Le Deep Learning en pratique avec Keras
Toulouse Data Science
18 Juin 2018
Florient Chouteau
About.md
Deep Learning Engineer at Magellium
... training neural networks since 2016
... mostly aerial & satellite imagery

Florient Chouteau
We have one hour.
let's talk about...
... Deep Learning for computer vision ...
... in pratice ...
... using Keras ...
WTF is... Deep Learning ?

Machine Learning and "Deep" Learning

Representation Learning

Hierarchical Representation Learning

Differentiable programming
# Define the neural network function y = x * w
def nn(x, weights):
return x * weights
# Define the cost function
def loss(y_true, y_pred):
return ((y_pred - y_true)**2).sum()
# define the gradient function.
def gradient(weights, x, y_true):
return 2 * x * (nn(x, weights) - y_true)
# define the update function delta w
def delta_w(w_k, x, y_true):
dw = gradient(w_k, x, y_true).sum()
return dw
# Start performing the gradient descent updates
for i in range(nb_of_iterations):
# Get the delta w update
dw = delta_w(w, x, y_true, learning_rate)
# Update the current weight parameter
w = w - learning_rate * dw
# Et voilà !- Express problem as computational graph
- Define differentiable loss function
- Optimize with gradient descent



In practice: Neural Networks
Stacking of:
- linear units (fully connected to inputs)
- non linear activation function


Convolutionnal Neural Networks


Use Cases
A LOT of things !
- Most drastic changes in the way we do pattern recognition...
- Natural language processing, translation...
- Reinforcement learning (Go... Starcraft soon ?)
Examples in CV:
- Today it's CVPR 2018 so lots of new things !
- Deep Globe challenge on US satellite images
- Medical Image (computer aided diagnosis)
- Twitter smart autocropping using saliency
- Looking to listen
Practical Deep Learning


So you have a DL project...






Translate biz. obj. into ML obj.
Get data
Define model
& training procedure
Build data pipeline
model.train()

Evaluate
Deploy
...then you need a DL framework...
- Abstraction of hardware (CPU, GPU, TPU, Distributed....)
- Data transformations & pipeline
- Model declaration
- Autograd/Autodiff
- Mostly so you don't go insane rewriting convs in CUPY
... that suits you well
- Ease of use / Low-levelness trade-off
- Accessibility / Scalability trade-off
- Adepted to your background
(please don't get offended if I forget one)








And also Matconvnet, DL4J, Dlib, and some more



static vs dynamic graphs

Pytorch
Keras
"Deep Learning for Humans"
What is Keras
- High level Python API for Deep Learning
- Same code that abstracts several backends: Theano (first one), Tensorflow, CNTK, MXnet (fork), PlaidML (soon)
-
Created in mid 2015 by François Chollet @ Google
-
One of the most popular way to do Deep Learning
- Currently in its version 2.2.0
(Pas l'adjoint au maire)
Why (still) talk about Keras ?
- One of the only way of doing DL for actual humans
- "Beginner only" reputation... unfounded ?
- Huge impact in terms of UX over other frameworks
- It's very likely you don't need more to solve your problem
(This is a personal opinion)
Thesis for what's next
If you are in an "humanly scaled" (e.g. not Google, not Facebook...) team or project, Keras is "the best" trade-off between acessibility, ease of use, extensibility, ability to scale up to bigger data and ability to ship models to production environments.
1. Accessibility
First steps into Deep Learning
Installing Keras
# Install your backend
pip install tensorflow==1.8.0
# (or tensorflow-gpu==1.8.0 or theano, or cntk...)
# Install keras
pip install keras==2.2.0
Note: I will not talk about other backends than tf because... I don't know anything about them.
Why Keras was built in one example
# Tensorflow Low Level API
# Start training
with tf.Session() as sess:
# Run the initializer
sess.run(init)
for step in range(1, num_steps+1):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop)
sess.run(train_op, feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.8})
if step % display_step == 0 or step == 1:
# Calculate batch loss and accuracy
loss, acc = sess.run([loss_op, accuracy],
feed_dict={X: batch_x,
Y: batch_y,
keep_prob: 1.0})
print("Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss) + ", Training Accuracy= " + \
"{:.3f}".format(acc))
So you did a data science project in scikit learn and you want to do DL ?
y = df2["Target"]
X = df2[features]
dt = DecisionTreeClassifier(min_samples_split=20, random_state=99)
dt.fit(X, y)Why Keras was built in one example
# Tensorflow Estimator High Level API
model = tf.estimator.Estimator(model_fn)
# Define the input function for training
input_fn = tf.estimator.inputs.numpy_input_fn(
x={'images': mnist.train.images},
y=mnist.train.labels,
batch_size=batch_size, num_epochs=None, shuffle=True)
# Train the Model - Here you see that we wrap functions to objects....
model.train(input_fn, steps=num_steps)
# Evaluate the Model
# Define the input function for evaluating
input_fn = tf.estimator.inputs.numpy_input_fn(
x={'images': mnist.test.images},
y=mnist.test.labels,
batch_size=batch_size, shuffle=False)
# Use the Estimator 'evaluate' method
e = model.evaluate(input_fn)
Why Keras was built in one example
# Keras
model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
validation_data=(x_test,
y_test),
epochs=10,
verbose=1,
workers=4,
callbacks=[TerminateOnNaN()])
Model/Layer abstraction
- Static graphs are a good idea
- Writing static graphs in tf/th is painful
- Keras makes graph ops (functions) as objects from start (Layers)
- Still, it's very hardcore to debug anything that fails at the graph level
Cleaner, more intuitive API
# Calculate crossentropy
categorical_crossentropy(y_true, y_pred)
# it's like scikit learn !
# Calculate mean of tensor
keras.backend.mean(x,
axis=None,
keepdims=False)
# it's like np.mean(x) !# Calculate crossentropy
tf.nn.softmax_cross_entropy_with_logits(
labels=None,
logits=None, # WTF is a logit ?
dim=-1, # EVERYBODY IS USING AXIS
name=None)
# Calculate mean of tensor
tf.reduce_mean( # Ok why not just mean ?
input_tensor,
axis=None,
keepdims=None,
name=None,
reduction_indices=None,# Axis & Reduction indices -> one of them is deprecated...
keep_dims=None) # Two keep_dims -> One of them is deprecated...
# have you heard of **kwargs ?- Writing in Tensorflow is not writing Python
- numpy is the reference in array/tensor manipulation
- scikit-learn is the reference in python-based data science
Example use case: Data
|_ dataset
|_ train
|_ cats
|_ cats_01.jpg
|_ dogs
|_ cats_01.jpg
|_ test
|_ cats
|_ cats_01.jpg
|_ dogs
|_ cats_01.jpgExample use case: I/O pipeline
Keras has nice input pipeline classes
from keras.preprocessing.image import ImageDataGenerator
# Define a data generator with augmentation for train
train_data_generator = ImageDataGenerator(
rotation_range=90.,
zoom_range=0.1,
channel_shift_range=0.1,
fill_mode='nearest',
horizontal_flip=True,
vertical_flip=True,
rescale=1. / 255.,
)
# Get a generator w/ augmented Data
train_generator = train_data_generator.flow_from_directory(
TRAIN_DIR,
target_size=input_shape[:2],
batch_size=batch_size,
class_mode='categorical',
shuffle=True,
seed=2018)
Example use case: Model
def my_first_model(input_shape, num_classes):
# We use Sequential API to build this model
model = Sequential()
# Feature extractor
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), padding="same"))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
(...)
# Feature bottleneck
model.add(Flatten())
# Classifier part
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
return model
model = my_first_model(input_shape, num_classes)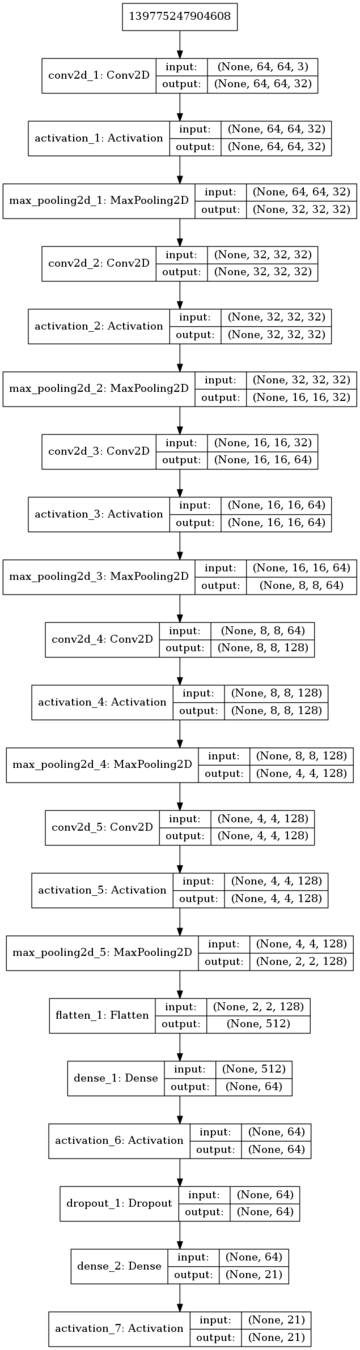
Example use case: Fit
from keras.optimizers import SGD
optimizer = SGD(lr=learning_rate, momentum=0.9, nesterov=True)
model.compile(
loss='categorical_crossentropy',
optimizer=optimizer,
metrics=['categorical_accuracy'])
model.fit_generator(
train_generator,
steps_per_epoch=train_samples // batch_size,
epochs=max_epochs,
validation_data=valid_generator,
validation_steps=valid_samples // batch_size,
verbose=2)
Epoch 1/20
- 20s - loss: 1.4208 - categorical_accuracy: 0.4743 - val_loss: 1.1377 - val_categorical_accuracy: 0.5941
Epoch 2/20
- 19s - loss: 1.2167 - categorical_accuracy: 0.5628 - val_loss: 1.6693 - val_categorical_accuracy: 0.4429
Epoch 3/20
- 19s - loss: 1.1094 - categorical_accuracy: 0.6151 - val_loss: 1.1680 - val_categorical_accuracy: 0.5710
Epoch 4/20
- 18s - loss: 1.0156 - categorical_accuracy: 0.6482 - val_loss: 0.9768 - val_categorical_accuracy: 0.6467
Epoch 5/20
- 18s - loss: 0.9369 - categorical_accuracy: 0.6791 - val_loss: 0.8757 - val_categorical_accuracy: 0.6658
Epoch 6/20
- 19s - loss: 0.8891 - categorical_accuracy: 0.6953 - val_loss: 0.7800 - val_categorical_accuracy: 0.7062
Epoch 7/20
- 18s - loss: 0.8277 - categorical_accuracy: 0.7112 - val_loss: 0.6462 - val_categorical_accuracy: 0.7843
(...)Example use case: Evaluate w/ sklearn
# Generate predictions for the test set
y_pred, y_true = predict_generator_with_y_true(
model, test_generator, steps=len(test_generator))
# Go to sklearn. Seemless due to the closeness of the API
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
for i in range(num_classes):
precision[i], recall[i], _ =
precision_recall_curve(
y_true[:, i],
y_pred[:, i])
average_precision[i] = average_precision_score \
(y_true[:, i], y_pred[:, i])
2. Extensibility
Using Keras every day
Keras main paradigm

Defining your own input pipeline
class Sequence(object):
def __getitem__(self, index):
"""Gets batch at position `index`.
# Returns
A batch
"""
def __len__(self):
"""
# Returns
The number of batches in the Sequence.
"""
def on_epoch_end(self):
"""Method called at the end of every epoch.
"""
pass- ImageDataGenerator is nice for classification
- need more things (detection, gans, segmentation) ? DIY !
- "Sequence" class for feeding data w/ prefetching
- Pure python: You can use custom imreads (libvips, opencv, rastio), custom augmentations (imgaug)
Layers as function: functional API
def identity_block(input_tensor, kernel_size, filters, stage, block):
x = layers.Conv2D(filters1, (1, 1))(input_tensor)
x = layers.BatchNormalization()(x)
x = layers.Activation('relu')(x)
x = layers.Conv2D(filters2, kernel_size,padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.Activation('relu')(x)
x = layers.Conv2D(filters3, (1, 1))(x)
x = layers.BatchNormalization()(x)
x = layers.add([x, input_tensor])
x = layers.Activation('relu')(x)
return x
Models as Layers: Finetuning
from keras.applications import VGG16
def finetuning(input_shape, num_classes):
feature_extractor = VGG16(include_top=False,
input_shape=input_shape)
inputs = Input(input_shape)
# Feature extraction with VGG16 trained on ImageNet
x = feature_extractor(inputs)
# Classifier
x = Flatten()(x)
x = Dense(512)(x)
x = Activation("relu")(x)
x = Dropout(0.5)(x)
x = Dense(num_classes)(x)
outputs = Activation("softmax")(x)
model = Model(inputs=inputs, outputs=outputs)
return model
model = finetuning(input_shape, num_classes)
Callbacks: Controlling the loop
class Callback(object):
def __init__(self):
pass
def set_params(self, params):
self.params = params
def set_model(self, model):
self.model = model
def on_epoch_begin(self, epoch, logs=None):
pass
def on_epoch_end(self, epoch, logs=None):
pass
def on_batch_begin(self, batch, logs=None):
pass
def on_batch_end(self, batch, logs=None):
pass
def on_train_begin(self, logs=None):
pass
def on_train_end(self, logs=None):
pass- Callbacks are the main control tool in Keras
- You can write pretty much anything (callbacks are outside the graph)
Examples:
Model checkpoint (save best)
LR Scheduler, Cyclic LR
Hard Negative Mining
Custom Eval (PR curves?)
Writing custom in-graph ops
class DiceLoss(object):
def __init__(self, smooth=1.):
self.smooth = smooth
def __call__(self, y_true, y_pred):
smooth = K.epsilon()
# Sum over the pixels
union = K.sum(y_pred + y_true, axis=(1, 2))
intersection = K.sum(y_pred * y_true, axis=(1, 2))
# Per sample per class IoU
iou = (2 * intersection + smooth) / (union + smooth)
iou = smooth * (1. - iou)
return iou- Keras is an API front end, so you can write low level functions if you want
- Either use existing "exposed" backend (K. !) function or expose them yourself
Metrics: Monitoring the loop
class BinaryAccuracy(object):
def __init__(self):
pass
def __call__(y_true, y_pred):
accuracy = K.equal(y_true, K.round(y_pred)
return K.mean(accuracy)
class BinaryTruePositives(Layer):
def __init__(self):
self.stateful = True
self.true_positives = 0
def __call__(y_true, y_pred):
y_pred = K.round(y_pred)
correct_preds = K.equal(y_pred, y_true)
true_pos = K.sum(correct_preds * y_true)
current_true_pos = self.true_positives * 1
self.add_update(K.update_add(self.true_positives,
true_pos),
inputs=[y_true, y_pred])
return current_true_pos + true_pos- Metrics are written like losses: f(y_true,y_pred)
- They can be stateless (averaged over batch) or stateful
Loss behaves the same way !
Layers: Wrapping ops and graphs
class BilinearUpSampling2D(Layer):
def __init__(self, size=(2, 2)):
super(BilinearUpSampling2D, self).__init__()
self.size = size
# + Some params
def compute_output_shape(self, input_shape):
# Basically returns 2x input shape
def call(self, inputs, **kwargs):
# Call a TF ops
return tf.image.resize_images_bilinear
(inputs,
self.size[0],
self.size[1],
self.data_format)
def get_config(self):
# Serialize Layer- Keras abstracts graph ops as objects.
- So if you have specific needs and know how to code in TF you can write a Layer and use it in Keras

3. "Scalability"
Going further with Keras
tf.
So what about tensorflow ?
- Late 2017 tf.keras was announced
- TF's own high-level API tf.data and tf.estimators were released
- Keras forked into tf.keras and "keras community edition"
- Latests commits of Keras teasing like tf.eager
- Latest releases of tf relying more and more on Keras API
(Example: Migration of tf.layers API to keras.layers in tf 1.9)
What do I gain by using tf.keras ?
- Optimization (no multi backend support to keep)
- tf.Eager support (dynamic graphs)
- tf.Estimator and tf.Data compatibility
- Last but not least:
The immense bliss of having absolutely no documentation about what is different*
*Because "yes it's ready" since tf 1.4 but the programmer's guide to keras is still WIP in tf 1.9 !

Oh ye of little faith:
I see you don't like TF very much...
- Yes
- It's totally undeserved, sorry Tensorflow
- OK, Let's do it:
(this is kinda new: 1.9rc0 from 7th June)
pip install tensorflow-gpu==1.9.0rc1Using tf.data
import tensorflow as tf
from tensorflow import keras
def parse_function(filename, label):
image_string = tf.read_file(filename)
# Don't use tf.image.decode_image, or the output shape will be undefined
image = tf.image.decode_jpeg(image_string, channels=3)
# This will convert to float values in [0, 1]
image = tf.image.convert_image_dtype(image, tf.float32)
return image, label
def train_preprocess(image, label):
# Image data augmentation coded with tf.image.random*
return image, label# Let train_images, train_labels the list of image filename and label
train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels))
train_dataset = train_dataset.shuffle(len(train_images))
train_dataset = train_dataset.map(parse_function, num_parallel_calls=4)
train_dataset = train_dataset.map(train_preprocess, num_parallel_calls=4)
train_dataset = train_dataset.batch(batch_size)
train_dataset = train_dataset.prefetch(1)
train_dataset = train_dataset.repeat()Using tf.data
h = model.fit(
train_dataset,
steps_per_epoch=train_samples // batch_size,
epochs=max_epochs,
validation_data=val_dataset,
validation_steps=valid_samples // batch_size,
verbose=1)


Before:
Let's run:
After:
Using tf.estimators
def input_fn():
return train_dataset
estimator = keras.estimator.model_to_estimator(model)
estimator.train(input_fn=input_fn)INFO:tensorflow:loss = 0.80180705, step = 1
INFO:tensorflow:global_step/sec: 211.485
INFO:tensorflow:global_step/sec: 161.321
INFO:tensorflow:loss = 1.25377, step = 201 (1.093 sec)
INFO:tensorflow:global_step/sec: 319.681
INFO:tensorflow:global_step/sec: 320.532
INFO:tensorflow:loss = 0.71999, step = 401 (0.625 sec)
INFO:tensorflow:global_step/sec: 317.201
INFO:tensorflow:global_step/sec: 319.046
INFO:tensorflow:loss = 1.009802, step = 601 (0.629 sec)Using tf.estimators
- Faster !
- You gain auto-distribution of training pipeline (yay!) and easy export to model servers
- You lose callbacks, metrics and all nice things
- You need to write pure tensorflow ops (notably for eval)
Trade off depending on use case & qty of data
(not much xp on this...)
Distributed
- tf.Estimators are nice but there are alternatives
- Keras provides basic single node multi gpu
- Otherwise Horovod:


# Horovod: adjust learning rate based on number of GPUs.
opt = keras.optimizers.SGD(lr=learning_rate * hvd.size(), momentum=0.9)
# Horovod: add Horovod Distributed Optimizer.
opt = hvd.DistributedOptimizer(opt)
callbacks = [hvd.callbacks.BroadcastGlobalVariablesCallback(0)...]
model.fit_generator(train_iter,(...)Let's finish
(because I'm probably late at this point)
def save_as_tensorflow_serving(path_to_model, version="1"):
K.clear_session()
# Set ourselves in inference mode
K.set_learning_phase(0)
with K.get_session() as sess:
model = keras.models.load(path_to_model)
# Build the Protocol Buffer SavedModel at 'export_path'
builder = tf.saved_model.builder.SavedModelBuilder(export_path)
# Specifically name the output_node so that we can get it later
pred = tf.identity(model.output, name="output_node")
# Create prediction signature to be used by TensorFlow Serving Predict API
signature = tf.saved_model.signature_def_utils.predict_signature_def(
inputs={"images": model.input},
outputs={"scores": pred},
)
# Save the meta graph and the variables
builder.add_meta_graph_and_variables(
sess=sess,
tags=[tf.saved_model.tag_constants.SERVING],
signature_def_map={
"predict": signature
})
builder.save()One more thing...
Exporting to production (in 30 secs)
- Keras models are "portable": You don't need the code declaring it to load it*
- With tf backend:
- convert keras models to tensorflow inference graphs (for tf.serving or just tf)
- apply optimizations (freezing, quantitization etc...)
- Theoretically you could even train as Keras Model, convert to tf.Estimator and use tf to export to inference graph
*except your custom layers
Wrapping things up
(for real)
Use (tf.)Keras ...
... for its frictionless learning curve
... for its scikit-learn-like API
... for its Model/Layer abstraction
... for a modern tf usage
... because you only have to solve problems that can be expressed as static graphs
... because you like model portability w/o code
... because you need/like model servers such as tf.serving / tf inference
... because this is probably the most mature high level API for now
... because in the end, Occam's razor
...Prefer pytorch...
. .. if you think static graphs aren't as intuitive (and a pain to debug) as dynamic graphs
... if you want something even more pythonic
... if you don't need model servers and just like to serve predictions with a Flask App
... if you have a raw numpy/cupy background
... if you need new layers with custom CUDA kernels
... because you are betting that ONNX and Caffe2 merge will work (!)
... if you think Keras is too slow and have too much overhead
Coming soon at TDS ?
(and Ignite)
Thank you
Bonus slide 1
- Tensorflow (king of static graphs) is currently developping
- tf.Eager: Dynamic graphs
- tf.Autograph: tf.Eager to graph
- Pytorch (king of dynamic graphs) is currently developping
- Caffe2 merge for dynamic to static
- ONNX for model portability