A Domain-Specific Supercomputer for Training Deep Neural Networks
Recap: TPU v1
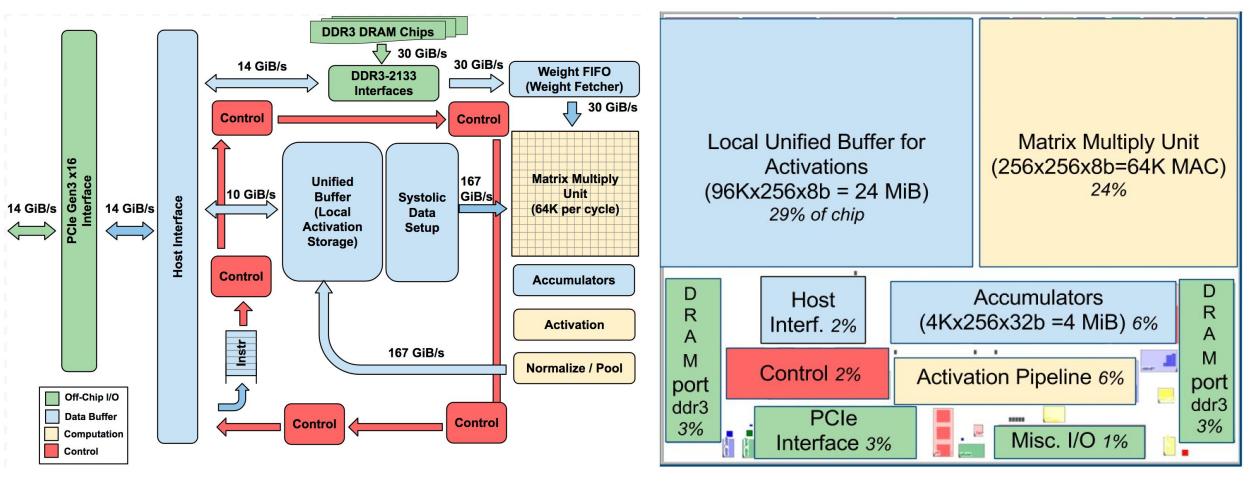
Recap: TPU v1
Motivation
- 2013 - TPU v1 development starts
- 15 months later, TPU v1 was deployed in datacenters
- 2014 - What next?
- Improve TPU v1 and build better inference chip
- Attack the more harder training problem
- SOTA training in 2014: Worker nodes and parameter servers, update parameters synchronously
DSA supercomputer vs cluster
we chose to build a DSA supercomputer instead of clustering CPU hosts with DSA chips.
- Training time is huge. TPUv2 chip would take two to 16 months to train a single Google production application, so a typical application might want to use hundreds of chips.
- DNN wisdom: bigger datasets plus bigger machines lead to bigger breakthroughs. Moreover, results like AutoML use 50x more computation.
Diff b/w training & inference on TPU
- Harder parallelization: Training needs synchronization to update weights
- More computation - calculating gradients, etc.
- More memory - need to store intermediate values of forward and back prop for gradient calculation, 10x higher
- More programmability - Should be able to adapt to newer algorithms
- Wider data: 8-bit int sufficient for inference, training needs higher precision fp data
Critical feature: Communication
Text