
El meme como la máxima cantidad de información en el mínimo espacio
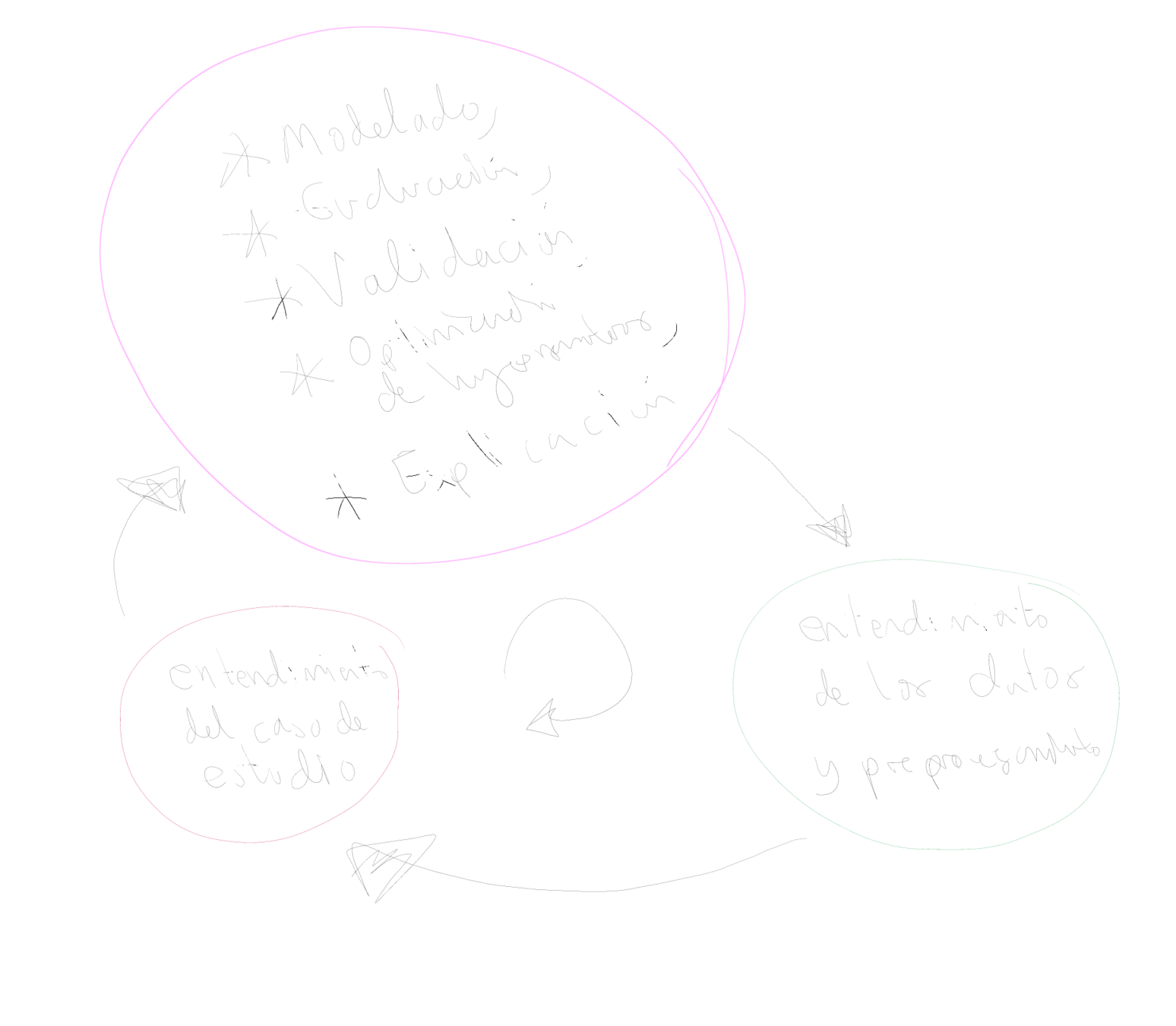
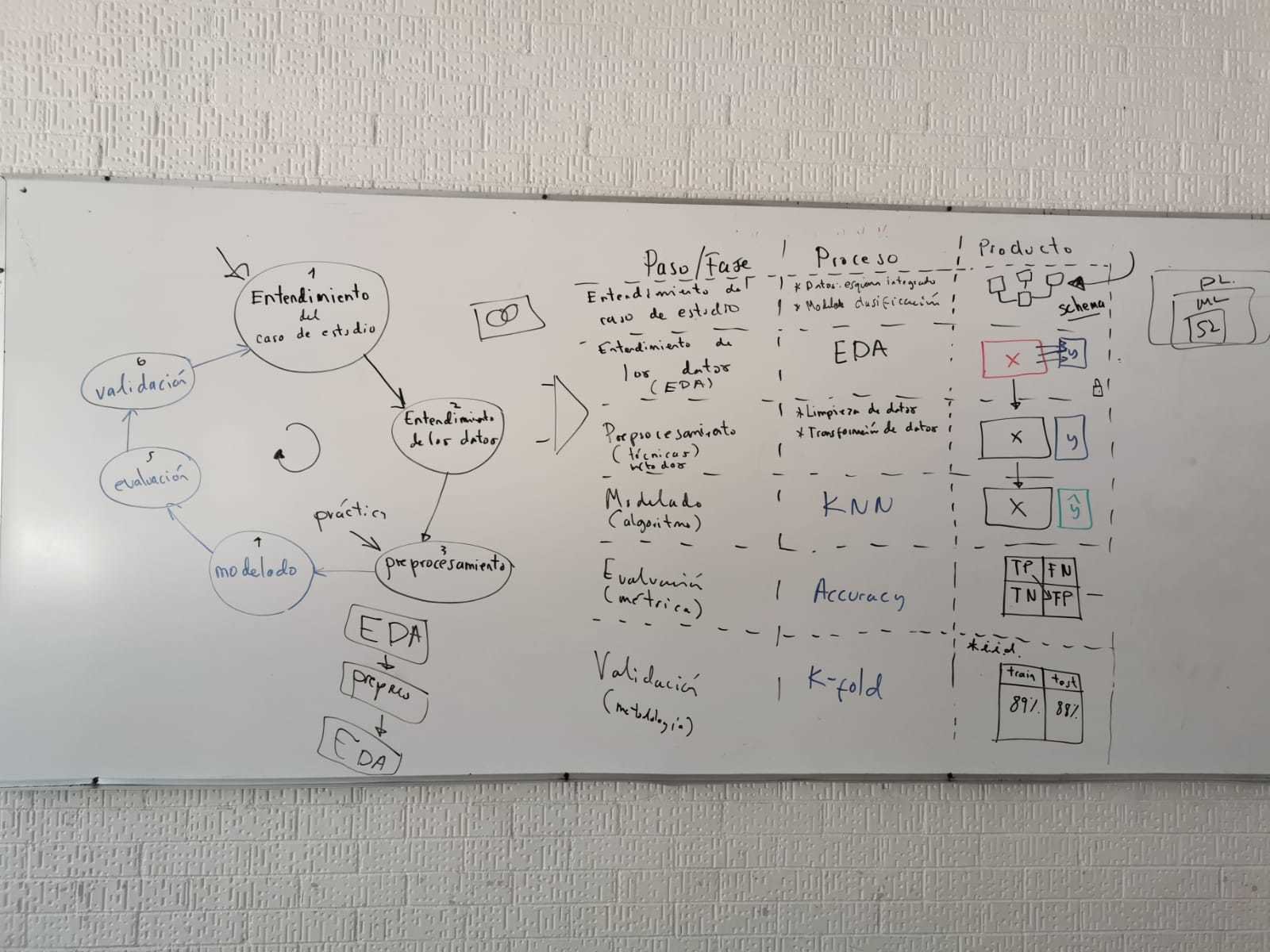
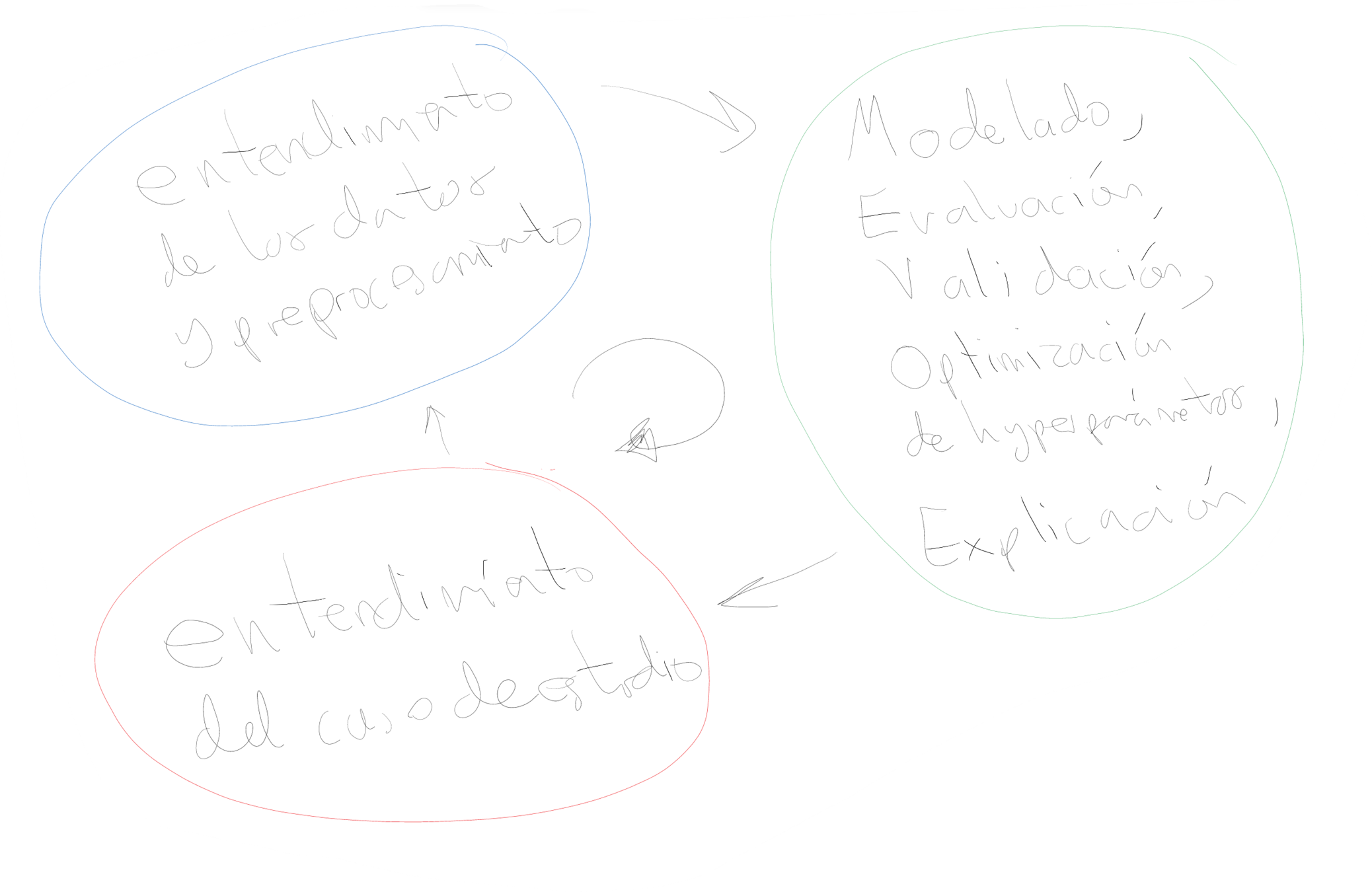
Entendimiento del caso de estudio
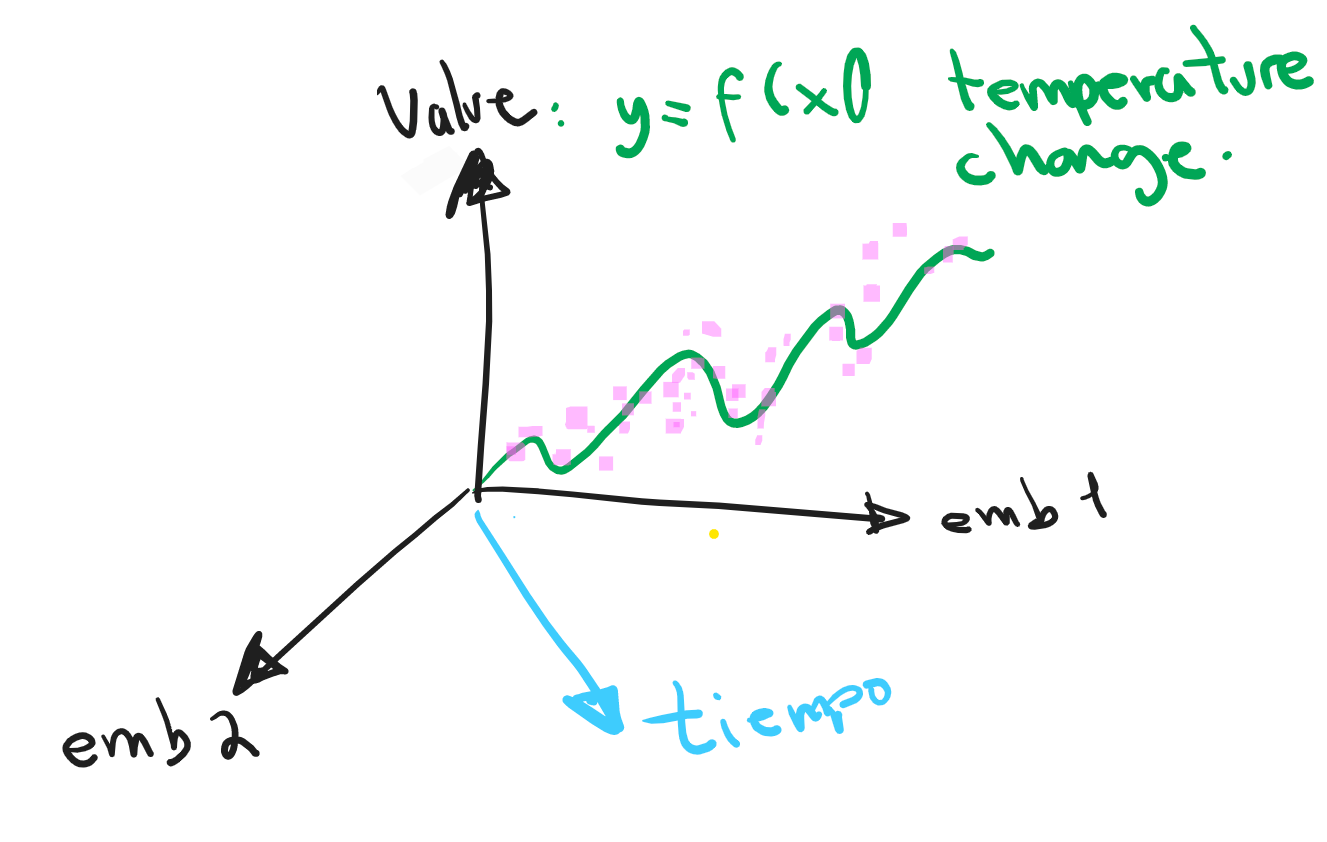
Propuesta: análisis de datos multivariados (data-driven approach) con aprendizaje automático (machine learning)
Propuesta: análisis de datos multivariados (data-driven approach) con aprendizaje automático (machine learning)
Hipótesis
Model
Data
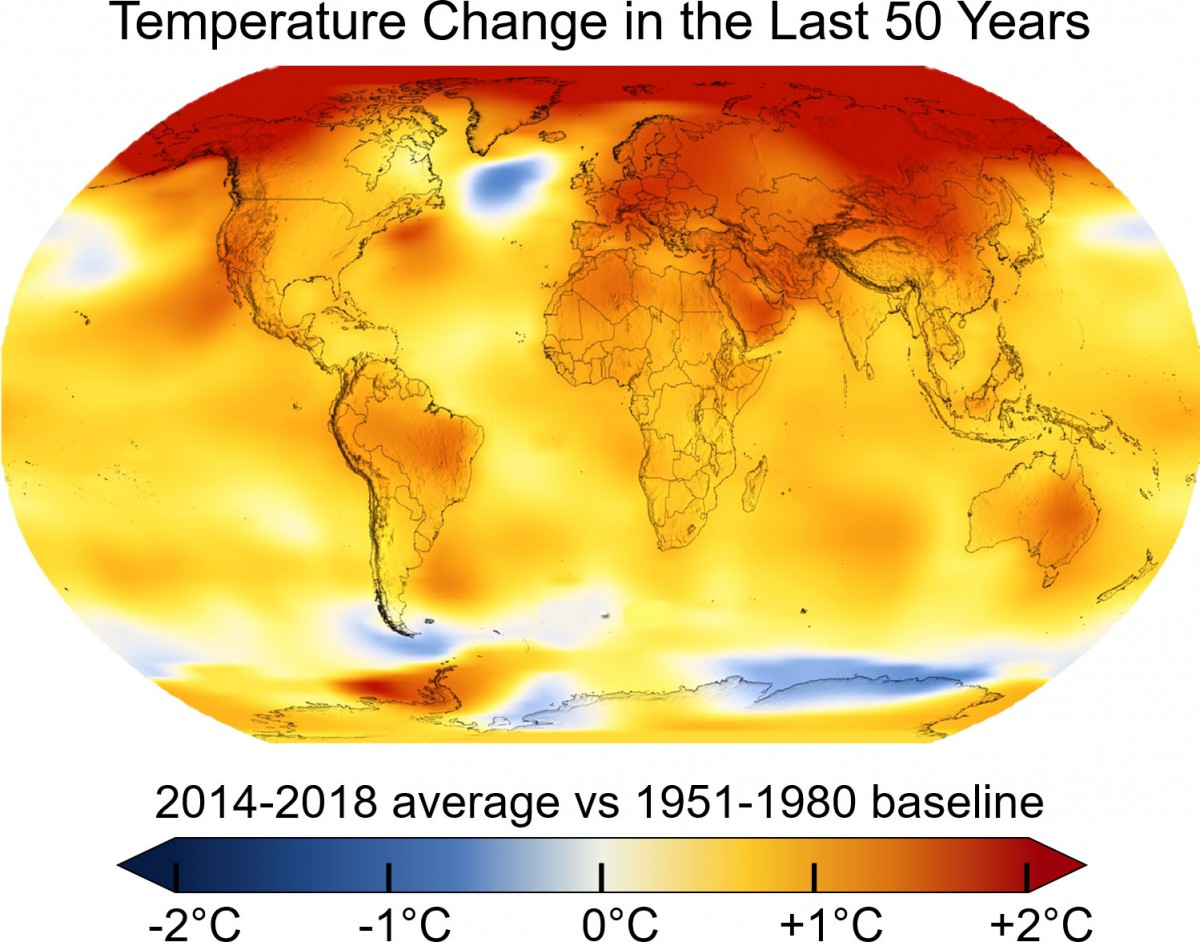
Hipótesis: existen relaciones entre el cambio de temperatura e indicadores agrícolas y alimenticios
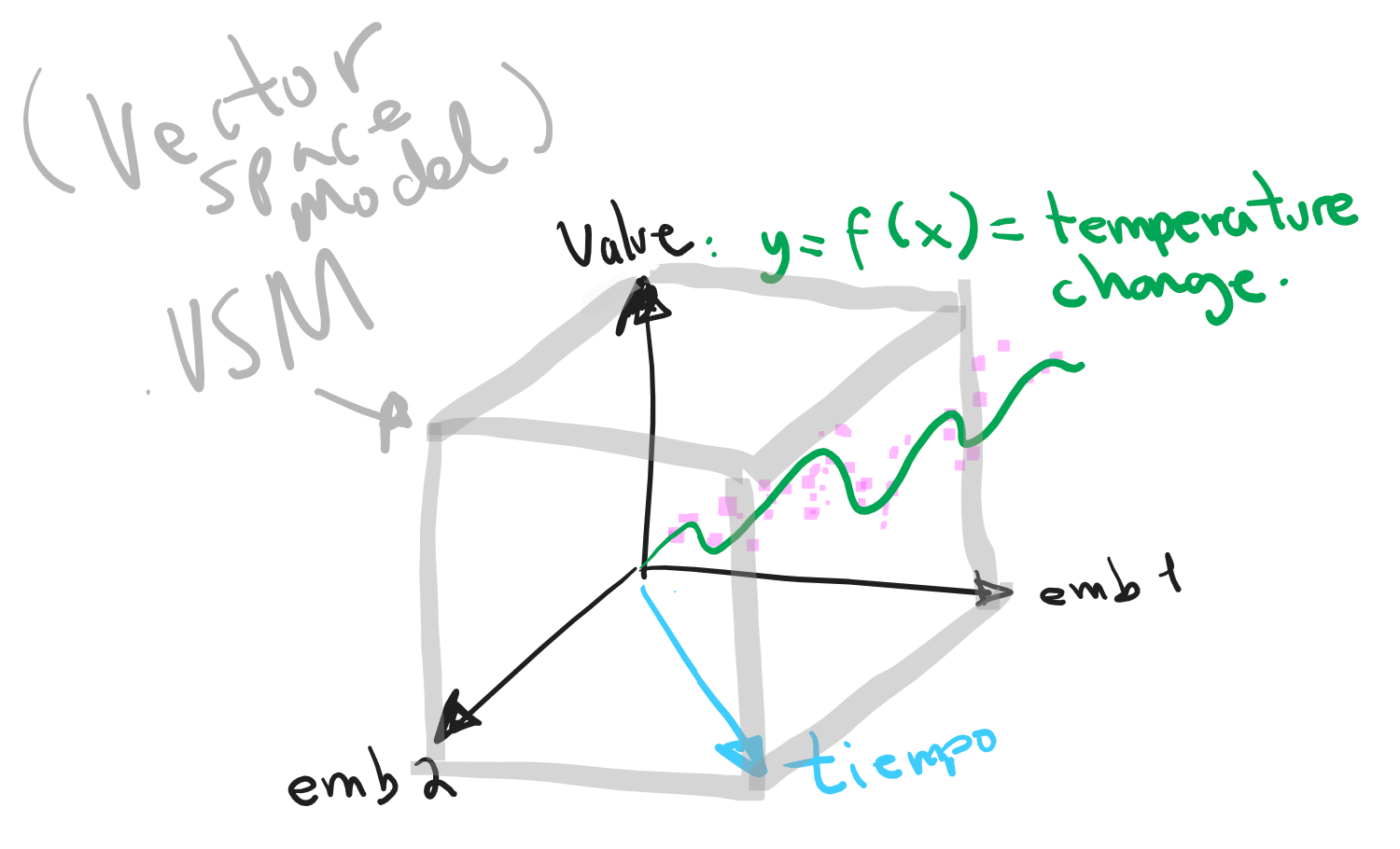
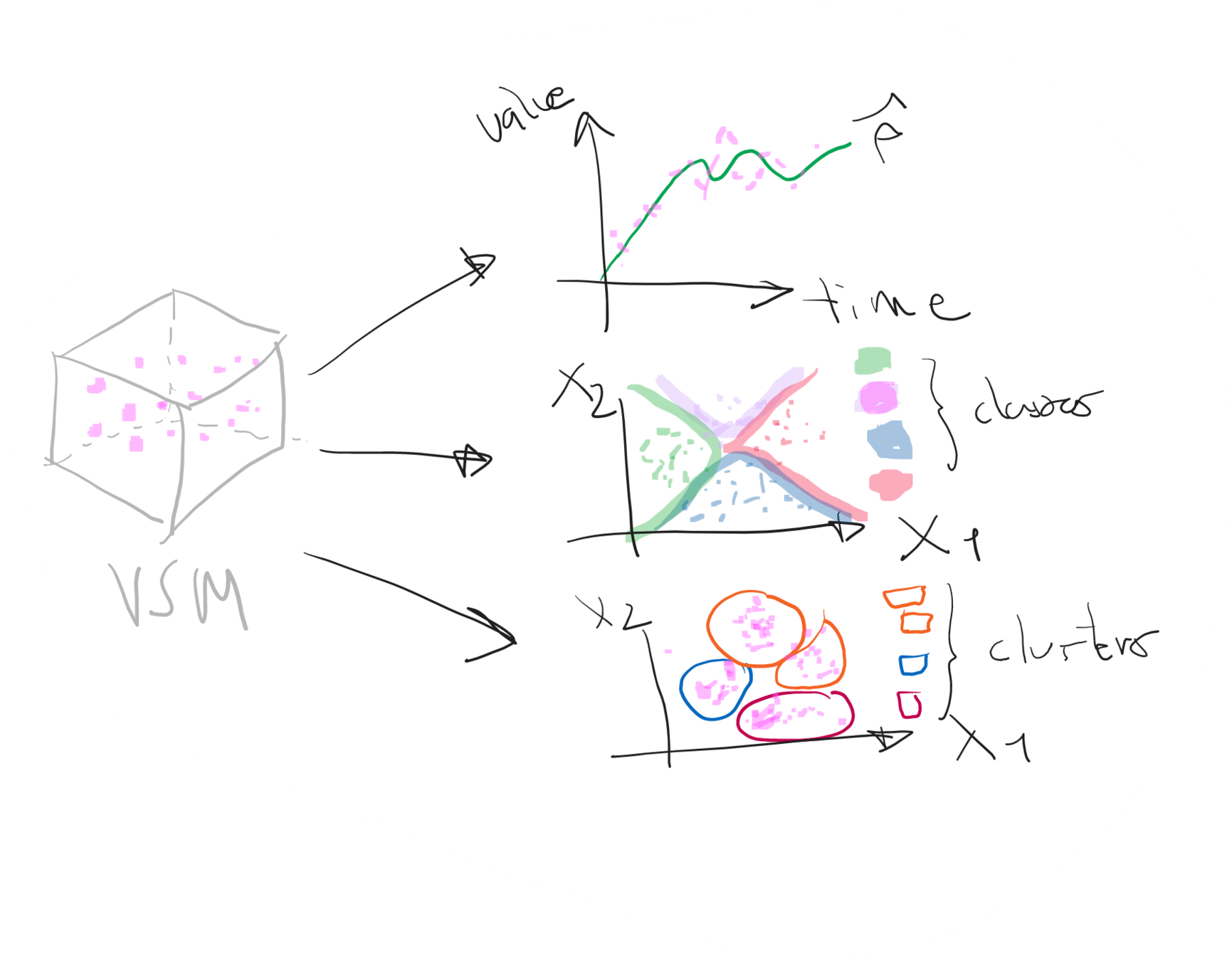
El Vector Space Model (VSM) como estructura/lattice de la representación del conocimiento (datos como objetos vectoriales)
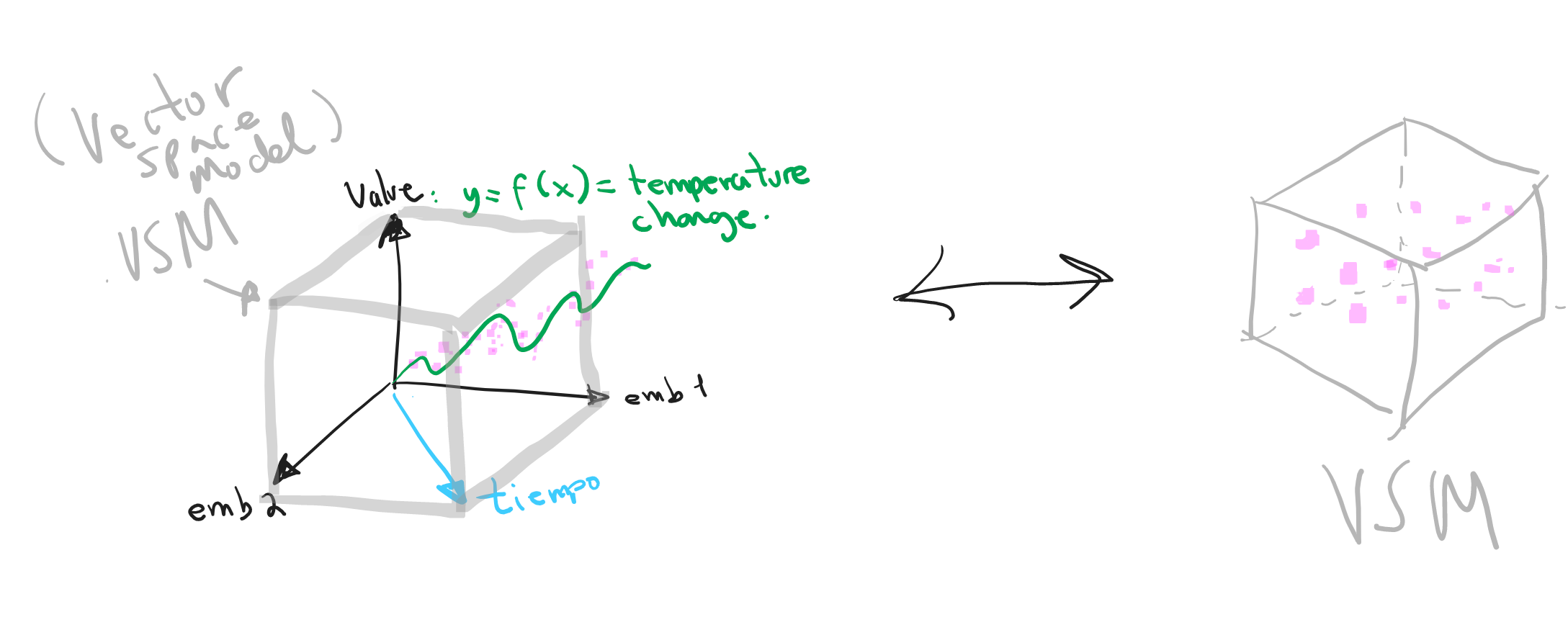
Objetivo principal: crear el VSM del caso de estudio
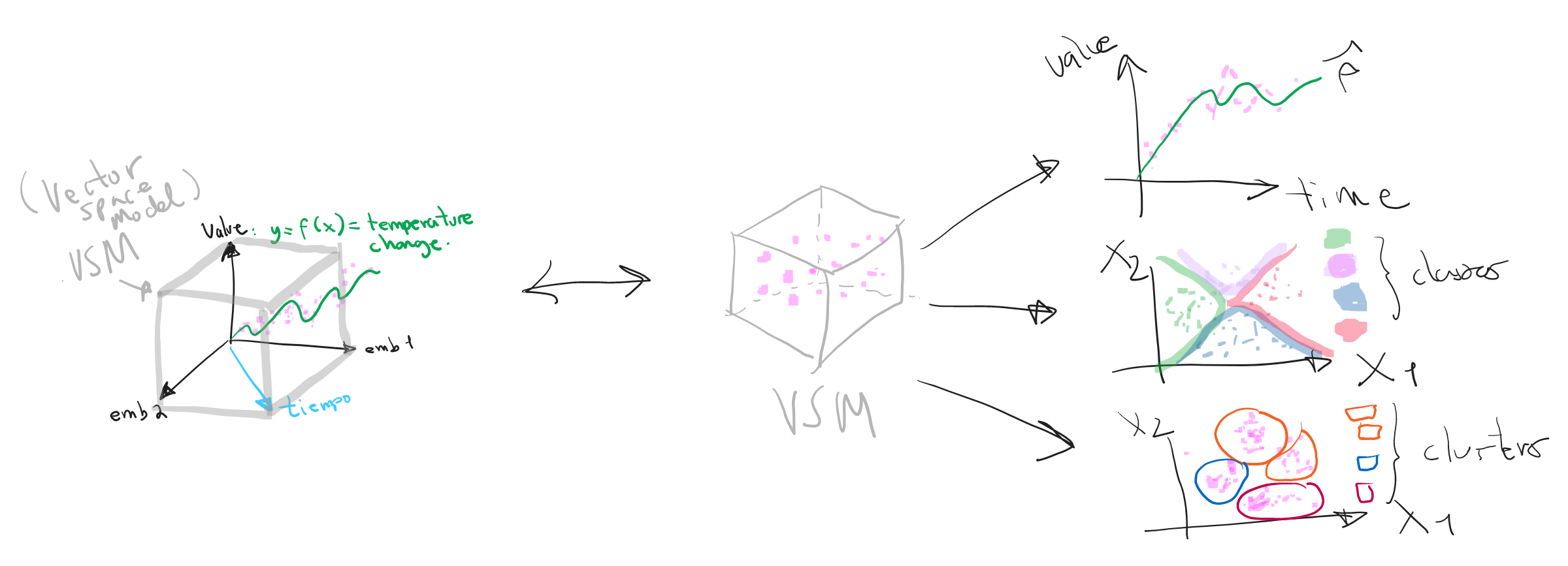
Data Model as a VSM
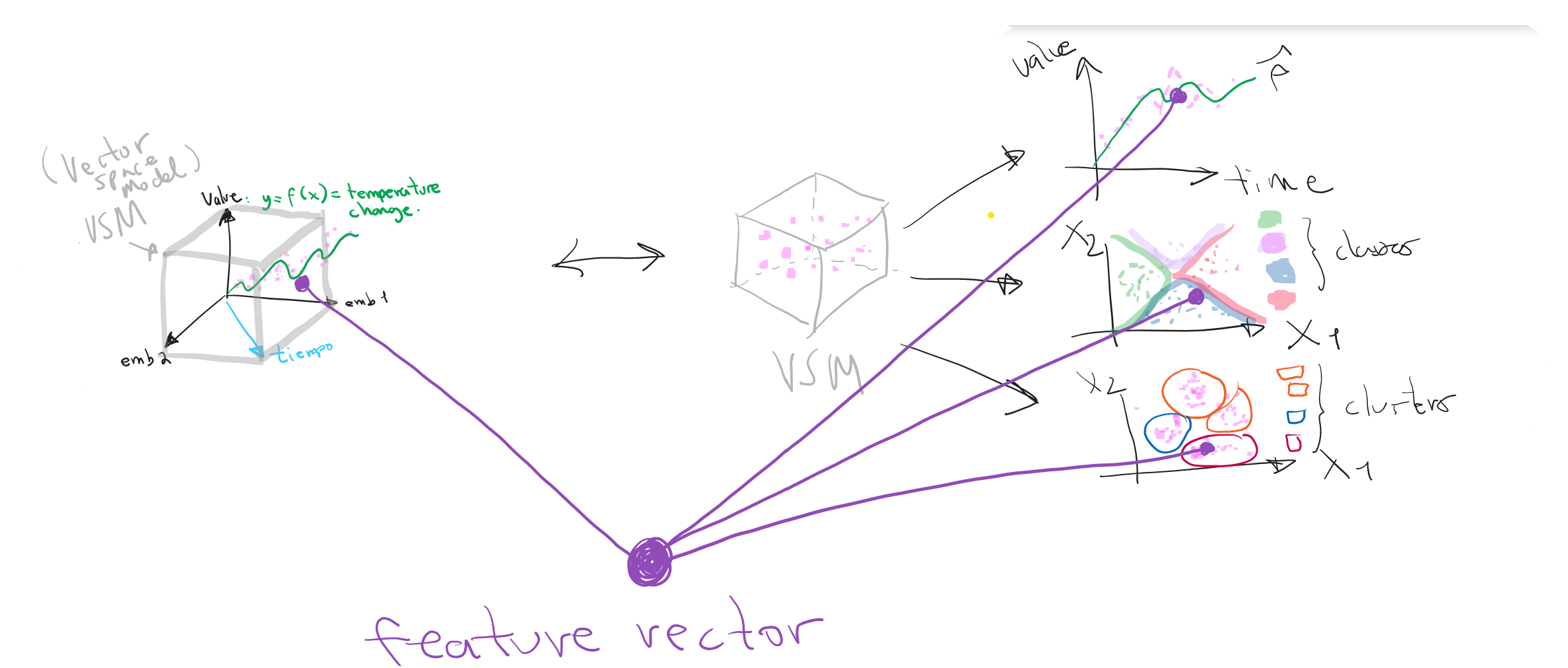
Dato <-> objeto vectorial <-> feature vector
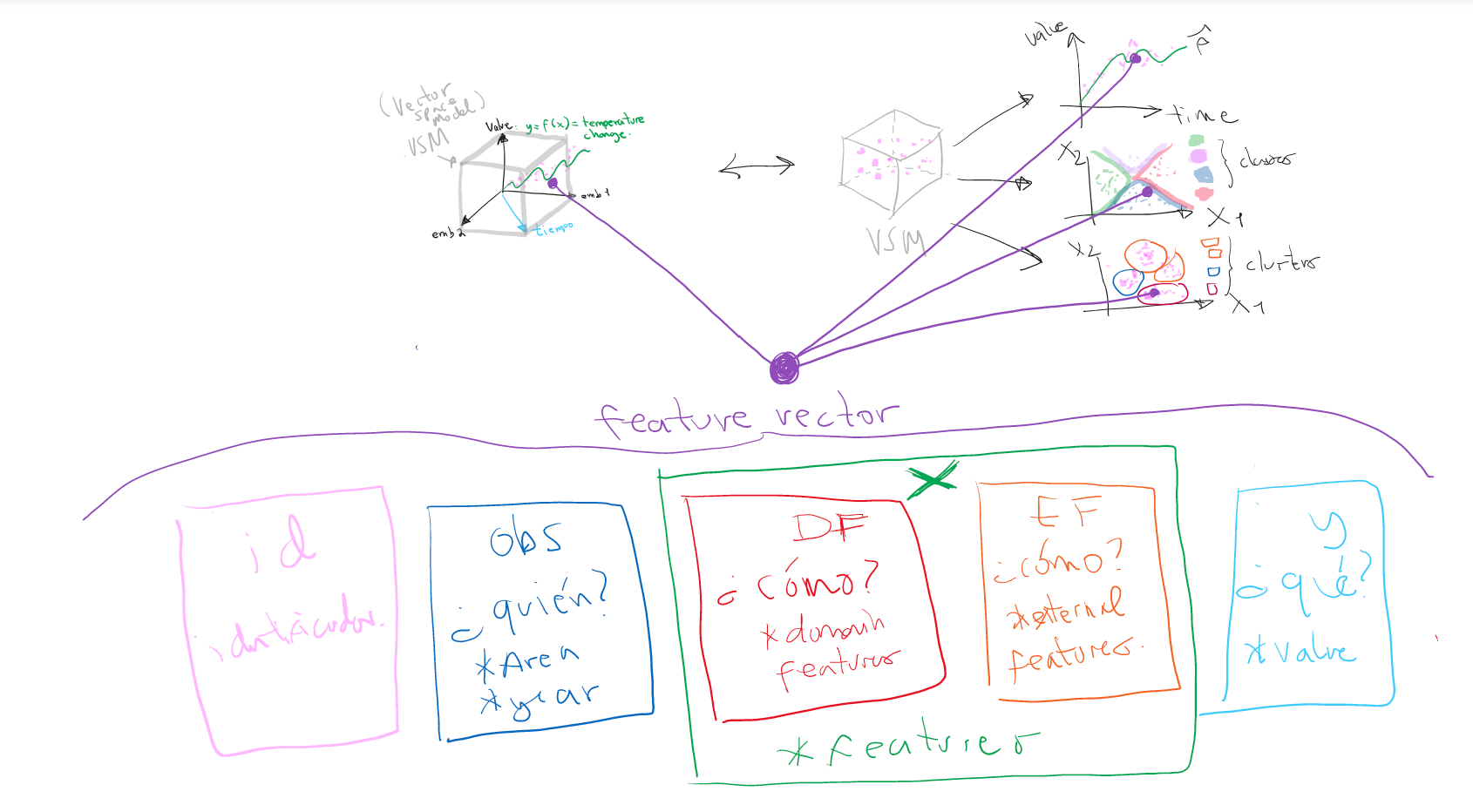
Estructura del feature vector
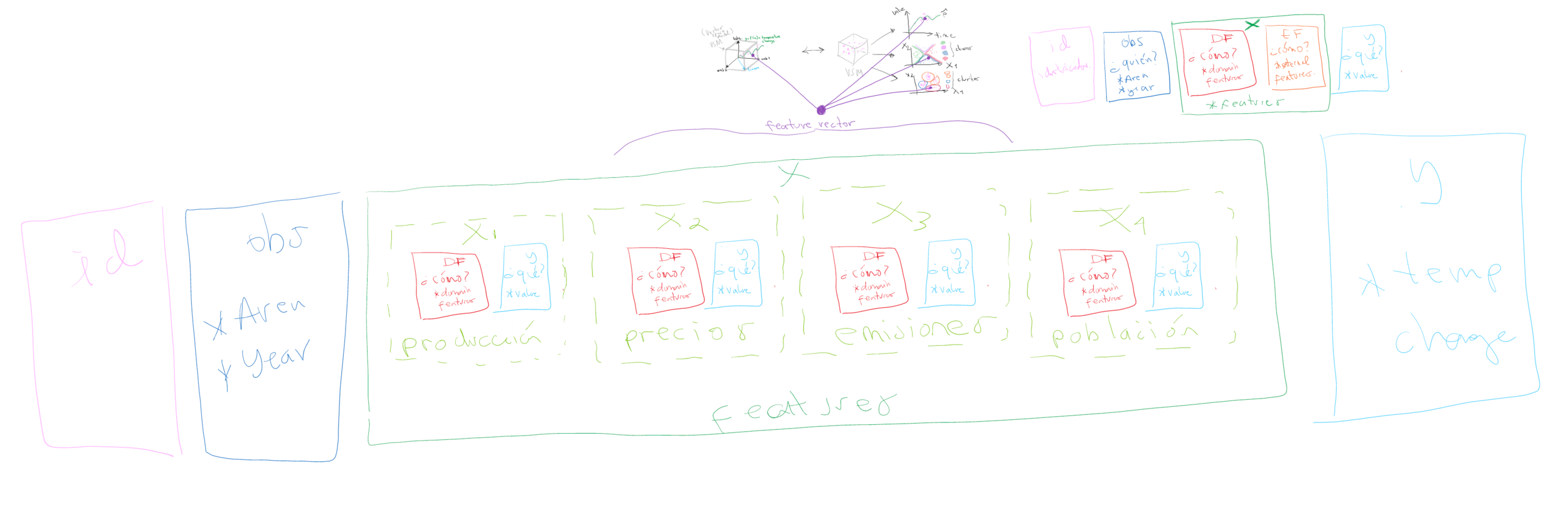
Estructura en alta dimensionalidad del feature vector
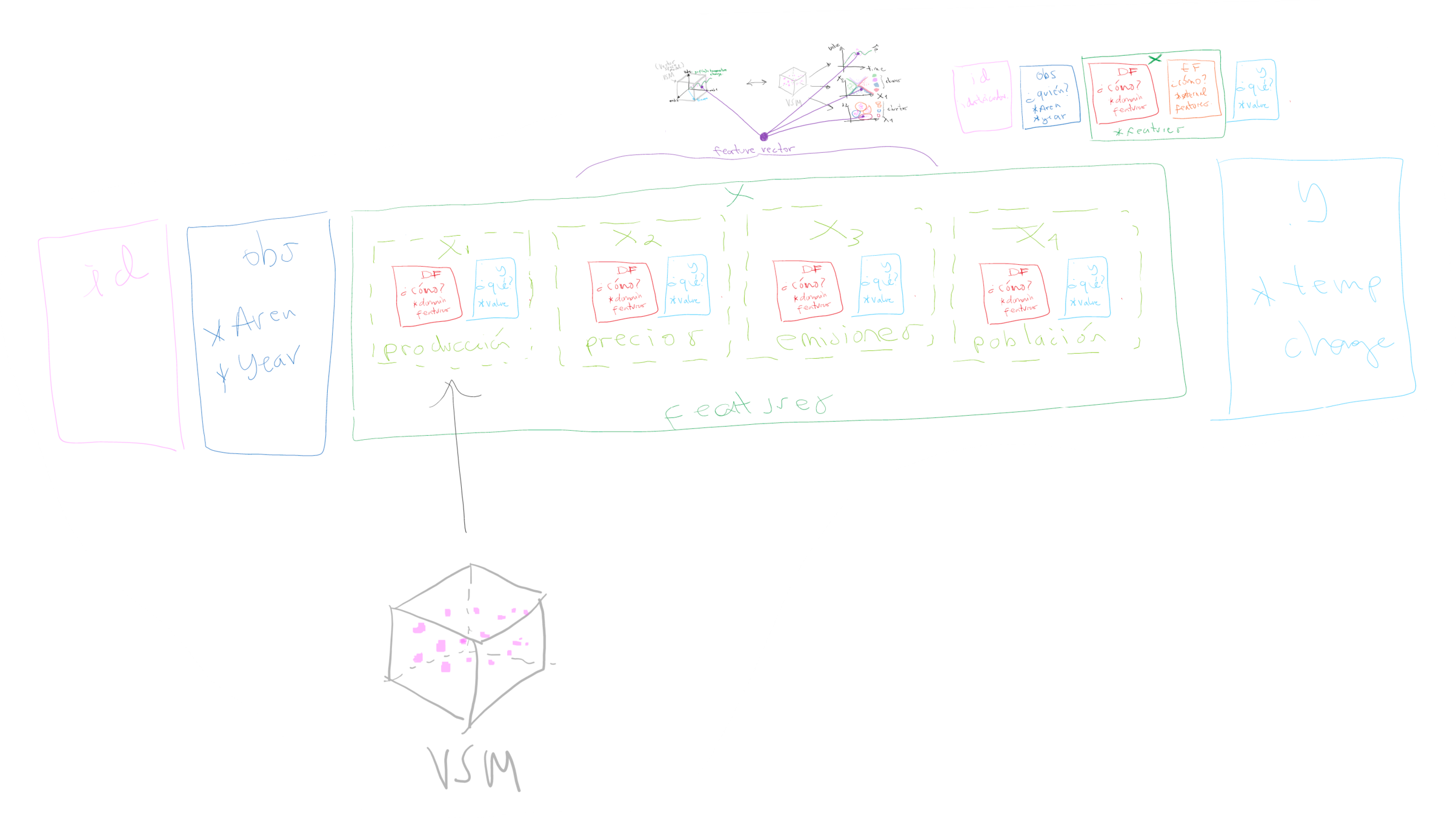
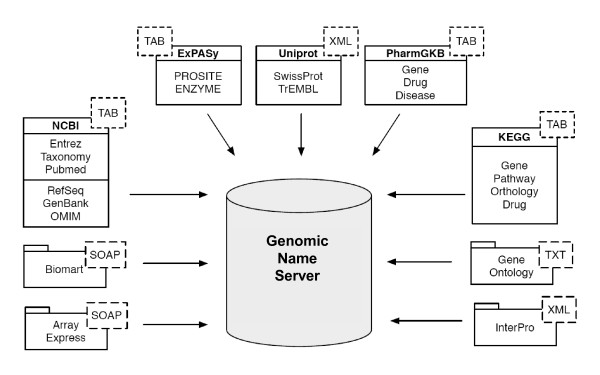
Contribución: DataReactor para la creación del VSM

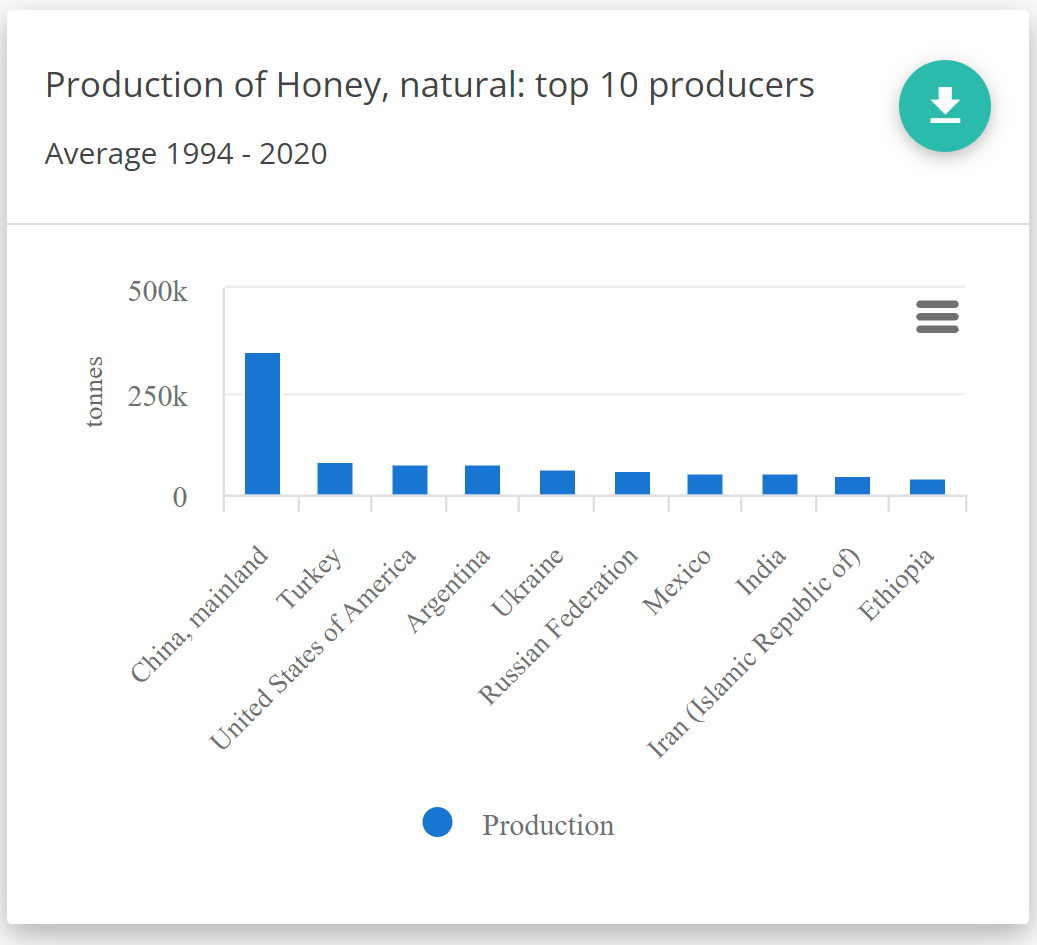
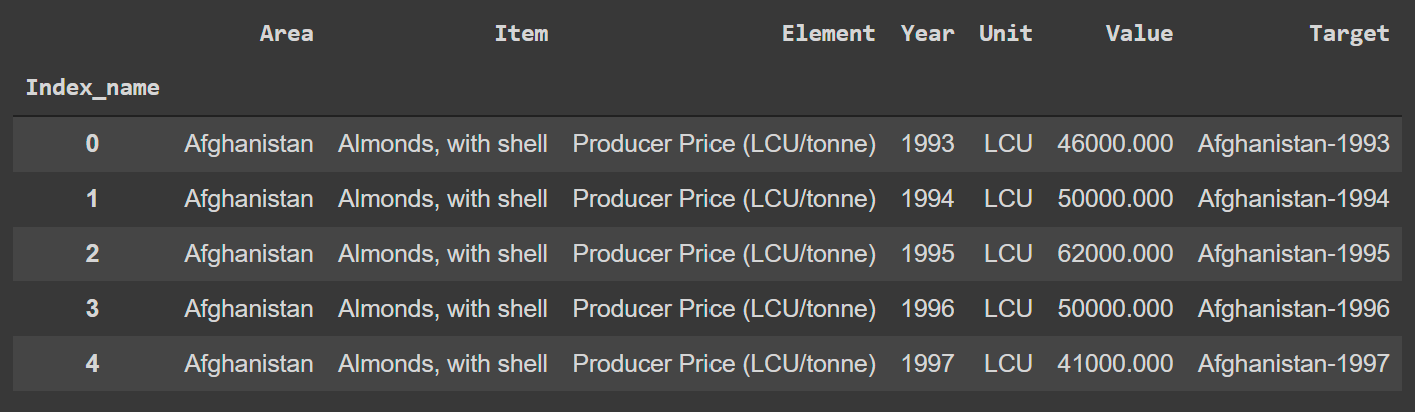
Ejemplo: VSM para el indicador "Producción"
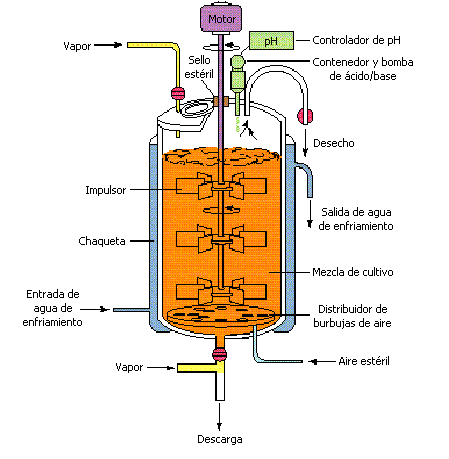
Inspiración: BioReactor

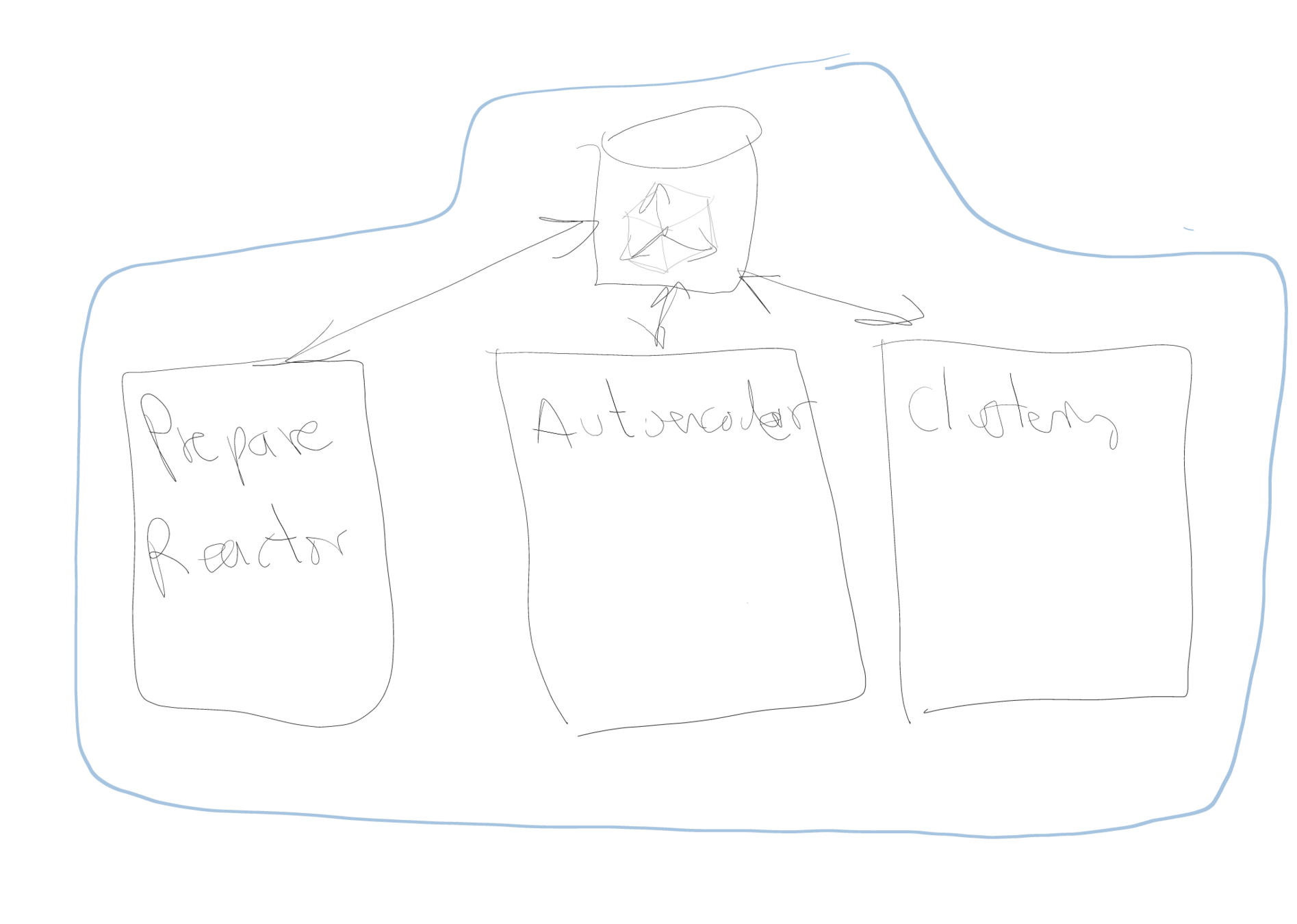
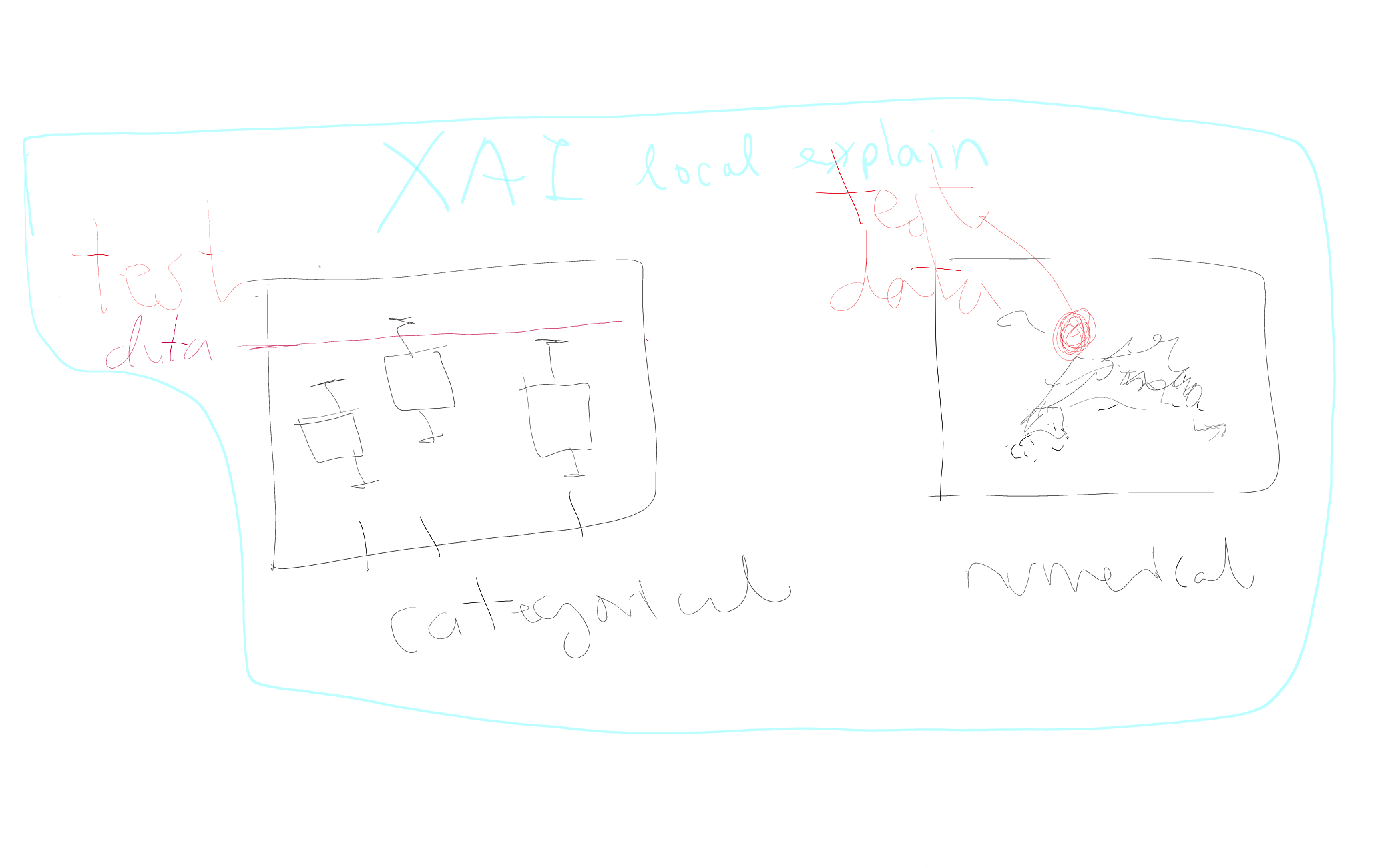
Centralized ML Pipeline
- Dynamic ML/DL Architecture
- Features Domain Adaptative
- MLOps Methodology
DataReactor para la creación del VSM
DataReactor Methodology:
Control de versión de iteración
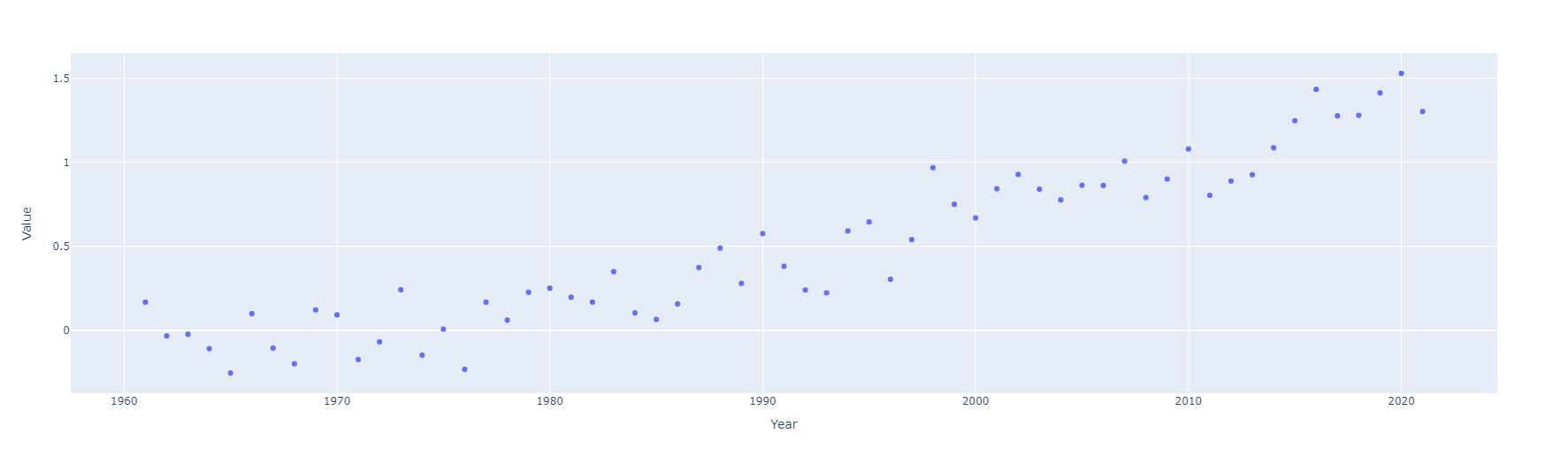

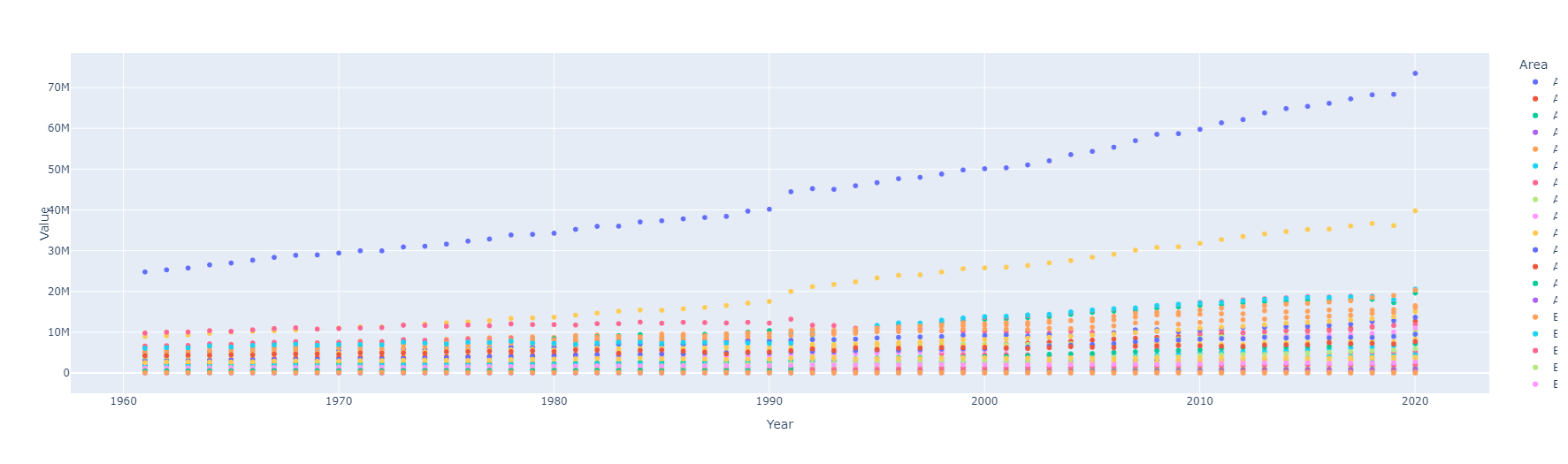
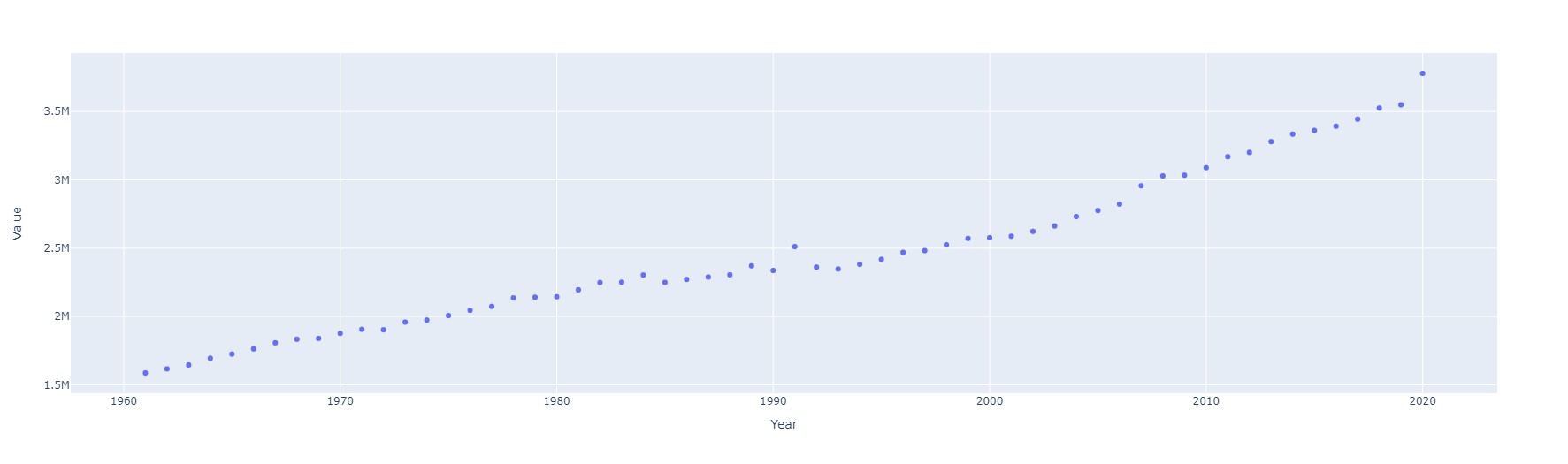

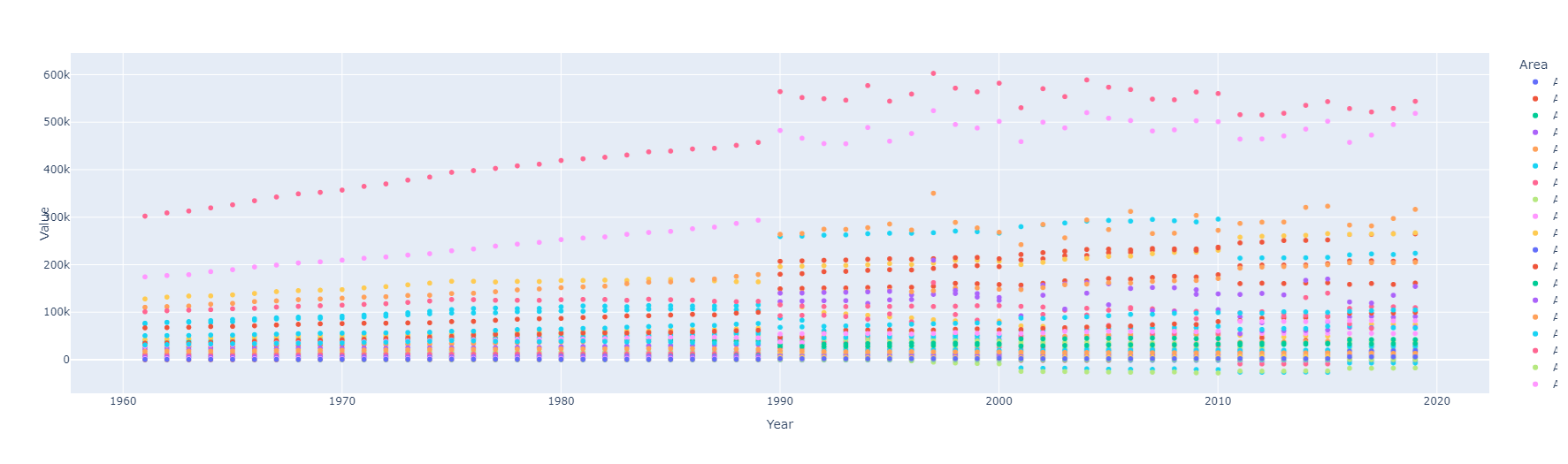
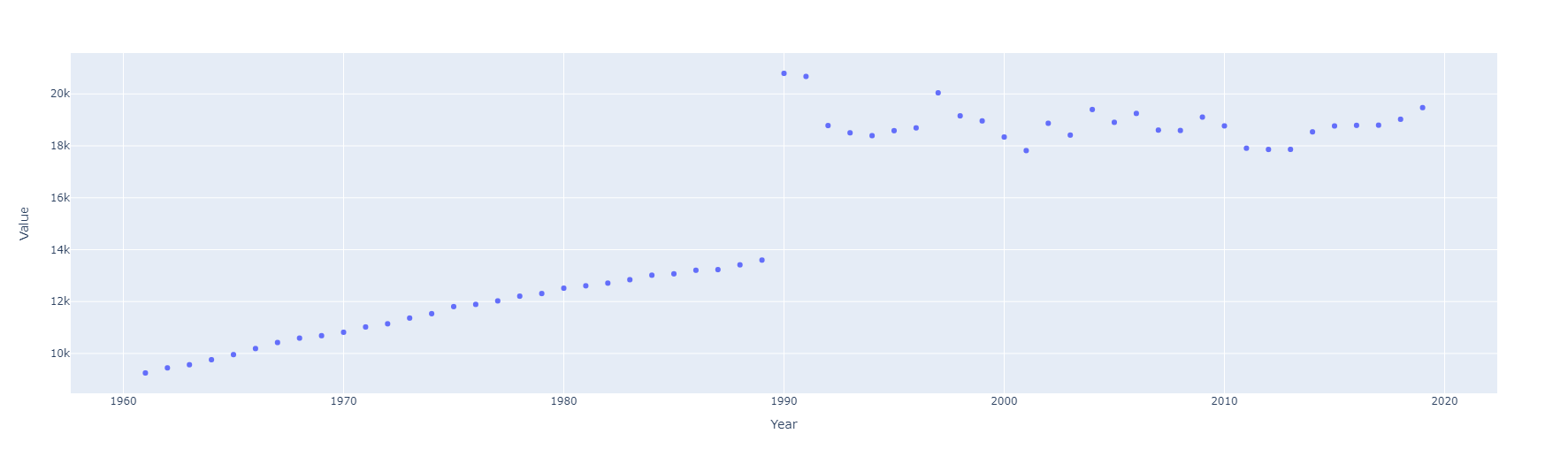

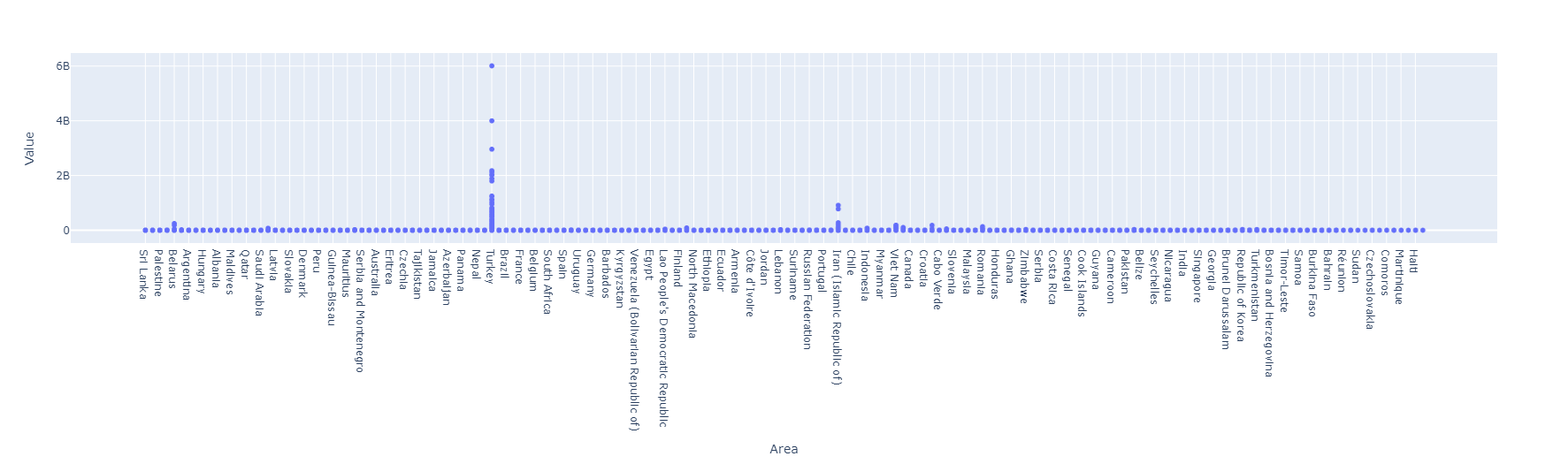
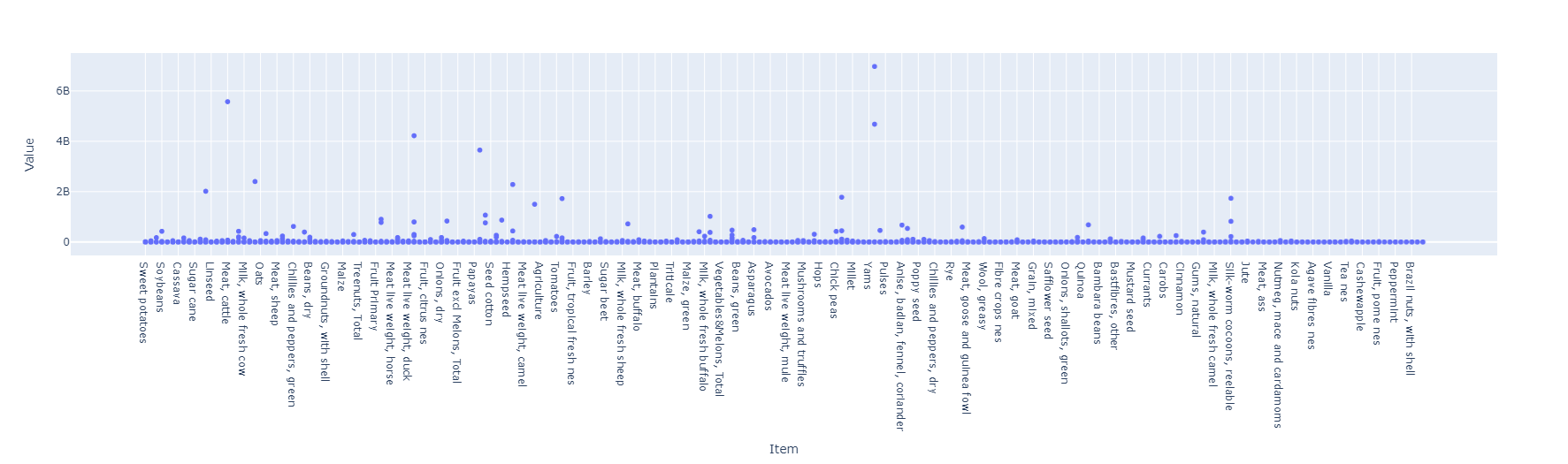
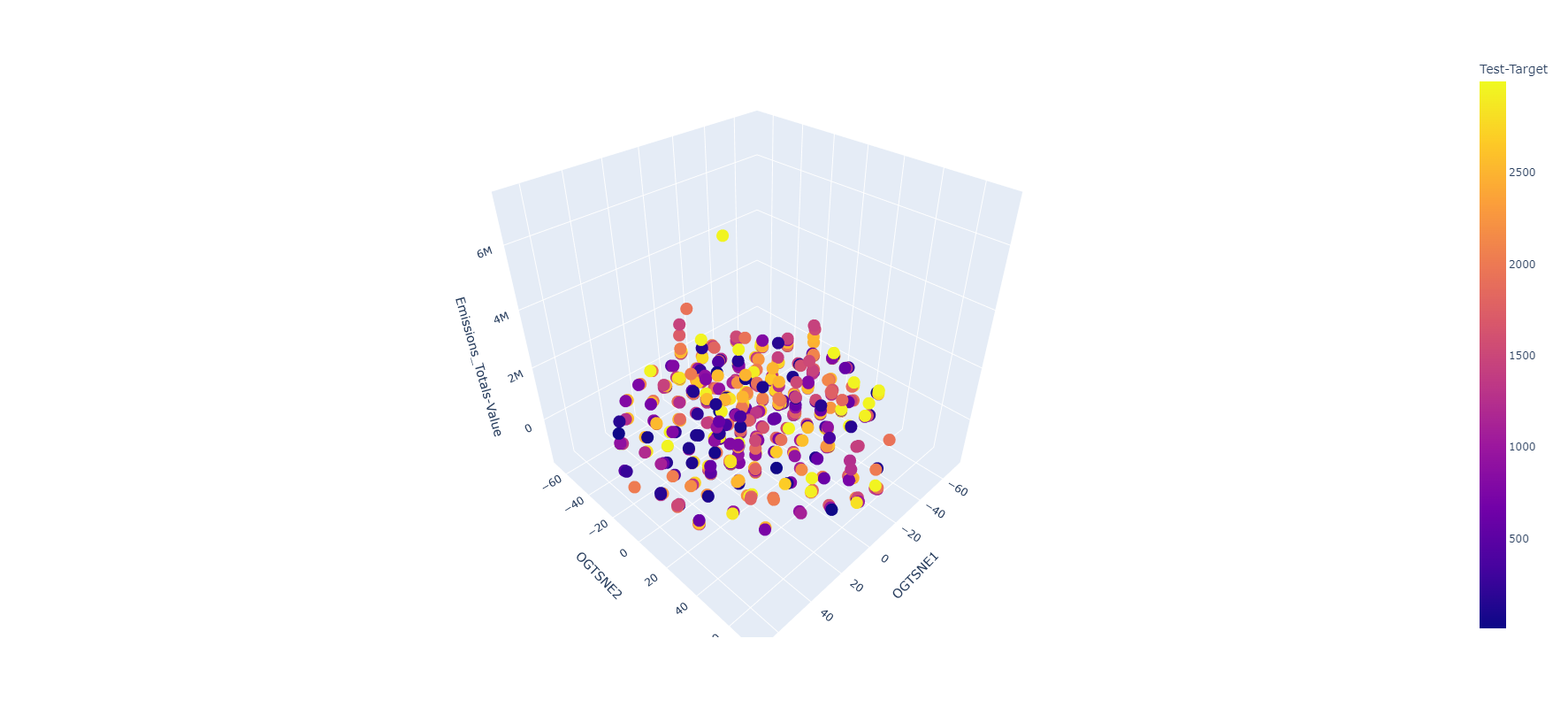
Indicador: Emisiones
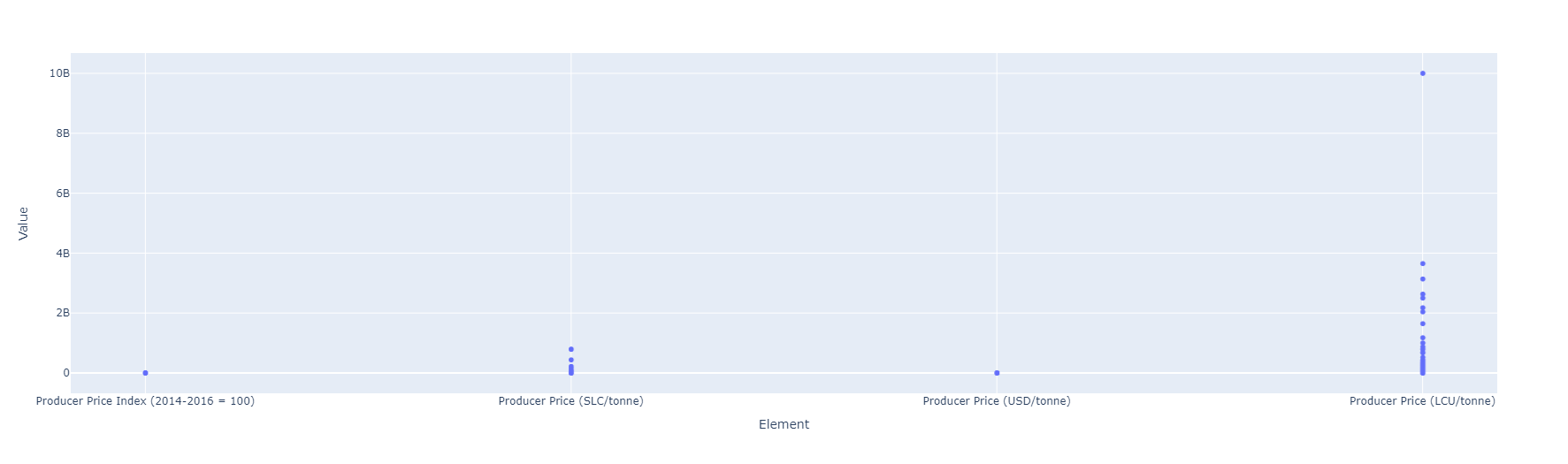
Indicador: Emisiones

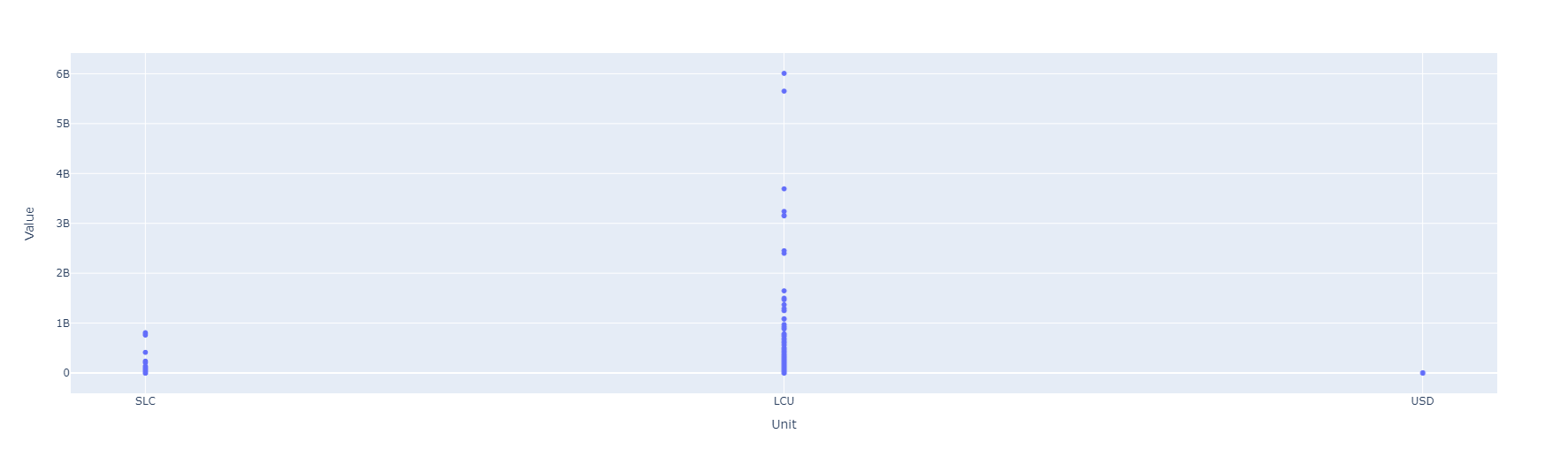
Indicador: Emisiones

Indicador: Emisiones
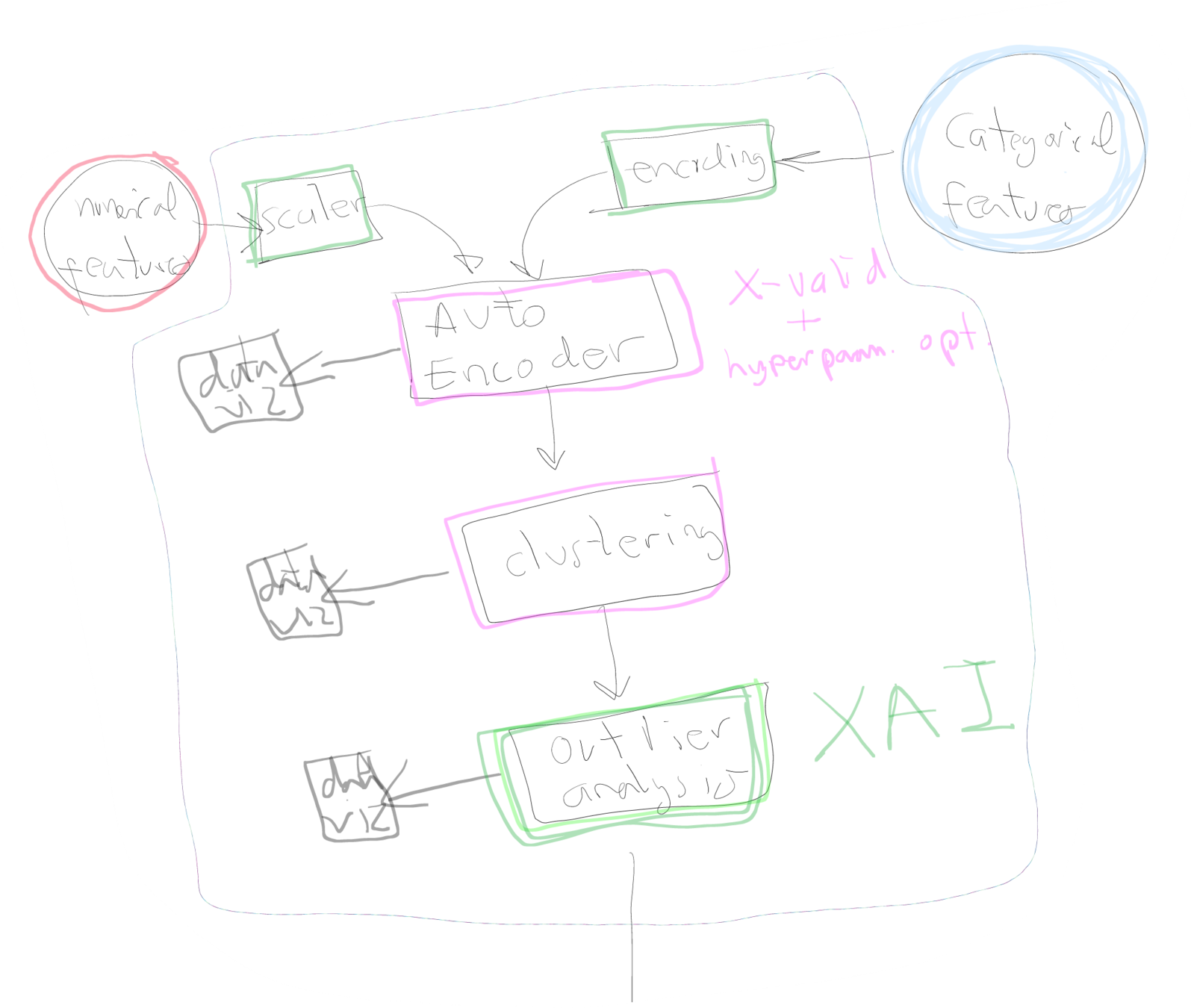
Target-Autoencoder

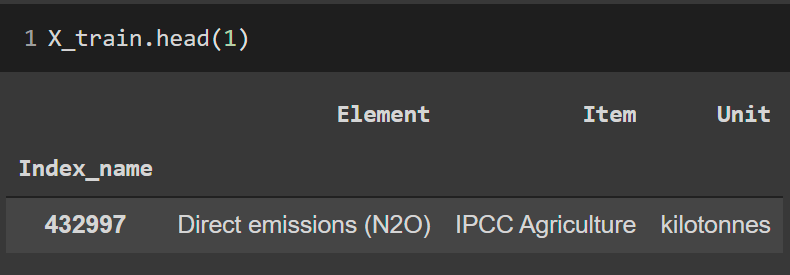
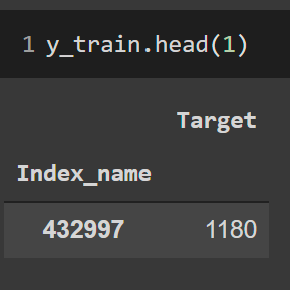
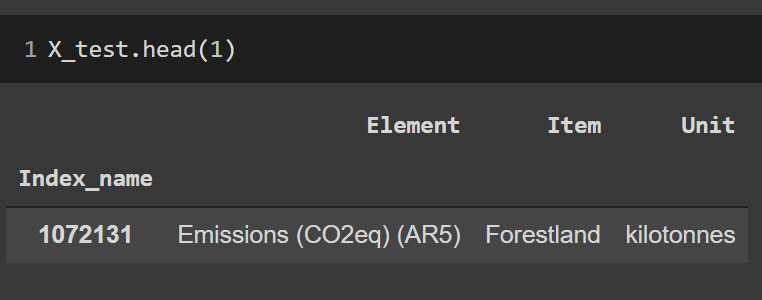
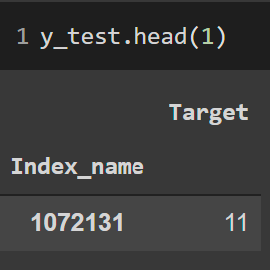

Indicador: Emisiones
X, y
(X_train,
y_train)
(X_test,
y_test)
(X_train_p,
y_train)
(X_test_p,
y_test)
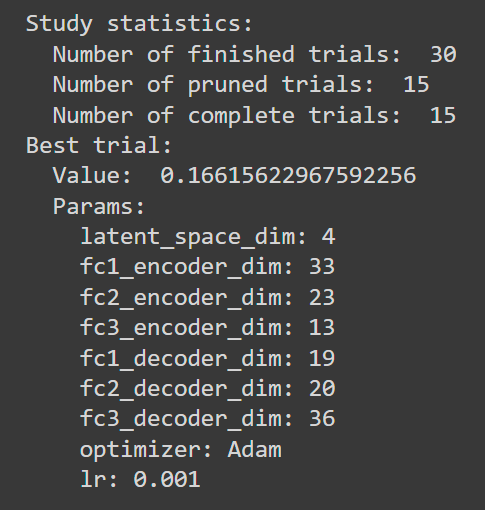
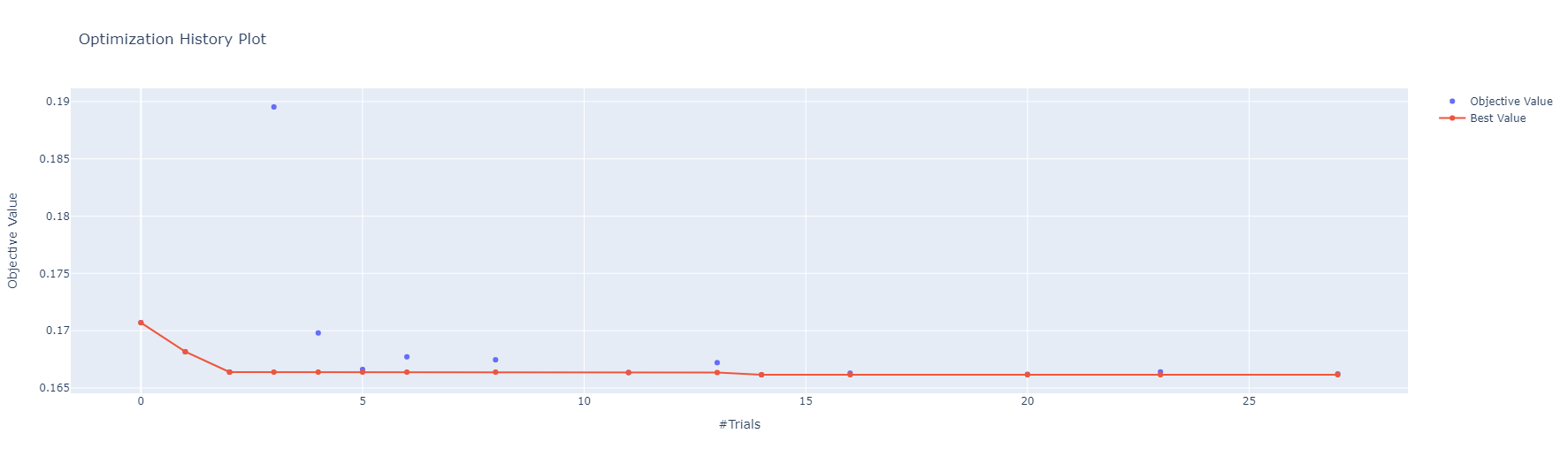
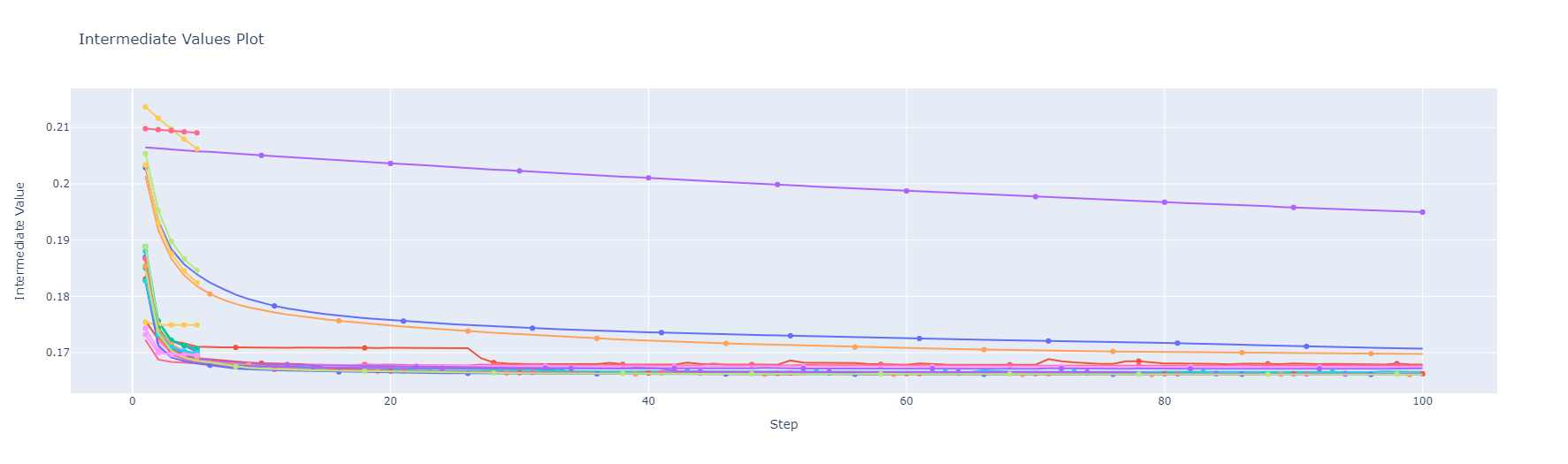
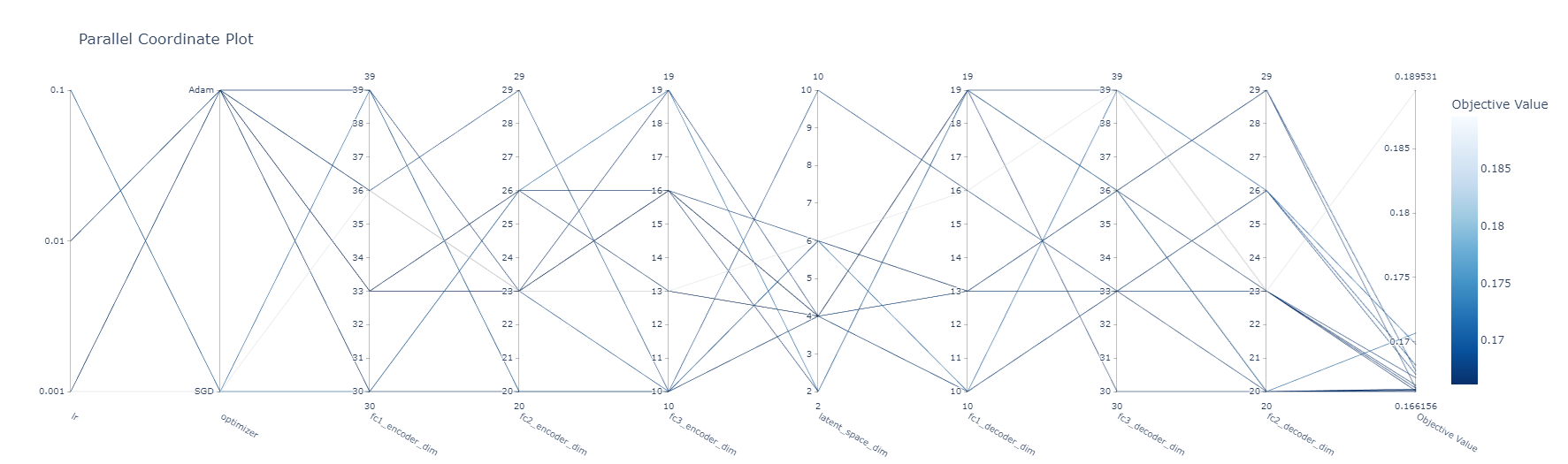
Autoencoder
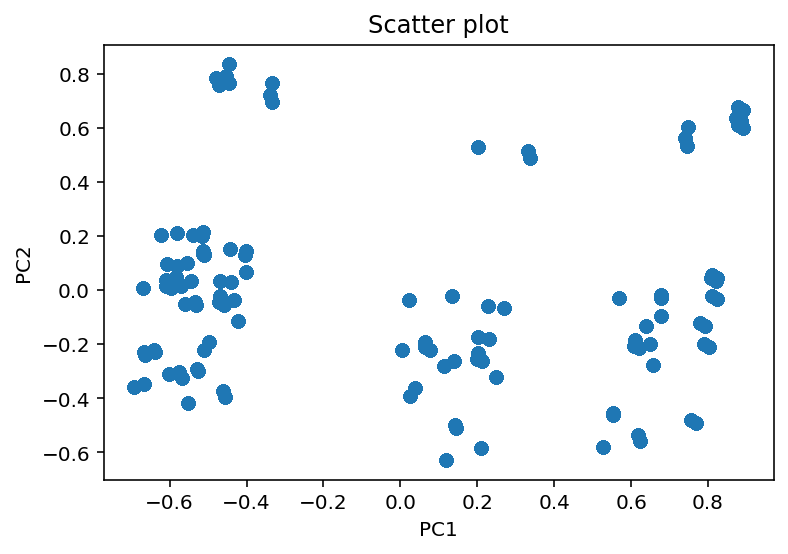

PCA
X_test_data_p (34 dim)
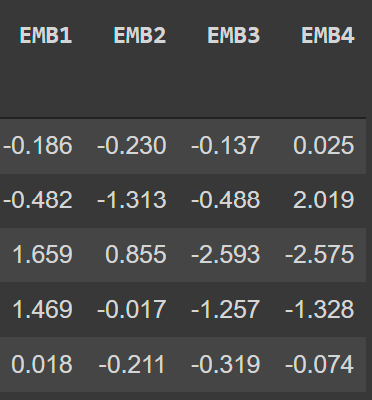
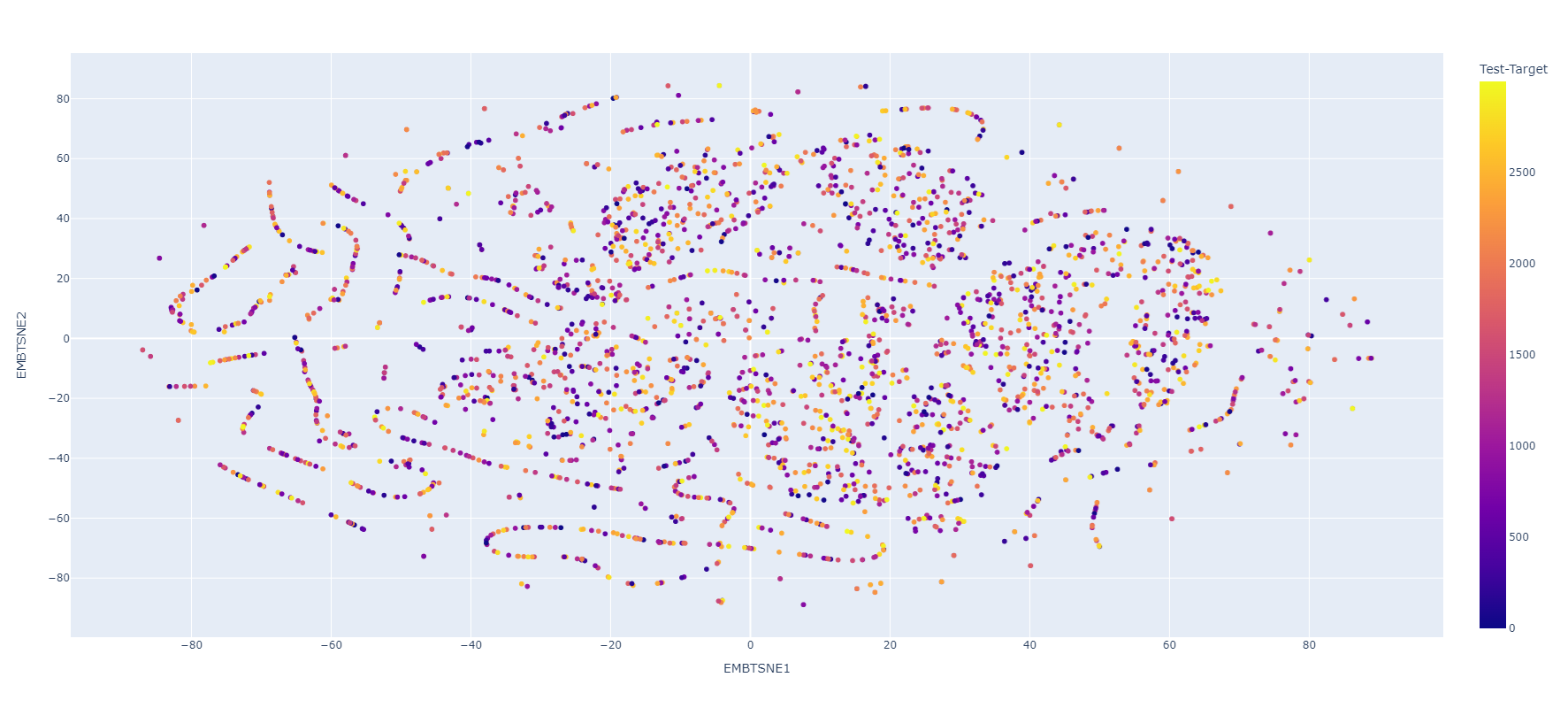
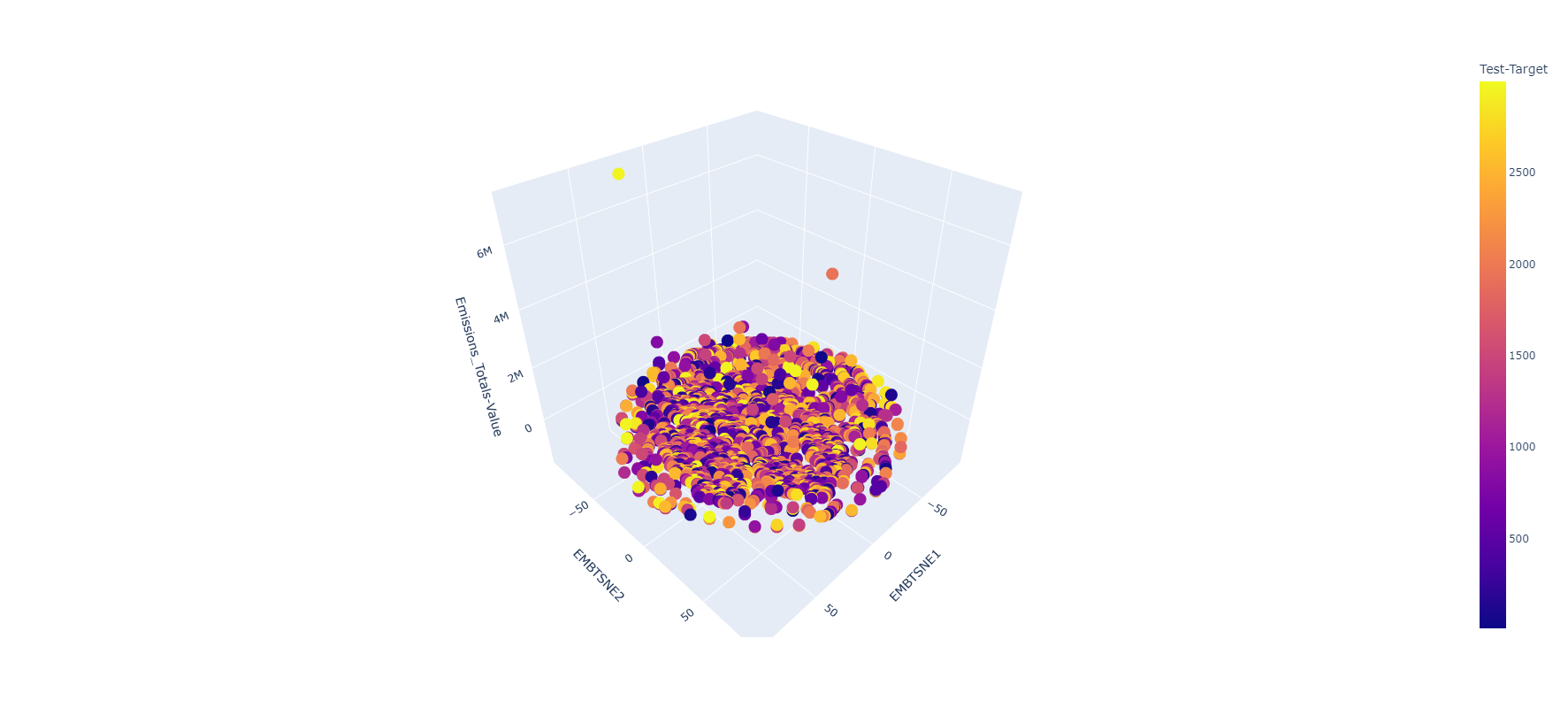
Embeddings (4 dim)
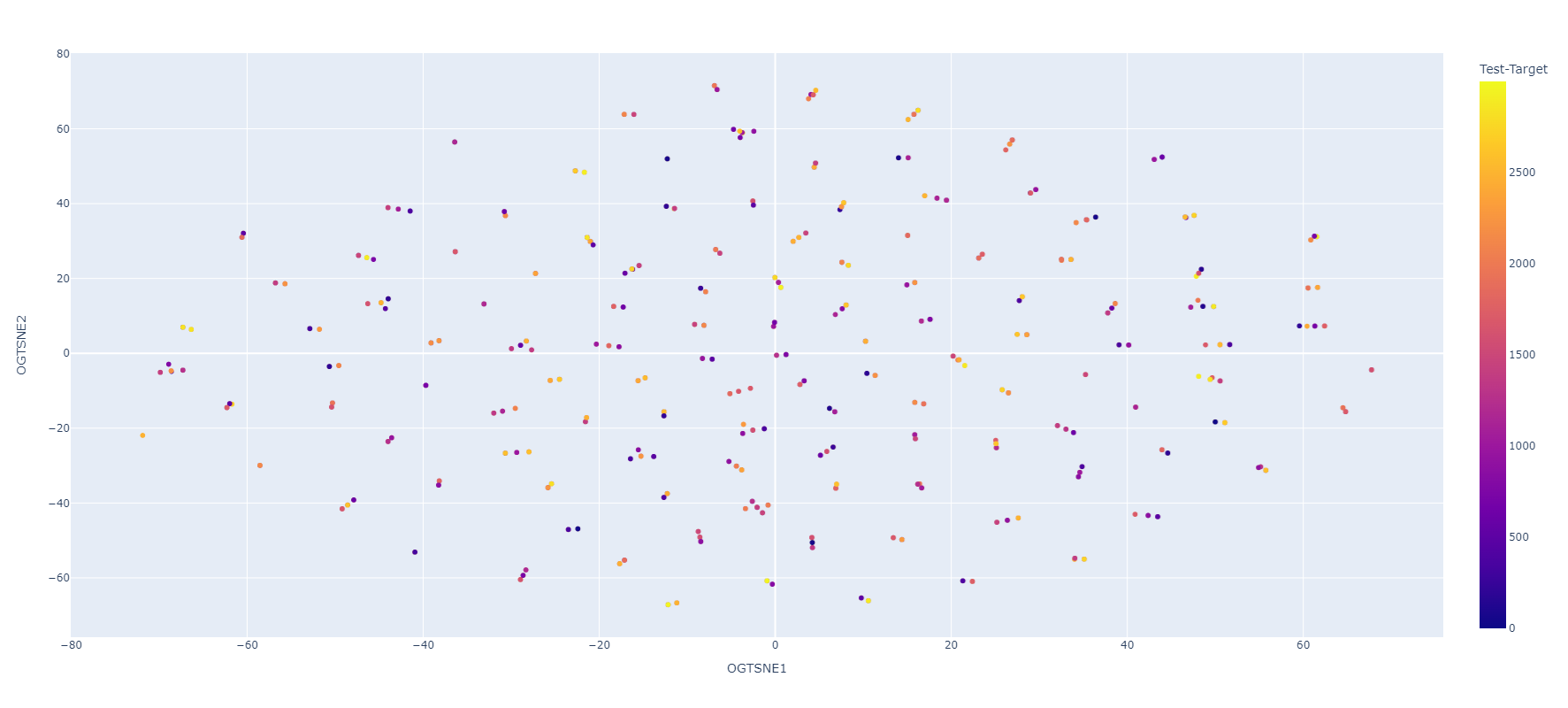
TSNE
X -> y
Clustering
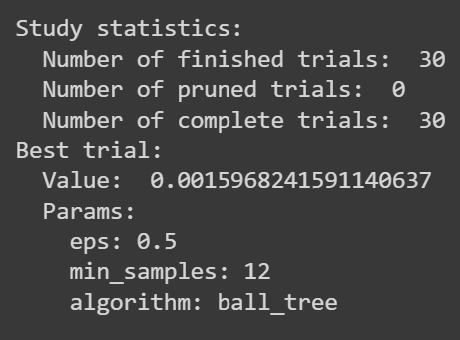
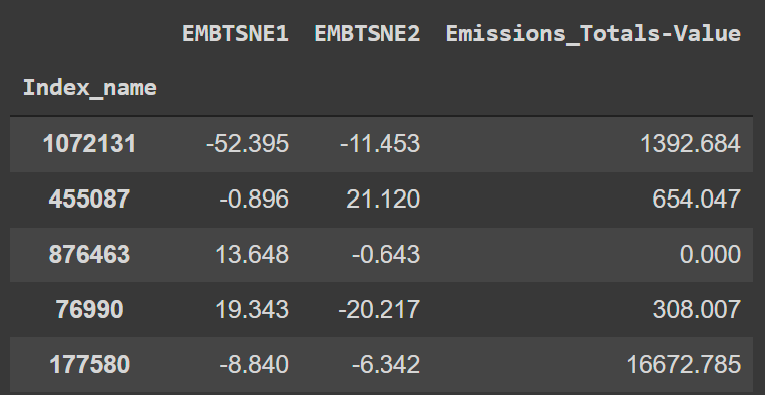
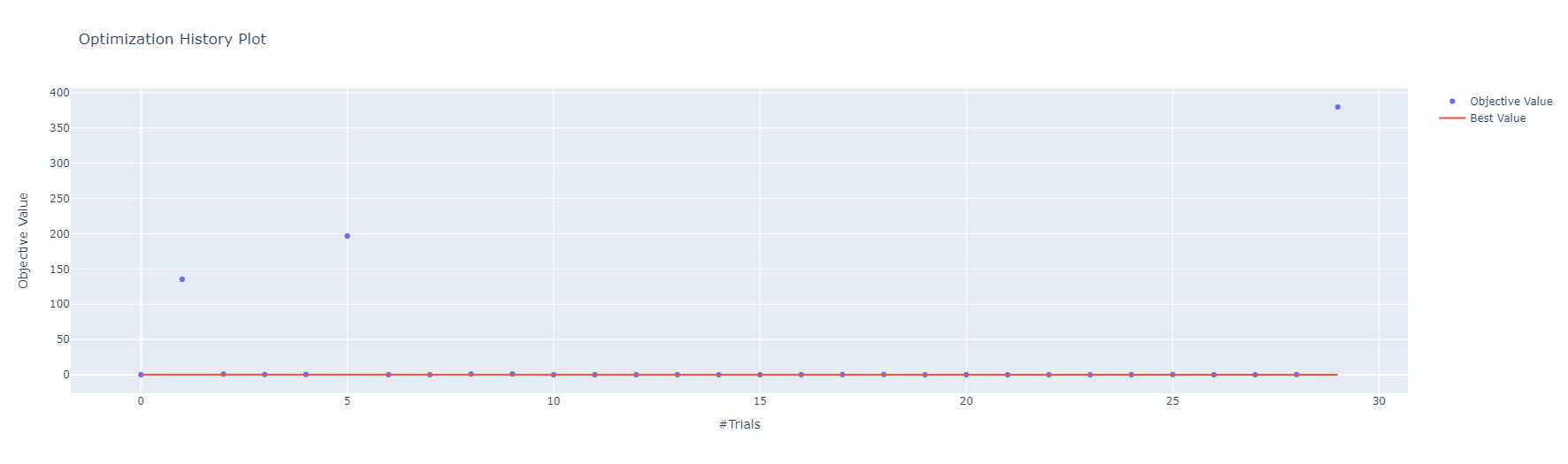
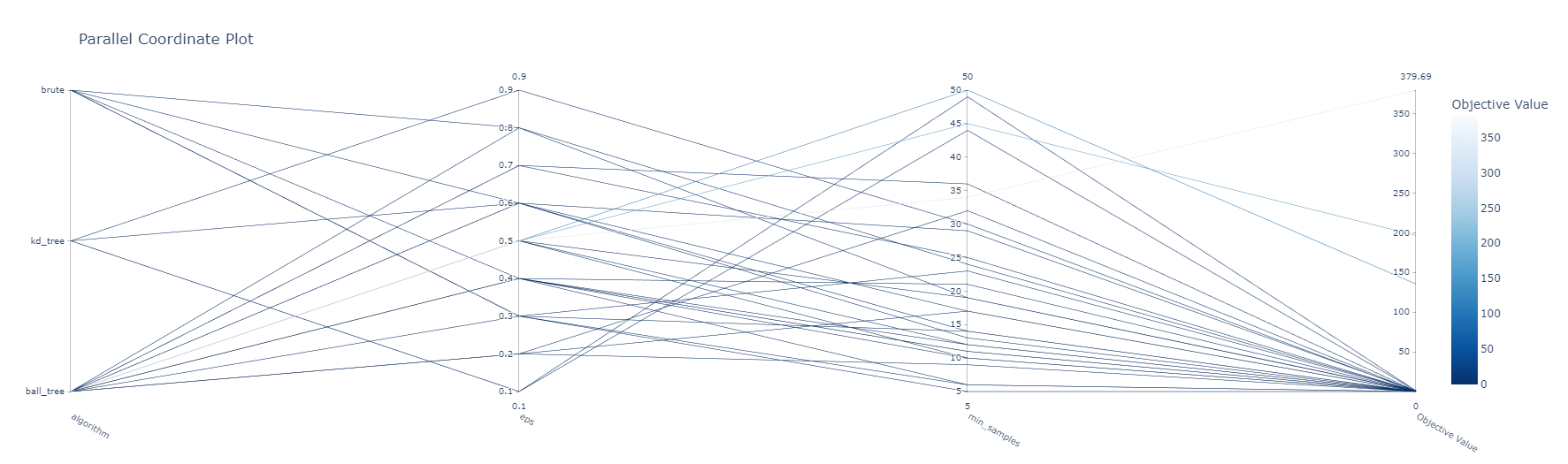
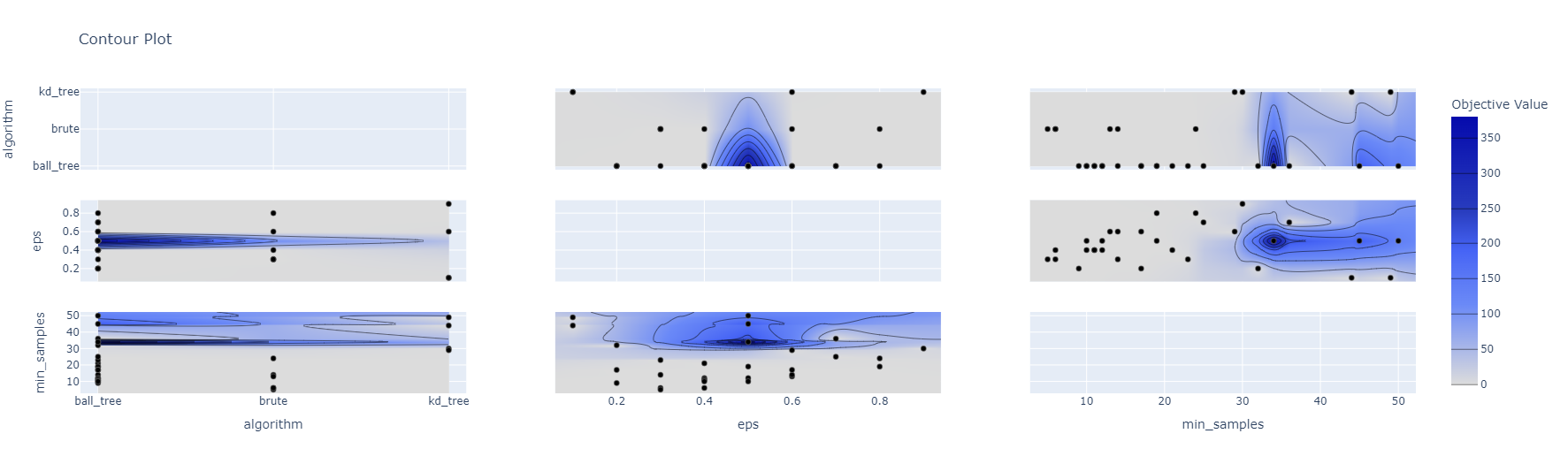
Clustering
Embeddings (4 dim)
Quality Label
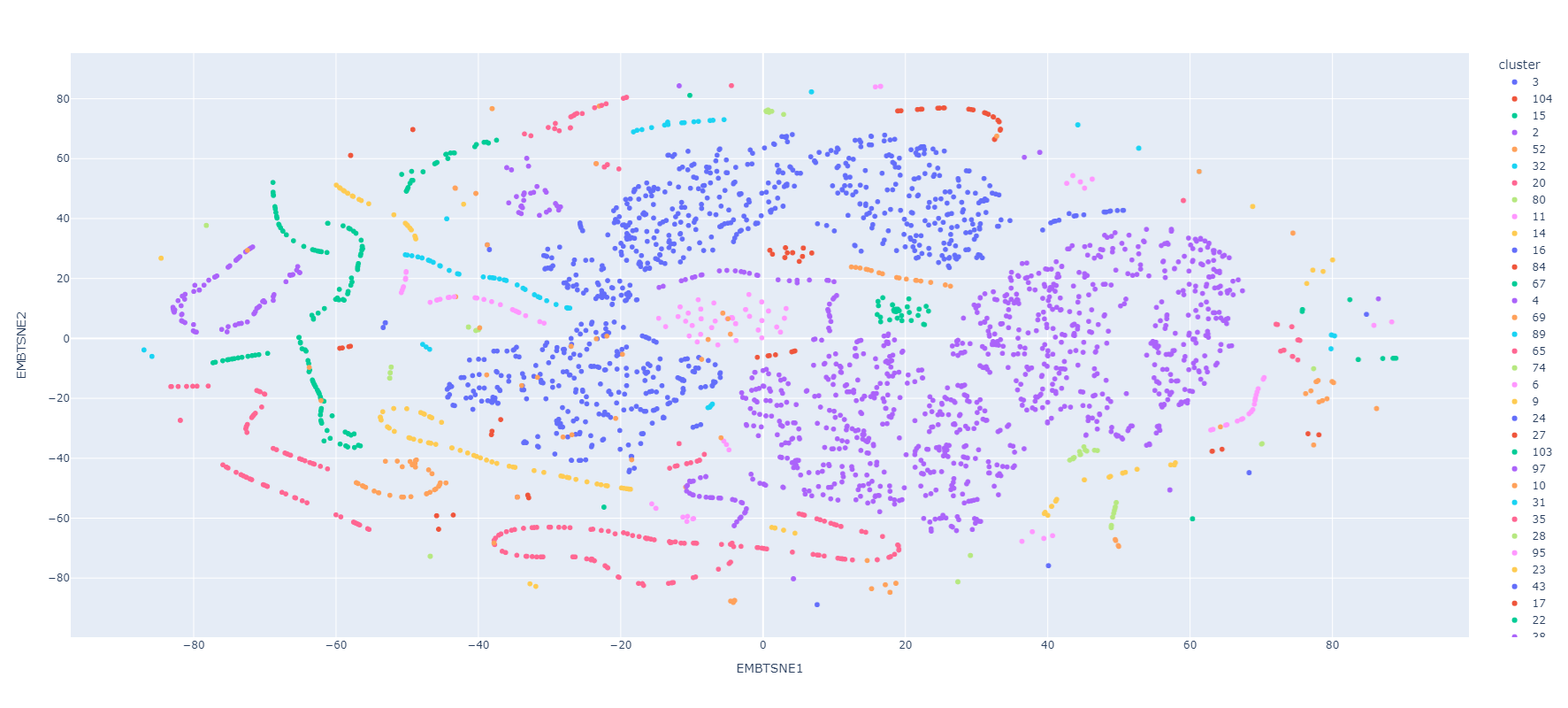
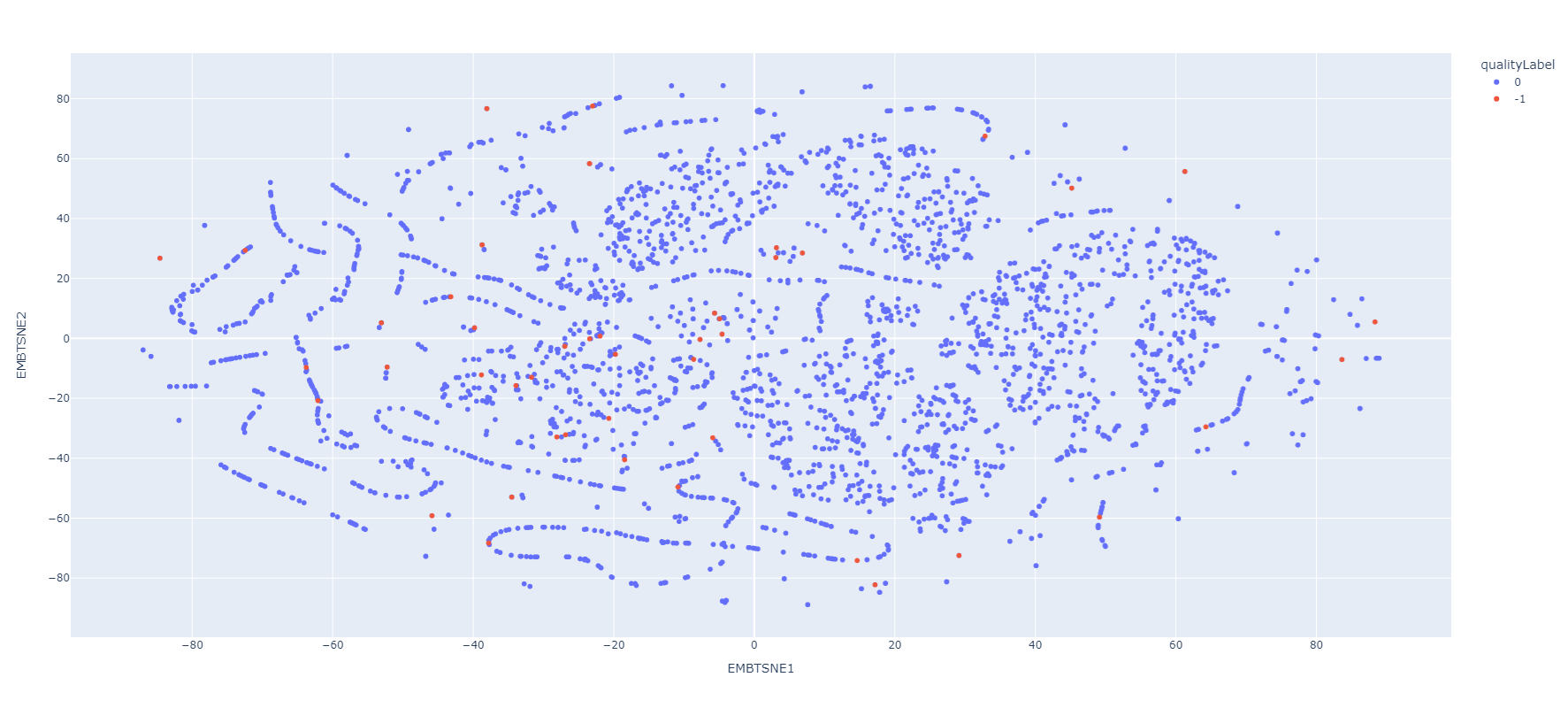
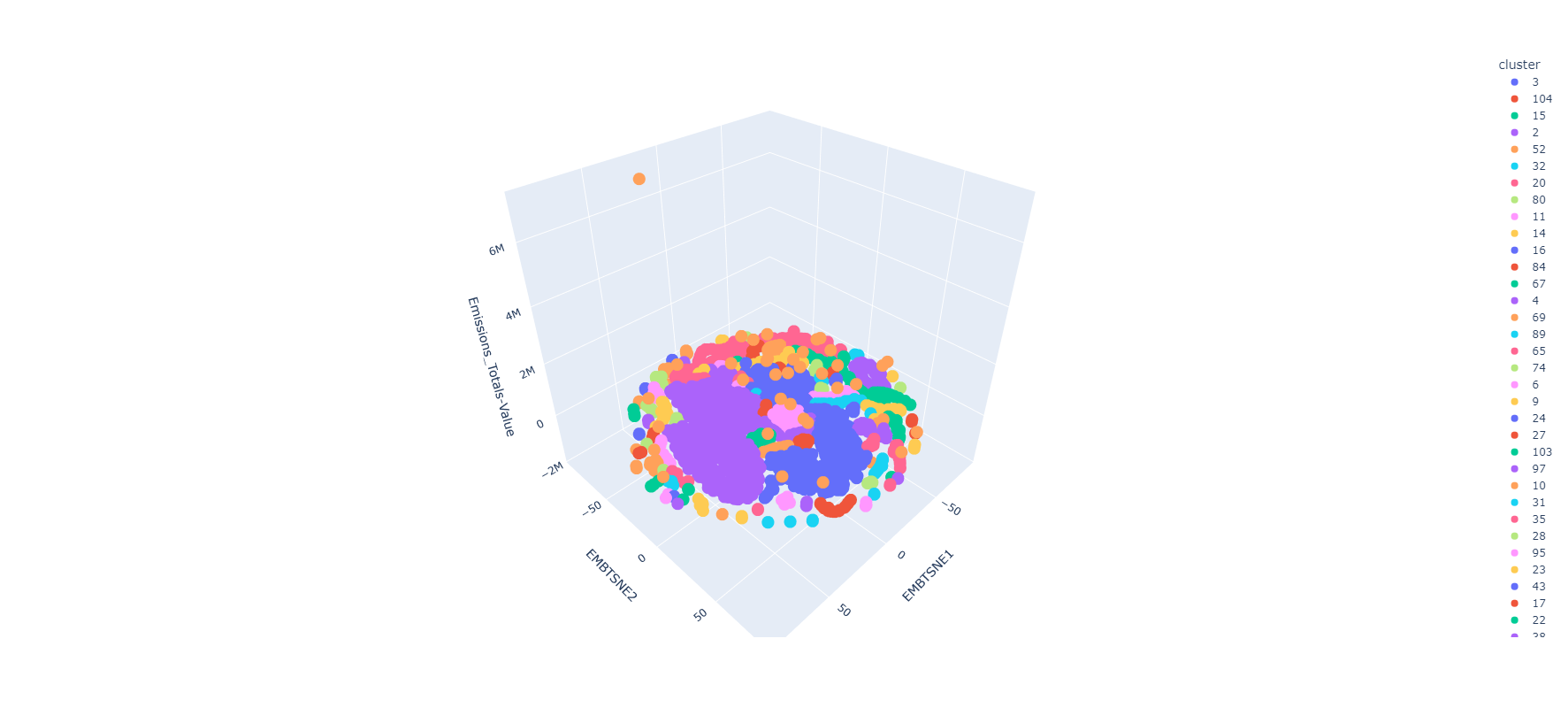
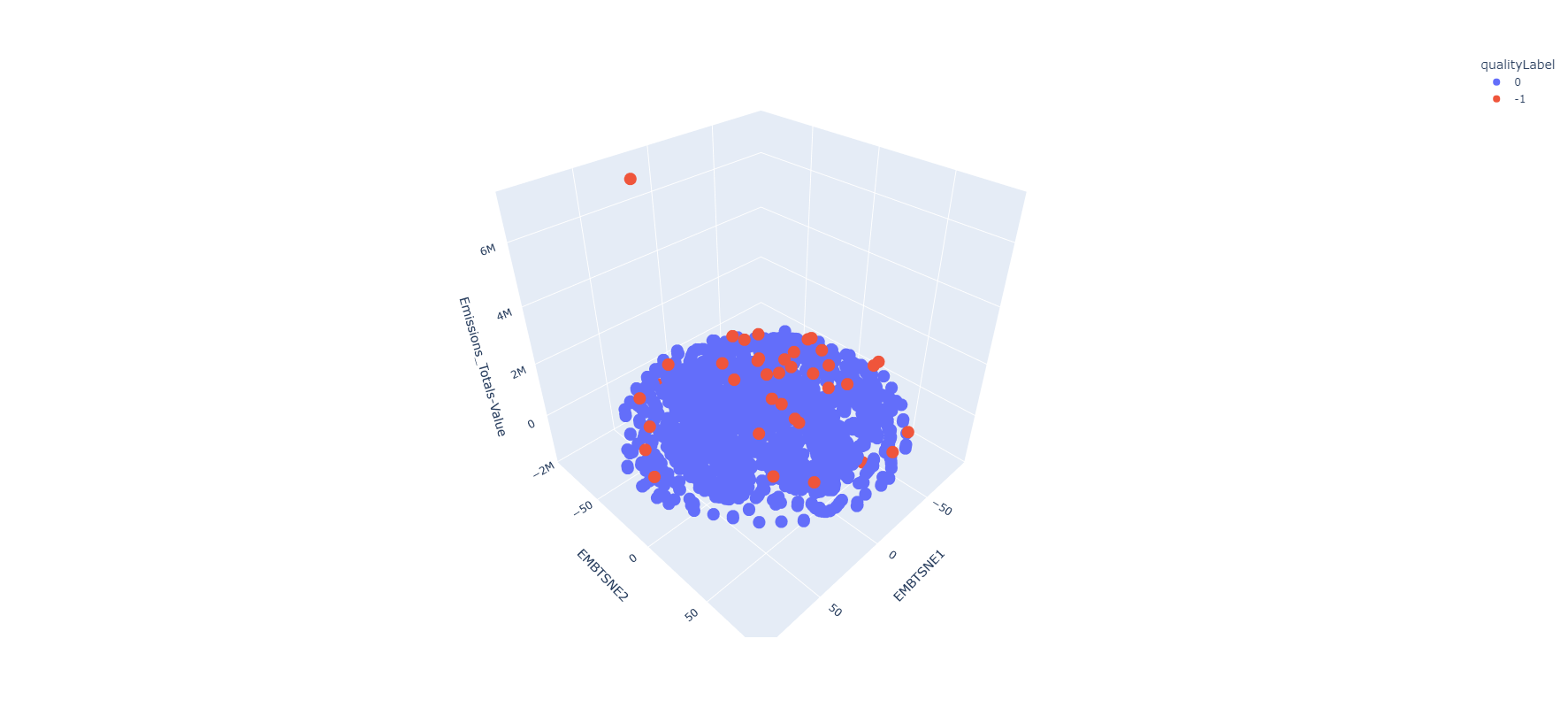
2-Dim
3-Dim

JCR (Junio-Julio-Agosto):
- VSM para indicadores de producción, precios, emisiones y población
- Regresión o Clasificación del cambio de temperatura con el VSM
JCR (Junio-Julio-Agosto):
- VSM para indicadores de producción, precios, emisiones y población
Tesis (Agosto-Diciembre):
- Regresión o Clasificación del cambio de temperatura con el VSM

¡Gracias por su atención!