SELECT * from the_hard_stuff
SubQueries
Sub queries allow you to reference its results in the main query. It's super useful, but has some drawbacks:
- Can be detrimental to performances, often there are other more suitable solutions
- Can be hard to read and reason about
SubQueries in FROM or JOIN clauses
SELECT mytable.id, faketable.name
FROM table1,
(SELECT id, name FROM table2 where table2.table1_id = table1.id)
-- Note that this could (and should for performances and readability)
-- be written as an INNER JOIN.SELECT mytable.id, t2.name
FROM table1 t1
JOIN (SELECT name from othertable) t2 ON t2.table1_id = table1.id
-- This one is also quite useless tbh, it's just an example :)SubQueries in WHERE clauses
SELECT *
FROM beers
WHERE beers.price > (SELECT max(price) FROM wine)
-- Or is the hip on beer that crazy?SELECT *
FROM beers
WHERE beers.id IN (
SELECT beer_id
FROM favorite_beers f
GROUP BY f.beer_id HAVING count(*) > 10
)SubQueries in INSERT/UPDATE/DELETE clauses
Also, you can do this if you ever need to copy/paste a table:
INSERT INTO favorite_beers (beer_id, person_id)
SELECT beers.id, fab.id
FROM beers, (SELECT id from persons where name="fabrice" LIMIT 1) fab
WHERE beers.brewery="Kernel"INSERT INTO copy
SELECT *
FROM originalINSERT INTO copy
SELECT *
FROM originalDELETE FROM favorite_beers
WHERE beer_id IN (
select id from beers where name="Foster" OR brewery="Kronembourg"
)
-- Because come on, that's disgustingSubQueries in UPDATE clauses
UPDATE beers b
SET b.best_client=best.person_id
FROM (
SELECT person_id, count(*)
FROM favorites f
WHERE b.id=f.beer_id
GROUP BY person_id
ORDER BY count(*) DESC
LIMIT 1
) best
WHERE b.id=best.idWITH clause
Like a subquery but more l33t
What is the WITH clause
- The SQL WITH clause allows you to give a sub-query block a name... which can be referenced in several places within the main SQL query. - www.geeksforgeeks.org
- Can be thought of as a temporary table that's dropped once the query is completed
Why use a WITH clause instead of subqueries?
- Write once use throughout your query
- Often much easier to read than subqueries
- Helps to break down a problem into smaller steps
- Can be more efficient
SHOW ME SYNTAX!!!
INSERT INTO favourite_beers (beer_id, person_id)
-- Get Fabrice's id
WITH fabrice_id AS (
SELECT id
FROM persons
WHERE name="fabrice"
LIMIT 1
)
-- Get the ids of all beers from Kernel
, kernel_beers AS ( -- Use commas to add an additional named block
SELECT id
FROM beers
WHERE brewery="Kernel"
)
-- Cross join Fabrice's id to all kernel beers ids
SELECT k.id,
fab.id
FROM fabrice_id fab
JOIN kernel_beers kWindow functions
What is a "Window function"?
- It's not made of glass
- It's not about you Mr. Gates!
-
The PostgresSQL documentation definition:
“A window function performs a calculation across a set of table rows that are somehow related to the current row…Behind the scenes, the window function is able to access more than just the current row of the query result.”
- We can use most aggregate functions as window functions, but there are also some window specific functions
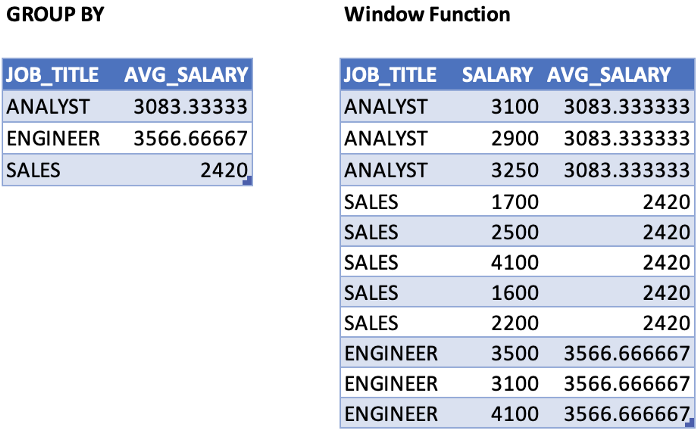
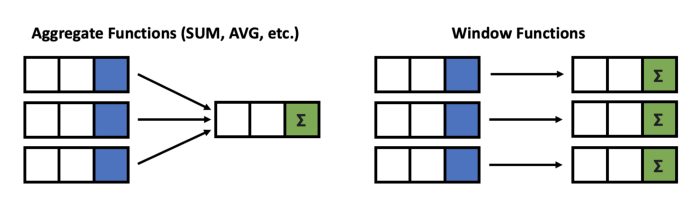
SELECT job_title,
salary,
AVG(salary) OVER (PARTITION BY job_title) AS avg_salary
FROM microsoftOver and partition by
Defining the window
- In order to use a window function you need to define the window
- You do this using the OVER function and defining how to "group" the data with the PARTITION BY clause
SELECT country,
state,
population,
SUM(population) OVER (PARTITION BY country) AS country_population
FROM the_worldIn this example we are calculating the total population of a country and showing it alongside the name and population of the states in that country.
Common mistakes: Why wouldn't this work?
SELECT country,
state,
population,
SUM(population) AS country_population
FROM the_world
GROUP BY country,
state,
populationCommon mistakes: Why wouldn't this work?
SELECT country,
state,
population,
SUM(population) AS country_population
FROM the_world
GROUP BY country,
state,
populationWe are grouping by the state and the population of that state so the country_population would be the same as the population of the state which is incorrect.
What about subqueries?
SELECT country,
state,
population,
c.country_population
FROM the_world w
JOIN (
SELECT country
SUM(population) AS country_population
FROM the_world
GROUP BY country
) AS c
ON w.country = c.countryThere are a few issues with this including readability and additional lines of code, but there's (at least) one mistake in this code.
Can you spot it? (Answer in speaker notes)
-- NB: Specific implementations and function names vary based on SQL dialect
-- Some of these examples are silly.
SELECT country,
state,
population,
-- ROW_NUMBER() Gives the row number in the window.
-- In this example we are showing how many states remain in the country list alphabetically.
ROW_NUMBER()
OVER(PARTITION BY country ORDER BY country DESC) - 1 AS states_remaining_in_country
-- LEAD() gives a value from further down the table.
-- In this example we are getting the name of the next state in the country alphabetically
LEAD(state,1)
OVER(PARTITION BY country ORDER BY country, state) as country_next_state_alphabetically
-- LAG() is similar to LEAD, but it looks back instead of forward.
-- In this example we are doing a running total of the population in a country.
population + LAG(population,1)
OVER(PARTITION BY country ORDER BY population ASC) AS pop_running_total
FROM the_world
ORDER BY country
,stateOther Window Functions