machine learning,
prototyping & experimeNTATION
Nick Merrill i290-SHDA fall 14
TRUisms
- We're very often interested in "classifying" physiological signals.
- These signals are almost always a series of readings over time (time series).
- The way these time series signals are expressed varies between users, and within users over time.
physiological computing as a pattern recongition task
to identify a time-series signal as one of a discrete set of possible categories.
EXAMPLE
Accelerometer TIME SERIES DATA
Walking?
Running?
BIKING?
1. LABEL EXAMPLE DATA
sitting down
drinking
order
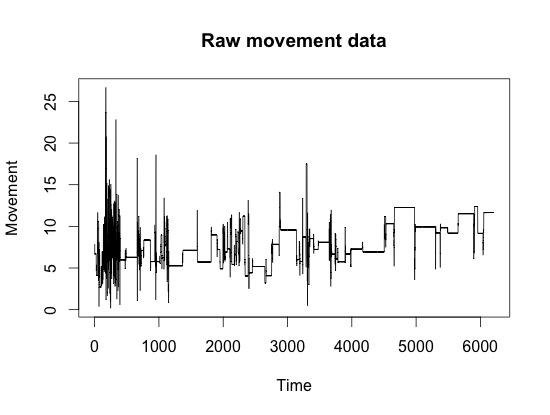
The presence of noise is a common feature in most time series - that is, random (or apparently random) changes in the quantity of interest. This means that removing noise, or at least reducing its influence, is of particular importance. In other words, we want to smooth the signal.
The simplest smoothing algorithm is a moving average. In this example, we average each point along with its ten neighboring points.
smoothed = np.convolve(data, np.ones(10)/10)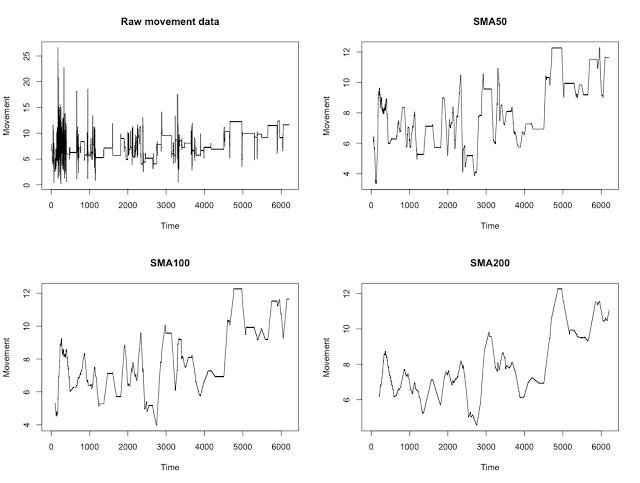
smoothed = np.convolve(data, np.ones(50)/50)smoothed = np.convolve(data, np.ones(200)/200)smoothed = np.convolve(data, np.ones(100)/100)However, this technique can have a serious drawback. When a signal has some sudden jumps / occasional large spikes, the moving average is abruptly distorted. One way to avoid this problem is to instead use a weighted moving average, which places less weight on the points at the edge of the smoothing window. Using a weighted average, any new point that enters the smoothing window is only gradually added to the average and gradually removed over time.
The python pandas package has great tools + tutorials for smoothing time series data.
2. Feed examples to a learning algorithm

sit down
drinking
wait for beer
src Scikit-learn doc
3. See how algorithm works on data it didn't study

?
support vector machine
hyperplane
scalar
vector
Matrix
three exercises
Introduction to the dataset
- 15 people
- 7 "mental gestures" from each one (see down)
- Each gesture = 10 second recording = 20 EEG readings (vectors of 100 numbers)
- We have 10 examples for each gesture
Mental gestures
- breathing with eyes closed;
- motor imagery of right index finger movement;
- motor imagery of subject’s choice of repetitive sports motion;
- mentally sing a song or recite a passage;
- listen for an audio tone with eyes closed;
- visual counting of rectangles of a chosen color on a computer screen;
- any mental thought of subject’s choice as their chosen “password”.
base
finger
sport
song
eye
color
pass
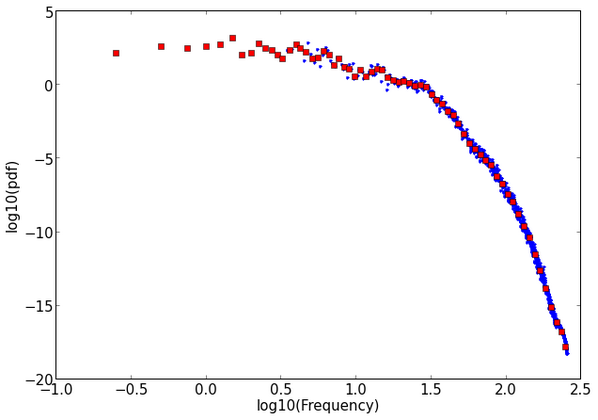
A single EEG reading. Each power spectrum is "quantized" by 100, logarithmically-spaced bins. This makes it fast enough to train SVMs quickly.
tutorial 1
distinguishing between mental gestures
pip install -U numpy scipy scikit-learn
git clone https://github.com/csmpls/sdha-svm.gitsetup
BAsic strategy
distinguishing whether a given eeg reading is gesture A or gesture B
- Train the classifier on the first trial of each gesture ( training set )
- Test the classifier on all the remaining trials - but only the first reading from each trial ( test set )
# training set
train_X,train_y = assemble_vectors(3,['color','pass'],[0], readings)
# fit SVM
clf = svm.LinearSVC().fit(train_X,train_y)
# testing set
test_X,test_y = assemble_vectors(3,['color','pass'], [1,2,3,4,5,6,8,8,9], [0])
predictions = clf.predict(test_X)
print score_predictions(predictions,test_y)tutorial1.py
never train on your test set ~
def train_and_test(subject_number, gesture_pair):
# training set
train_X,train_y = assemble_vectors(subject_number,gesture_pair,[0], readings)
# fit SVM
clf = svm.LinearSVC().fit(train_X,train_y)
# testing set
test_X,test_y = assemble_vectors(subject_number,gesture_pair, [2,3,4,5,6,8,8,9], [0])
predictions = clf.predict(test_X)
return score_predictions(predictions,test_y)
tutorial1.py
print train_and_test(1, ['color', 'pass'])
print train_and_test(3, ['color', 'pass'])
print train_and_test(4, ['song', 'sport'])- Try things, make observations
- List of tasks earlier in the slide
- Example questions:
- what is the best pair of gestures for subject 6?
- can we distinguish between 3 gestures?
Free exploration! (10 min)
tutorial 2
CALIBRATING A Brain-computer interface
inferring about the future
base vs color
color vs song
song vs sport
sport vs pass
pass vs song
pass vs sport
pass vs eye
eye vs base
. . .
Making predictions about reliability
CRoss-validation
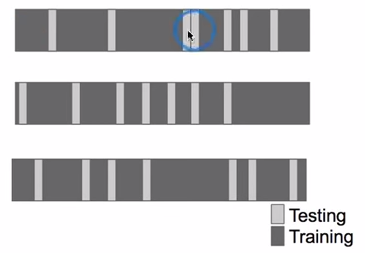
def cv_calibration_data(subject_number, gesture_pair):
# training set
train_X,train_y = assemble_vectors(subject_number,gesture_pair,[0,1,3,4,5,6], readings)
# fit SVM
clf = svm.LinearSVC().fit(train_X,train_y)
# cross-validate
cv_score = cross_validation.cross_val_score(clf,train_X,train_y, cv=7).mean()
print(subject_number, gesture_pair, cv_score)
cv_calibration_data(0,['pass','color'])
cv_calibration_data(12,['song','sport'])tutorial2.py
Does a gesture pair's cross-validation score predict how effective the classifier will be at distinguishing future recordings of those gestures?
20 minutes to answer this question as best you can
experiment / synthesis
identifying people based on their brainwaves
Can we tell people apart based on their brainwaves?
Can we tell any 2 people apart? Any 3 people? Are some mental gestures better than others for telling people apart? How much data do we need to distinguish people from one another? etc . . . . . . . .
whats next?
- multimodal input................"ensemble" technique
- asynchronous classification/interaction
- incremental/online learning
ffff@berkeley.edu