SQL -
SELECT * FROM the_basics
What's SQL?
- Hem... You should know 😈 It's a declarative database query language, AKA Structured Query Language
- There's a standard. Or 200. Each flavor of SQL is actually slightly different, we won't go in details
- Some are strongly typed, other not.
CRUD!
Create - INSERT
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...); Note that if the table has more columns than specified in the clause, null will be inserted
Read - SELECT
SELECT column1, column2, ...
FROM table_name; SELECT * FROM table_name; Update - UPDATE
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition; Warning: don't forget the condition. Why you say? Go figure it out :)
Delete - DELETE
DELETE FROM table_name WHERE condition;Warning: don't forget the condition. Why you say? Go figure it out :)
JOINS!
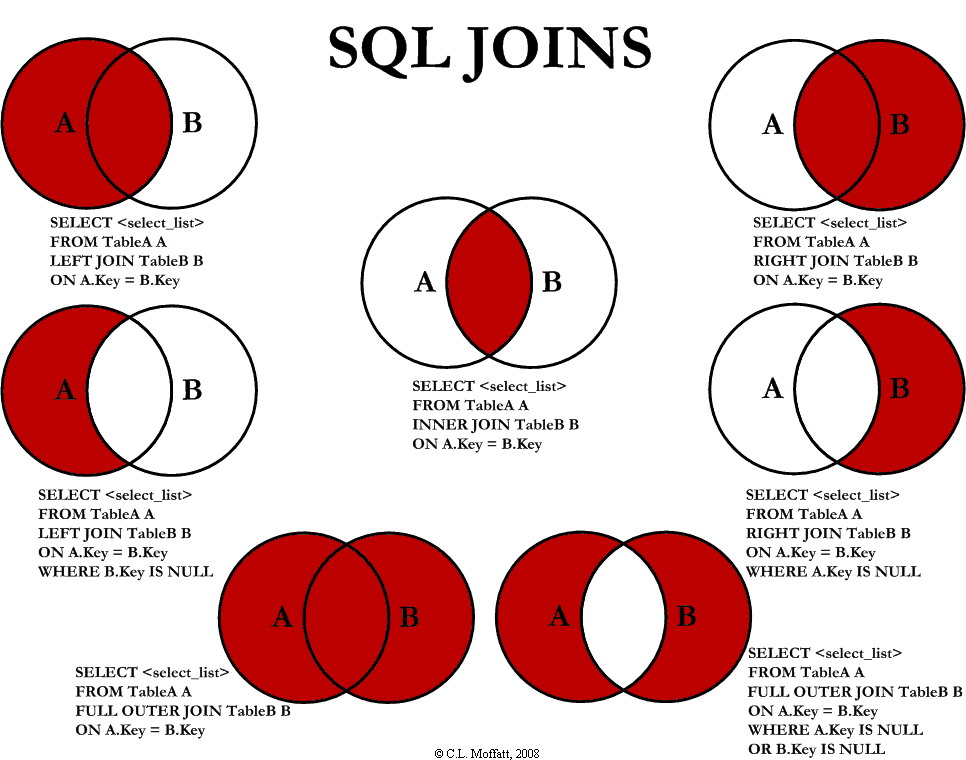
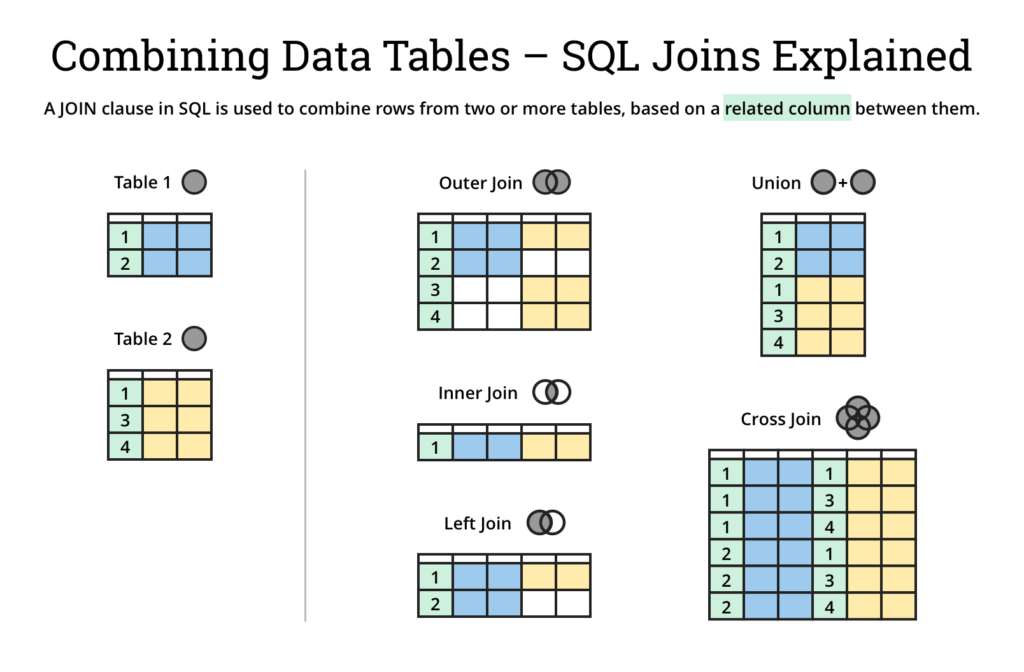
Joins and Columns
When returning result, you'll get columns from A and B together, and A or B columns may be set to null if outer join.
Join the columns of two tables based on a shared condition
Syntax
JOIN new_table
ON existing_table.column = new_table.column
AND other_conditions
Default JOIN is inner JOIN
Watch outs
- Can lead to repeated data
- Exponentially large result set
- Be deliberate in what the conditions are
- Inner joins will exclude data from both tables
- Check that the data makes sense before calling it a day
Data types
Each DB will have its own types, but here's a few common ones
- Varchar is closest to "String" it will have a max length
- Text is also closest to "String", unspecified max length
- Various numbers (int, decimal, float...)
- Dates. Format usually is 'YYYY-MM-DD HH:mm:ss'. Sensible!
- Timestamp - well, that's an int. At least it's stored like taht, depends of implementation
- Casting is a thing:
- CAST(<value> AS <type>)
Useful clauses
Like
-- starts with Fab, any cahrs after
select firstname from persons where names LIKE 'Fab%';
-- % means any chars
select firstname from persons where names LIKE '%ab%';
-- _ mean any 1 char
select firstname from persons where names LIKE 't_t_'; This is an expensive operation, it's better to do an exact match or at least use % at the end, not the beginning
IN
select firstname from persons where firstname IN ('Fabrice', 'Chris');
select firstname from persons where firstnam NOT IN ('Fabrice', 'Chris');IS NULL
select firstname from persons where firstname IS NULL;
select firstname from persons where firstname IS NOT NULL;Note that we can't use firstname = NULL
LIMIT
-- Get only the 1st record
select firstname from persons LIMIT 1;Each implementation is different
Aliases
Give a table an alias so that you don't have to type out the full name.
SELECT tn.column1
FROM table_name AS tn
JOIN second_table st
ON tn.id = st.id
; Aliases
Rename a column to something more useful or to differentiate between two different columns with the same name.
SELECT tn.column1 AS fancy_column,
st.column1
FROM table_name AS tn
JOIN second_table st
ON tn.id = st.id
; Functions
SQL has a number of functions.
Usually used to transform a value, or for aggregation.
Note this again varies a lot from implementation to implementation
-- All Date functions - datediff, adddate, ...
-- All String functions - concat, substring, ...
-- All numeric functions - round, ...
SELECT IF(500<1000, "YES", "NO");
SELECT IFNULL(NULL, "toto");
SELECT CAST("2017-08-29" AS DATE);
SELECT OrderID, Quantity,
CASE
WHEN Quantity > 30 THEN "The quantity is greater than 30"
WHEN Quantity = 30 THEN "The quantity is 30"
ELSE "The quantity is under 30"
END
FROM OrderDetails; Group By
Group By is used in a SELECT statement to aggregate rows.
Let's say you have a Book table with author & title, you can run the following query to see how many books each other wrote:
select author, count(*) from books group by author;Something people are often tempted to do, but doesn't work:
select author, parution_date, count(*) from books group by author;The engine has no way to choose which book it should take the Parution_date from
Having
People are often confused by "Having" clause.
I think one way to see it is - it's like a WHERE clause, but that happens AFTER the aggregation. Here's an example:
select author, count(*) from books group by author HAVING count(*) > 1;Something people are often tempted to do, but doesn't work:
select author, parution_date, count(*) from books group by author;The engine has no way to choose which book it should take the Parution_date from
Just for fun - Do you see what that does?
SELECT author, YEAR(parution_date) as parution_year, count(*) AS book_count FROM books
GROUP BY author, YEAR(parution_date) HAVING count(*) > 0
ORDER BY parution_year ASC, book_count DESC;Order By
-- Ordering
select * from persons order by lastname DESC, firstname DESC