Analysing the Convergence and Divergence of Language Models
Introduction
Introduction
Vaswani et al. (2017)
Huh et. al (2024)
Chang and Bergen (2022)
ChatGPT (2022)
Scaling and multi-modal
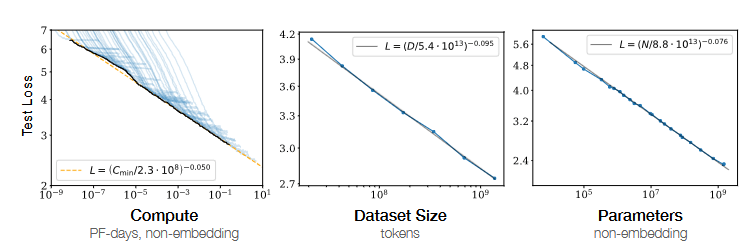
Kaplan/Hennigan et al. (2020)
Objective & Significance
- Analyse convergence of model probabilities
- Quantify impact of different features
- Large(r) randomly initialised models converge during training; behaviour for smaller models is unclear
- Hypothesise different phases of word acquisition
Background
Language Models
Bengio et al. (2003), Mikolov et al. (2013), Vaswani et al. (2017)
Evolution in Training
Chang and Bergen (2022), Meister et al. (2023), Huh et al. (2024)
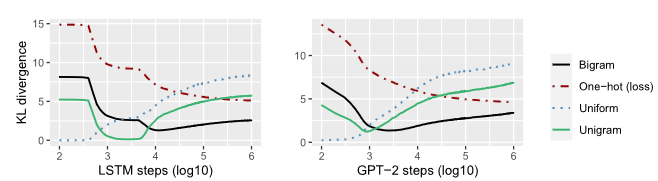
KL divergence between probabilities output and various distributions
Methodology
Kullback Leibler Divergence
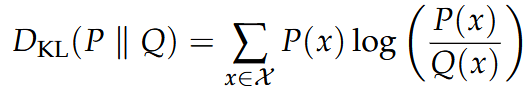
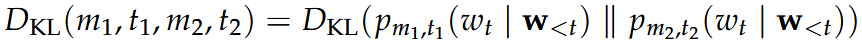
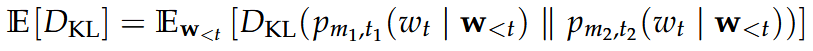
Short hand notation between models:
We compute the expectation
by approximating over the samples
Cross-Entropy
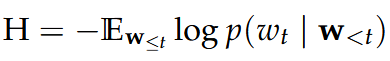
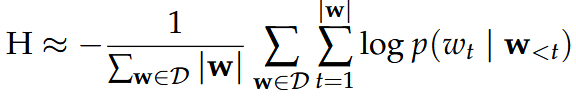
Definition:
Approximation with validation set samples:
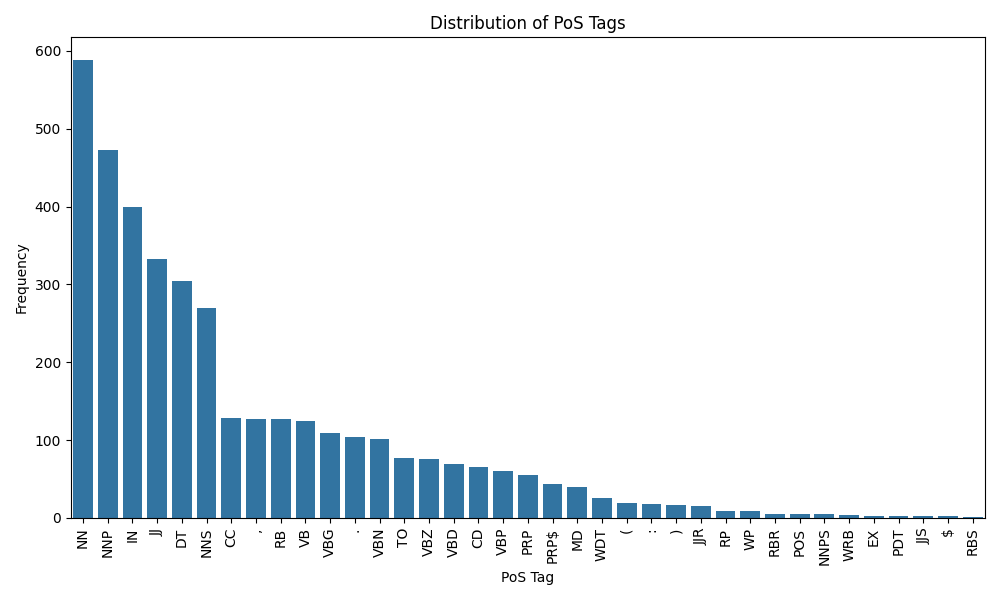
Frequency
Part of Speech
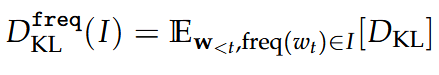
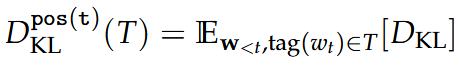
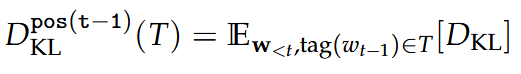
By predicted:
By context:
Begin/End of Word
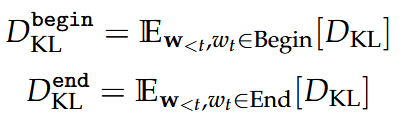
Experimental Setup
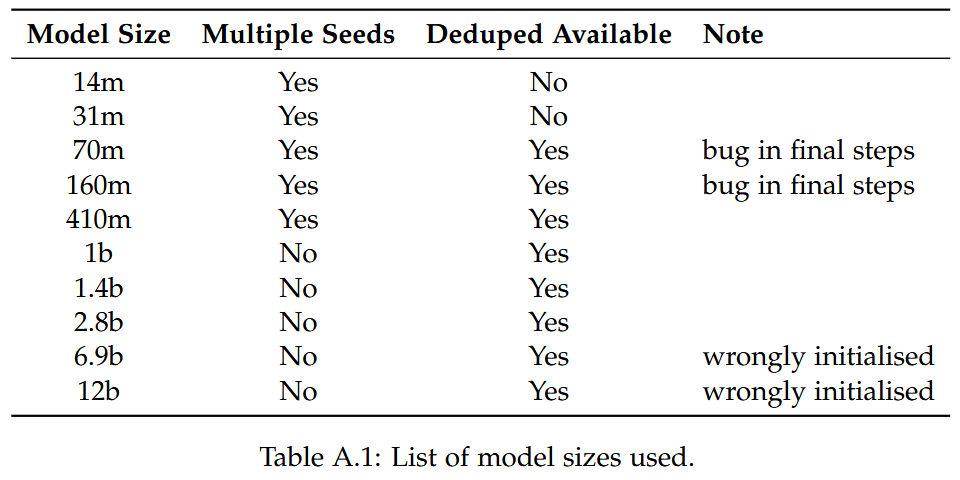

Model Selection
- Pythia models (Biderman et al., 2023)
- Logarithmic steps
- Random seeds 1, 3, 5, 7, 9
Model Selection
- Pythia models (Biderman et al., 2023)
- Logarithmic steps
- Random seeds 1, 3, 5, 7, 9
Model Selection
- Pythia models (Biderman et al., 2023)
- Logarithmic steps
- Random seeds 1, 3, 5, 7, 9
Model Selection
- Pythia models (Biderman et al., 2023)
- Logarithmic steps
- Random seeds 1, 3, 5, 7, 9
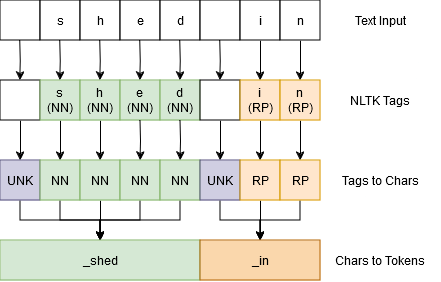
Part of Speech Tagging
Part of Speech Tagging
Part of Speech Tagging
Part of Speech Tagging
Results
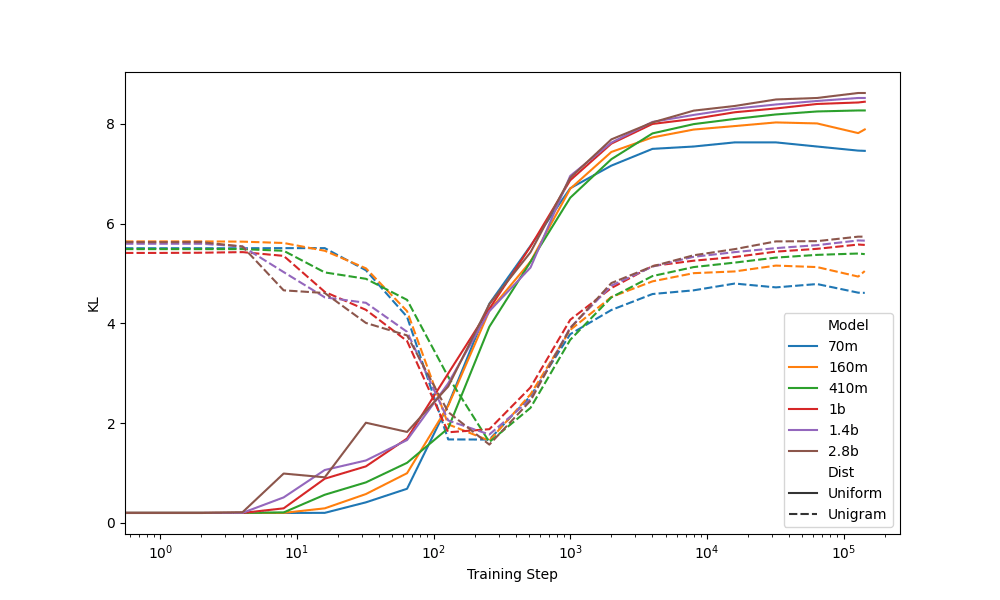
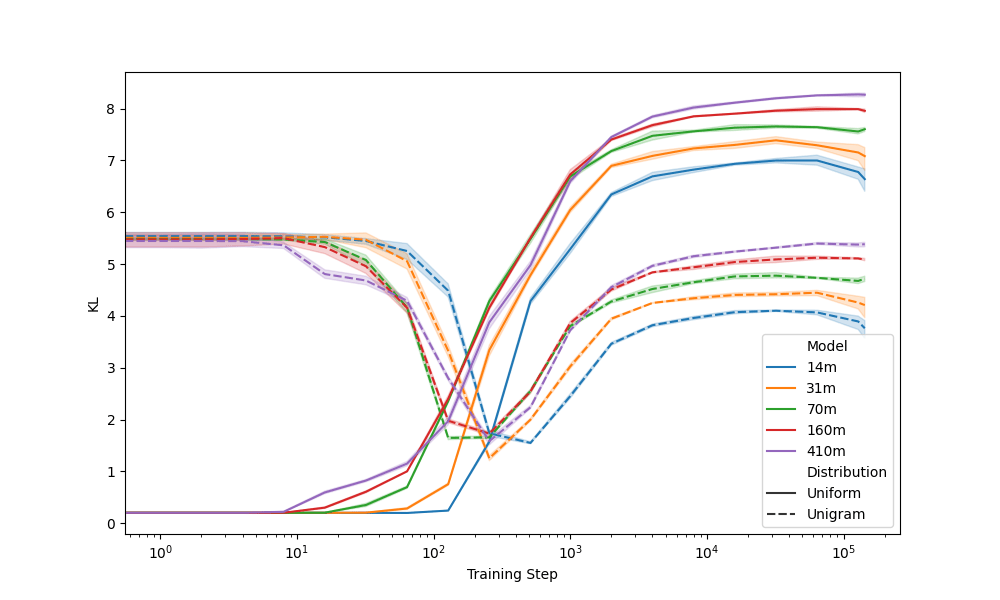
Reference Distributions
Reference Distributions
Reference Distributions
Convergence to unigram around 256 steps
Relative Divergences
Goal: Determine relatively significant P.o.S. at each training step
For predicted token:
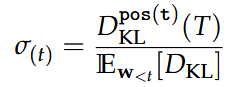
For context token:
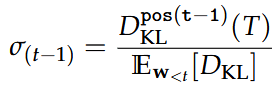
Looking for outliers =/= 1
Relative Divergences
Relative Divergences
Looking at learnability
Relative Divergences
all, either, every ...
Relative Divergences
all, either, every ...
Trump, Escobar, Zurich
Relative Divergences
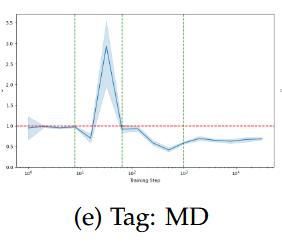
can, may, need ...
Relative Divergences
can, may, need ...
all, either, every, ...
Training Phases
- Uniform Phase (until approx. step 8)
- Functional Universality Phase (approx. step 8 to 64)
- Unigram Transition Phase (approx. step 64 to 1000)
- Contextual Learning Phase (approx. step 1000 onwards)
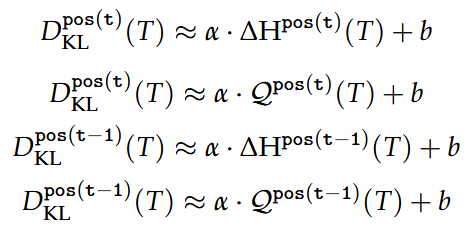
Cross-Entropy Fitting
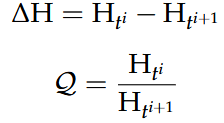
Cross-Entropy Fitting
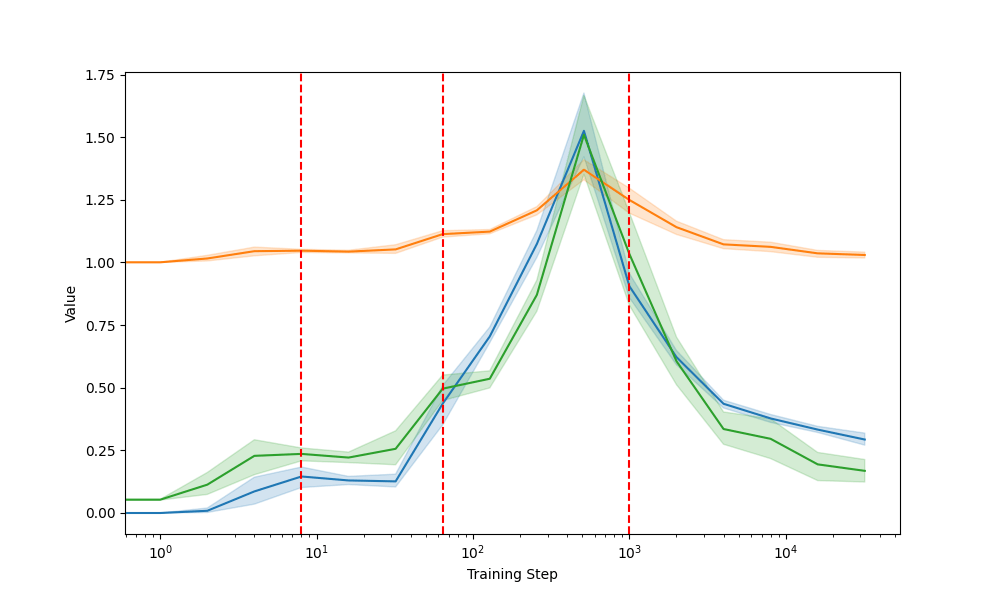
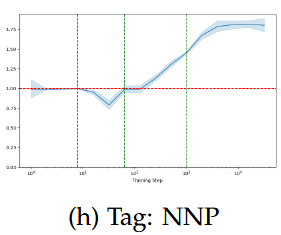
pos(t-1); NNP - e.g. Switzerland, Zurich
Cross-Entropy Fitting
pos(t-1); NNP - e.g. Switzerland, Zurich
Cross-Entropy Fitting
pos(t-1); NNP - e.g. Switzerland, Zurich
Cross-Entropy Fitting
pos(t-1); NNP - e.g. Switzerland, Zurich
Greater sensitivity is connected to higher divergence in later steps
Cross-Entropy Fitting
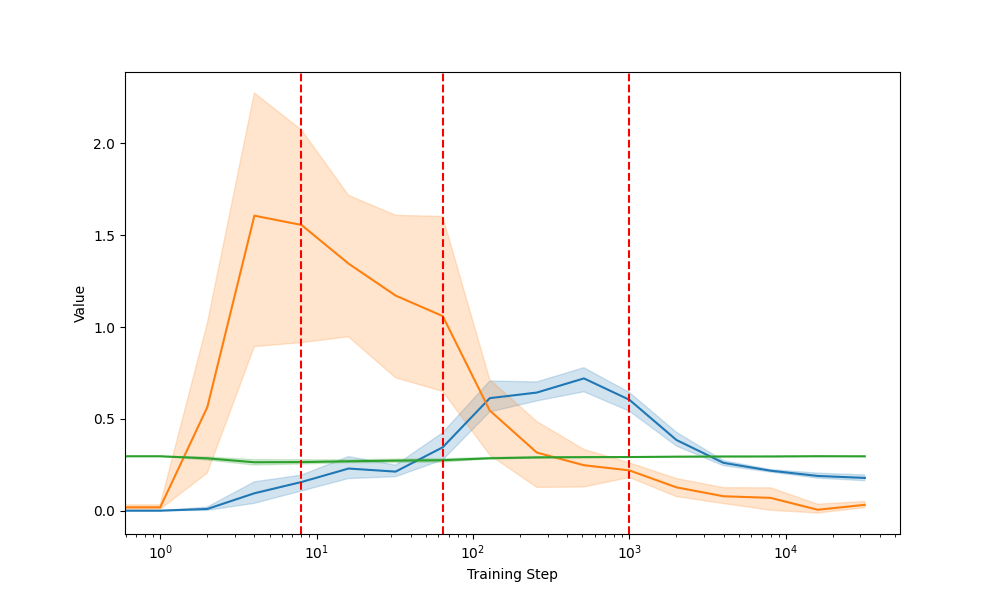
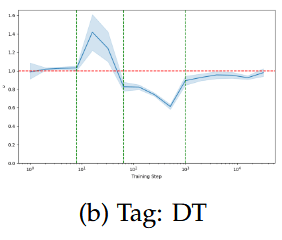
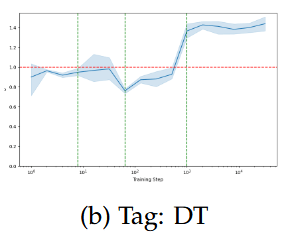
pos(t); DT - e.g. all, either, there
Cross-Entropy Fitting
pos(t); DT - e.g. all, either, there
Cross-Entropy Fitting
pos(t); DT - e.g. all, either, there
For (early) functional linguistic features, KL lags CE
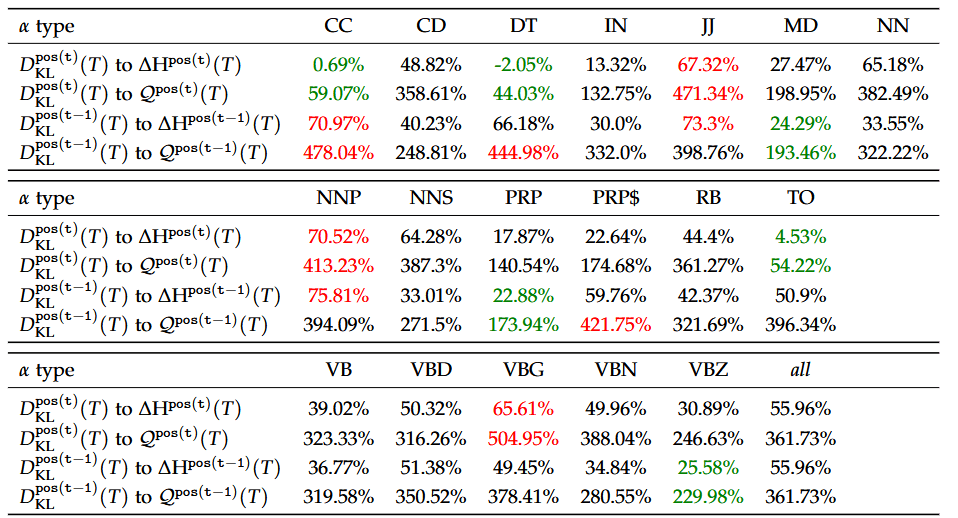
Cross-Entropy Fitting
Holds true for both fitting by ratio / difference
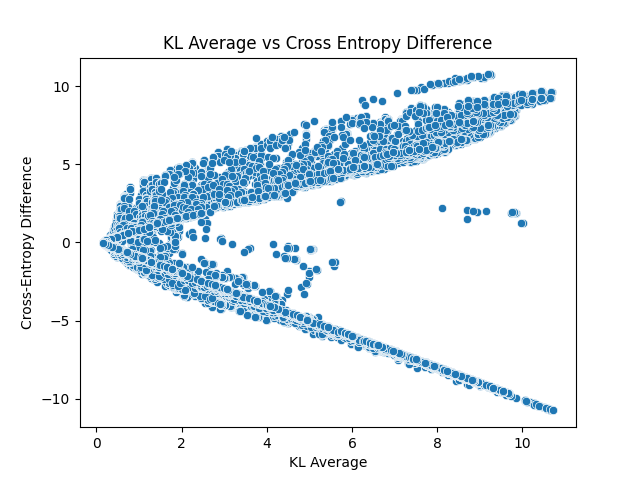
Cross-Entropy Difference
Cross-Entropy Difference
Cross-Entropy Difference
Cross-Entropy Difference
Low cross-entropy difference is a necessary condition for low KL!
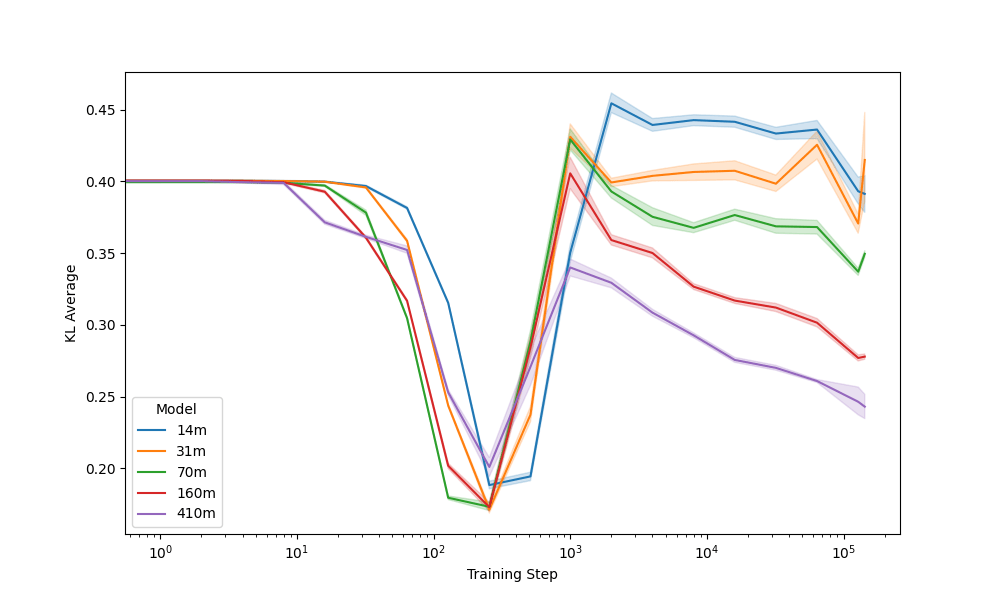
Seed Comparison
Seed Comparison
Seed Comparison
Seed Comparison
Seeds: Frequency
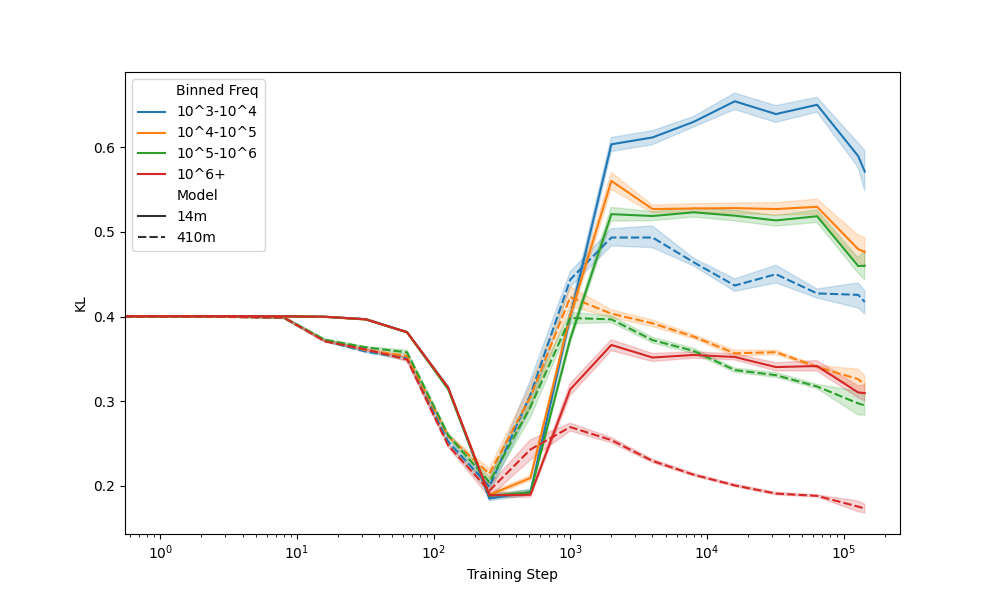
Seeds: Frequency
Seeds: Frequency
Seeds: Frequency
Seeds: Nouns
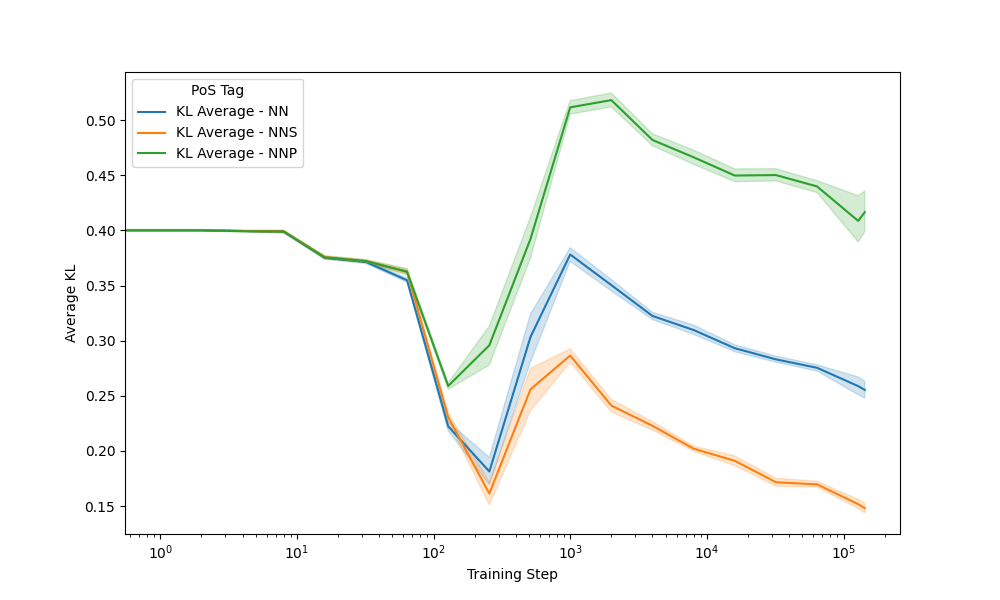
Context
Prediction
410m model - NN: house, cat, dog - NNP: ETH
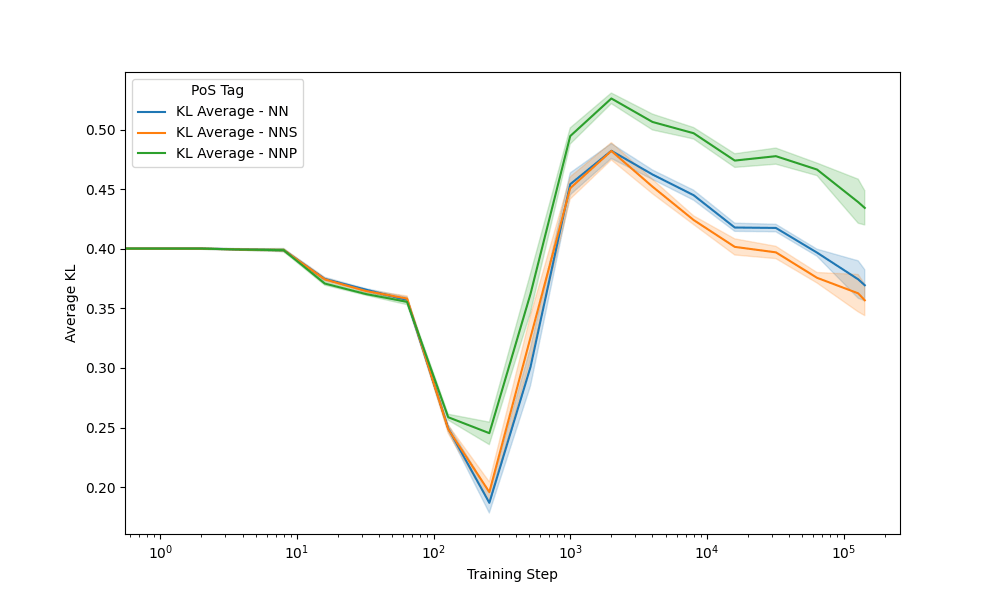
Seeds: Nouns
Context
Prediction
410m model - NN: house, cat, dog - NNP: ETH
Seeds: Verbs
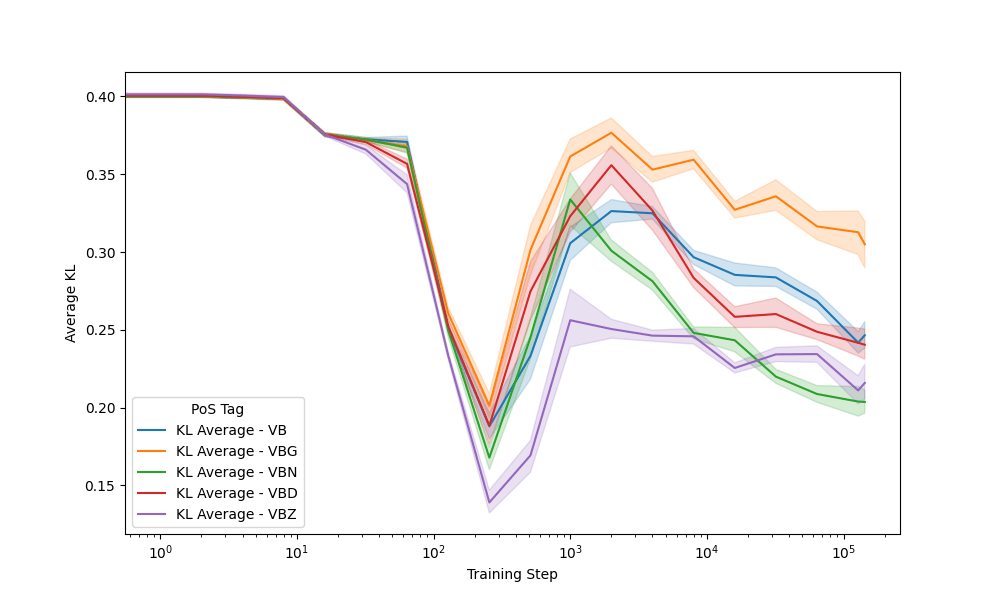
Context
Prediction
410m model - VBG: eating - VBN: called
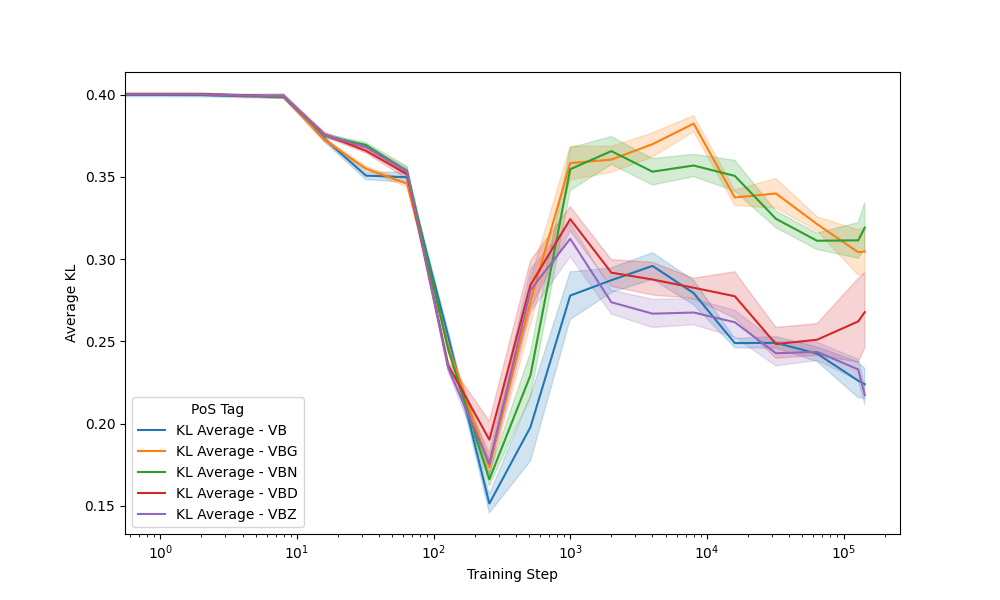
Seeds: Verbs
Context
Prediction
410m model - VBG: eating - VBN: called
Seeds: Other P.o.S.
Context
Prediction
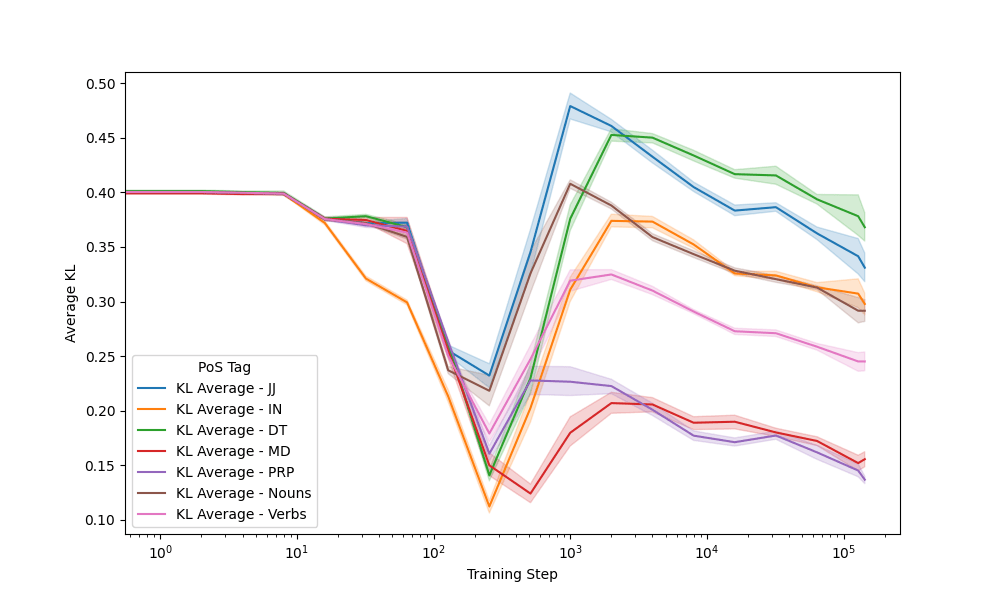
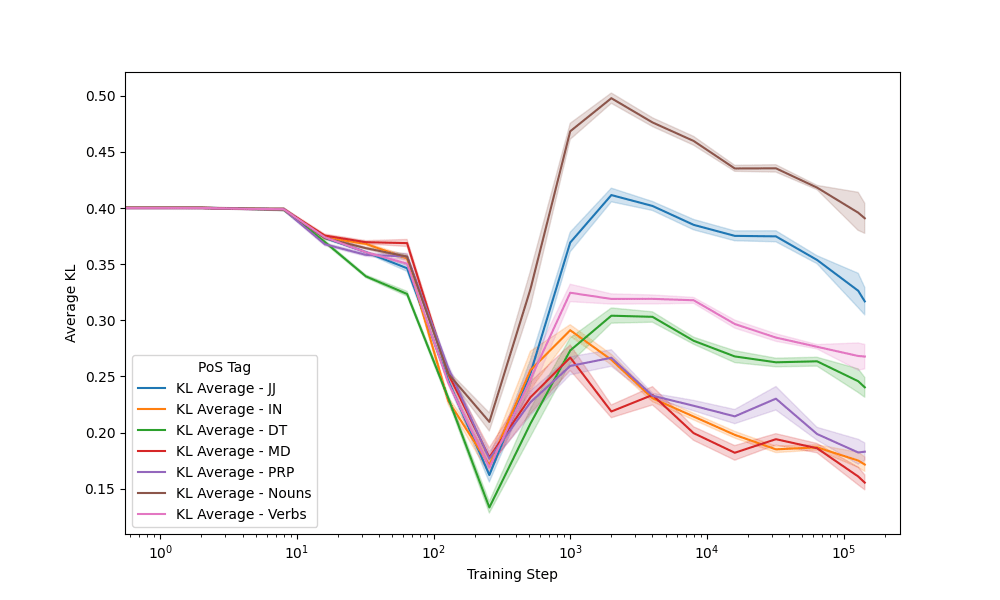
410m model
Earlier divergence in training correlates to greater stability later on
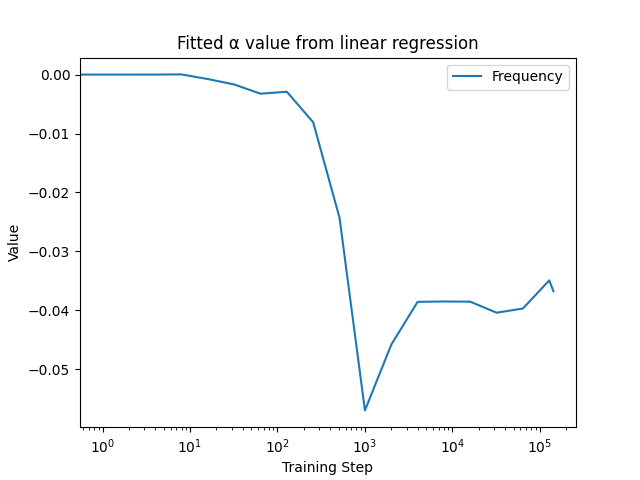
Linear Regression
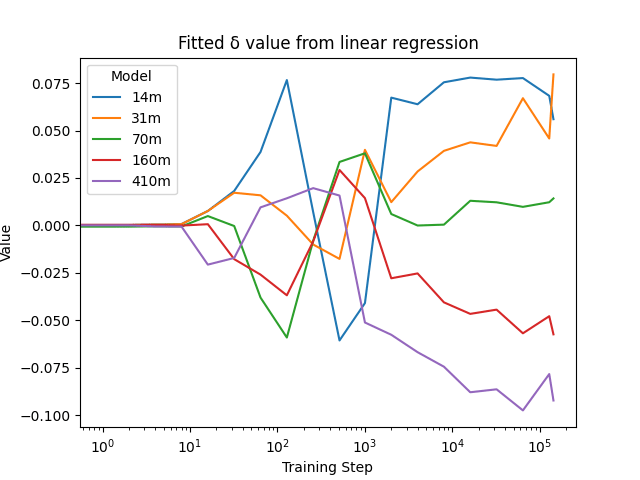
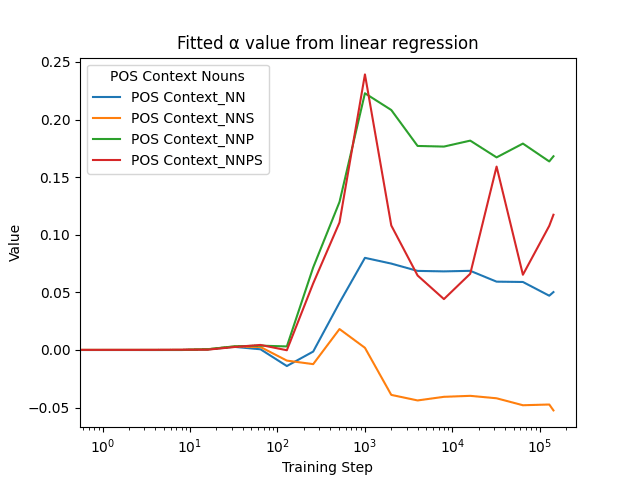
Linear Regression
Conclusion
Summary
- Trajectory in model training
- Model size's role in enhancing self-consistency
- Significant differences by part of speech
- Efficiency gains can likely be made by adapting model training to linguistic structure
Limitations & Future Work
- Lack of different model architectures
- No variability in tokenisers
- Issues with Pythia model suite
- Improvement by emphasis on unstable linguistic features
- Connection between KL and cross-entropy could help improve model performance
- Focus on multi-lingual P.o.S. features