Minería de Datos


Jacobo G. González León
@jacoboggleon
Temario
- Introducción a la Minería de Datos
- Pre-procesamiento de datos
- Técnicas de minería de datos
- Evaluación de los resultados obtenidos y presentación de datos
- Herramientas para Minería de Datos
Organización
- Introducción a la Ciencia de Datos
- Introducción a la Minería de Datos
- Herramientas para la Minería de Datos
- Entendimiento de los datos
- Preparación de los datos
- Técnicas de Minería de Datos
- El problema del "aprendizaje"
- Evaluación de los modelos
- Implementación
Evaluación
| Método de aprendizaje | Porcentaje (%) |
|---|---|
| Examen escrito sobre el dominio y compresión teórico-empírica. | 10 |
| Prácticas y participación con propuestas de casos de estudio. | 30 |
| Tareas individuales y colaborativas. | 20 |
| Proyecto integrador en el que se apliquen y demuestren los conocimientos adquiridos. | 40 |

Bibliografía
- Delmater y Hancock. (2001). Data mining explained. E.U.A.: Digital Press.
- Han y Kamber. (2000). Data mining. Concepts and techniques. E.U.A .:Academic Press.
- Hand et al. (2001). Principles of data mining (adaptive computation and machine learning). E.U.A.: MIT Press.
- Jiawei, Han, Kamber, Micheline y Pei, Jian. (2012). Data mining: concepts and techniques. USA: Morgan Kaufmann Publishers.
- Spangler, Scott y Kreulen, Jeffrey. (2008) . Mining the talk: unlocking the business value in unstructured information. USA: Pearson Education.
- Berry y Linoff. (2000). Mastering data mining, E.U.A.:Wiley.
- Feldman, Ronen y Sanger, James. (2007). The text mining handbook : advanced approaches in analyzing unstructured data. U. S. A.: Cambridge. ·
- Russell, Matthew A. (2011). Mining the social web. U. S. A.: O´Reilly.
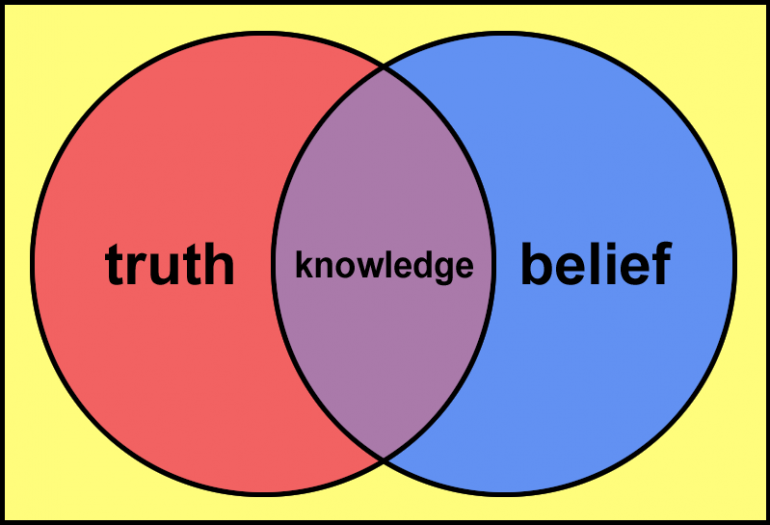
Introducción a la ciencia de datos
Plan del día
- Explorar, definir, introducir entender el área de estudio

Hipótesis inicial

Epistemología y ciencia
(de datos)
ἐπιστήμη, epistēmē, knowledge, conocimiento
-λογία, -logia, -logy, -logía
El estudio del conocimiento

datos
Scientia, science, ciencia
(a.k.a conocimiento)

Sistema para generar conocimiento


Ágora

Introducción a la Minería de Datos
Plan del día
- Entender el proceso del descubrimiento de conocimiento y la minería de datos
- Explorar fuentes de datos
- Revisar el concepto Data Warehouse (OLAP y OLTP)
- Entender la relación de la minería de datos con otras disciplinas
- Revisar algunas aplicaciones de minería de datos
- Definir qué es y que no es minería de datos
- Introducir y clasificar las técnicas de minería de datos
Hechos conocidos, sin procesar, que podrían registrarse y almacenarse, a partir de los cuáles se produce información.
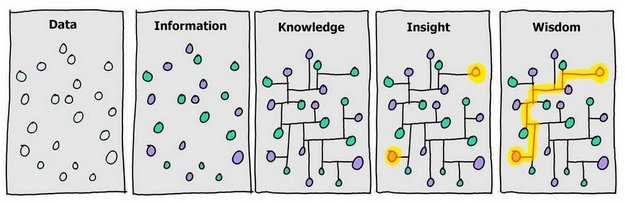
Datos

- Recopilamos datos de nuestros sensores
- Procesamos los datos para obtener reglas abstractas
- Controlamos nuestras acciones en ese entorno
- Almacenamos esas reglas en nuestros cerebros
- Recordamos y los usamos estas reglas cuando es necesario
Problema: percepción del entorno
¿Cómo percibimos el mundo?
Propuesta de solución
Recolectar datos
Procesar datos
Controlar las acciones
Almacenar reglas
Recordar las reglas
Usar las reglas
Encontrar patrones





- 2008-2018
-
45 indicadores:
- educación, salud, alimentación y vivienda
- "generar información no sólo de acceso sino también de calidad"
- "herramientas en la elaboración de los diagnósticos de cualquier política social"
Problema: modelo mutidimensional
¿Cómo medir la pobreza con ~45 variables?
Datos
(experimentales)
Método de aprendizaje
Parámetros
Distribución desconocida (compleja)
Modelo
(basado en datos)
Propuesta de solución
Función desconocida (compleja)
Generalización
(compleja)
53%
47%
Knowledge Discovery in Databases (KDD)
Estructurados
Semi-estructurados
Cuasi-estructurados
No-estructurados



\( dominio(variable_{numérica}) = \mathbb{R} \)
\( dominio(variable_{categórica}) = \lbrace{s_1,s_2,...,s_n}\rbrace \)
número de personas= 4
variables cuantitativas
variables cualitativas
clima={soleado, lluvioso}
Tipos de datos
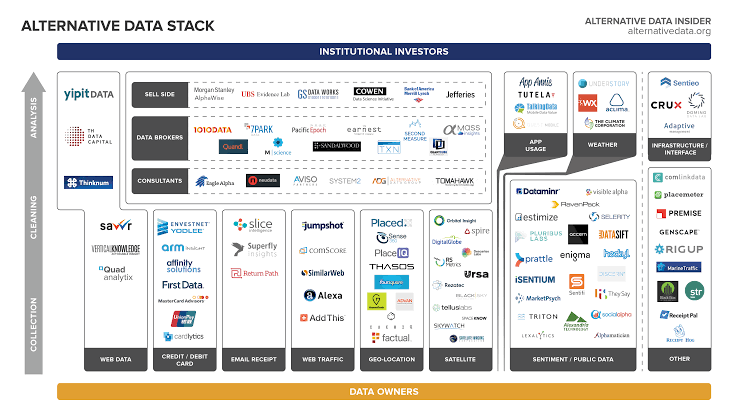
Datos alternativos
Data warehouse
Estructura global de los datos
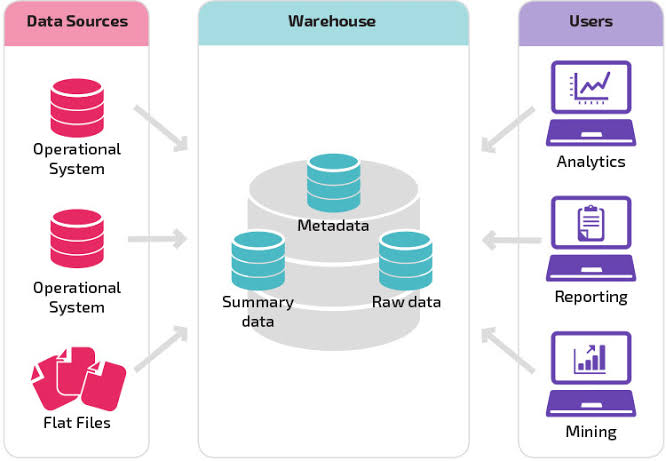
Data warehouse

Extract Transform Load (ETL)
Optimizar lectura y escritura
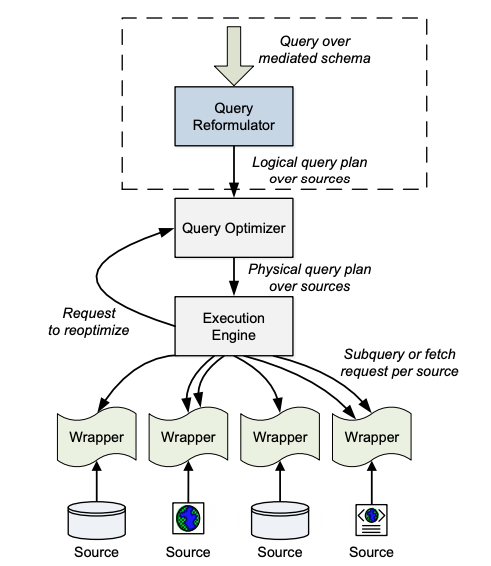
Integración de datos

Ch 3. Describing Data Sources. Hai Doan, Alon Halevy & Zachary Ives: Principles of Data Integration Morgan Kaufmann, 1st edition, 2012. ISBN 0124160441 http://research.cs.wisc.edu/dibook/
Heterogeneidad semántica
(diferencias)
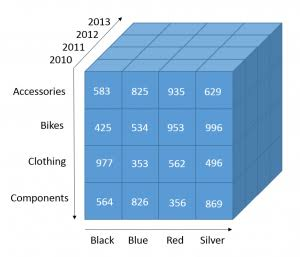
OnLine Analytical Processing (OLAP)
OLAP
Cubo de datos
Optimizar lectura y escritura
OnLine Transaction Processing (OLTP)
OLTP
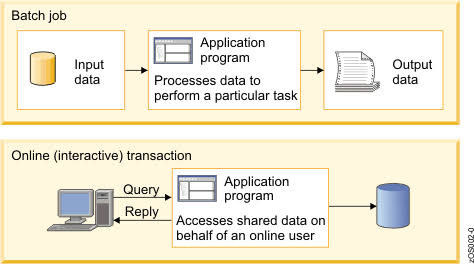
Transacción
Optimizar el proceso de los datos
Minería de datos
Cómputo distribuido
Procesamiento del lenguaje natural
Ciencia
de
datos
Inteligencia
artificial
Estadística
Análisis de datos
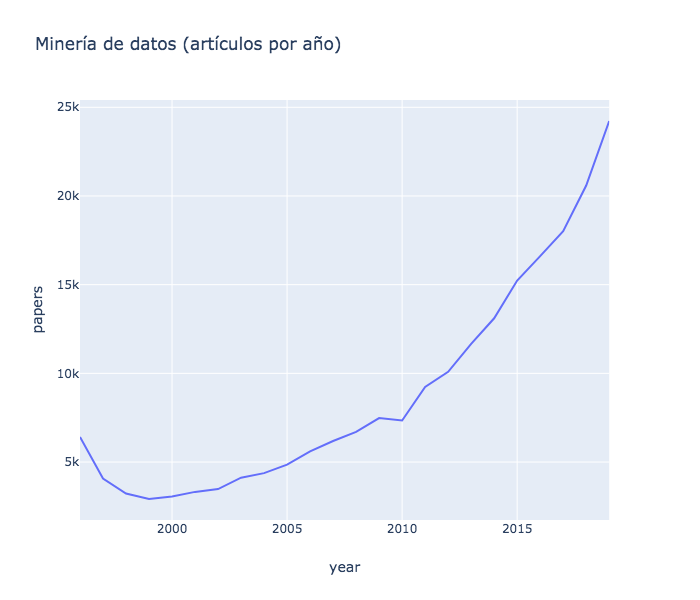
Total: 302,527



¿Qué es Minería de Datos?
Proceso iterativo para descubrir información y generar conocimiento, a través de métodos automáticos o manuales.

El estudio de el comportamiento inteligente logrado a través de medios computacionales. La representación del conocimiento y el razonamiento son parte de la IA que se enfoca en cómo un agente usa lo que sabe para decidir qué hacer
Es el estudio de pensar como un proceso computacional
¿Qué es Inteligencia Artificial?
Primera aproximación al aprendizaje automático
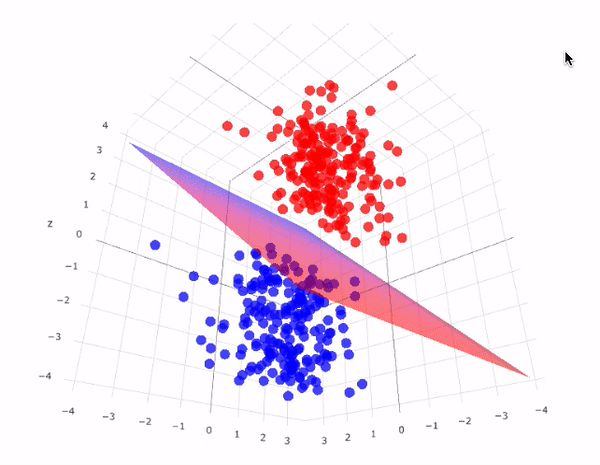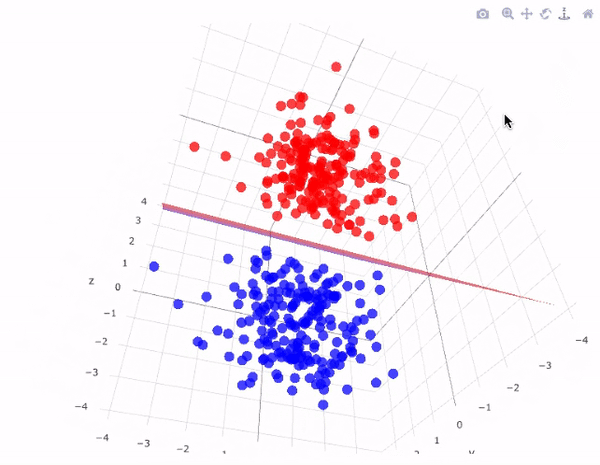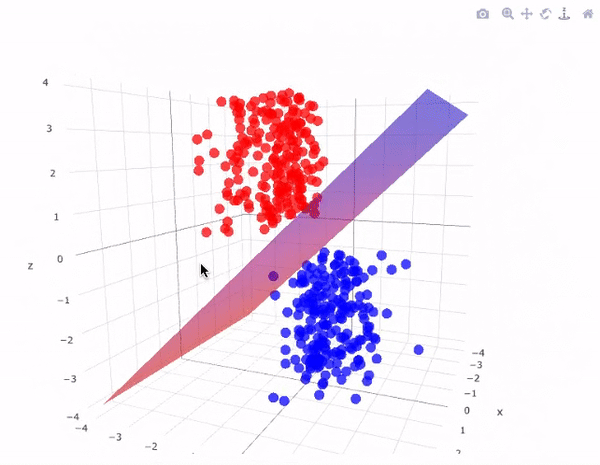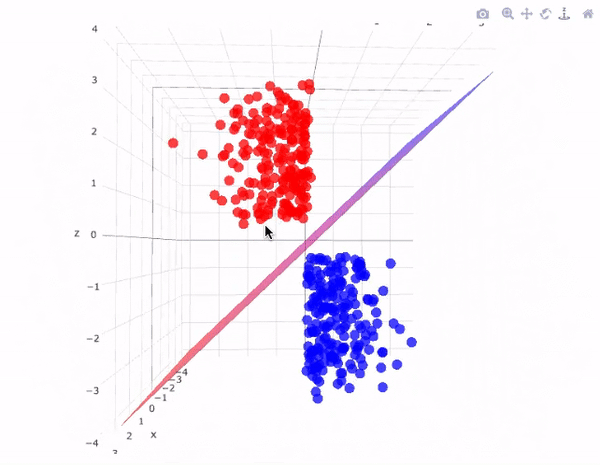
Problema geométrico \(n-\text{dimensional}\)
*Supervisado
No supervisado
Supervisado
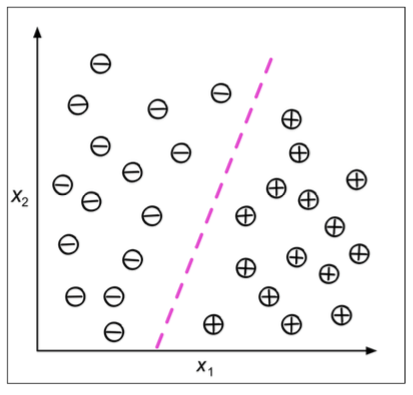
Regresión
Clasificación
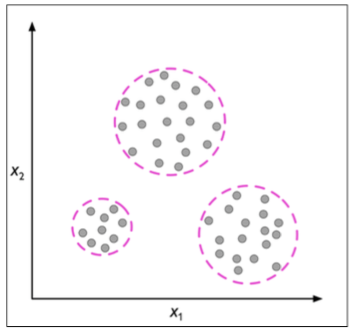
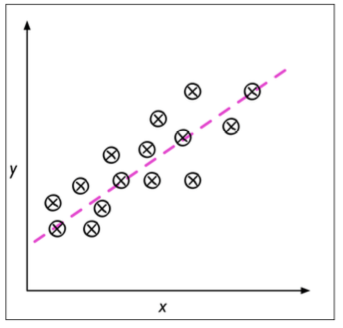
Reforzado
Predicción
Descripción
Aprendizaje automático para Minería de Datos
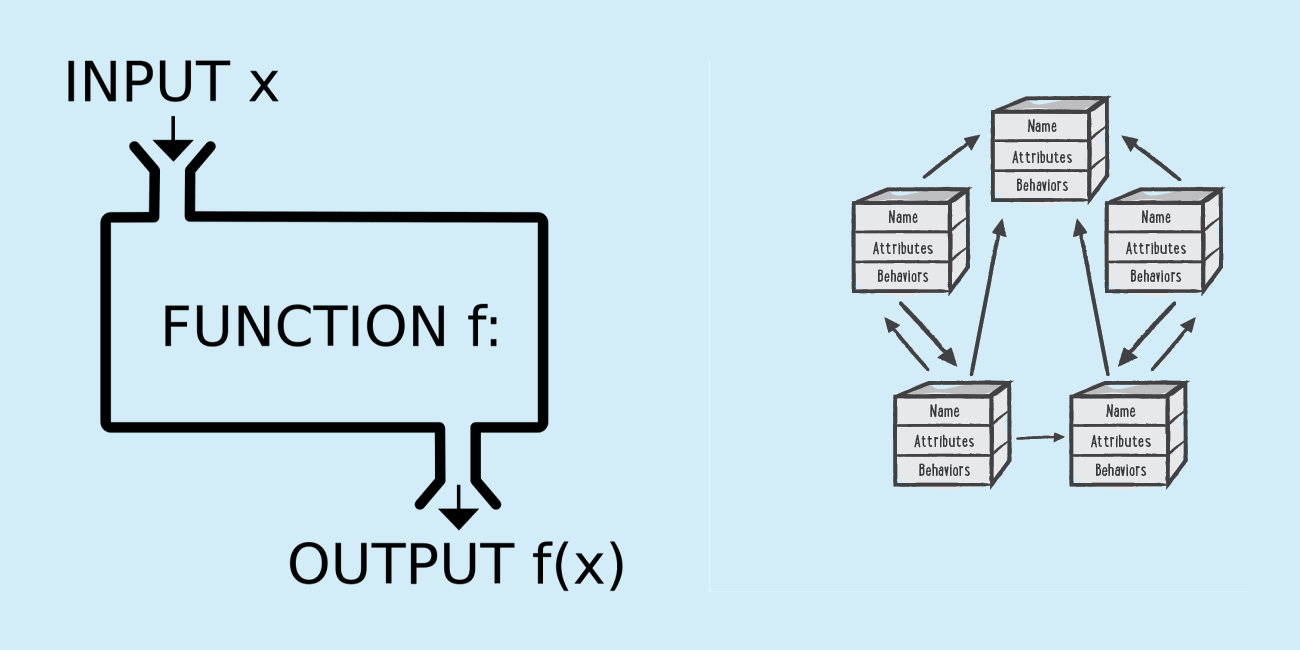
input
output
Sistema tradicional
entrada
resultado esperado
modelo
Aprendizaje automático como sistema inteligente
*Con aprendizaje automático supervisado
variables explicativas \(X=\{x_1, x_2, \dots, x_n\}\)
variable explicada \(y\)
Resumen de la Unidad 1
- Introducción y definición del área de estudio
- Tipos y fuentes de datos
- Historia (Warehouse, OLTP y OLAP)
- Descubrimiento del conocimiento (KDD)
- Disciplinas y aplicaciones relacionadas
- Descripción breve de técnicas
Miscelánea
Objetivo de la sección
- Explorar, definir, introducir conceptos claves en el área de estudio
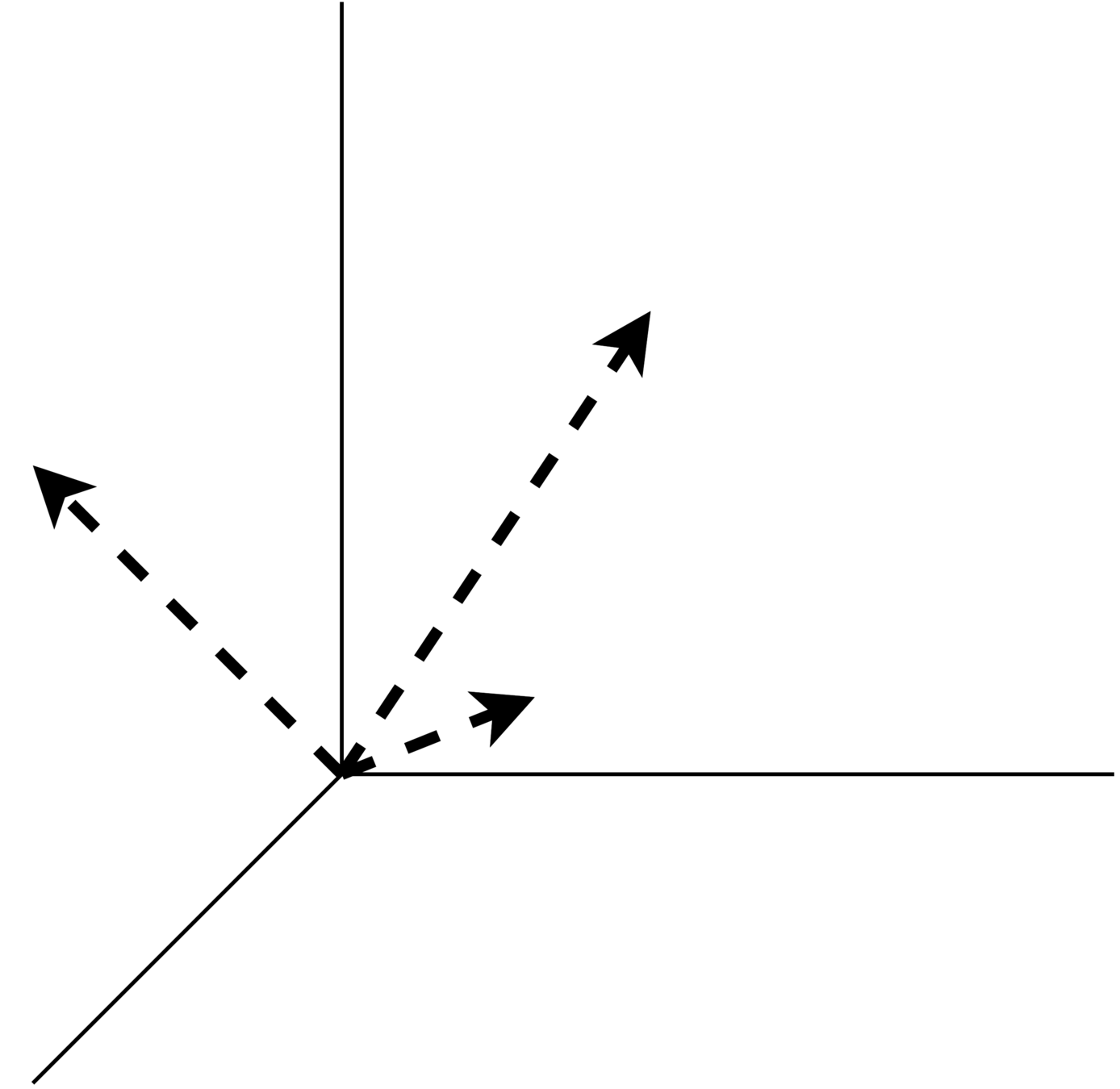
\(\text{Característica 1}\)
Vector Space Model
\(\text{Característica 2}\)
\(\text{Característica 3}\)
Espacio euclidiano
¿Qué es computar? ¿Cuándo algo es computable?

Problema de decisión:
un algoritmo para decidir si un enunciado dado se puede demostrar a partir de los axiomas usando las reglas de la lógica
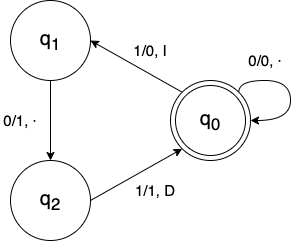
Tesis de Alan Turing (1936)
Máquina de Turing

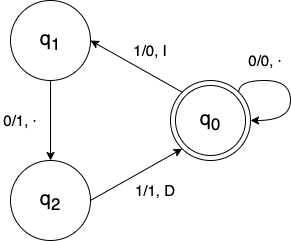
0
1
0
1
0
1
1
0
1
Máquina de Turing
0
0
1
1
0
0
1
0
1
0
1
0
0
1
0
0
0
1
A
B
+
C
entradas
salida
proceso
Tesis Church-Turing
¿Se tendrán mayor poder de cómputo si ...
- ... se tienen más cintas?
- ¿... se tiene una infinita secuencia de símbolos (palabra)?
- ¿... se tienen más alfabetos que sólo \(\{0,1\}\)?
- ¿... la cabecera se mantiene en la misma posición?
- ¿... se permite el no determinismo?
(no regresa el mismo resultado)
R1 = todas las variaciones son equivalentes en capacidad de cómputo
R2 = una función es computable de manera realista (o algorítmica) si y solo si es computable por una máquina de Turing
¿Qué es un algoritmo?
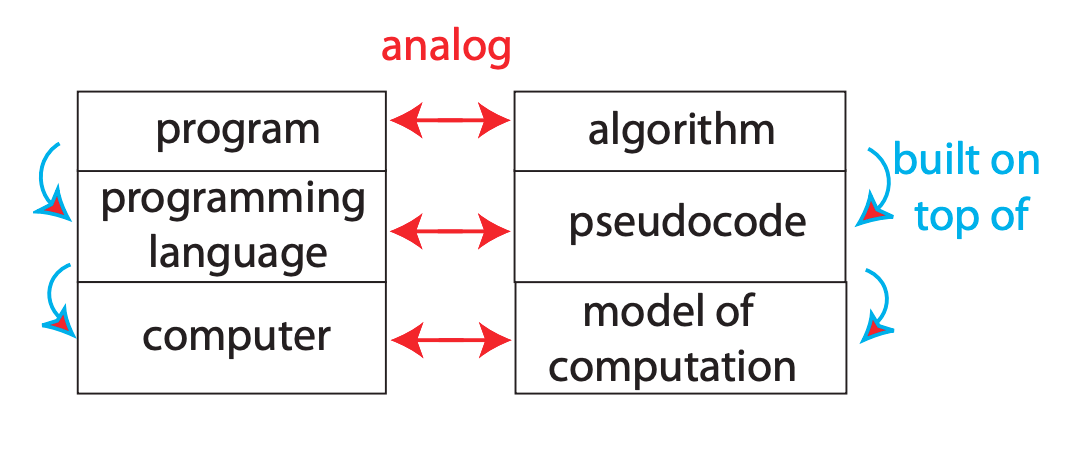

matemáticas
cómputo
Gabriela Santiago Valdivia de TEyMD Grupo 16 MAC FES-Acatlán
¿Qué es un algoritmo?
... procedimiento paso a paso para realizar alguna tarea en un período de tiempo finito
¿Qué es un estructura de datos?
... es una forma sistemática de organizar y acceder a los datos.
espacio
¿Cómo escribir un algoritmo?
Metodología general: componentes
- Un lenguaje para describir algoritmos.
- Un modelo computacional que los algoritmos ejecutan dentro.
- Un paradigma de programación.
Metodología general: Modelo de computación
Conjunto de operaciones primitivas de alto nivel que son independientes del lenguaje de programación utilizado y pueden identificarse también en el pseudocódigo
- Asignar un valor a una variable
- Llamar a un método
- Realizar una operación aritmética
- Comparar dos números
- Indexación en una estructura de datos
- Seguir (leer) la referencia de objeto
- Retorno de un método
¿Cómo escribir un algoritmo?
Metodología general: Modelo de computación: Random Access Machine Model
\(w={w_1,w_2,... }\)
la memoria almacena una palabra (word)
?
acceso aleatorio a la memoria via una operación primitiva
¿Cómo escribir un algoritmo?
Metodología general: pseudocódigo
Ejemplo: encontrar el elemento máximo en un arreglo \(A\) con \(n \in \Z\) elementos enteros
Algorithm arrayMax(A, n): Input: An array A storing n ≥ 1 integers. Output: The maximum element in A. currentMax ← A[0] for i ← 1 to n − 1 do if currentMax < A[i] then currentMax ← A[i] return currentMax
¿Cómo escribir un algoritmo?
Pseudocódigo: lenguaje de programación + lenguaje natural
- Expresiones:
- \(a \leftarrow 5\)
- Declaración de métodos:
- \(algorithm\) \(\text{method-name}(param1, param2, . . .)\)
- Estructuras de decisión:
- \(if\) \(\text{ condition }\) \(then\) \(\text{ true-actions }\) \(else\) \(\text{ false-actions }\)
- Ciclos while:
- \(while\) \(\text{ condition }\) \(do\) \(\text{ actions }\)
- Ciclos repeat:
- \(repeat\) \(\text{ actions }\) \(until\) \(\text{ condition }\)
-
Ciclos for:
- \(for\) \(\text{ variable-increment }\) \(do\) \(\text{ actions }\)
-
Indexación de arreglos:
- \(A[i]\)representa la \(iésima\) posición/espacio-de-memoria en el arreglo \(A\)
-
Llamadas a métodos:
- \(object.\) \(\text{method-name}(args)\)
- Retorno de métodos:
- \(return\) \(value\)
¿Cómo escribir un algoritmo?
Paradigmas de programación: funcional vs orientado a objetos
¿Cómo escribir un algoritmo?
Dataframe como estructura de datos
*Con aprendizaje automático supervisado
variables explicativas \(X=\{x_1, x_2, \dots, x_n\}\)
variable explicada \(y\)
Dataframe como estructura de datos
*Con aprendizaje automático no supervisado
variables explicativas \(X=\{x_1, x_2, \dots, x_n\}\)
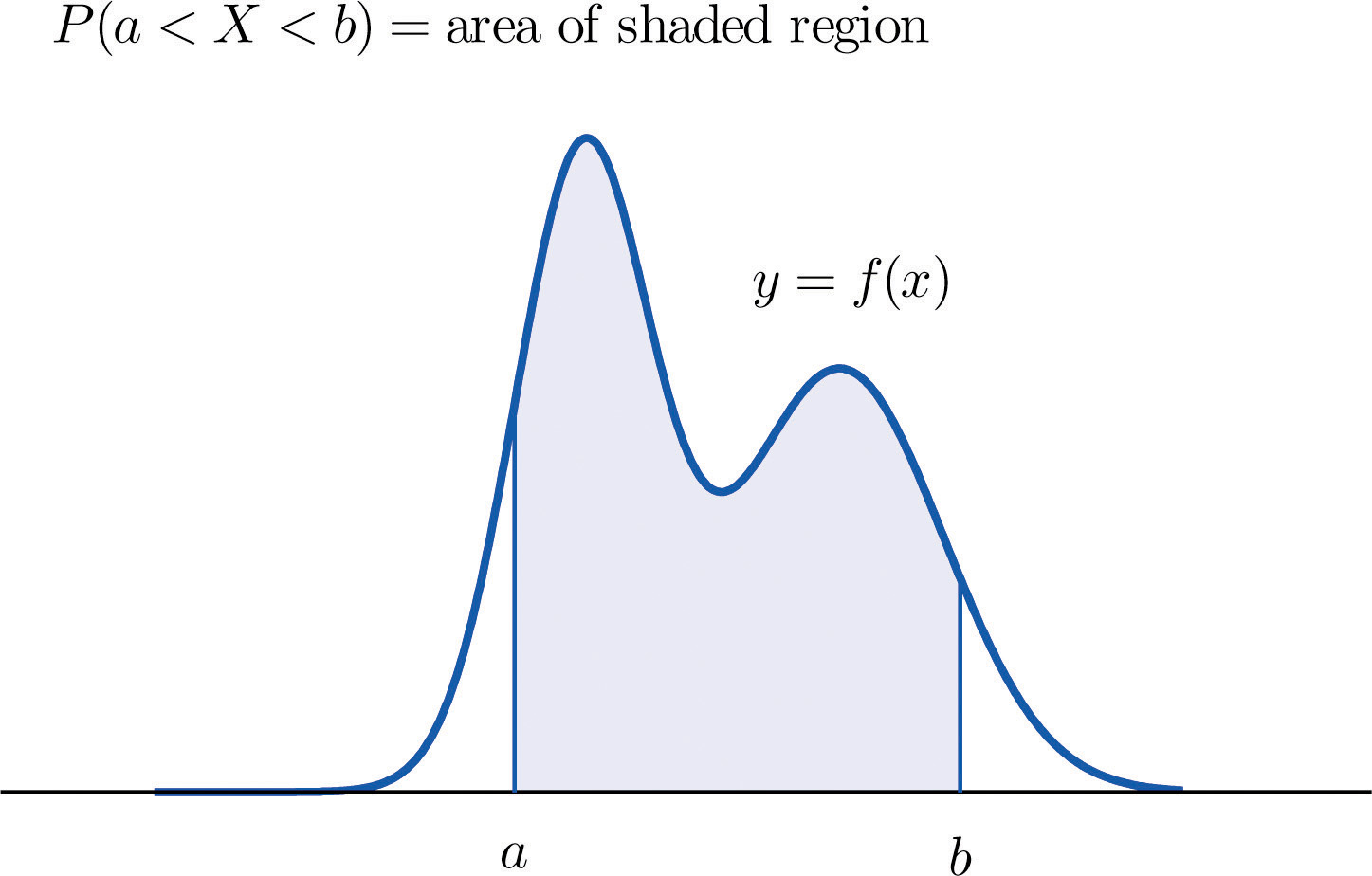
Variables aleatorias
Entorno:
i.i.d data
Suposiciones de independencia:
en los datos o, no hay dependencia entre características, o la dependencia es lo suficientemente menor como para que podamos ignorarla.
Independiente e idénticamente distribuído


Entendimiento de los datos
Plan del día
- Definir los tipos de datos para minería de datos
- Entender las diferencias entre variables numéricas y categóricas
- Introducir el concepto de alta dimensionalidad
- Explorar las propiedades de la alta dimensionalidad
Recordando el proceso KDD
Representación de la naturaleza
Tipos de datos
Clasificación de los atributos
Tipos de datos
\( dominio(variable_{numérica}) = \mathbb{R} \)
\( dominio(variable_{categórica}) = \lbrace{s_1,s_2,...,s_n}\rbrace \)
variables cuantitativas
variables cualitativas
Clasificación de los atributos
Variables cuantitativas o numéricas
\( dominio(variable_{numérica}) = \mathbb{R} \)
Orden
\(2 < 5\)
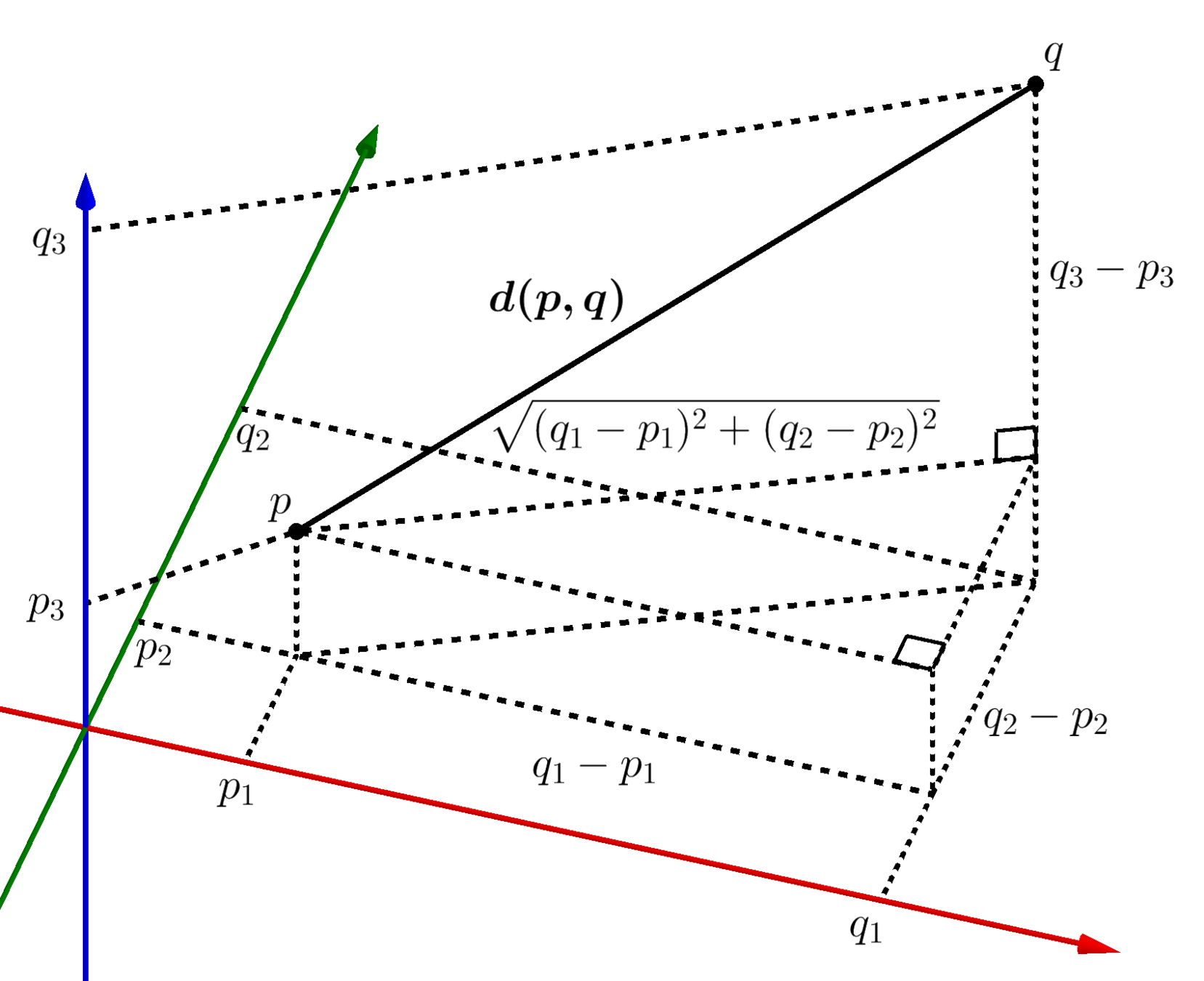
Distancia
\(d(2.3, 4.2) = 1.9\)
Escala de intervalos
(intervalo)
Escala de proporción
(ratio)

Por ejemplo:
Clasificación de los atributos
Variables cualitativas o categóricas
Escala no ordenada
(nominal)
Escala ordenada
(ordinal)
\( dominio(variable_{categórica}) = \lbrace{s_1,s_2,...,s_n}\rbrace \)


Clasificación de los atributos
Variables numéricas y categóricas
Numéricas
Categóricas
| Nivel | Intervalo | Ratio | Nominal | Ordinal |
|---|---|---|---|---|
| Característica | Distancia | Cero | Distinguir | Ordenar |
| Operaciones | + - | x / | = ≠ | < > |
| Ejemplos | Días, horas, dinero | Peso, edad | CP, ID, sexo, género | Ranking, grados, edad |
Clasificación de los atributos
Variables numéricas y categóricas
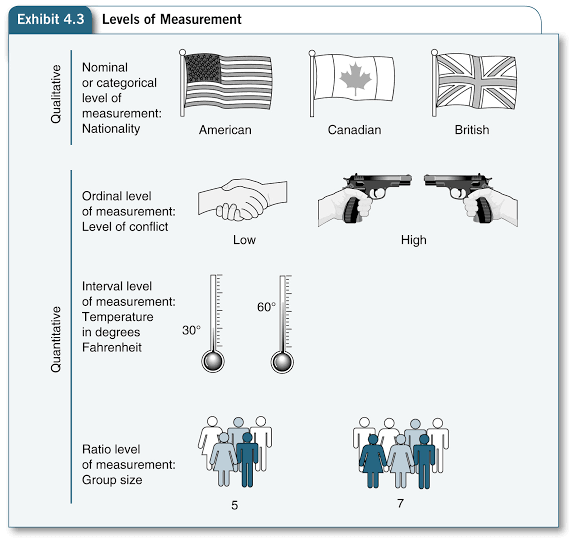
Nominal
Ordinal
Interval
Ratio
Características de los datos
Alta dimensionalidad
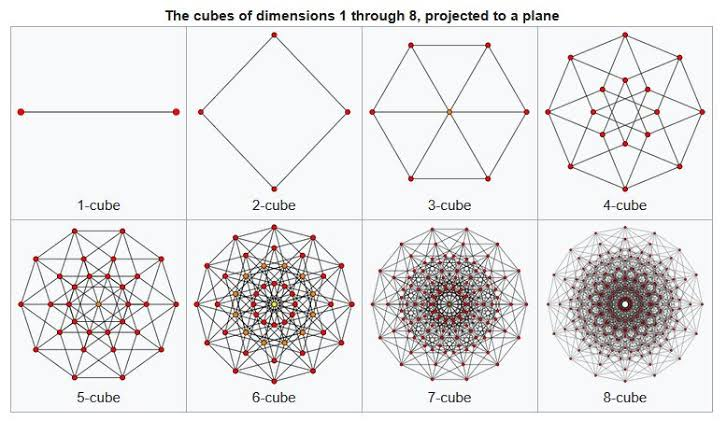

Características de los datos
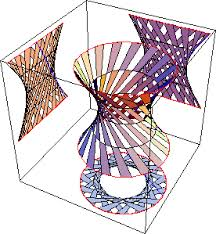
Alta dimensionalidad
"La maldición de la alta dimensionalidad"
... los objetos en espacios de alta dimensión tienen una mayor superficie para un volumen dado que los objetos en espacios de baja dimensión ...
Características de los datos
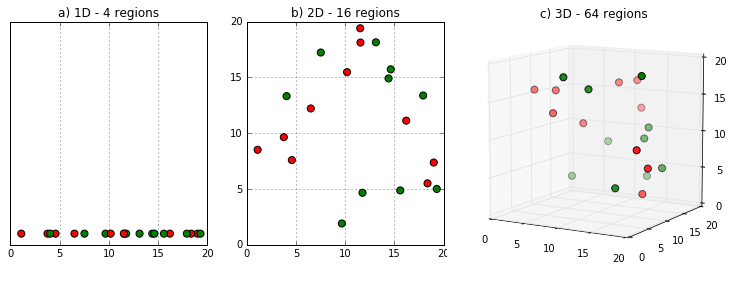
La maldición de la alta dimensionalidad
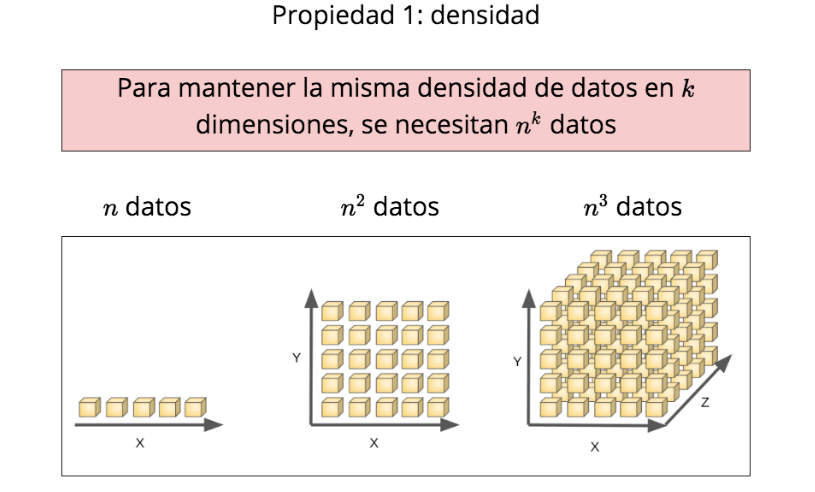
Propiedad 1: densidad
\(n\) datos
\(n^2\) datos
\(n^3\) datos
Para mantener la misma densidad de datos en \(k\) dimensiones, se necesitan \(n^k\) datos
Características de los datos
La maldición de la alta dimensionalidad
Propiedad 2: vecindad a.k.a. hypercubo
Se puede calcular la arista \(e\):
\(e(p)=P^{\frac{1}{d}}\)
donde \(p\) es la fracción de muestras y \(d\) el número de dimensiones
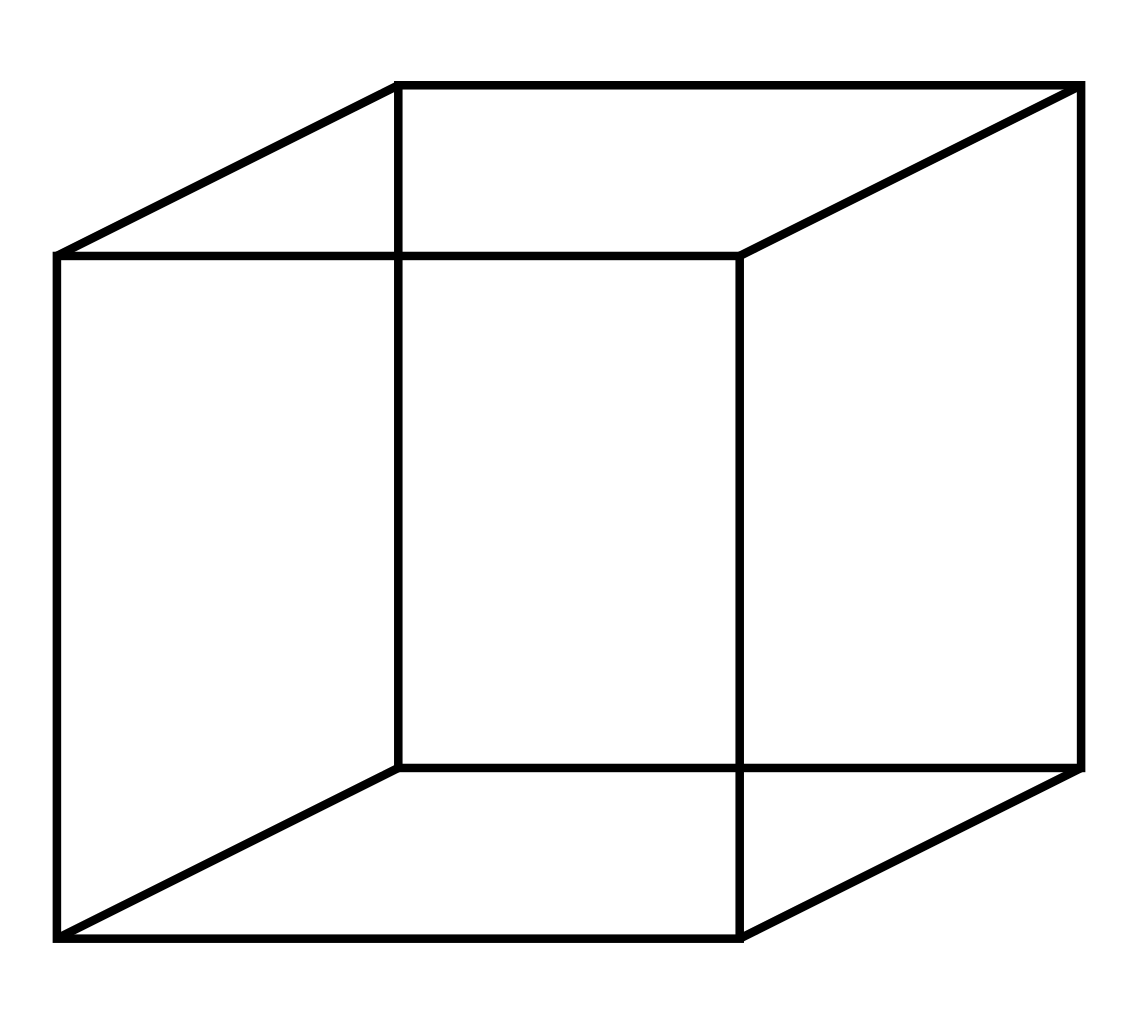
\(e\)
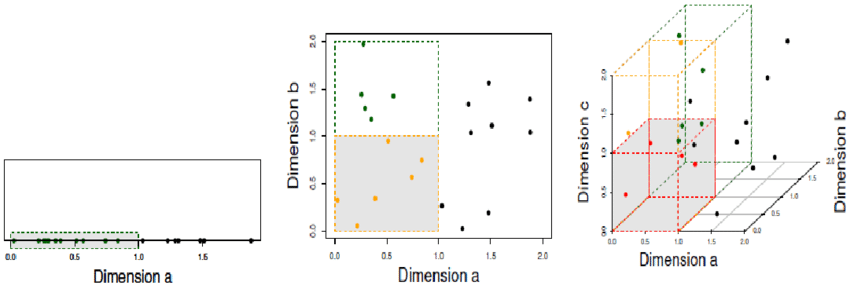
Características de los datos
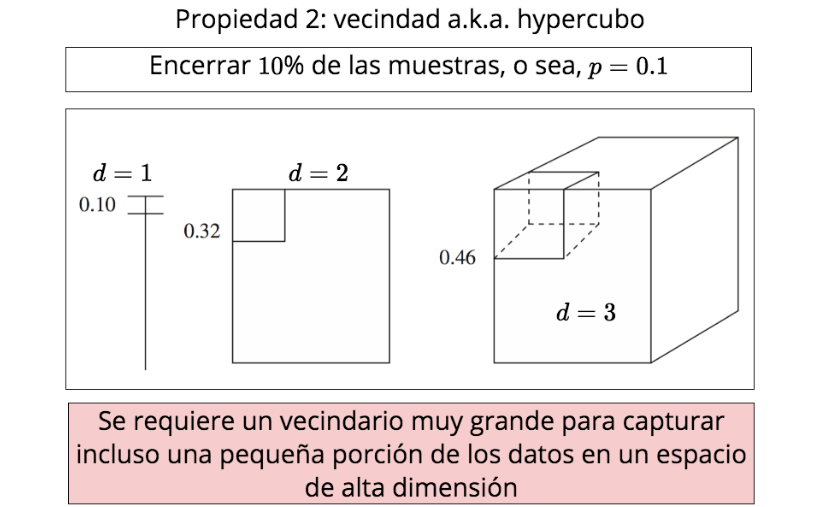
La maldición de la alta dimensionalidad
Propiedad 2: vecindad a.k.a. hypercubo
Encerrar \(10\)% de las muestras, o sea, \(p=0.1\)
\(d=1\)
\(d=2\)
\(d=3\)
Se requiere un vecindario muy grande para capturar incluso una pequeña porción de los datos en un espacio de alta dimensión
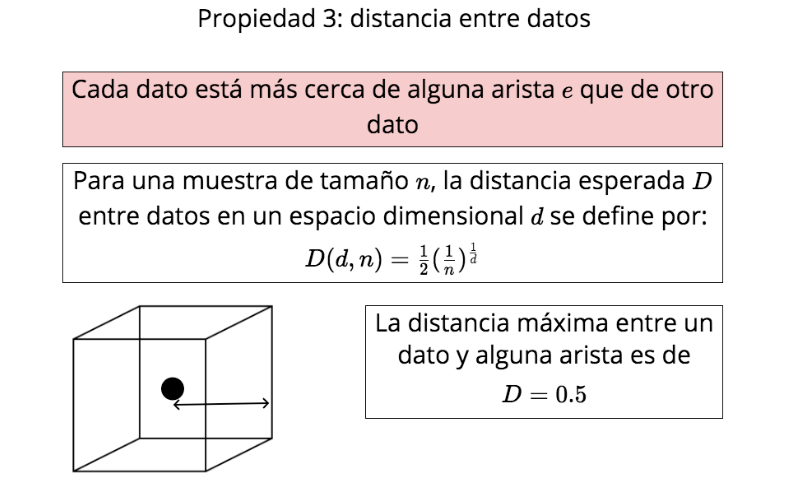
Características de los datos
La maldición de la alta dimensionalidad
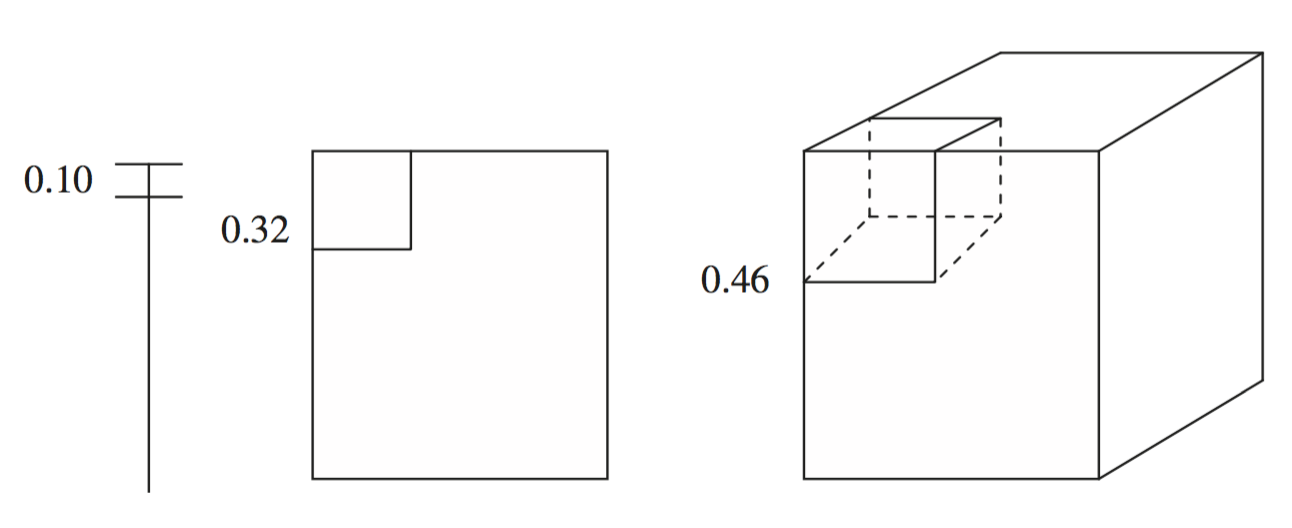
Propiedad 3: distancia entre datos
Cada dato está más cerca de alguna arista \(e\) que de otro dato
Para una muestra de tamaño \(n\), la distancia esperada \(D\) entre datos en un espacio dimensional \(d\) se define por:
\( D(d,n)={\frac{1}{2}} {(\frac{1}{n})^{\frac{1}{d}}}\)
La distancia máxima entre un dato y alguna arista es de
\(D=0.5\)
Características de los datos
La maldición de la alta dimensionalidad
Propiedad 3: distancia entre datos
Para un espacio dimensional \(d=2\) con una muestra de \(10,000\) datos, la distancia esperada (entre puntos) es \(D(2,10000)=0.005\)
Para un espacio dimensional \(d=10\) con la misma muestra de \(10,000\) datos, la distancia esperada (entre puntos) es \(D(10,10000)=0.4\)
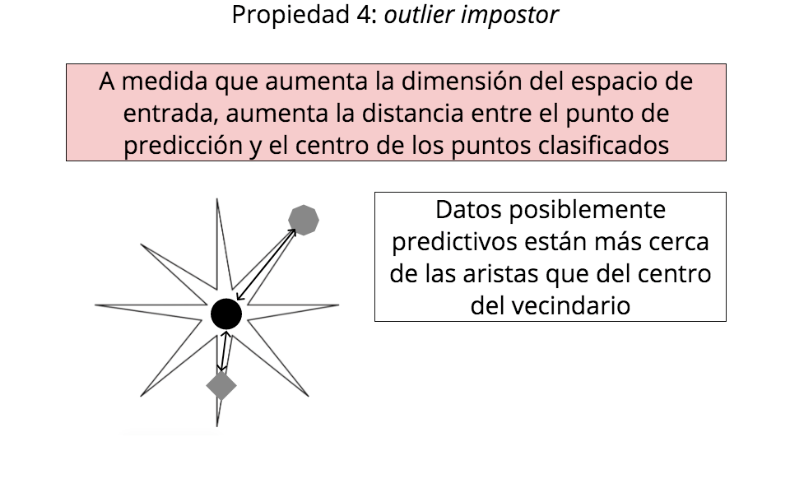
Características de los datos
La maldición de la alta dimensionalidad
Propiedad 4: outlier impostor
A medida que aumenta la dimensión del espacio de entrada, aumenta la distancia entre el punto de predicción y el centro de los puntos clasificados

Datos posiblemente predictivos están más cerca de las aristas que del centro del vecindario
Características de los datos
La maldición de la alta dimensionalidad
En las propiedades 1 y 2 se ve la dificultad de estimaciones locales en altas dimensiones
Entre más aumentan las dimensiones, se necesitan más muestras
Características de los datos
La maldición de la alta dimensionalidad
En las propiedades 3 y 4 se ve la dificultad de predecir un dato verdadero
Cualquier nuevo dato estará (en teoría) más cerca de las aristas de su hypercubo que de la parte central
Características de los datos
La maldición de la alta dimensionalidad
En las propiedades 1 y 2 se ve la dificultad de predecir un dato verdadero
Cualquier nuevo dato estará (en teoría) más cerca de las aristas de su hypercubo que de la parte central
Resumen de la Unidad
- Tipos de datos
- Variables numéricas y categóricas
- Ejemplos
- Alta dimensionalidad
- Su maldición
Herramientas para minería de datos
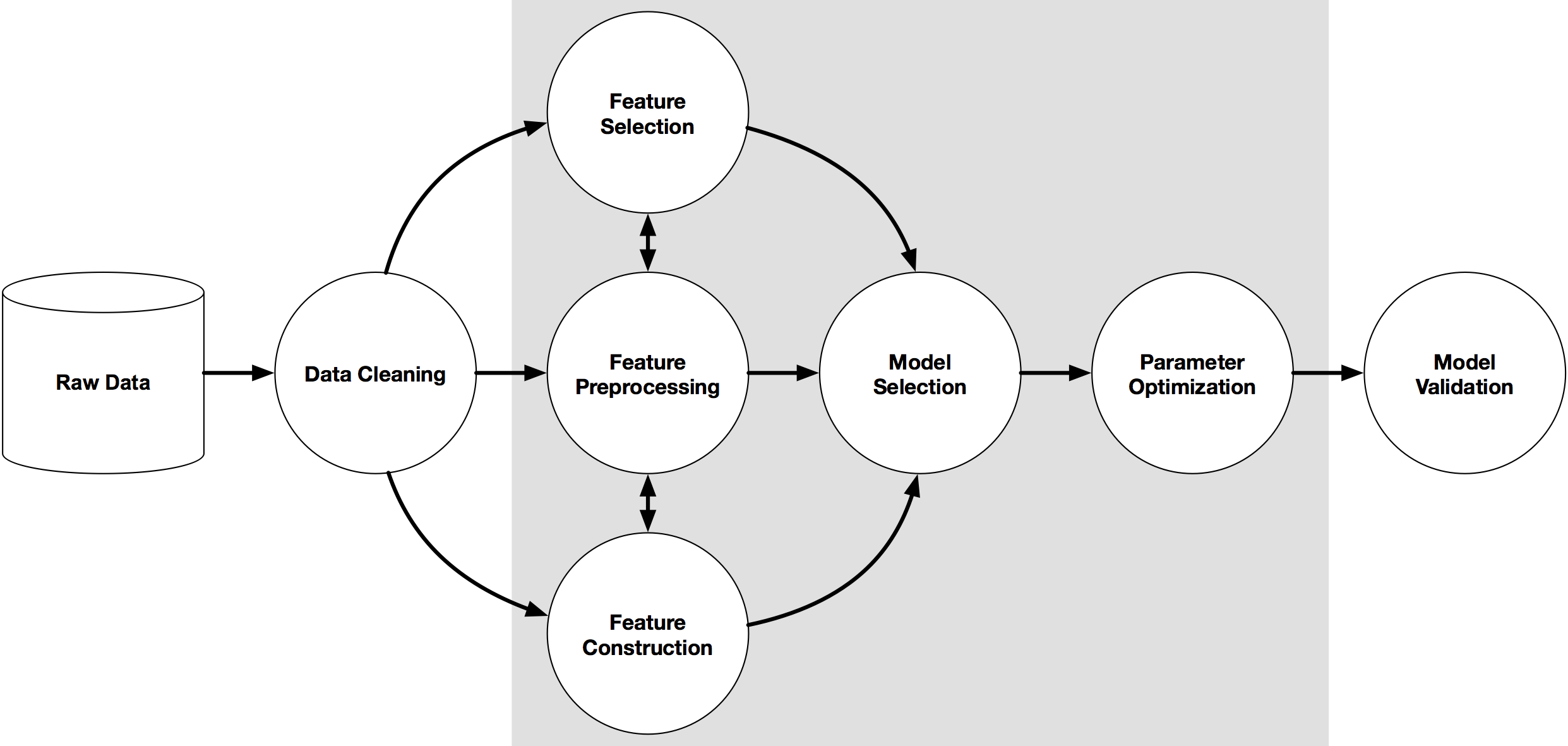
ML Pipeline: flujo de trabajo desde ML
Tareas de analítica

input
output
Black-box tradicional
entrada
resultado deseado
modelo
Black-box para ML
*Supervisado
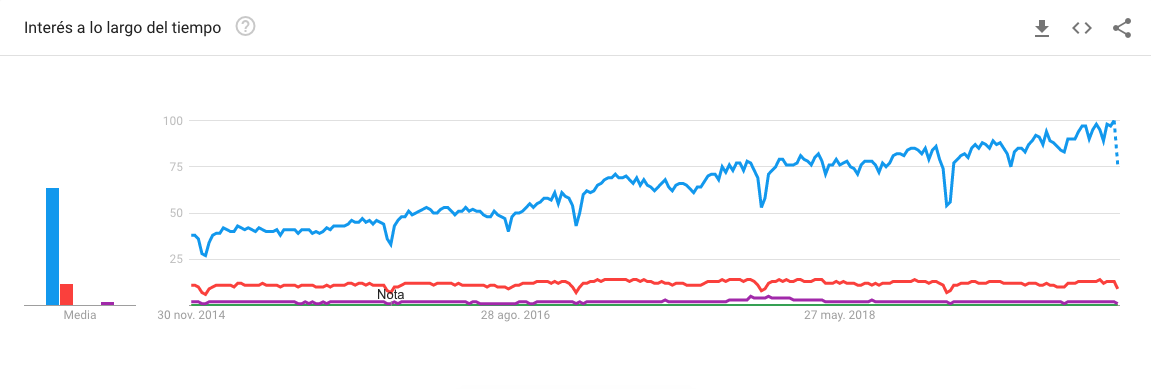
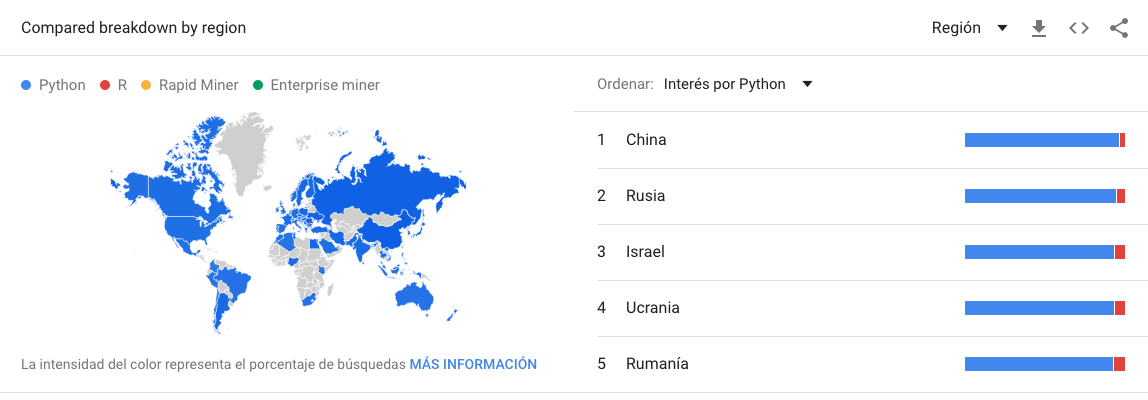
R vs Python













Open Source Data Science Ecosystem
*
*
*
Preparación de los datos
Plan del día
-
Entender los elementos del proceso de la preparación de los datos:
- Preparación de los datos
- Transformación de los datos
- Normalización
- Escalado decimal
- Normalización min-max
- Normalización
- Datos faltantes
- Análisis de datos anómalos (outliers)
- Transformación de los datos
- Reducción de los datos
- Reducción de características
- Selección de características
- Extracción de características
- Reducción de características
- Preparación de los datos
Recordando el proceso KDD
Preparación de los datos
Espacio \(n\)-dimensional: abstracción


Re-escalar
Preparación de los datos
Escalado decimal
Objetivo
Mantener los valores dentro del rango \([{-1,1}]\) moviendo el punto decimal
Método
\(v'(i)=\frac{v(i)}{10^k}\),
para un \(k\) tal que \(max(|v'(i)|)<1\),
donde \(v(i)\) es el valor \(i\)-ésimo de la variable \(v\), y \(v'(i)\) es el valor escalado
Ejemplo
Si el valor más grande es \(455\) y el valor más pequeño es \(-834\),
entonces
\(max(|v'(i)|)=0.834\)
está dentro del rango \([-1,1]\), por lo tanto \(k=3\)
Preparación de los datos
Normalización min-max
Objetivo
Mantener los valores dentro del rango \([{0,1}]\) mediante la el mínimo y el máximo
Método
\(v'(i)=\frac{v(i)-min(v(i))}{max(v(i))-min(v(i))}\),
donde \(v(i)\) es el valor \(i\)-ésimo de la variable \(v\), y \(v'(i)\) es el valor escalado
Ejemplo
Si el valor más grande es \(455\) y el valor más pequeño es \(-834\),
entonces
\(max(|0|)=0.647\)
está dentro del rango \([0,1]\)
Preparación de los datos
Datos faltantes
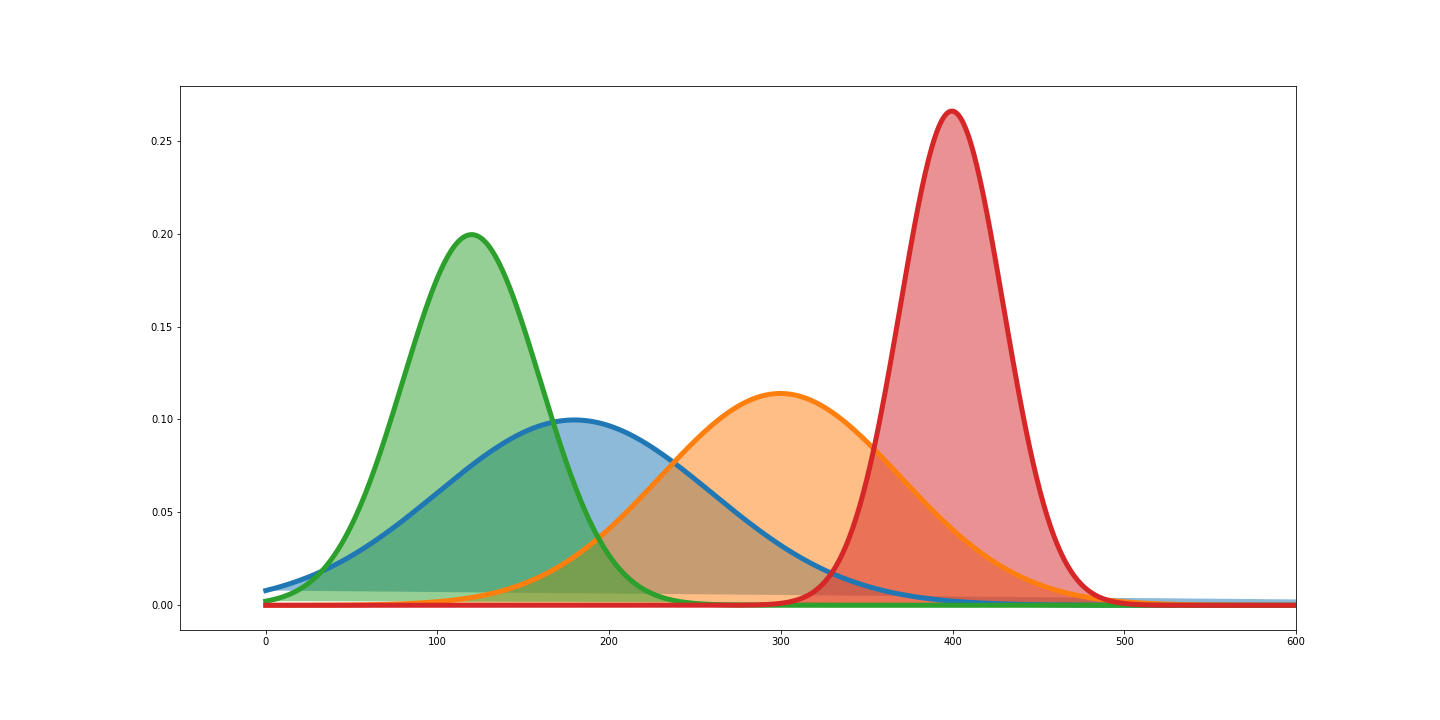
Métodos estadísticos
Métodos computacionales
Preparación de los datos
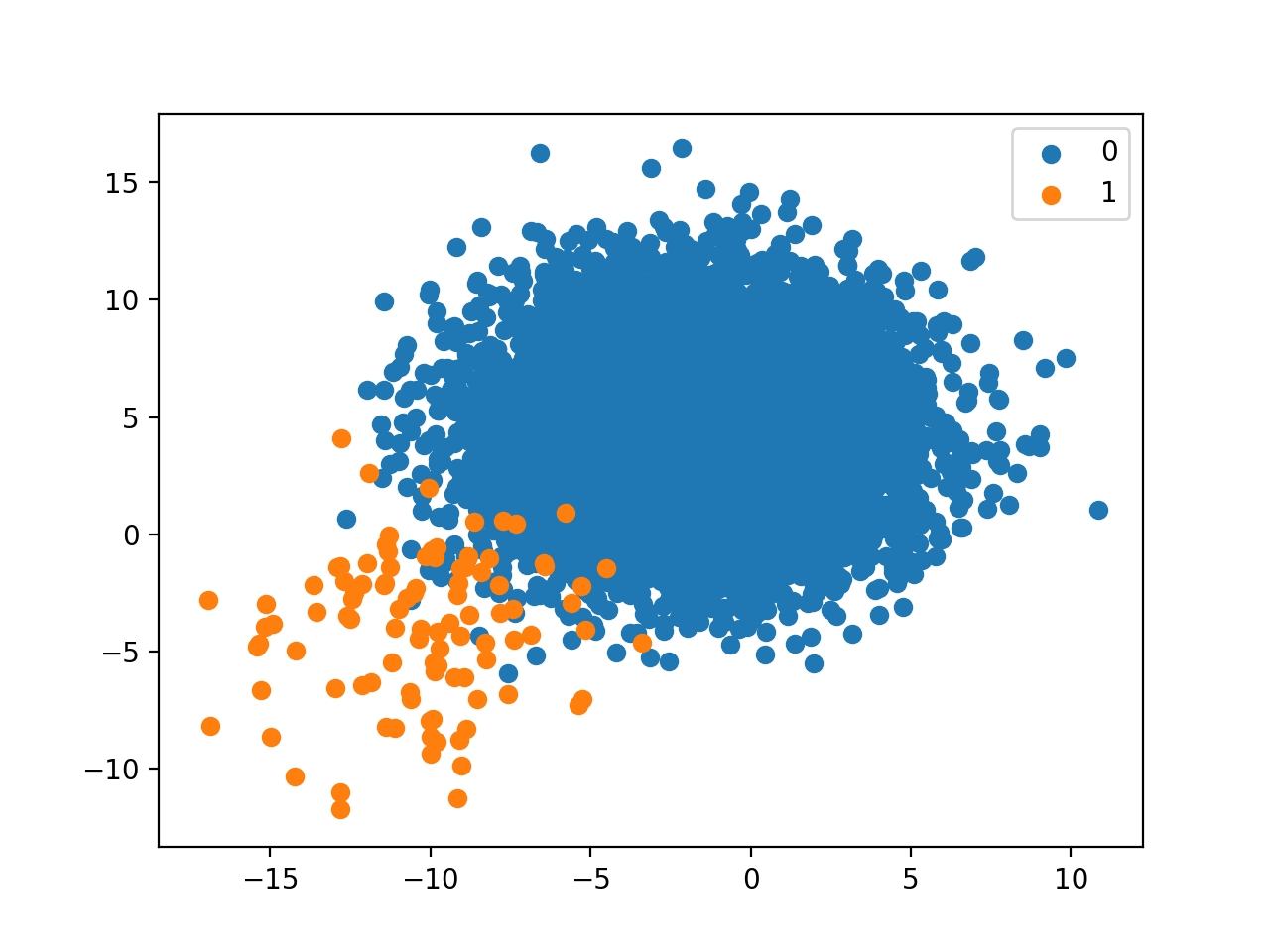
Análisis de datos anómalos (outliers)
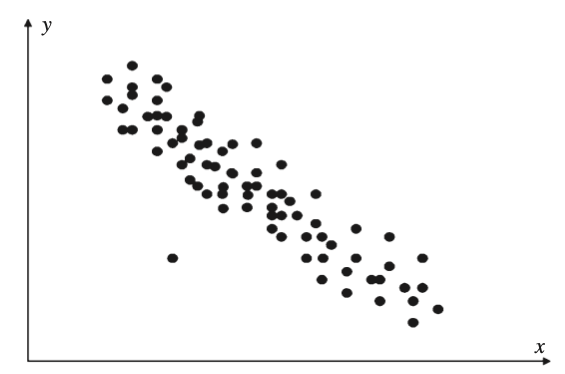
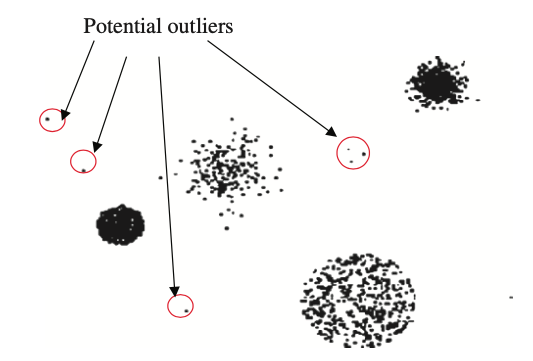
The rule of thumb
Preparación de los datos
Reducción de datos
Reducción de características
Reducción de datos
Características "relevantes"

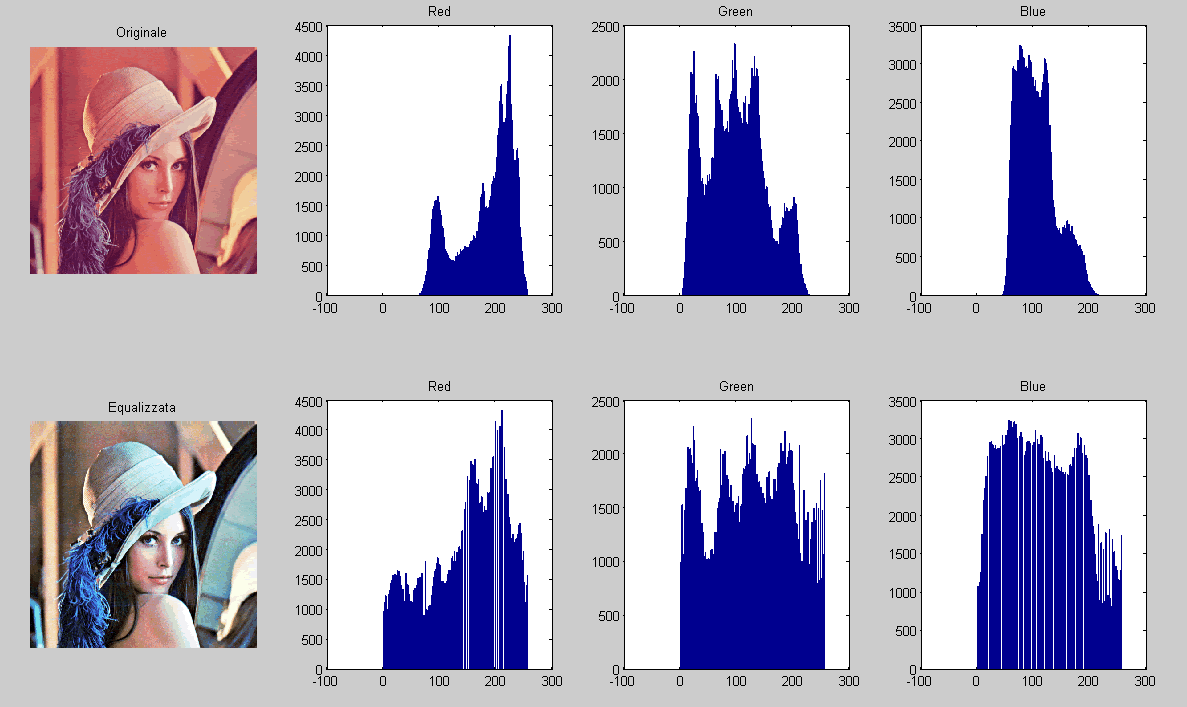

Reducción de datos
Máximo desempeño con la mínima cantidad de datos
Utopía (aún)
- menos datos
- aprendizaje más rápido
- mayor precisión
- mejor generalización
- mejor interpretación
(humana)
- características redundantes o irrelevantes
Reducción de datos
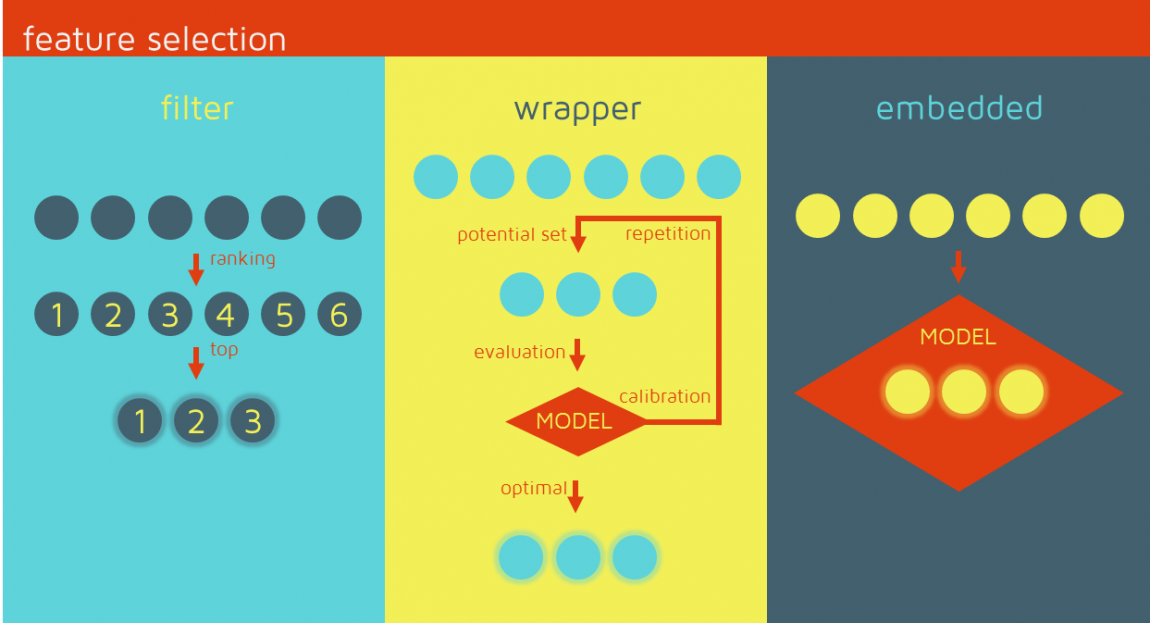
Selección de características
- Basado en el conocimiento previo
- Manual o automático
- 3 frameworks:
- filter model
- wrapper model
- embedded methods
Extracción de características
- Basado en la transformación de los datos
- La (de)composición de características tiene un impacto distinto en el resultado respecto al conjunto de datos original
Diferencias
- Selección de características: cuando se desea determinar las características más importantes
- Extracción de características: cuando se desea reducir la dimensionalidad del problema. (todas las características son necesarias para hacer la transformación)
Resumen de la Unidad
- La preparación de los datos y sus elementos
- Cómo funciona y para qué sirve la transformación y reducción de los datos
- Datos faltantes y la detección de anomalías
- Métodos para reducir datos y características
Técnicas de minería de datos
Plan del día
-
Entender la formalización y la teoría del aprendizaje automático
- STL
- Tipos de aprendizaje automático
- Tareas de aprendizaje automático
Recordando el proceso KDD
Aprendizaje de los datos
Enfoque: crar un modelo a partir de datos
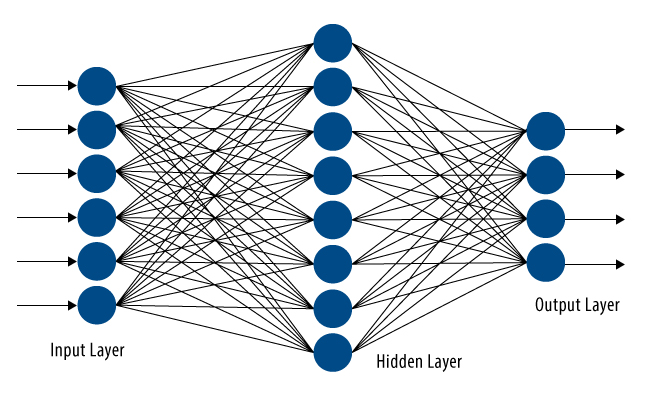
Los sistemas biológicos aprenden a enfrentar a la naturaleza desconocida del entorno de una manera basada en los datos.



Aprendizaje de los datos
Enfoque: crar un modelo a partir de datos
El problema de aprender de los datos y generar una noción de inferencia es filosofía clásica
Proceso de aprendizaje predictivo
1. Aprender o estimar dependencias desconocidas de un sistema dado un conjunto de datos
2. Usar estas dependencias para predecir nuevas salidas dadas nuevas entradas en el sistema

Aprendizaje de los datos
Enfoque: crar un modelo a partir de datos
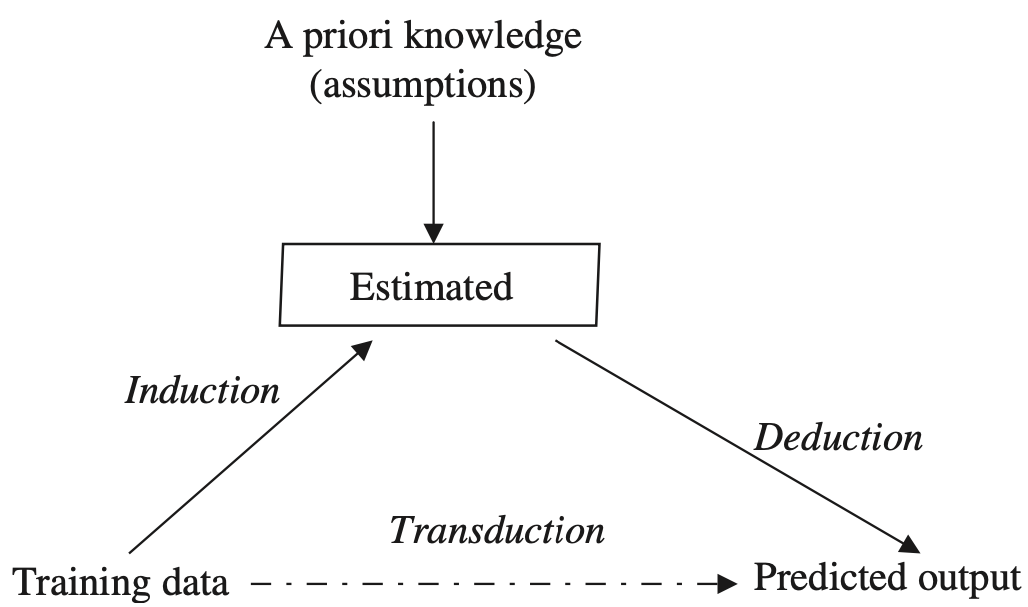
Inducción
De lo particular (entrenamiento) a lo general (modelo)
Deducción
De lo general (modelo) a lo particular (test)


Aprendizaje de los datos
El proceso del aprendizaje inductivo
Un método de aprendizaje
Estima una relación desconocida entre las entradas y salidas de un sistema a partir del conjunto de datos
Una vez que dicha relación desconocida ha sido estimada con precisión, puede ser utilizada para predecir futuros resultados del sistema a partir de nuevos los valores de entrada.
(algoritmo)
(dependencias)
Máquinas de aprender
Aprendizaje automático aprendizaje de máquina
Aprender buscando en el espacio \(n\)-dimensional de un conjunto de datos dado para encontrar una generalización aceptable
Estimar una dependencia (o estructura de entrada y salida) desconocida de un sistema utilizando un número limitado de observaciones (o mediciones de entradas y salidas del sistema)
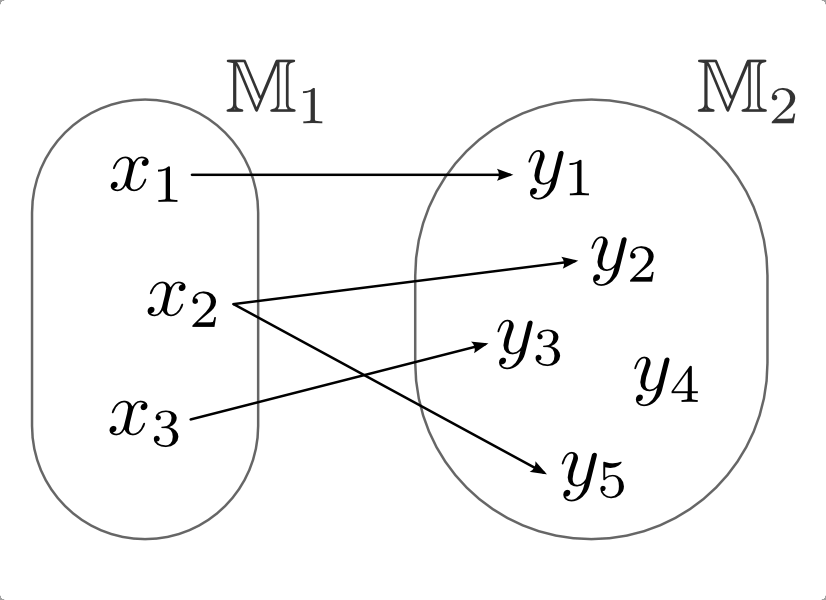
Máquinas de aprender
Aprendizaje automático
- Un generador de vectores de entrada \(X\),
- Un sistema que devuelve una salida \(Y\) para un determinado vector de entrada \(X\)
- Una máquina de aprendizaje, que estima las relaciones desconocidas (entrada X - salida Y') del sistema a partir de las muestras observadas (entrada X - salida Y)
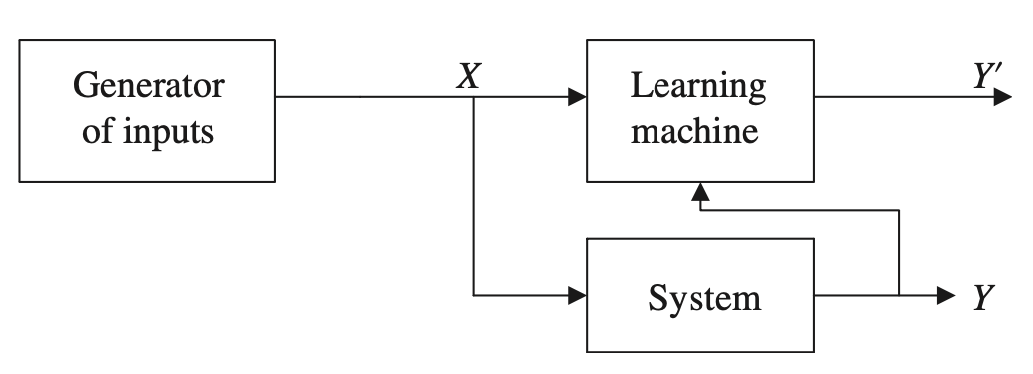
Ej. \(p(Y|X)\) o \(Y=f(x)\)
Máquinas de aprender
Aprendizaje automático
Una máquina de aprendizaje inductivo trata de formar generalizaciones a partir de hechos reales

Máquinas de aprender
Aprendizaje automático
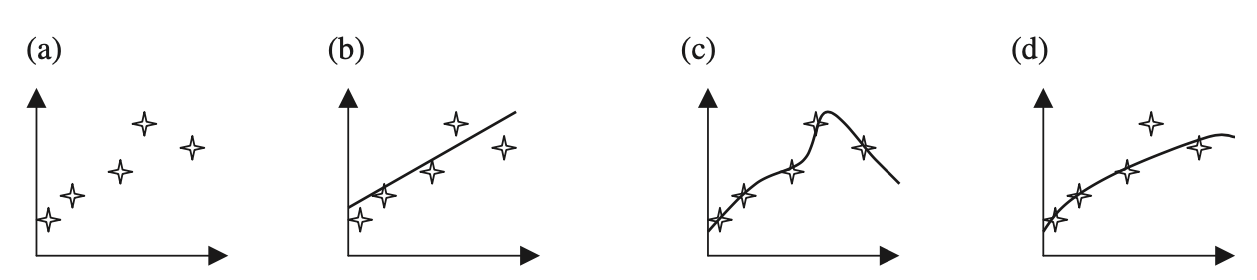
a. Observaciones (conjunto de datos)
b. Aproximación lineal
c. Aproximación polinomial (no lineal)
d. Aproximación cuadrática
Máquinas de aprender
Riesgo (risk): Proceso, relacionado con un riesgo, para minimizar lo negativo y maximizar las consecuencias positivas y sus respectivas probabilidades.
Intercambio (Trade-off): sacrificio, compensación, trueque, solución.


Conceptos básicos para adentrar en la SLT
Máquinas de aprender
Conceptos básicos para adentrar en la SLT
Función de pérdida (loss function): una función que relaciona un evento (objeto vectorial) con un número real que representa el coste asociado con el evento.
Funcional (functional): una función cuyo dominio es un conjunto de funciones
Teoría del aprendizaje estadístico
Statistical Learning Theory (SLT) o VC Theory

Aprendizaje inductivo de muestras finitas a.k.a. teoría de Vapnik-Chervonenkis (VC) vía estimación estadística ~60s
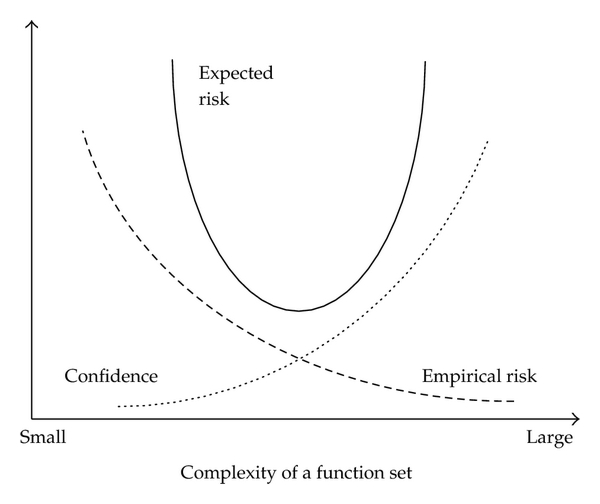
Dado un conjunto finito de muestras, proporciona una descripción cuantitativa del intercambio (trade-off) entre la complejidad del modelo y la información disponible
Reconocimiento de patrones y problemas de clasificación
Teoría del aprendizaje estadístico
SLT o VCT o Aprendizaje inductivo
Aprendizaje inductivo
Estimación óptima
Mínimo riesgo esperado
Riesgo verdadero
Riesgo empírico
funcionales
Riesgo verdadero
Teoría del aprendizaje estadístico
SLT o VCT o Aprendizaje inductivo
Aprendizaje inductivo
Objetivo
Estimar dependencias desconocidas dado un conjunto de funciones de aproximación usando información disponible (datos)
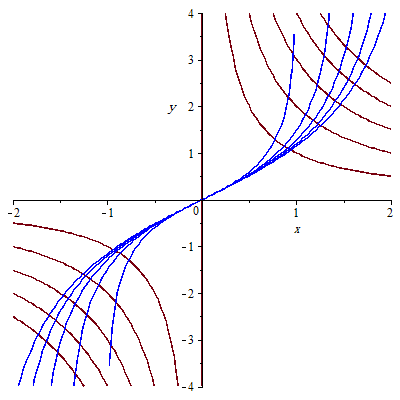
Teoría del aprendizaje estadístico
SLT o VCT o Aprendizaje inductivo
Estimación óptima
Definición
Corresponde al riesgo mínimo esperado (funcional). Esta distribución es desconocida, y la única información disponible sobre la distribución es un conjunto de datos finito.
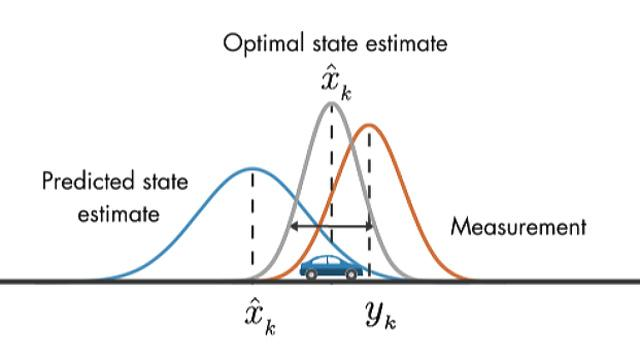
Teoría del aprendizaje estadístico
Empirical risk minimization (ERM)
Riesgo verdadero
Riesgo empírico

Distribución general de los datos
Distribución desconocida de los datos
Teoría del aprendizaje estadístico
Definición
Se busca encontrar una solución \(f(X, w^∗)\) que minimice el riesgo empírico expresado a través del error de entrenamiento como sustituto del riesgo verdadero desconocido, que es una medida del error verdadero en toda la población.
Empirical risk minimization (ERM)
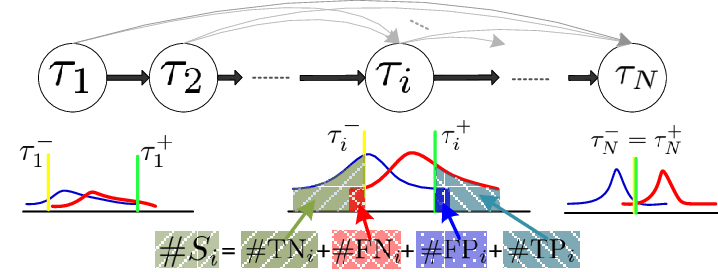
Teoría del aprendizaje estadístico
Definición
Requisito para que el modelo estimado converja con el modelo verdadero o la mejor estimación posible, a medida que el número de muestras de entrenamiento crece.
Consistencia asintótica
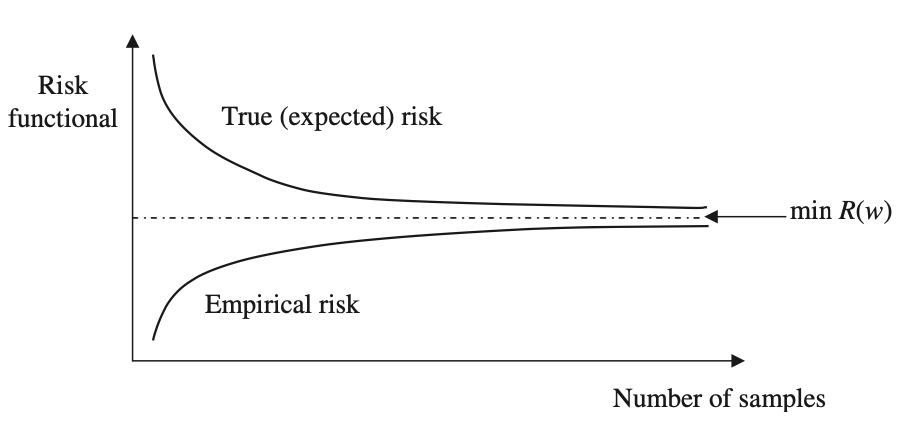
\( n \to ∞ \)
Teoría del aprendizaje estadístico
Definición
Para asegurar que la consistencia del método ERM sea siempre válida y no dependa de las propiedades de las funciones de aproximación, es necesario que el requisito de consistencia se mantenga para todas las funciones de aproximación
Consistencia no trivial
Teoría del aprendizaje estadístico
Definición
Cada función aproximada que está en la forma de la función de crecimiento \(G(n)\) tendrá una propiedad de consistencia y potencial para una buena generalización bajo aprendizaje inductivo, porque las funciones empíricas y de riesgo real convergen.
Función de crecimiento
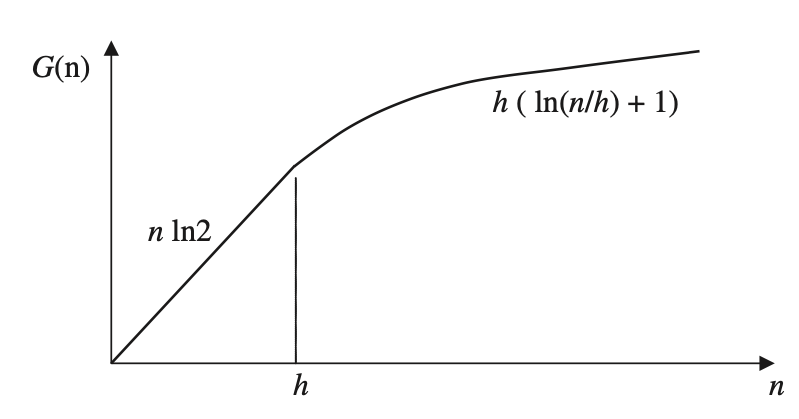
En \(n=h\) el crecimiento comienza a disminuir y garantiza entonces una convergencia
Teoría del aprendizaje estadístico
Definición
Mecanismo formal para elegir un modelo con una complejidad óptima en conjuntos de datos limitados y finitos ... la solución requiere la especificación a priori de una estructura en un conjunto de funciones aproximadamente iguales.
Minimización del riesgo estructural
El conjunto de funciones aproximadas \(S_1\) es el de menor complejidad y aumenta conforme \(k\)
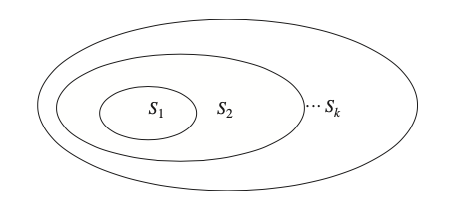
Teoría del aprendizaje estadístico
- calcular o estimar la dimensión de complejidad de la aproximación de las funciones (VC dimensions) para cualquier elemento \(Sk\) de la estructura
- minimizar el riesgo empírico para cada elemento de la estructura.
¿Cómo encontrar entonces las estimación óptima?
Elegir la estructura que produce el mínimo error garantizado, vinculado al riesgo verdadero.
Teoría del aprendizaje estadístico
¿Cómo encontrar entonces las estimación óptima?

Teoría del aprendizaje estadístico
¿Cuál estrategia de optimización elegir?
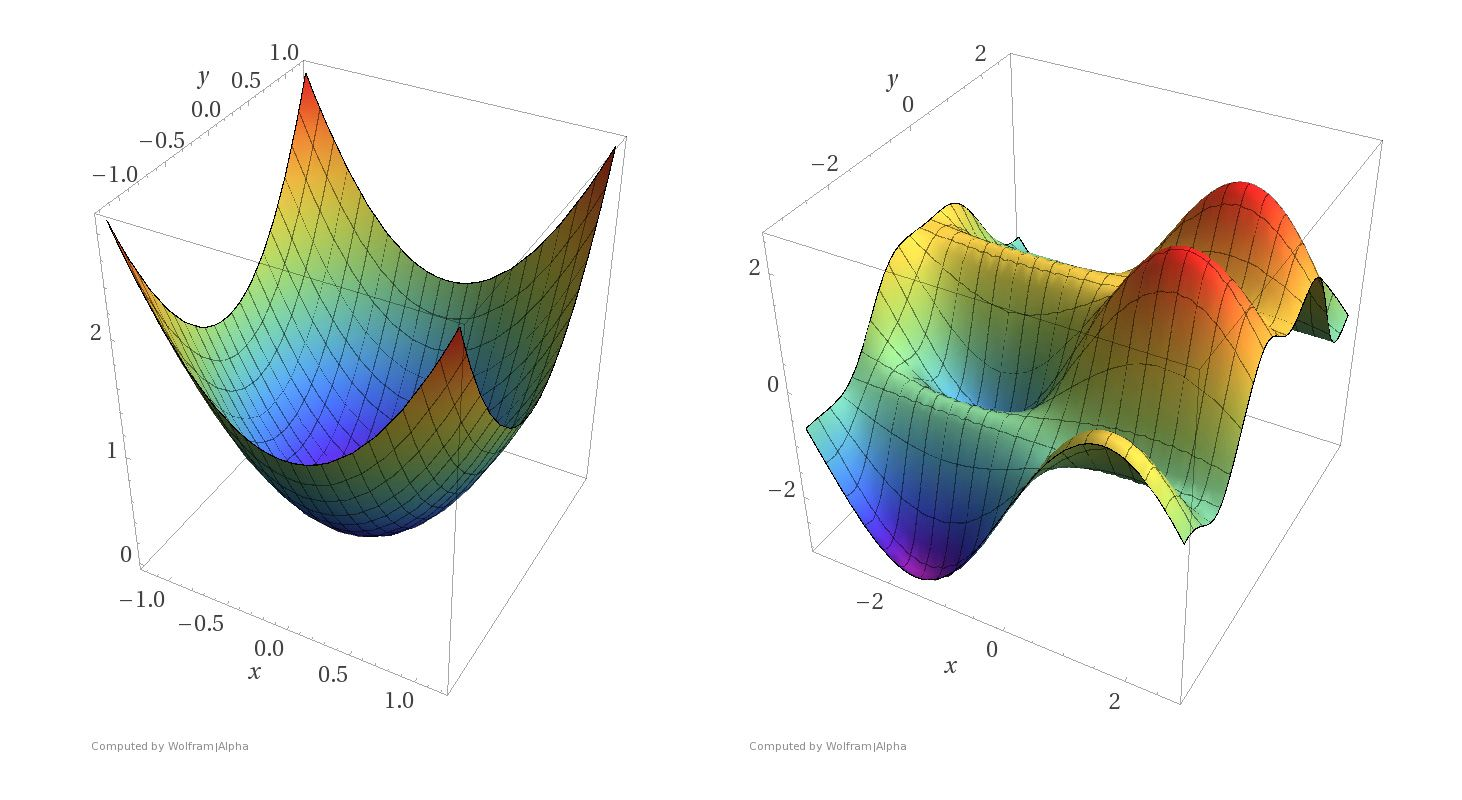
Aproximación estocástica o gradiente descendente
Dada una estimación inicial de los valores para las funciones de aproximación del parámetro \(w\) en términos de una función de riesgo, los valores óptimos del parámetro se encuentran actualizándolos repetidamente hasta encontrar el mínimo local/global.
Teoría del aprendizaje estadístico
¿Cuál estrategia de optimización elegir?
Métodos iterativos
Los valores del parámetro \(w\) se estiman de forma iterativa para que en cada iteración se reduzca el valor del riesgo empírico
Teoría del aprendizaje estadístico
¿Cuál estrategia de optimización elegir?
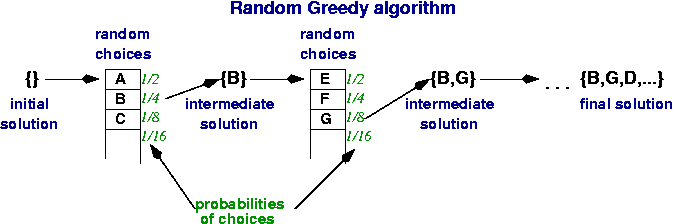
Optimización "voráz" (greedy)
Inicialmente, sólo se utiliza el primer término de las funciones de aproximación y se optimizan los parámetros correspondientes. La optimización corresponde a la minimización de las diferencias (error) entre el conjunto de datos de entrenamiento y el modelo estimado. Este término se mantiene fijo y el siguiente se optimiza.
Teoría del aprendizaje estadístico
Guía (rápida) para formar un modelo de estimación óptima a partir de datos finitos
- Un conjunto de funciones de aproximación \(f(X,w), \forall w \in W\)
- Conocimiento previo: datos y relaciones (patrón)
- Un método de inducción, o método de inferencia.
- Un método de aprendizaje, o algoritmo de aprendizaje.
Tipos de métodos de aprendizaje
Aprendizaje supervisado
Usado para estimar dependencias desconocidas de observaciones conocidas entrada-salida
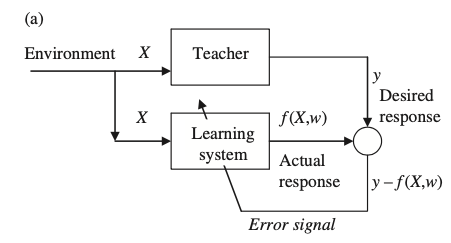
Se supone la existencia de un "maestro" que conoce el fenómeno y sus características
Los parámetros del sistema de aprendizaje se ajustan bajo la influencia combinada de las muestras de entrenamiento y la señal de error.
La señal de error es la diferencia entre la respuesta deseada y la respuesta real del sistema de aprendizaje.
Tipos de métodos de aprendizaje
Aprendizaje no supervisado
Descubrir la estructura "natural" de los datos de entrada
Se elimina la existencia de un "maestro" y se requiere que el método de aprendizaje forme y evalúe por sí mismo el modelo
Los parámetros del sistema de aprendizaje se ajustan con respecto a alguna medida de la calidad de la tarea.
El resultado puede ser una representación global aplicable a todo el dataset (clustering), o local, aplicado a un subconjunto del dataset (association rules).
Tipos de métodos de aprendizaje
Tareas comúnes de aprendizaje
Generar una "infraestructura" para el proceso de aprendizaje. Llamado también el Vector Space Model (VSM)
Una observación es un par características-clase, \(X-y\), que puede ser visualizada como un punto en un espacio n-dimensional, donde \(n\) es el número de atributos o dimensiones

Tipos de métodos de aprendizaje
Clasificación
Encontrar una función de aprendizaje que clasifica un elemento de datos en una de varias clases predefinidas
Para un espacio \(n\)-dimensional de muestras, la complejidad de la solución aumenta exponencialmente, y la función de clasificación se representa en forma de hiperplanos en el espacio dado.
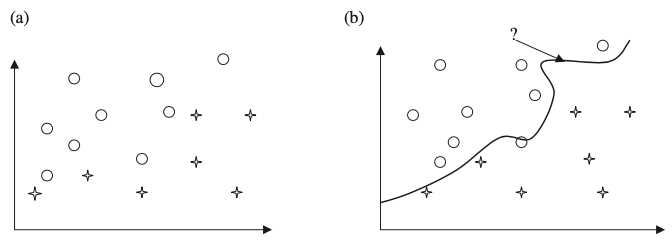
Tipos de métodos de aprendizaje
Regresión
Encontrar una función de aprendizaje, que asigna un elemento de datos a una variable de predicción de valor real
A partir de esta función, es posible estimar el valor de la variable de predicción \(y\) para cada nueva muestra
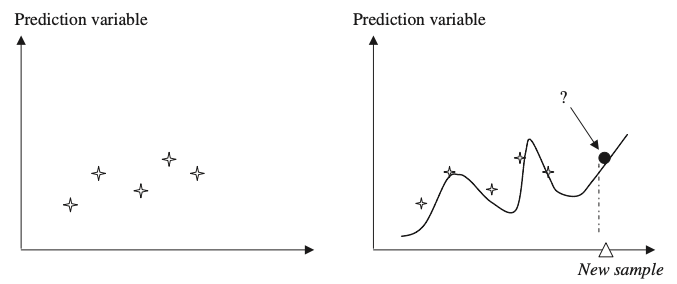
Tipos de métodos de aprendizaje
Sumarización
Encontrar una descripción compacta de un conjunto (o subconjunto) de datos
La información se puede simplificar y por lo tanto mejorar el proceso de toma de decisiones en un dominio determinado.

Tipos de métodos de aprendizaje
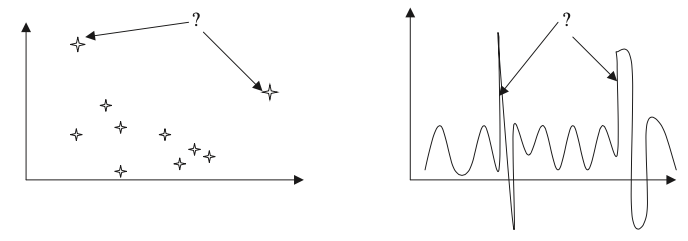
Detección de cambios y desviaciones (outliers)
Descubrir los cambios más significativos en un gran conjunto de datos
La detección de valores atípicos en un conjunto de datos con valores discretos de las características
Tipos de métodos de aprendizaje
Técnicas clásicas de descubrimiento del conocimiento
- Método estadísticos
- Inferencia Bayesiana, regresión logística, análisis de varianza (ANOVA), modelos lineales.
- Clustering
- Algoritmos divisibles y jerárquicos, particiones.
- Métodos computacionales
- Árboles de decisión, CLS, ID3, C4.5, prunning
- Reglas de asociación
- Apriori, WWW
- Redes neuronales artificiales y aprendizaje profundo
- Backpropagation, feedforward, redes recursivas, redes convolucionales
- Algoritmos de inteligencia evolutiva y de enjambre
- Colonia de abejas, manada de lobos, amiba
- Sistemas de inferencia difusos
- fuzzy c-means
Tipos de métodos de aprendizaje
Tarea 5
Clasificación
- k nearest neighbors
- Naïve Bayes
- Decision Trees
- Random Forest
- Ensemble methods
Regresión
6. Ordinary Least Square
7. Lasso y Ridge regression
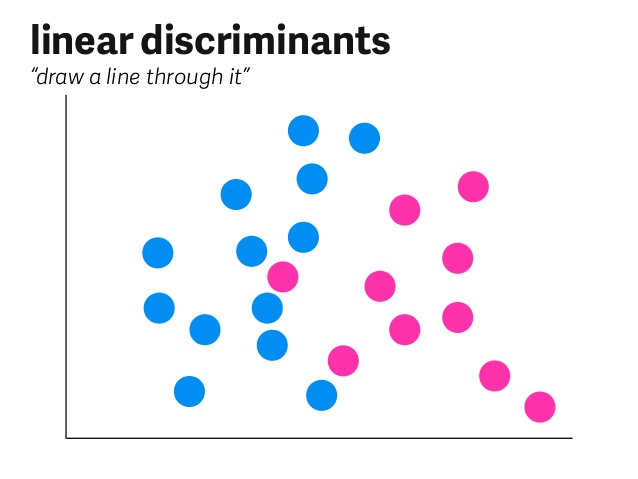
8. Linear and Quadratic Discriminant Analysis
Clustering
9. k-means, k-medoids y k-modes
10. Gaussian Mixture Models
11. DBSCAN
Evaluación del modelo
Recordando el proceso KDD
Compensación de sesgo y variación
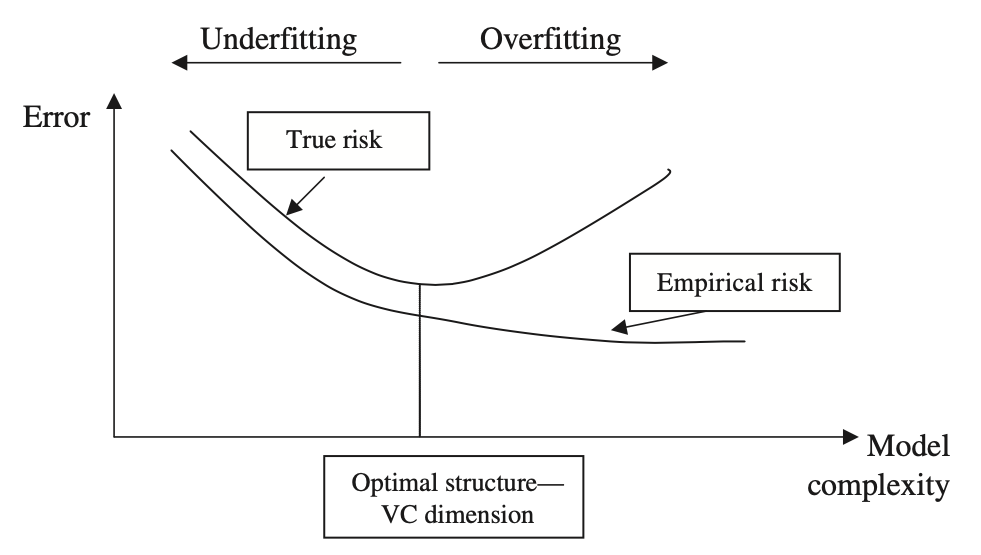
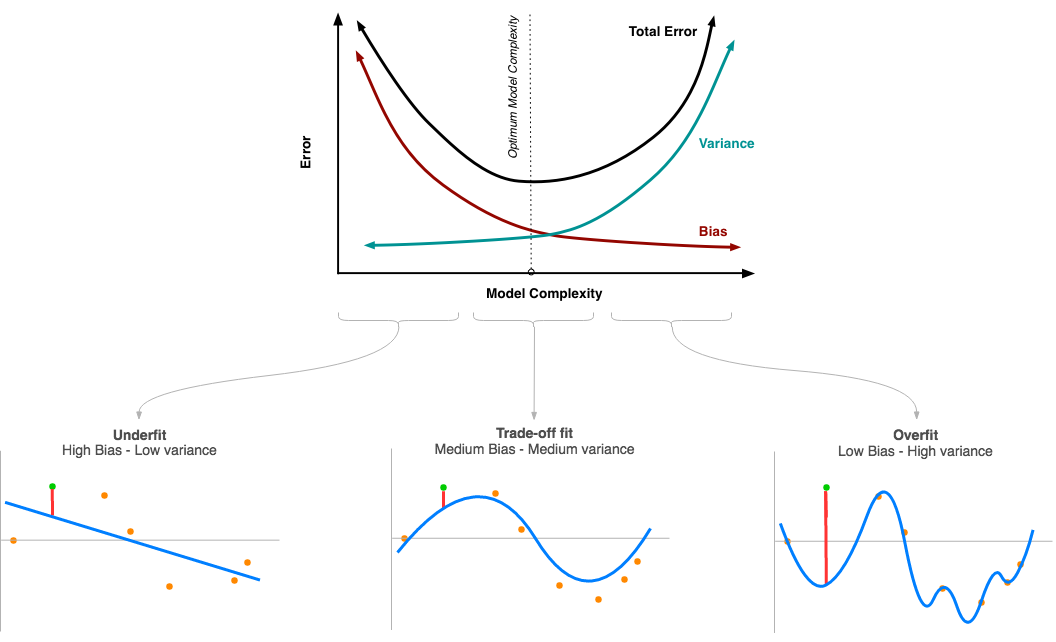
¿Cómo evaluar el desempeño de un modelo?
La compensación sesgo-varianza (bias-variance trade-off) es un comportamniento natural de estos modelos
Compensación de sesgo y variación
¿Qué es el sesgo?
Cuando un modelo de aprendizaje automático no logra aprender los patrones importantes (o a veces complejos) que se exhiben en los datos, decimos que el modelo está sesgado
Simplifica demasiado
Aprende reglas tan simples que no puede generalizar
Compensación de sesgo y variación
¿Qué es la varianza?
Cuando un modelo de aprendizaje automático aprende patrones innecesarios, de tal manera que incluso pequeñas variaciones en los datos producen cambios indeseables en la predicción
Aprende reglas muy exactas y tan complejas, que no puede generalizar
Compensación de sesgo y variación
Escenario ideal
Generar un modelo con bajo sesgo y baja varianza, es decir, un modelo que ha aprendido los patrones necesarios
Para lograr el equilibrio entre el sesgo y la varianza se utiliza una combinación de métodos de ajuste de hiperparámetros
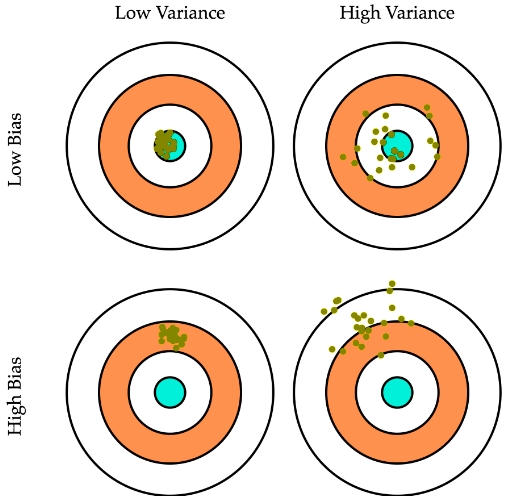
Compensación de sesgo y variación
Soluciones al sobreajuste y subajuste
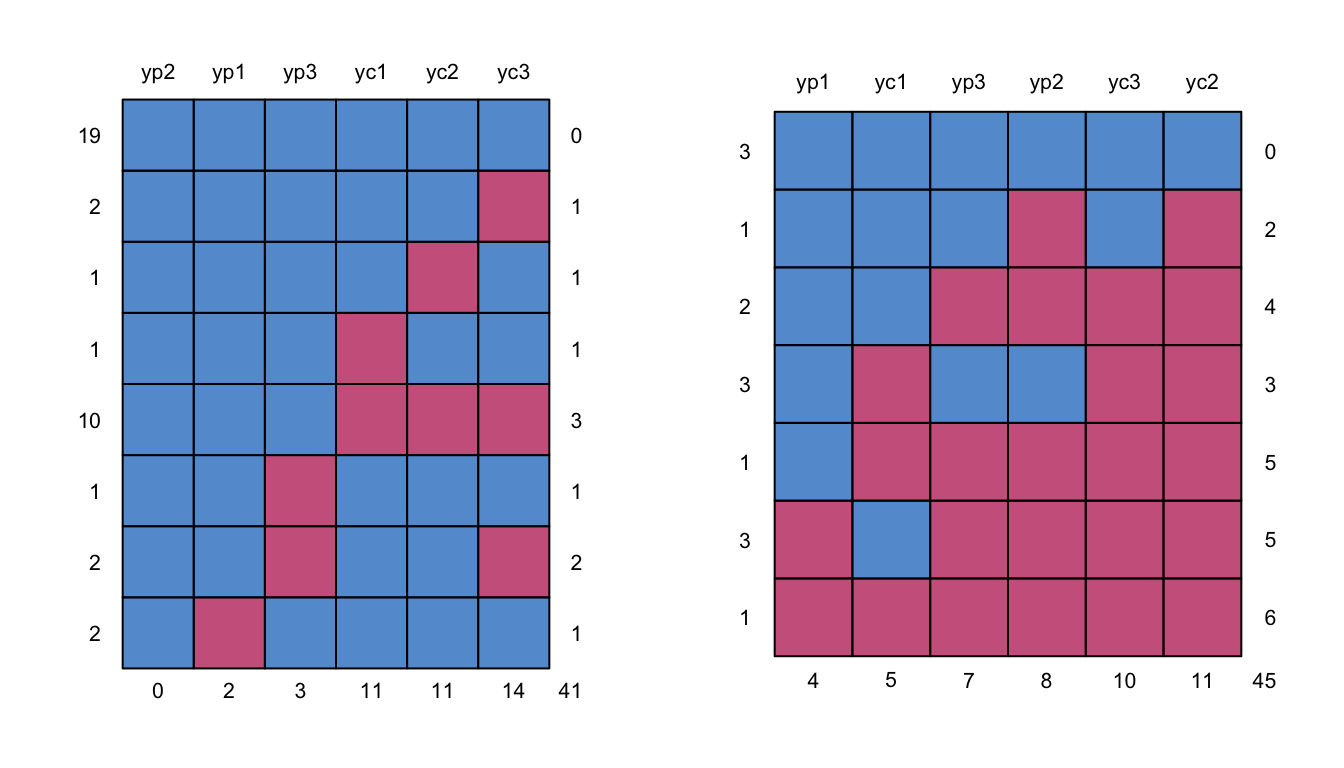
Validación cruzada: técnica de validación de modelos que ayuda a evaluar el rendimiento y la capacidad de un modelo de aprendizaje de la máquina para generalizar en un conjunto de datos independiente.
Evaluar la robustez del modelo en datos no vistos.
Estimar un rango realista para las métricas de rendimiento deseadas.
Mitigar el overfitting y el underfitting de los modelos.
Compensación de sesgo y variación
Validación cruzada
Probar el modelo en todo el conjunto de datos en varias iteraciones, dividiendo los datos en grupos y usando la mayoría para entrenar y la minoría para probar

Asegurar que el modelo ha sido probado en todas las observaciones disponibles
Compensación de sesgo y variación
¿Cómo saber si el modelo tiene sesgo alto?
Si la media de las métricas de rendimiento dice que:
- la precisión general (para la clasificación) o el porcentaje de error absoluto medio (para la regresión) es bajo, entonces hay un alto sesgo y el modelo es de bajo ajuste.
Compensación de sesgo y variación
Validación simple (Holdout Validation)

Dividimos aleatoriamente el conjunto de datos disponibles en conjuntos de datos de entrenamiento y pruebas. Las proporciones de división más comunes utilizadas entre los conjuntos de datos de entrenamiento y de prueba son 70:30 u 80:20.
Compensación de sesgo y variación
Validación cruzada de retención (Leave-One-Out Validation)
En lugar de crear \(k\) particiones, elegimos el número de particiones como el número de puntos de datos disponibles. Por lo tanto, tendríamos sólo una muestra en una partición. Utilizamos todas las muestras excepto una para el entrenamiento, y probamos el modelo en la muestra que se ha mantenido y repetimos este número \(n\) de veces, donde \(k\) es el número de muestras de entrenamiento.
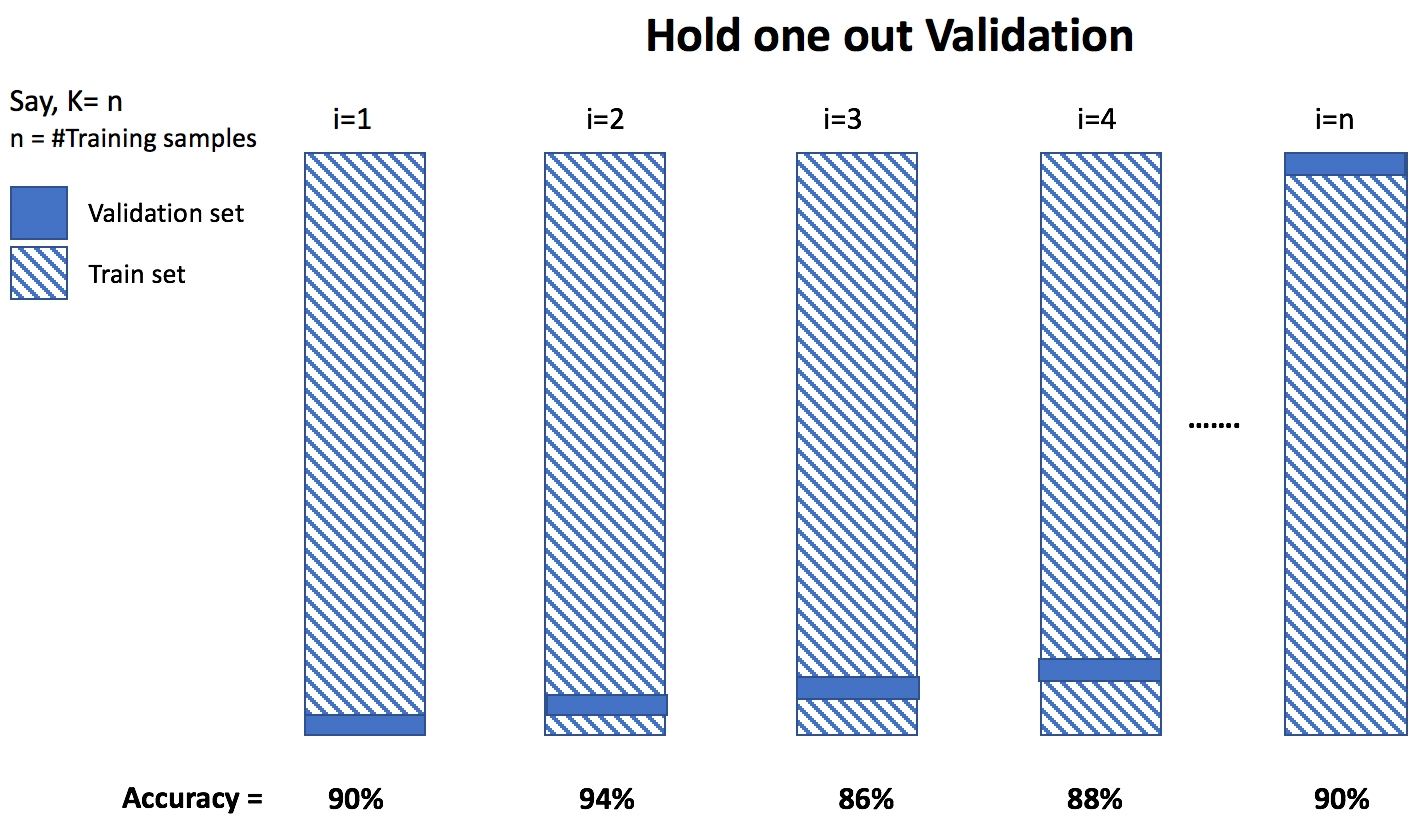

Optimización de hiperparámetros
¿Qué son los hiperparámetros de un modelo?
Un hiperparámetro es un parámetro que define las características de un modelo de aprendizaje automático.
Los hiperparámetros son diferentes de los parámetros del modelo; estos no pueden ser aprendidos por el modelo.
Los parámetros del modelo son aprendidos por el modelo durante el proceso de aprendizaje
(\(w_1, w_2, ...\))
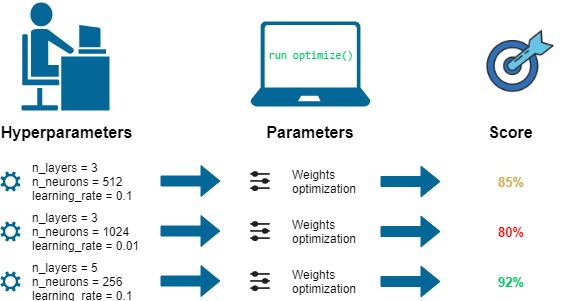
Optimización de hiperparámetros
El proceso de optimización o ajuste de los hiperparámetros se puede resumir como:
el proceso iterativo de encontrar el conjunto óptimo de valores para los hiperparámetros que resulta en el mejor modelo de aprendizaje de la máquina para nuestra tarea de predicción.
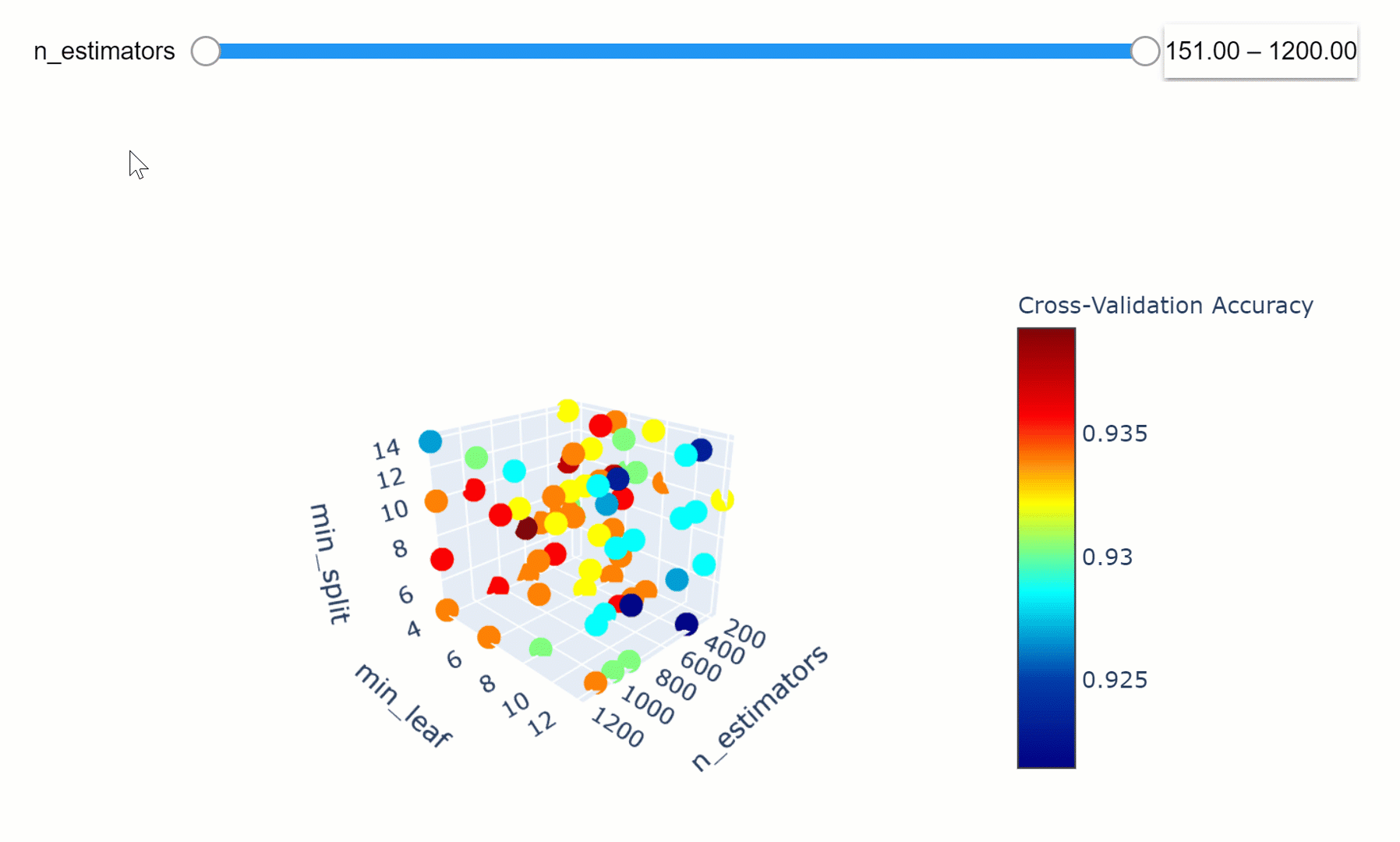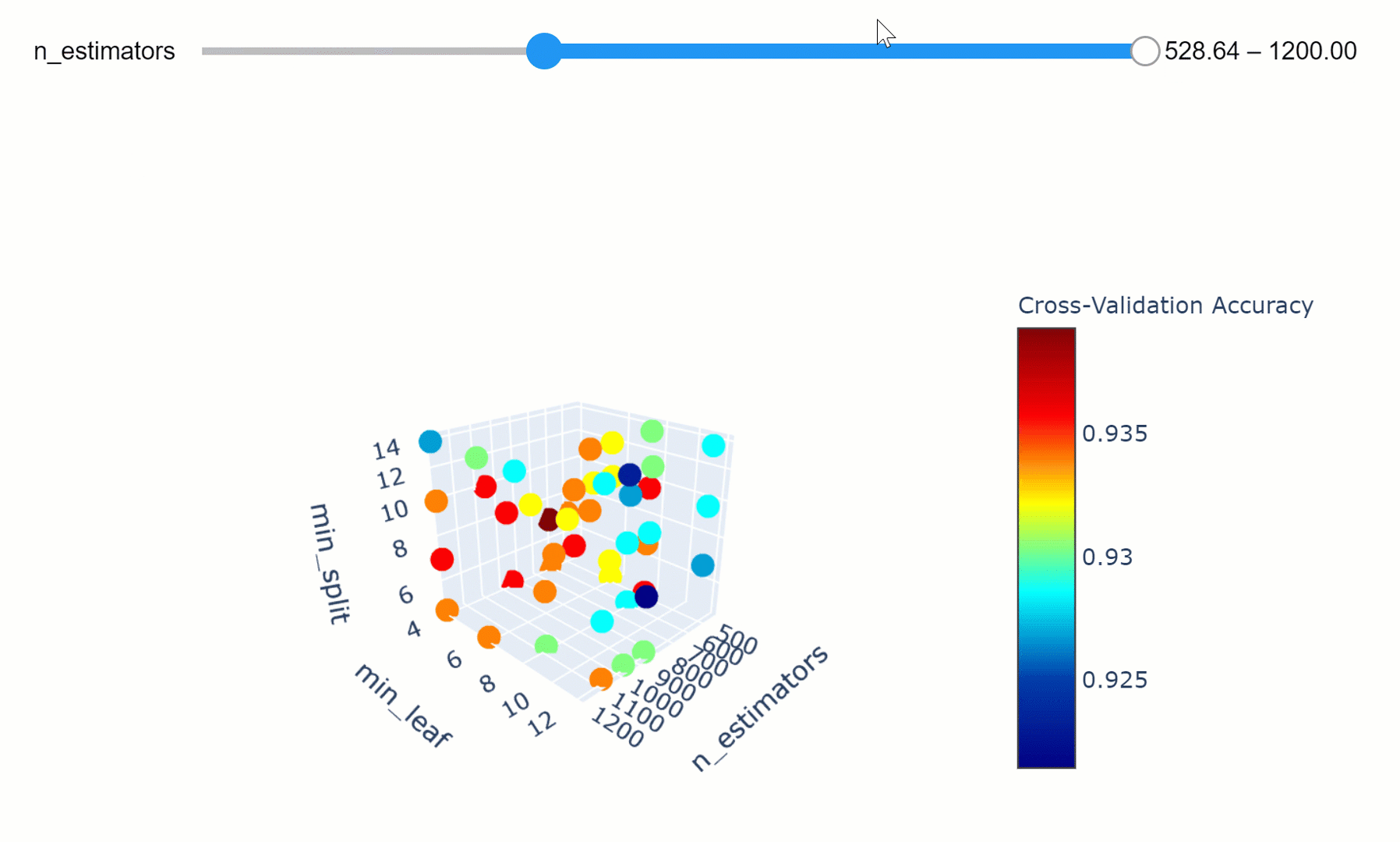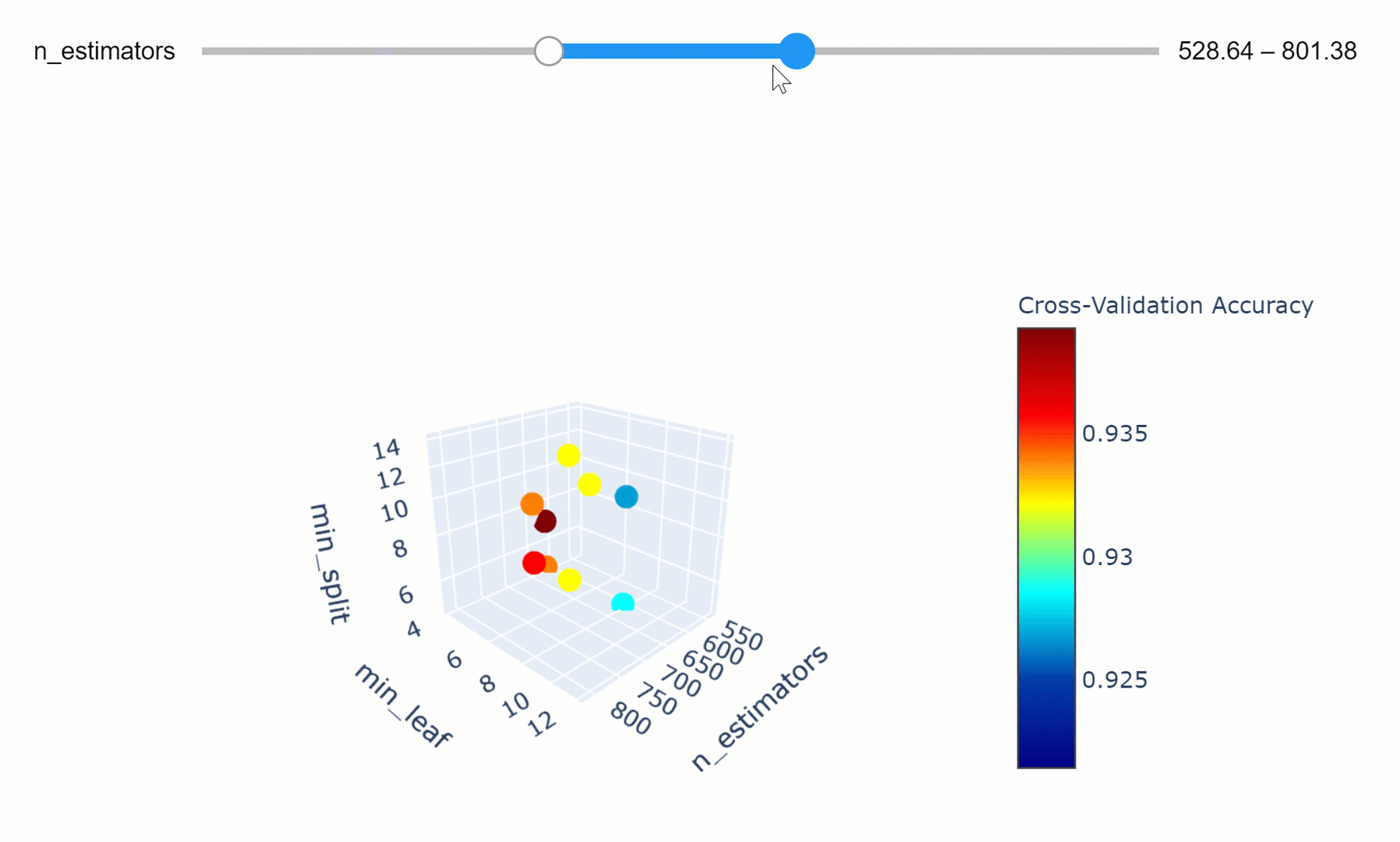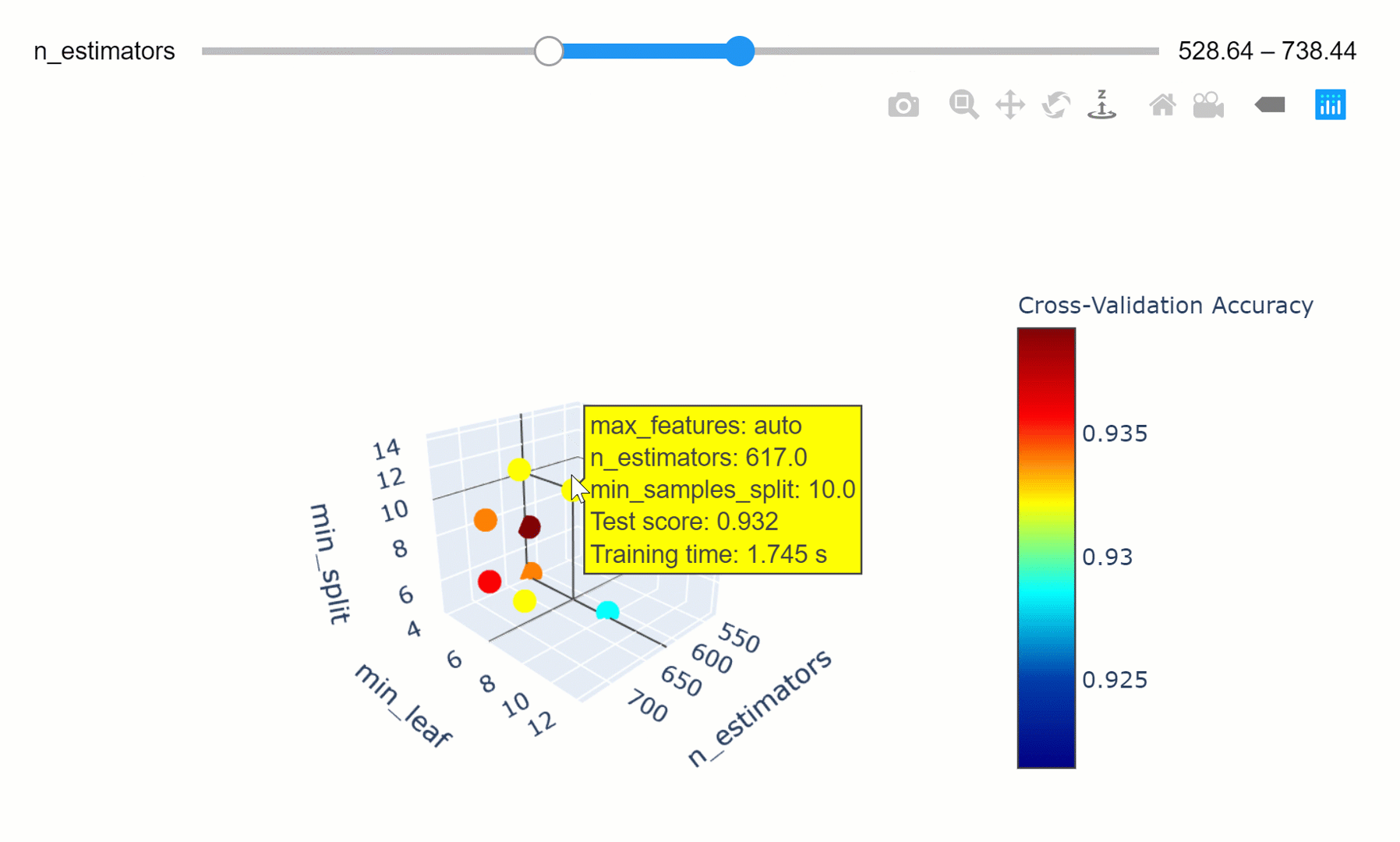
Optimización de hiperparámetros
Definimos un conjunto finito de valores para cada hiperparámetro que nos interesaría optimizar para el modelo. El modelo es entonces entrenado para combinaciones exhaustivas de todos los valores de hiperparámetros posibles y la combinación con el mejor rendimiento es seleccionada como el conjunto óptimo.

Grid-search optimization
Optimización de hiperparámetros
Aquí, optamos por elecciones aleatorias de una distribución (en el caso de un valor continuo para los hiperparámetros), en lugar de una lista estática que definiríamos. En la optimización de búsqueda aleatoria, tenemos una gama más amplia de opciones de búsqueda, ya que los valores continuos de un hiperparámetro se eligen aleatoriamente de una distribución
Random search optimization
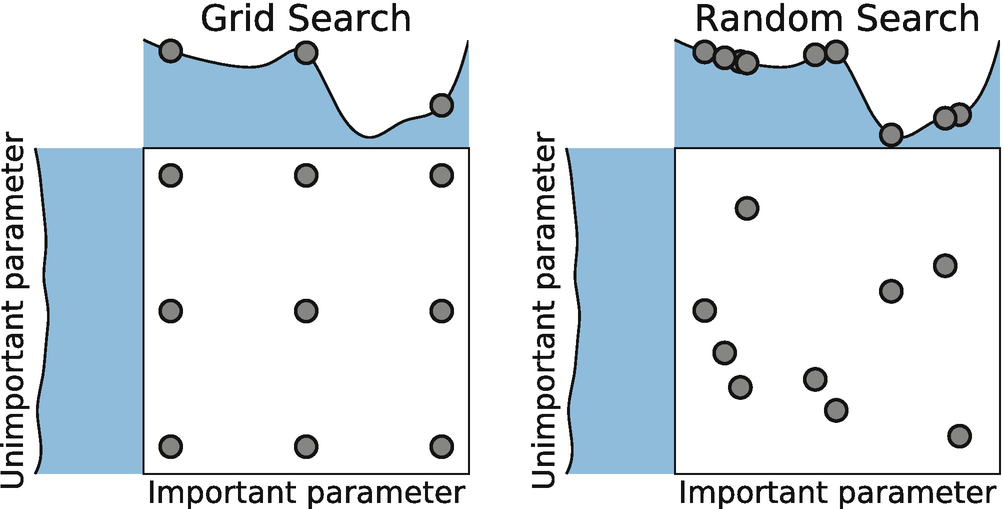
Prácticas


References



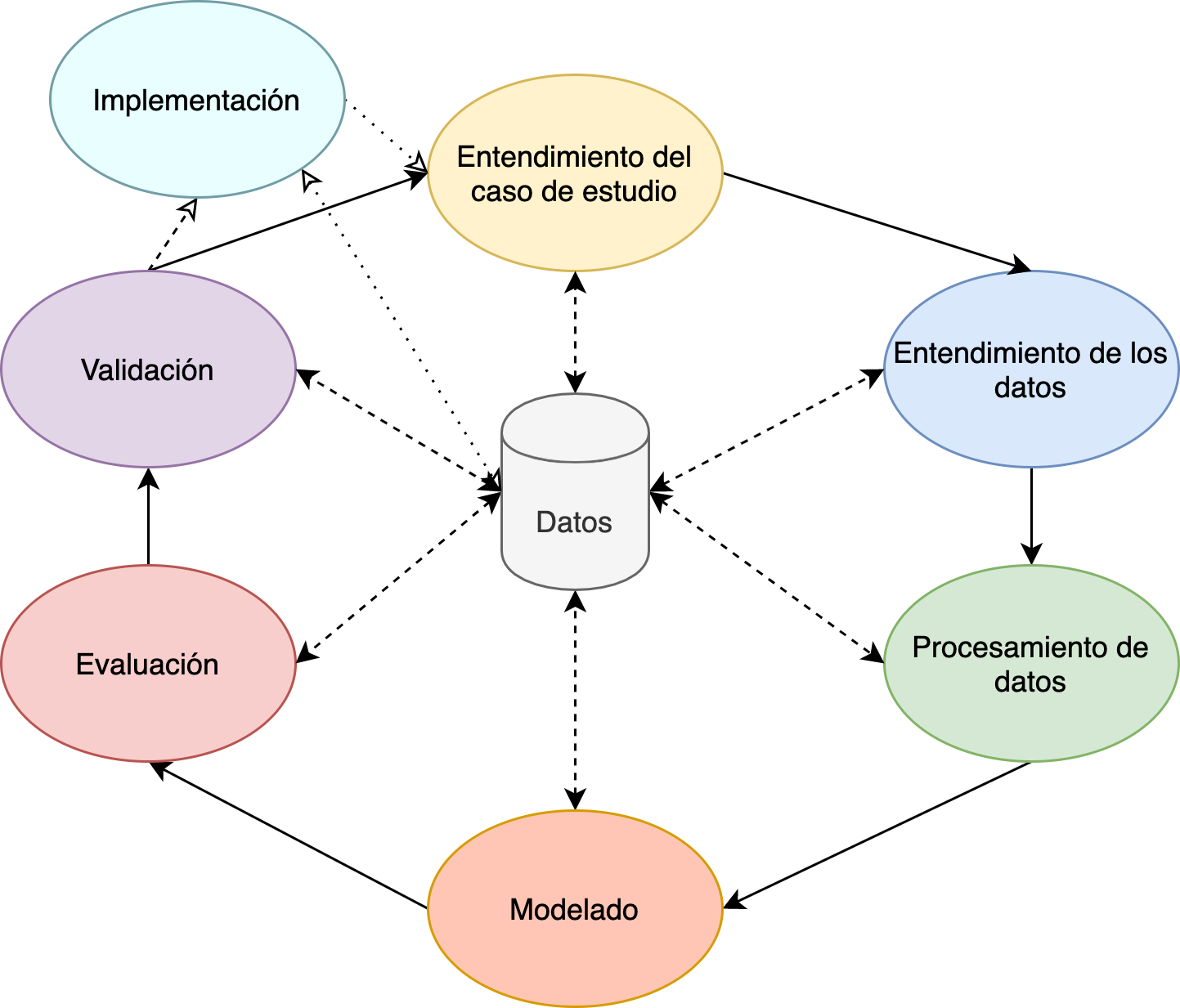
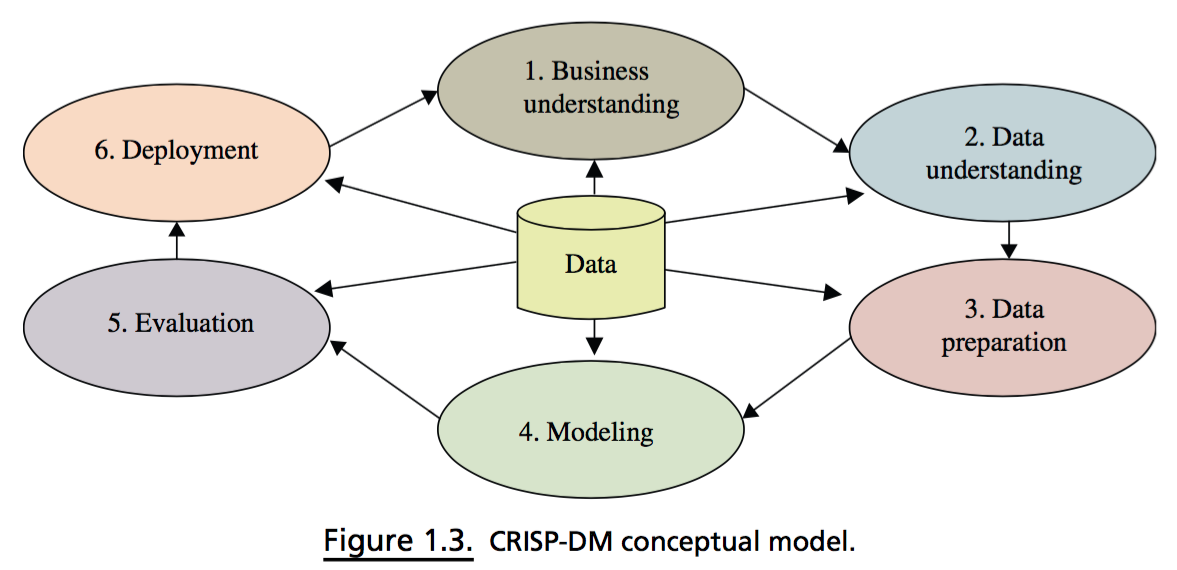
Uso de la metodología CRISP-DM:
- Data collection
- Data exploration
- a.k.a wrangling, munging
- Data viz







Temas extras














Referencias
Kantardzic, M.: Data Mining: Concepts, Models, Methods, and Algorithms. Wiley-IEEE Press, 3rd Edition, (2020)


Han, J., Kamner, M. Hei, J.: Data Mining: Concepts and Techniques. Morgan Kaufmann Publishers; 3rd ed, (2012)