How to avoid overfitting
How to make trading strategies that work well in future
Three truths of data-science
1. We don't care about past performance of a model. We care about how it will perform in future. 2. Past data is all we have to learn from. We don't have data of what will happen in future. 3. Not all aspects of past data are equally likely to occur in future.
The process of making a trading strategy
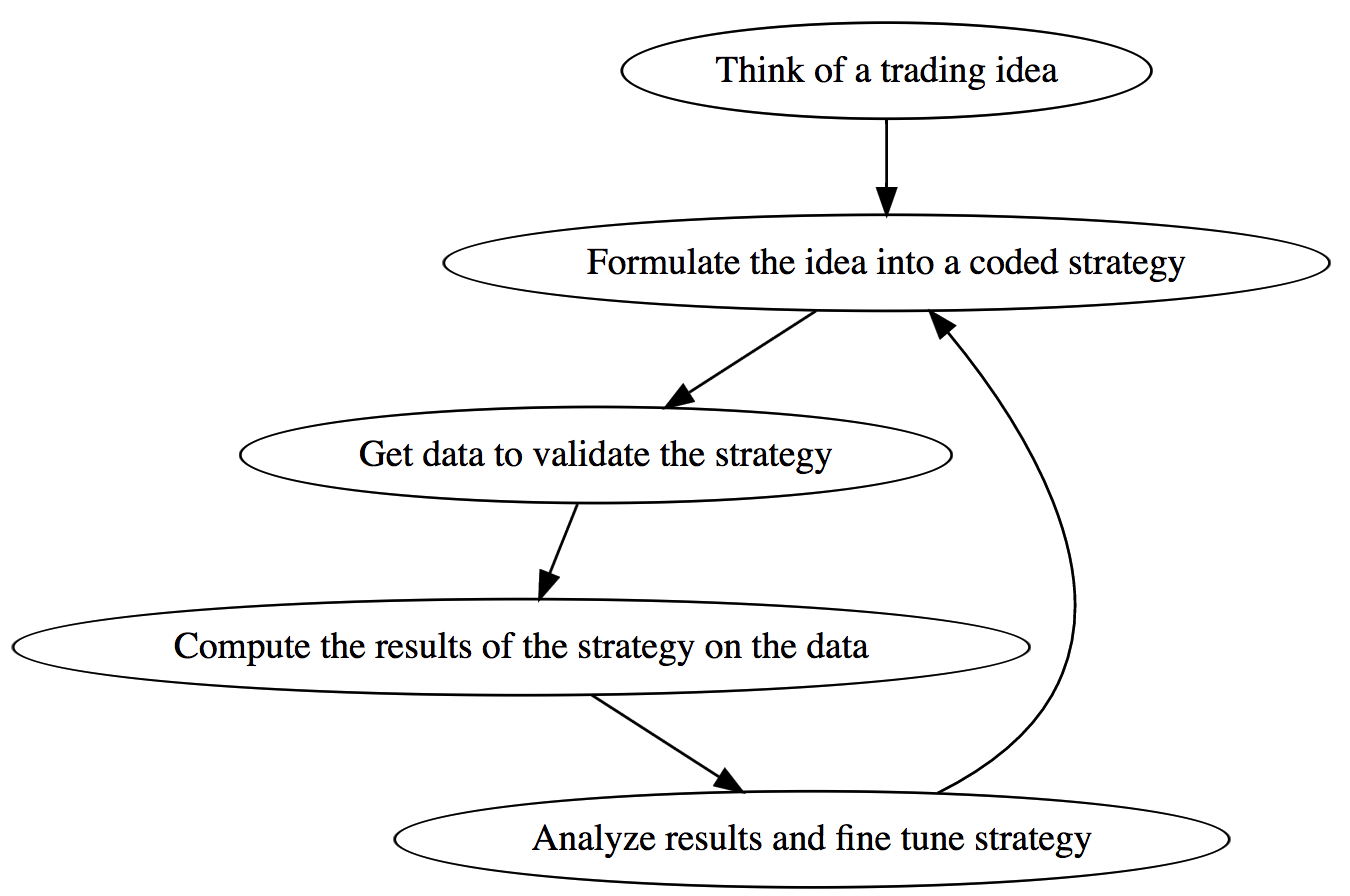
What is meant by overfitting?
"We can call a strategy overfitted if the returns are much worse on out-of-sample data than in-sample data." - Mansi
"Speaking from an accounting and compliance background, the promotional material and back tests shown by the portfolio manager is an implicit promise about the future. We need to have a set of standards around honest back testing" - Kaushal
"Overfitting is about making sure that our work is long-lasting. I could keep toiling all my life in finding out what would have worked yesterday. Focus on learning lasting truths." -Ankit
"If the strategy was meant for a certain type of market condition then we can call it overfit if that market condition reoccurs and yet the strategy is not able to profit." - Hardik
"The goal is to deliver what we promise. Overfitting fails that promise" - Nilesh
Real life experiments with overfitting and underfitting
- Trading group D would regenerate their model once in three months using as much data as they could get their hands on and with the train-test approach to splitting data. ( underfitting )
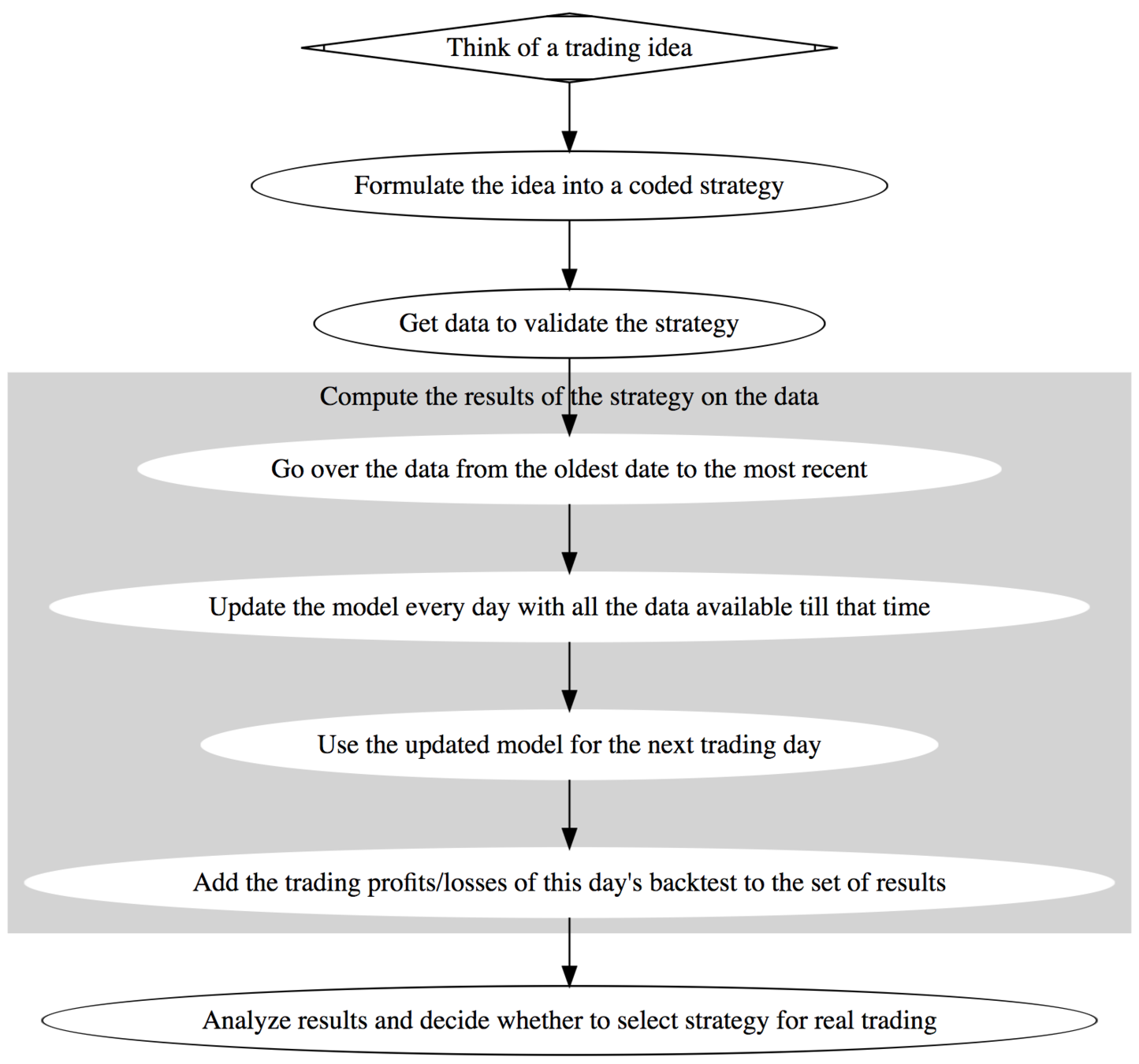
- Trading group J would regenerate the model every day using last five days data. ( walk-forward backtesting)
The problem with D's approach is that in trading there is a lot of seasonality. Ignoring the most recent data in model training will lead to under-fitting. Doing so, however, precludes that data from being used in model evaluation.
J's approach takes care to use most recent data without using the same data in evaluating the model that was used to train it.
How do data-scientists avoid overfitting?
-
Take as much data as you can possibly get to verify your ideas. -
Optimize metrics like Sharpe Ratio and not based on returns. -
Labeled data is expensive. Maximize what you can learn from unlabeled data before you start learning from labeled data. -
Split data into training and testing. However, this can be tough and impractical when trying to learn ideas that are short-lived. -
Walk-forward optimization: Measure your strategy strictly in accordance with 2nd truth. -
Think in terms of future-testing and not back-testing.
Walk-forward = No cheating
Presentation Video
Let's learn together
Our aim here at FinTech - DataScience - NY/JC meetups is for people to come together and share with others what they have learned, towards building a better future.
If you want to want to present at our meetups please email at community@qplum.co