PostGIS Memento
{ "name": "Felix Kunde" , "email": "fkunde@virtualcitysystems.de"}
{ "conf": "FOSSGIS 2015", "where":"Muenster", "when":"2015-03-12T15:00:00+01:00"}
{"geometry": {"type": "Point", "coordinates": [7.613056, 51.9637] }}
Hintergründe
Motivation
Umsetzung
Roadmap
Versionsverwaltung für 3D-Stadtmodelle

Bisherige Lösung für 3DCityDB
Versionsverwaltung eines proprietären DBMS
Lineare Versionierung mit Zeitstempel
Erlaubt Arbeiten in verschiedenen "Workspaces"
Merging von Workspaces ist möglich
In der Theorie super, in der Praxis ... schwierig ...
Einsichten
Klare Trennung von Produktions- und Archivdaten
Transparenz bei archivierten Daten
Datenbankperformance darf nicht leiden
Motivation
Versionsverwaltung für PostgreSQL in der Datenbank
Lineare Versionierung durch getriggerte Aufzeichnungen
Zugriff auf komplette frühere Versionen nur über Ausspielung in separates Schema einer Datenbank (entweder als Sicht oder Tabelle)
Aber: Direktes Revertieren einzelner Transaktionen
Hierarchische Versionierung ebenfalls über Schemata lösen
Vorhandene Lösungen
- audit trigger 91plus by ringerc
- tablelog by Andreas Scherbaum
- Cyan Audit by Moshe Jacobsen
- wingspan-auditing by Gary Sieling
- pgaudit by 2ndQuadrant
QGIS DB Manager

Geodaten versionieren
- QGIS Versioning Plugin by OSLandia
-
pgVersion by Horst Düster
- GeoGig by Boundless
- (Interactive map tracking by Lionel Atty, Remi Cura)
PostgreSQL Logical Decoding
neue API seit 9.4 für Zugriff auf Replikationsströme von Daten
dekodiert die Aufzeichnungen des Write-Ahead-Log
ermöglicht Bidirektionale Replikation >> Multi-Master-Cluster
Ausspielung von Veränderungen in Replication Slots
Auditing und Versionierung möglich
Output plugins: WAL-Format >> gewünschtes Format
Weitere Infos: Doku, Postgres Open, FOSDEM, PgConfRu
Der Beginn von pgMemento
Tabellenzeile >> row_to_json(OLD) >> JSON
JSON >> json_populate_record(null::test_table, JSON) >> Tabellenzeile
Generisches Tracking

Setup
PL/pgSQL Skripte ausführen
Trigger anlegen
Zusätzliche Audit_ID Spalte anlegen
Bestehende Daten als "eingefügt" loggen
Log Tabellen
transaction_log ( txid BIGINT, stmt_date TIMESTAMP, user_name TEXT, client_name TEXT); table_event_log ( id SERIAL, transaction_id BIGINT, op_id SMALLINT, table_operation VARCHAR(8), schema_name TEXT, table_name TEXT, table_relid OID); row_log ( id BIGSERIAL, event_id INTEGER, audit_id BIGINT, changes JSONB);
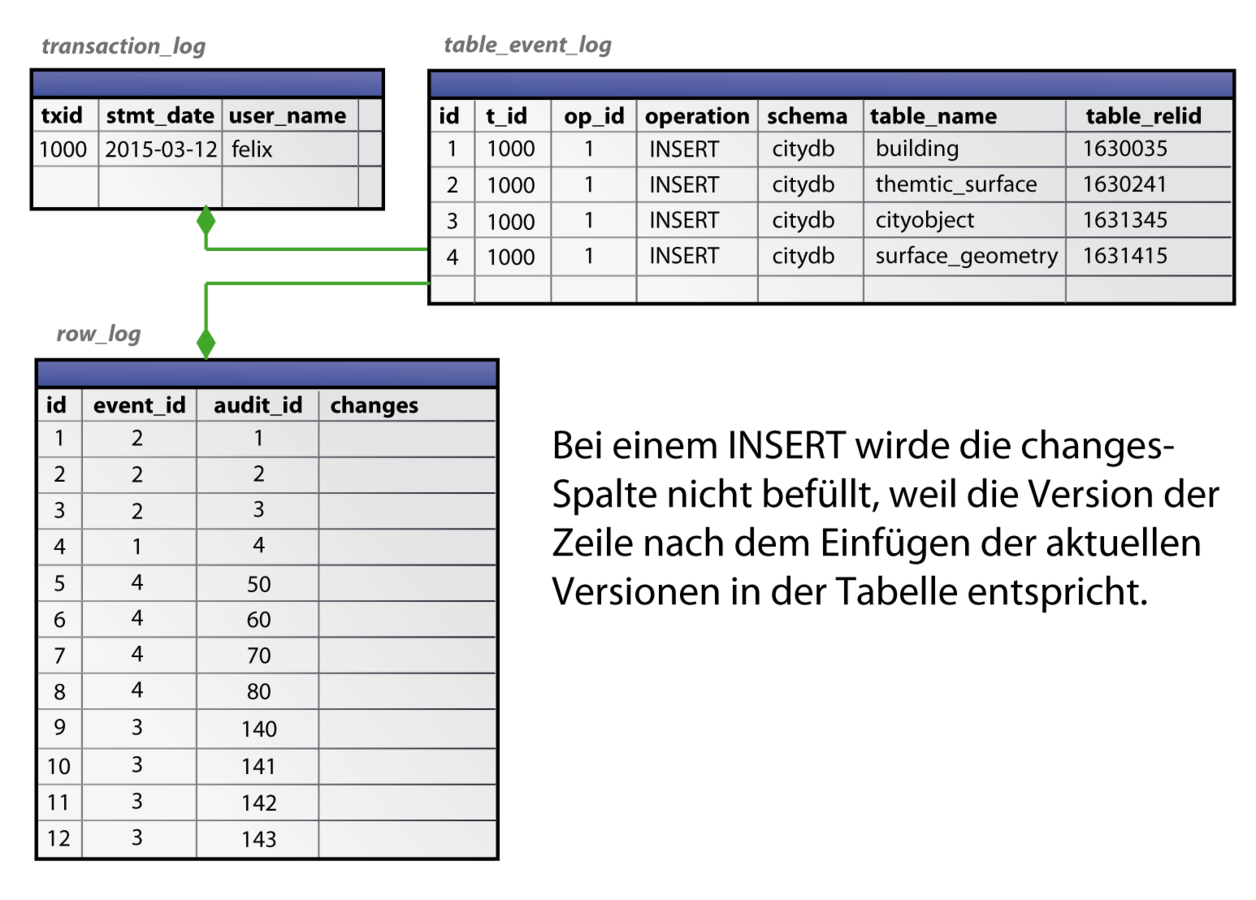
Beispiel: INSERT

Beispiel: INSERT
Beispiel: UPDATE
UPDATE building SET measured_height = 12.8 WHERE id = 1;
Beispiel: DELETE

Schnelle Abfragen dank GIN Index
CREATE INDEX row_log_changes_idx ON pgmemento.row_log USING GIN (changes); Suche nach Transaktion, die Änderung einer Spalte durchführte
SELECT t.txid
FROM pgmemento.transaction_log t
JOIN pgmemento.table_event_log e ON t.txid = e.transaction_id
JOIN pgmemento.row_log r ON r.event_id = e.id
WHERE
r.audit_id = 4
AND
(r.changes ? 'measured_height');
-> Index Scan using row_log_audit_idx on row_log r
Index Cond: (audit_id = 4)
Filter: (changes ? 'measured_height'::text) Suche nach alten Werten
SELECT DISTINCT audit_id FROM pgmemento.row_log
WHERE
changes @> '{"measured_height": 0.0}'::jsonb;
-> Bitmap Index Scan on row_log_changes_idx
Index Cond: (changes @> '{"measured_height": 0.0}'::jsonb)
Restore einer Tabelle oder Datenbank
SELECT pgmemento.restore_schema_state(
1002, -- Zeitpunkt vor Transaktions ID
'citydb', -- Quellschema
'state_before_delete', -- Zielschema
'TABLE', -- Wiederherstellungstyp
ARRAY['spatial_ref_sys'] -- Ausnahmen
); Was passiert im Hintergrund?
- Ermittle valide Zeilen zum gesuchten Zeitpunkt?
- Sammle Audit_IDs kleiner Transaktions-ID (Distinct)
- Schließe Audit_IDs aus, die zu gelöschten Einträgen gehören

Alte Werte finden
- Ermittle Spalten einer Tabelle zum Zeitpunkt x.
- Suche das nächste Auftreten des Spaltennamen in den Logs (also Audit_ID >= Transaktions_ID, denn bei Audit_ID < Transaktions_ID findet man nur vergangene Werte)
- Wenn kein Ergebnis, dann jeweilige Tabelle abfragen

JSONB Fragmente verbinden
) -- hier endet WITH Block, der valide audit_ids sammelte
SELECT v.log_entry FROM valid_ids f
JOIN LATERAL ( -- muss für jede audit_id erfolgen
SELECT json_build_object(
q1.key, q1.value,
q2.key, q2.value,
...)::jsonb AS log_entry
FROM ( -- Abfragen nach alten Werten (vorheriger Schritt)
SELECT q.key, q.value FROM (
SELECT 'id' AS key, r.changes -> 'id'
FROM pgmemento.row_log r ...
)q ) q1,
SELECT q.key, q.value FROM (
SELECT 'name' AS key, r.changes -> 'name'
FROM pgmemento.row_log r ...
)q ) q2, ...
Wiederherstellung der Tabelle
) -- die vorherigen Schritte erfolgten in einem WITH Block
SELECT p.* FROM restore rq
JOIN LATERAL (
SELECT * FROM jsonb_populate_record(
null::citydb.building, -- Template
rq.log_entry -- zusammengesetztes JSONB
)
) p ON (true)
Transaction Revert
- Fall: Wenn gelöscht >> INSERT
- Fall: Wenn aktualisiert >> UPDATE
- Fall: Wenn eingefügt >> DELETE
Korrekte Sortierung nach Audit_IDs verhindert Foreign Keys Violation
Abfrage für Revert
SELECT * FROM (
(SELECT r.audit_id, r.changes, e.schema_name, e.table_name, e.op_id
FROM pgmemento.row_log r
JOIN pgmemento.table_event_log e ON r.event_id = e.id
JOIN pgmemento.transaction_log t ON t.txid = e.transaction_id
WHERE t.txid = $1 AND e.op_id > 2 -- DELETE oder TRUNCATE
ORDER BY r.audit_id ASC) -- die ältesten Werte zuerst einfügen
UNION ALL
(SELECT ...
WHERE t.txid = $1 AND e.op_id = 2 -- UPDATE
ORDER BY r.audit_id DESC) -- die jüngsten Werte zuerst aktualisieren
UNION ALL
(SELECT ...
WHERE t.txid = $1 AND e.op_id = 1 -- INSERT
ORDER BY r.audit_id DESC -- die jüngsten Werte zuerst löschen
) txid_content
ORDER BY op_id DESC -- erst DELETEs, dann UPDATEs, dann INSERTs verarbeiten
Baustellen
Revertieren bisher etwas zu simpel
Filter bei Restore (nach Zeit, BBox etc.)
Kein Tracking von DDL-Befehlen
Kein Merging zwischen Schemata
Wenig Benchmarking
Mehr Restriktionen und Sicherheit der Logs
Keine GUI, reines SQL-Coding
Weitere Anmerkungen
Für schreiblastige Datenbanken wahrscheinlich ungeeignet, da hoher Speicherverbrauch (obwohl nur Deltas gespeichert werden)
Log-Tabellen sind leicht angreifbar und kein Ersatz für Backups und Recovery Werkzeuge
Repository
https://github.com/pgMemento/pgMemento
Gibt es Fragen ?
Kontakt:
Felix Kunde
fkunde@virtualcitysystems.de
+49(0)30 890 48 71 - 42