CS6886
Assignment 2
Pitfalls in Problem Statement
- Padding - constant time, doesn't affect result much
- Absence of scatter-gather instructions in AVX
Fallacies in the submissions
- Folder Structure (seriously?)
- Functions implemented without using AVX
- Constructing vector operand from individual operands
- Estimating operational intensity as a macro property
2D convolution
for i = 1 to N
for j = 1 to M
for k = 1 to E
for l = 1 to F
out = vector_init(0)
for c = 1 to C
for r = 1 to R
for s = 1 to S, s=s+8
inp = vector_load(input[i][c][k+r][l+s], 8)
wgt = vector_load(weight[j][c][r][s])
inp = vector_mul(inp, wgt)
out = vector_add(out, inp)
output[i][j][k][l] = vector_reduce(out)
Memory accessed = (C * R * S * 2 + 8) x 4 bytes
Compute performed = C * R * S * 2
Operational Intensity= \(\frac{C*R*S*2}{(C * R * S * 2 + 8) * 4}\)
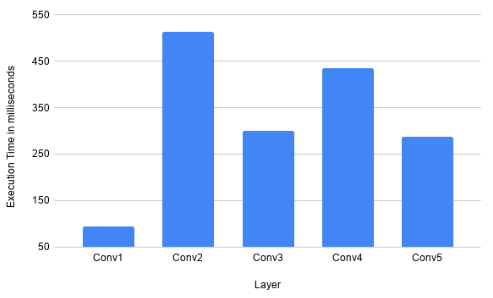
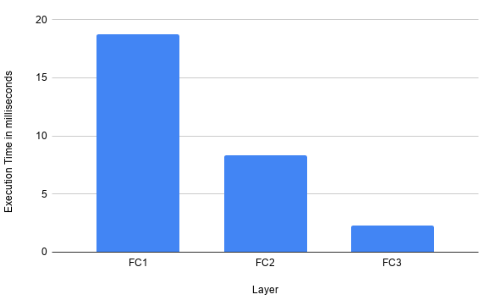
Layerwise execution time
Input Stationary
for i = 1 to N
for c = 1 to C
for k = 1 to E
for l = 1 to F
inp = vector_load(input[i][c][k][l])
for j = 1 to M
for r = 1 to R
for s = 1 to S, s=s+8
wgt = vector_load(weight[j][c][r][s])
inp = vector_mul(inp, wgt)
out = vector_add(out, inp)
output[i][j][k][l] += vector_reduce(out)Weight Stationary
for j = 1 to M
for c = 1 to C
for r = 1 to R
for s = 1 to S, s=s+8
wgt = vector_load(weight[j][c][r][s])
for i = 1 to N
for k = 1 to E
for l = 1 to F
inp = vector_load(inp[i][c][k][l])
inp = vector_mul(inp, wgt)
out = vector_add(out, inp)
output[i][j][k][l] += vector_reduce(out)Output Stationary
for i = 1 to N
for j = 1 to M
for k = 1 to E
for l = 1 to F
out = vector_init(0)
for c = 1 to C
for r = 1 to R
for s = 1 to S, s=s+8
inp = vector_load(input[i][c][k+r][l+s], 8)
wgt = vector_load(weight[j][c][r][s])
inp = vector_mul(inp, wgt)
out = vector_add(out, inp)
output[i][j][k][l] = vector_reduce(out)
Choice between DATAFLOWS
- Data Reuse pattern
- IS \( \approx \) WS < OS
- Depends more on the implementation
- Tiling for layer 2
- 9 x 9 tiles
- Memory layout
- NHWC
- MRSC
ReLU
for i = 1 to N
for c = 1 to C
for k = 1 to H
for l = 1 to W, l=l+8
inp = vector_load(input[i][j][k][l])
zero = vector_init(0)
mask = vector_cmp(inp, zero, CMP_GT)
inp = vector_and(inp, mas)
vector_store(inp, input[i][j][k][l])2D MaxPool
for i = 1 to N
for j = 1 to C
for k = 1 to E
for l = 1 to F
out = vector_init(FLOAT_MIN)
for r = 1 to R
for s = 1 to S, s=s+8
inp = vector_load(input[i][c][k+r][l+s], 8)
inp = vector_mul(inp, wgt)
out = vector_add(out, inp)
output[i][j][k][l] = vector_reduce(out)