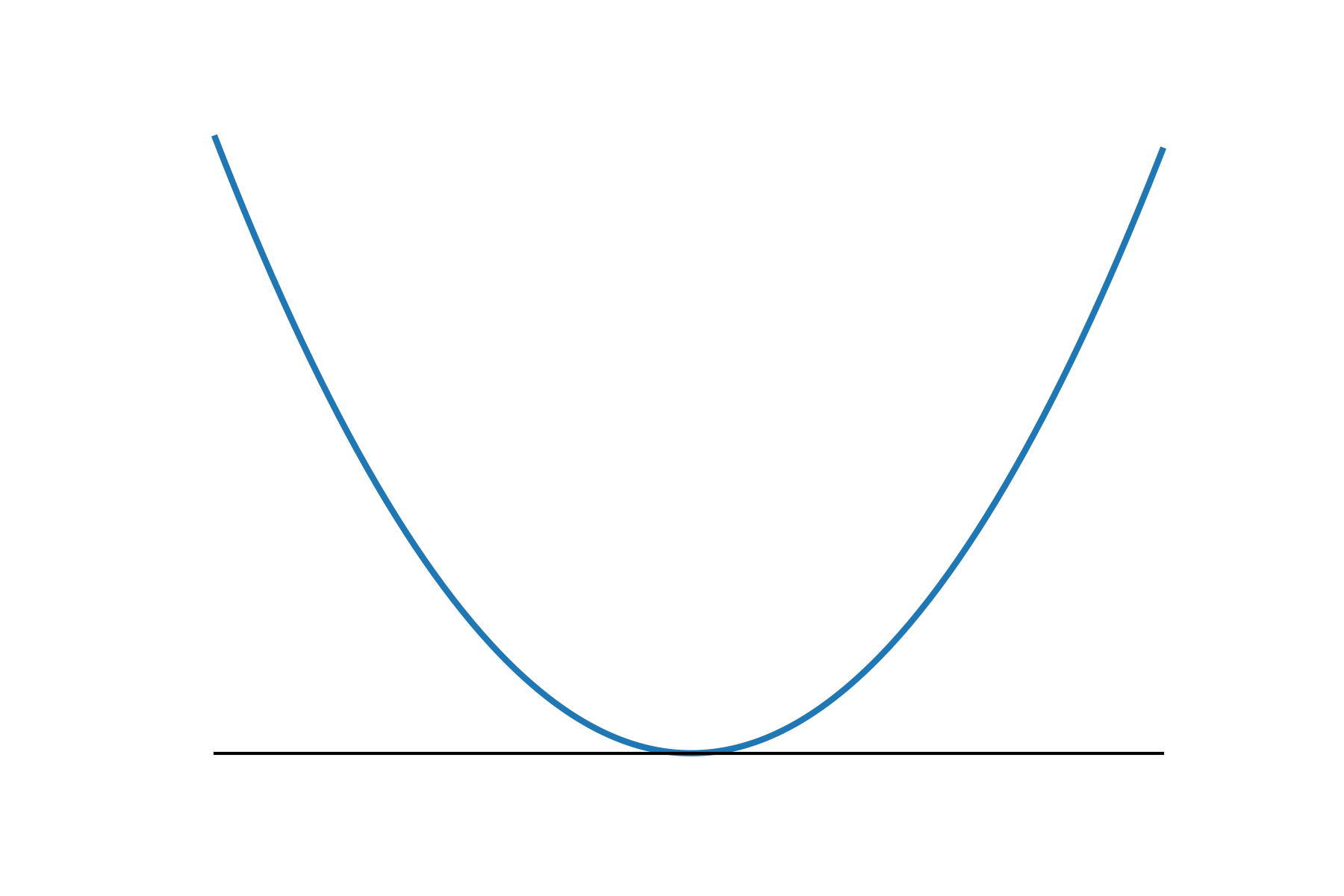
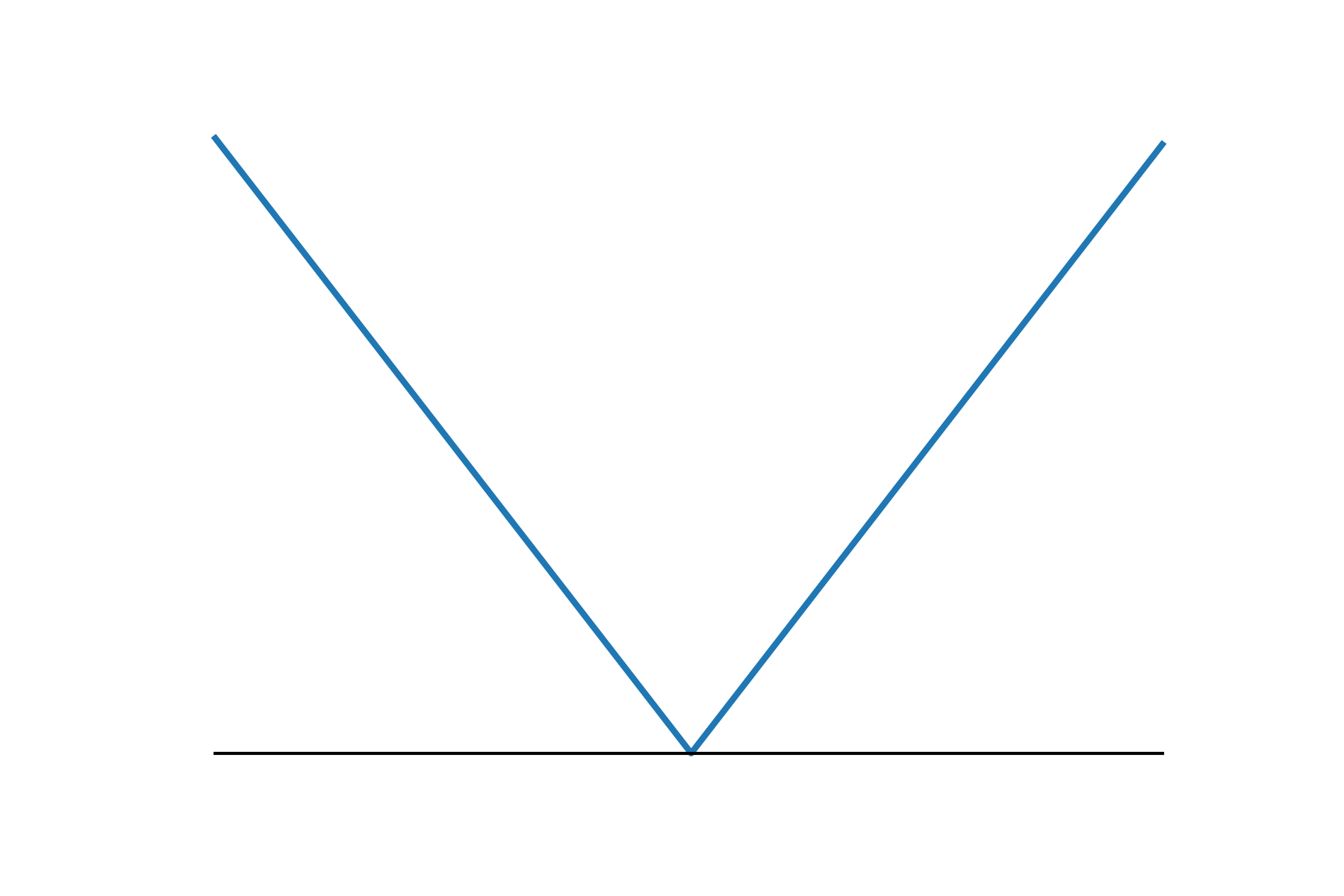
smooth
nonsmooth
The empirical observation
Some discrepancies between theory and practice:
- Nonsmoothness from the model does not slow down our training in practice.
- The learning rate schedule can yield optimal iteration complexity but seldom used in practice.
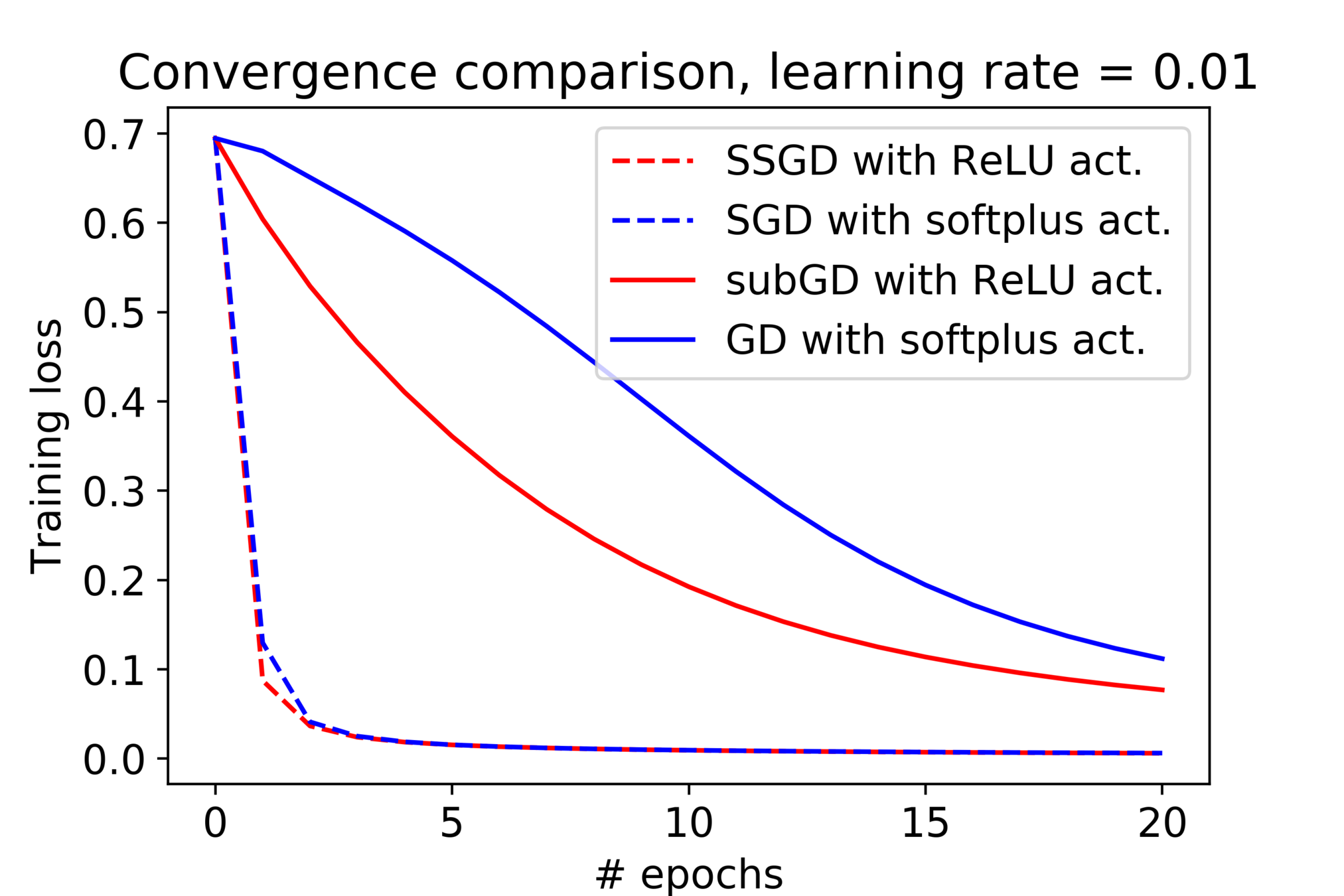
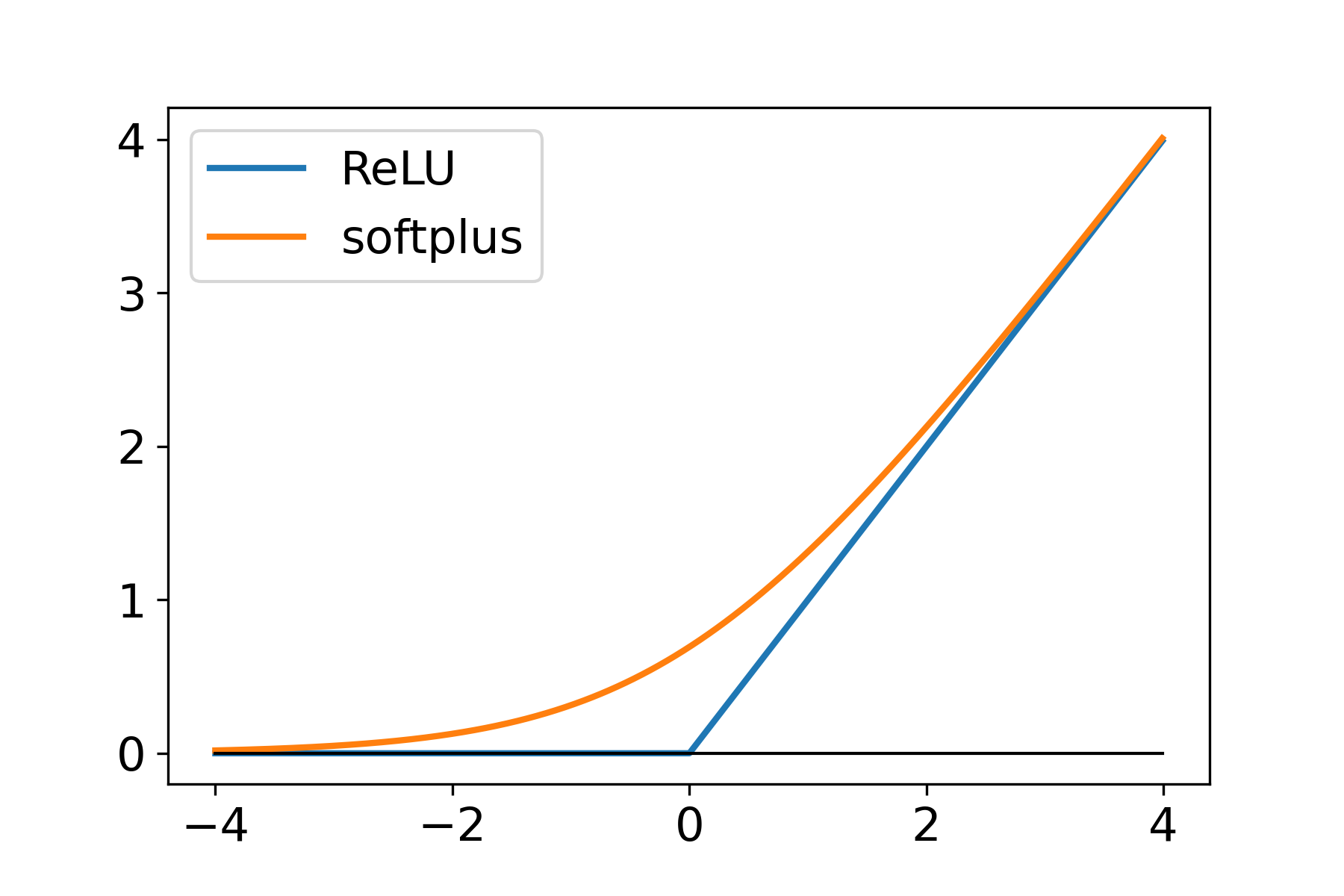
Filling the gap
Two important structures:
- The objective satisfy certain structure:
where is a nonnegative, , convex, 1-smooth loss function, 's are Lipschitz continuous.
- The interpolation condition: there exist such that
[FFF, ICLR'21]
square loss, L2-hinge loss, logistic loss, etc.
absolute loss, L1-hinge loss.
Filling the gap
With constant learning rate, we prove
- Convex objective:
- Strongly convex objective:
- The above rates match the rate of SGD for smooth objectives.
[FFF, ICLR'21]
Lower bounds
- Can we accelerated SSGD using momentum under interpolation? e.g.,
Two follow up questions:
- The structure stays in the center of our analysis, could this structure itself give us improved rate without the interpolation condition?
[FFF, ICLR'21]
The answer to above questions is "no".
- With interpolation condition:
- Without interpolation condition:
We derive lower bounds for iteration complexity:
Part II: Optimization for applications
Knowledge Graph Reasoning
Knowledge graph
- Knowledge graph: a set of triplets , such as (Tom, workAt, Baidu), (Beijing, cityOf, China), etc.
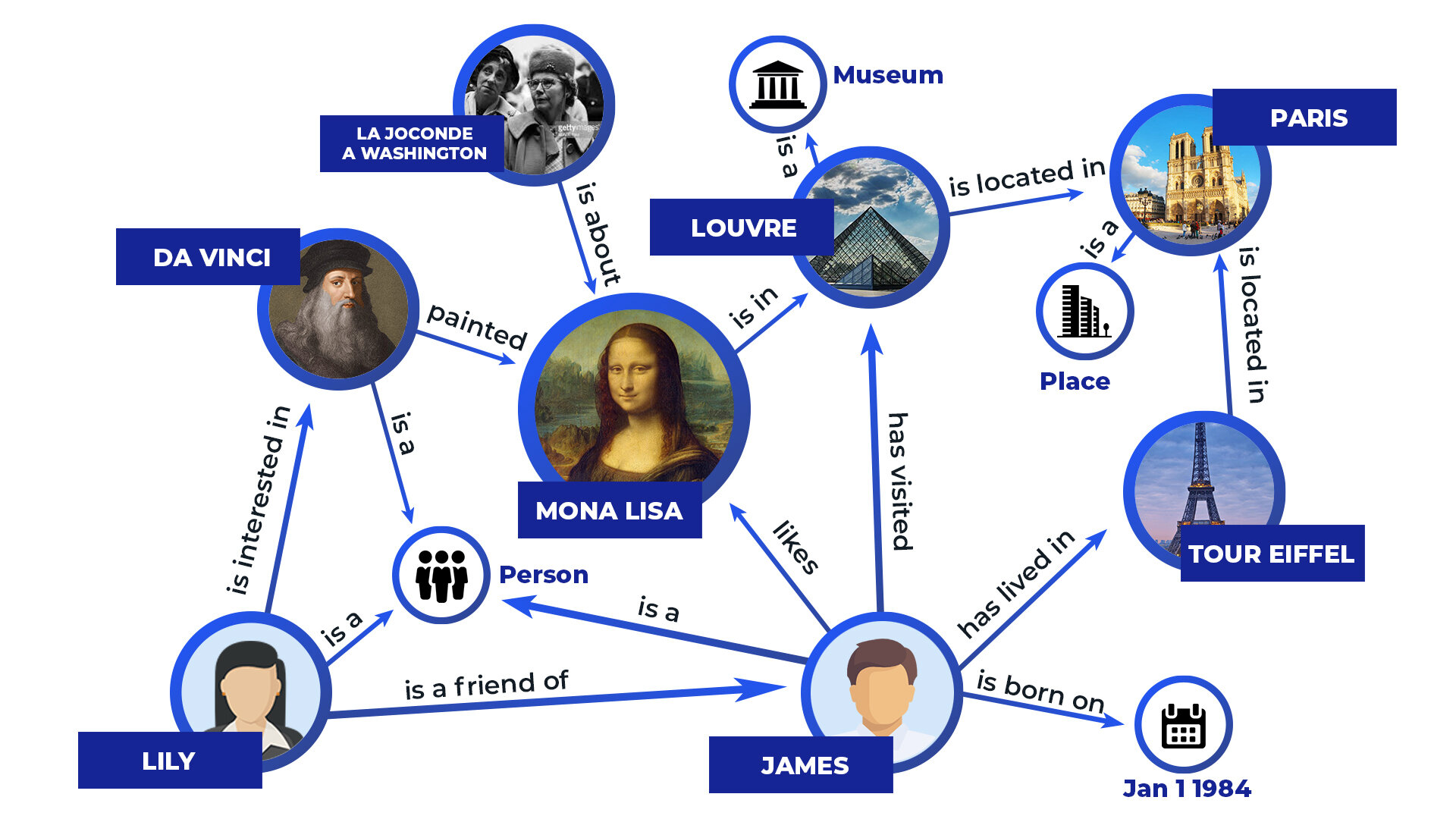
- Reasoning on knowledge graph:
Markov Logic Network (MLN)
- First-order logic rules:
1.0
0.4
- Given a set of facts, MLN defines the probability of the "world" as
where is the number of time that the i-th rule is satisfied.
The previous state of MLN
- MLN suffers from an efficiency issue, both the learning and MAP inference of MLN are NP-hard.
- Existing MLN solvers such as Alchemy, Tuffy, DeepDive and PSL all cannot scale to medium-size KBs.
Key insights
- The MAP inference of MLN is essentially solving a huge SAT problem (potentially solved by the WalkSAT algorithm).
- Expolit the sparsity of knowledge graph and develop a smart implementation of the WalkSAT algorithm.
- Our implementation is based on Julia, available at https://github.com/baidu-research/MLN4KB.
[FLCS, WWW'23]
Experiments
- Efficiency on the Kinship dataset.
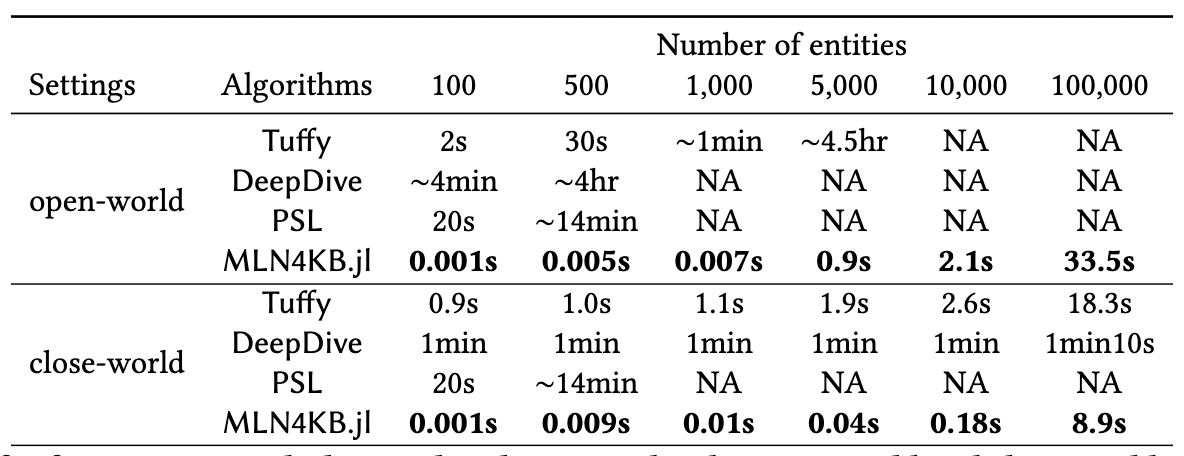
~10,000 speed up!
[FLCS, WWW'23]
Experiments
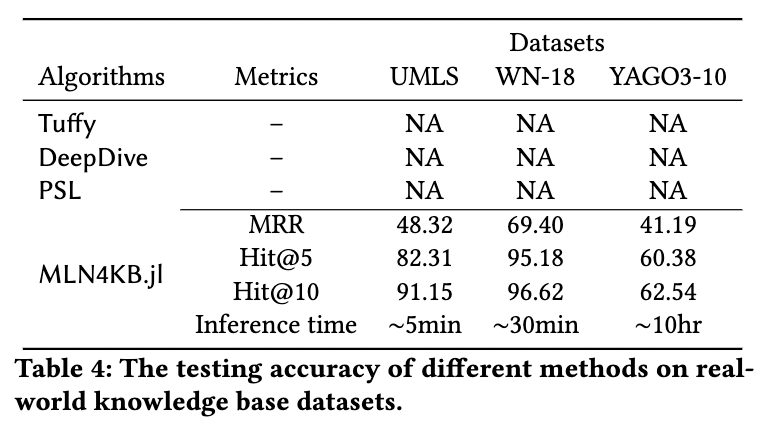
- Performance on real-world KG datasets, rules extracted by the AMIE (GTHS13) software.
- Memory usage:

[FLCS, WWW'23]
Follow up work
[CCFHS, NeurIPS'23]
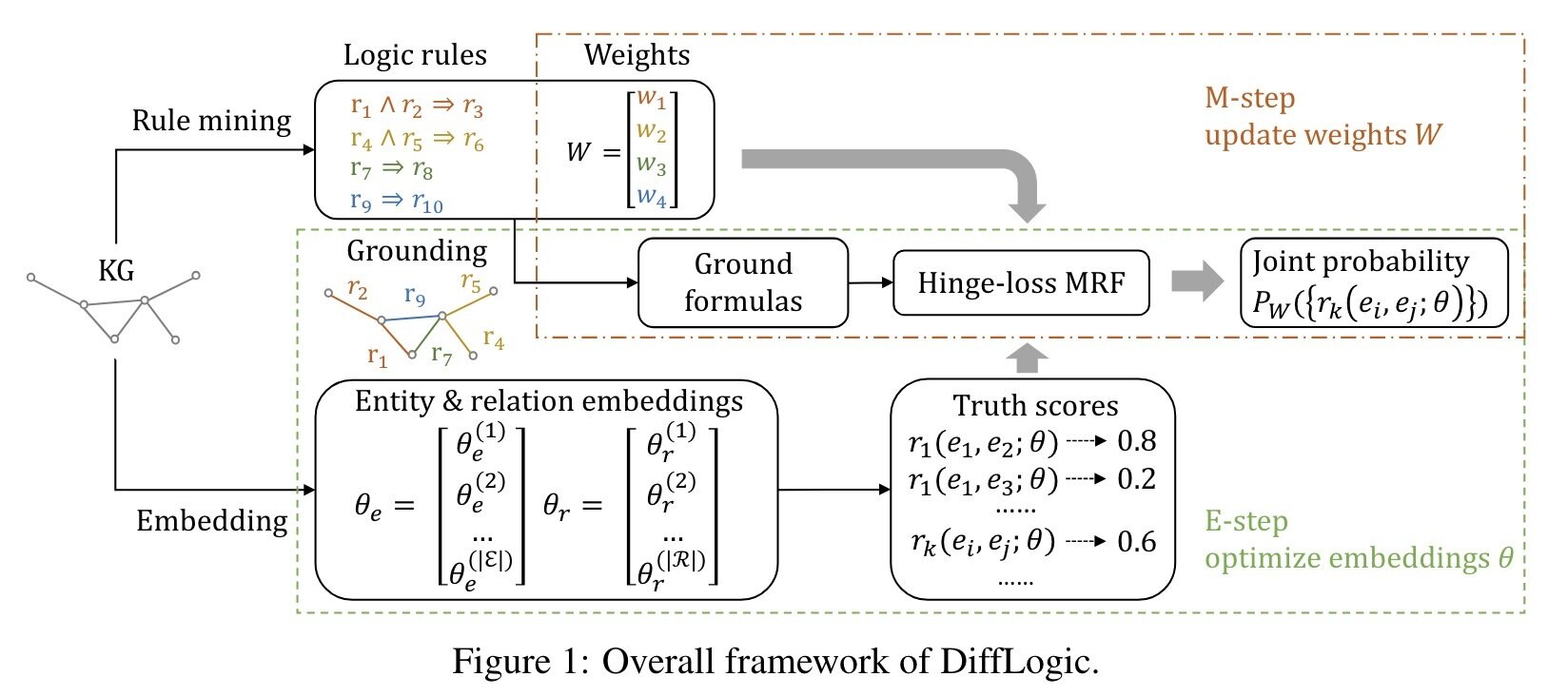
DiffLogic: combining (soft) MLN with knowledge graph embedding.
Computational Optimization and Large Language Model
Optimization matters for pretraining
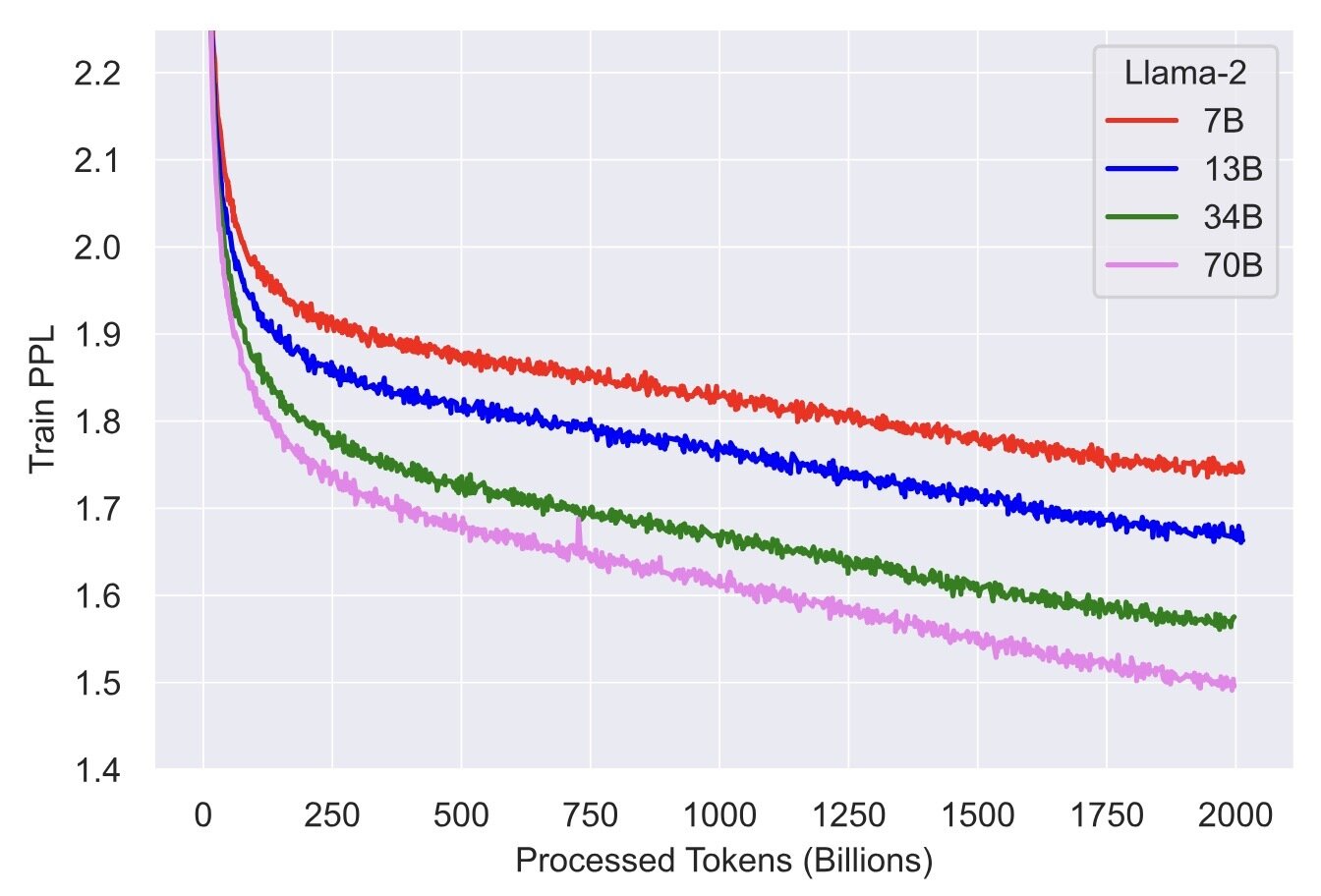
LLM pretraining is essentially an optimization problem! Lower loss means better performance.
Figure comes from "Llama 2: Open Foundation and Fine-Tuned Chat Models"
Training stability of the Adam optimizer
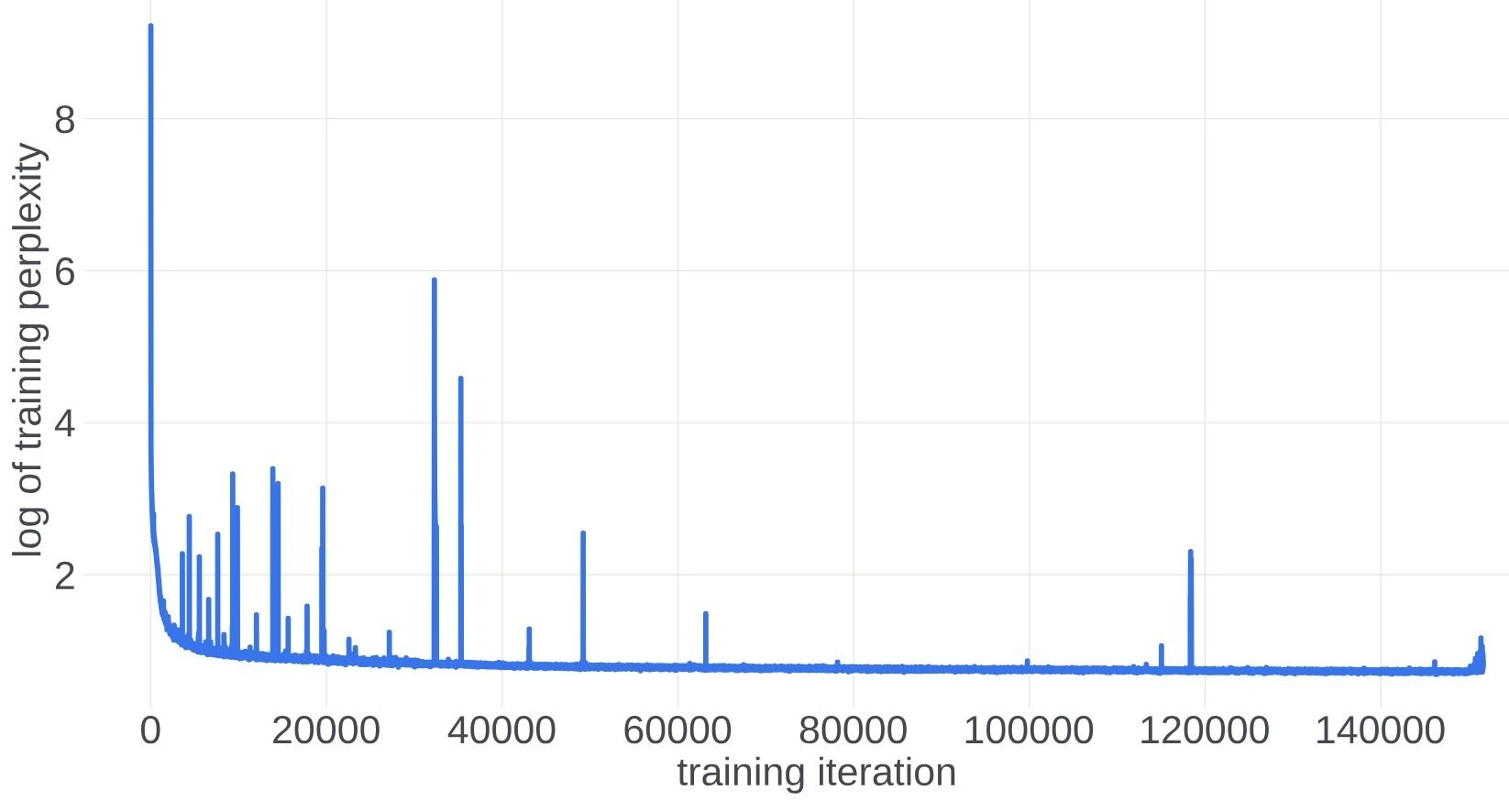
The training curve of a 546b model from META.
Figure comes from "A Theory on Adam Instability in Large-Scale Machine Learning"
Low precision training
- A well-known trend: model gets larger, dataset gets larger...
- A less well-known trend: float32 -> float16 -> bfloat16 -> int8 -> int4...
training
inference
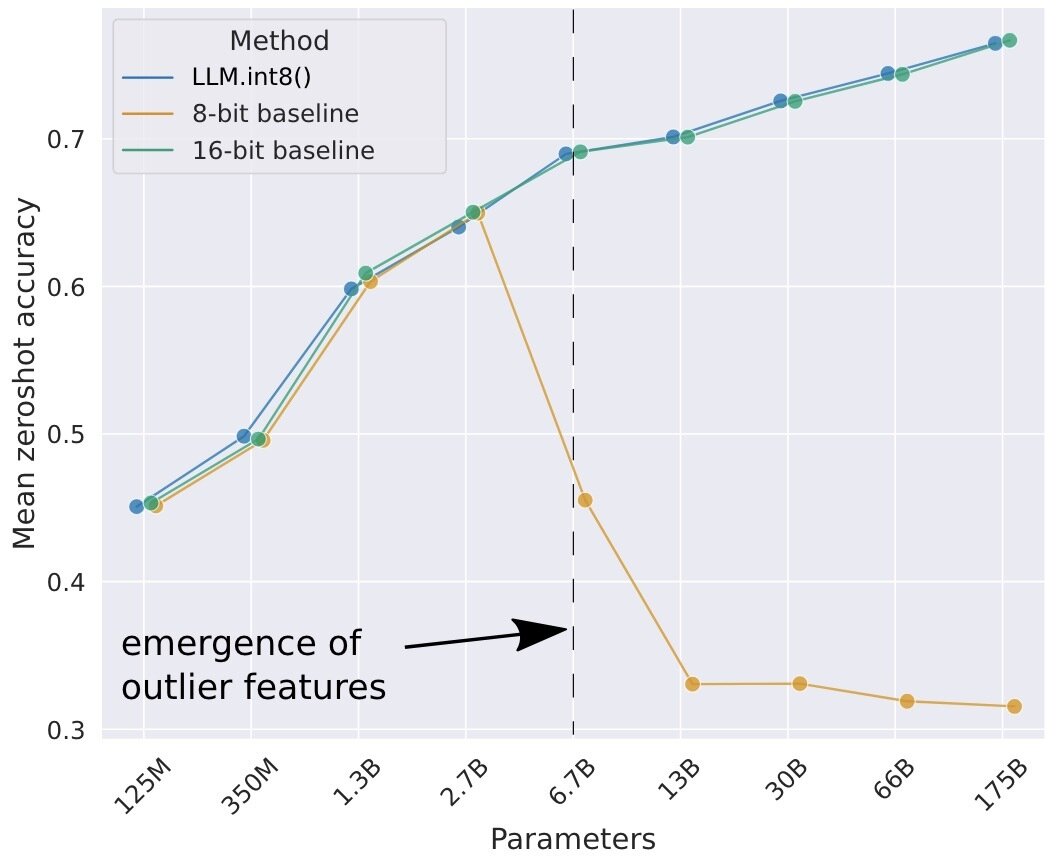
Figure comes from "LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale"
Thank you! Questions?
Matrix AMGM inequality
for all PSD matrix
The matrix AMGM inequality conjecture is false [LL20, S20])
Backup slides for SGD
Basics
| smooth | nonsmooth | smooth+IC | nonsmooth + IC | |
|---|---|---|---|---|
| convex | ||||
| strong cvx |