Meta-learning Spiking Neural Networks with Surrogate Gradient Descent
Research salon
Kenneth Stewart, Emre Neftci
https://arxiv.org/abs/2201.10777
What is meta learning?
-
Deep learning works well when we have lots of data available
- What to do when we have little data? -> use data from different tasks to learn how to learn and then learn new tasks more efficiently
- learn an optimizer, a model, a learning rule
- in practice closely related to multi-task learning
Why might meta learning be good idea?
- might have only little data available for a given task (e.g. medical image recognition), but much more available for related tasks (image classification)
- Collect a small amount of labeled data for specific task (fine-tuning)
- higher model prediction accuracy by optimizing hyperparameters
- generalized models: meta learning does not focus on training one model on one specific dataset
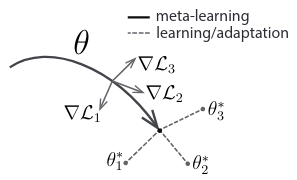
Model Agnostic Meta Learning (MAML)
- aim: train models that can achieve rapid adaptation
- maximizing the sensitivity of the loss functions of new
tasks with respect to the parameters: when the sensitivity
is high, small local changes to the parameters can lead to large improvements in the task loss.
Summary
- + easy to apply to any architecture or loss function
- - hard to optimize, sensitive to hyperparameters
- - requires second order derivative