An Investigation of Unified Memory Access Performance in CUDA
GPU Microbenchmarks
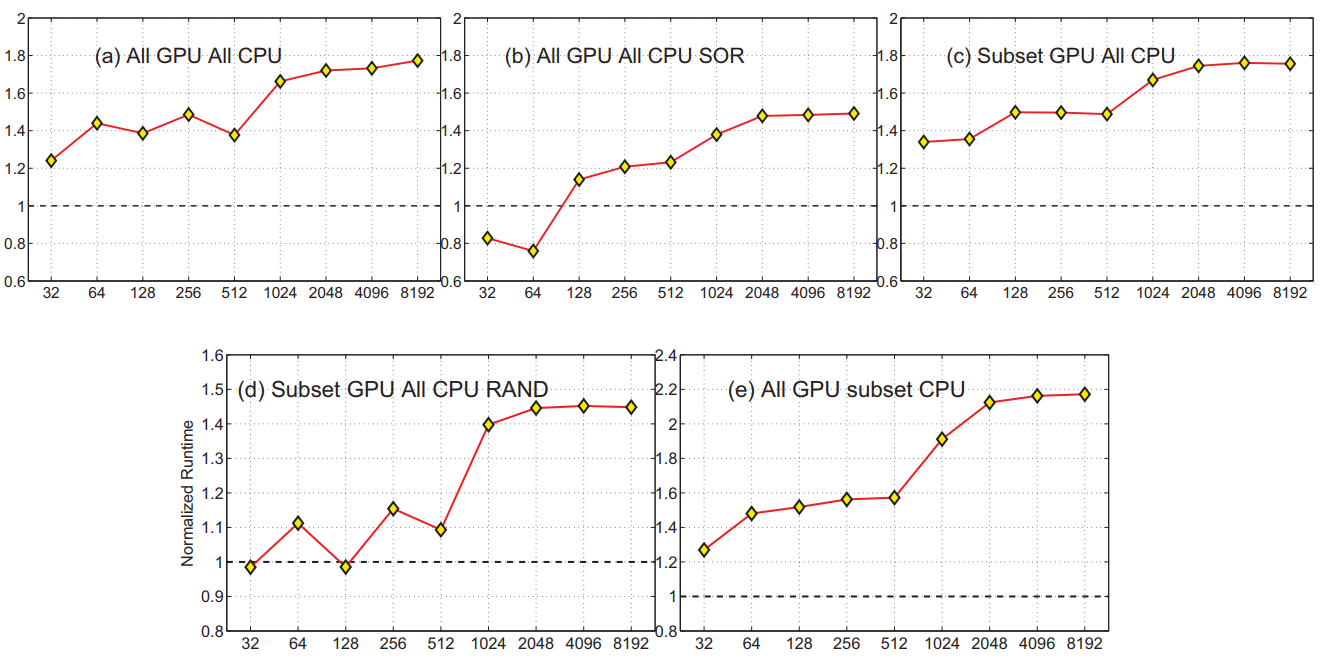
All GPU All CPU
All of the elements in the matrix are accessed by the GPU during computation. Each element is simply incremented by one in place. Data is transferred to the CPU and all of the matrix elements are incremented by one again to simulate an exhaustive post processing.
All GPU All CPU SOR
This kernel requires significantly more memory accesses, more threads, and is performed out of place, requiring an input and output matrix.
We implement this kernel to observe the effect of more complex memory access patterns on the runtime of UMA.
Subset GPU All CPU
On the host CPU, three elements are chosen at random and provided to the GPU kernel at launch. On the GPU, only the threads which pass over the matching elements perform the computation: a simple in place addition and multiplication to the element. Only three elements of the matrix are ever accessed by the GPU
Subset GPU All CPU RAND
Similar to the previous microbenchmark, with the exception that the elements accessed by the GPU are a random subset of the input matrix. This is achieved by performing the computation out of place, with an input and output matrix. An element of the output matrix is assigned if the input matrix value is below a threshold. The threshold is used to control the percentage of elements in the output that are touched, since A is given random values within a range
All GPU Subset CPU
This microbenchmark uses the same GPU kernel as the All GPU All CPU case. The CPU computation is changed so that only a subset of the output matrix is accessed at random on the CPU
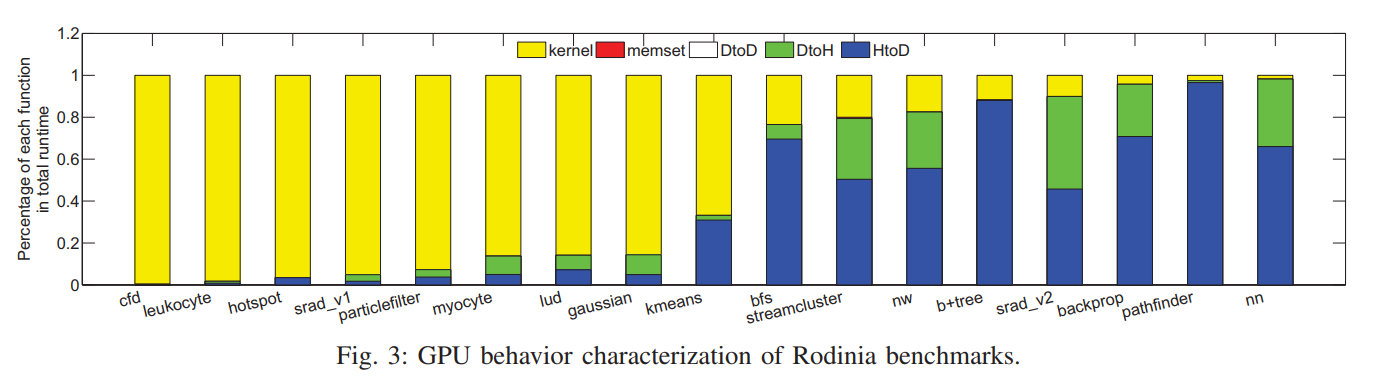
Rodinia Benchmarks

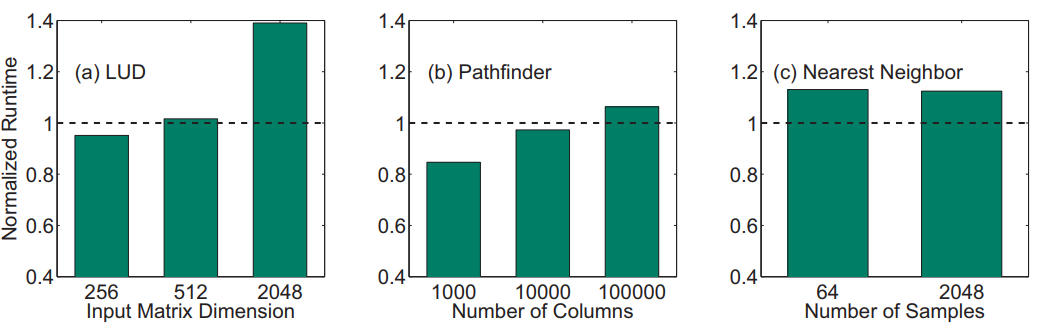
Result
Conclusion
in both our microbenchmarks and the Rodinia benchmarks, the difference in code complexity between the UMA and nonUMA version is little, with no more than 10 lines of code changing across versions
In order to improve UMA performance, we find that the application must use kernels which operate on subsets of the output data at a time. In this way, the paging mechanism provided by UMA provides the most benefit.
UMA can become a more performance oriented tool if it is extended to support more features and controls. Dynamically specifying the paging size between CPU and GPU memory would be critical, as the data transfer can then be tuned to match memory access behavior for a given application. Once the input hits the page size, performance decreases notably
If CUDA were more transparent in the data transfer mechanism using UMA, the program design could be better optimized to match data transfer patterns.
UMA has limited utility due to its high overhead and marginal improvement in code complexity. Further work on UMA should include greater transparency in the paging mechanism, greater control of the internal mechanism, as well as further analytical tools for optimizing UMA behaviors.