seq2seq networks
hamish
seq2seq
- still building up to transformers
- last time talked about transfer learning
- this time about seq2seq models
- going to just talk about sequences in general today
- next time apply to an NLP problem
Sequence problems
"Here, have potato"
???
???
"fold" over this building up an understanding of patterns
"unfold" until some condition is met
Natural approach
Quick tour of RNNs
x_{0}
x_{3}
x_{2}
x_{1}
y_{0}
y_{3}
y_{2}
y_{1}
h_{0}
h_{4}
h_{3}
h_{2}
h_{1}
elements of sequence
neural network things
happen
memory
same weights
Quick tour of RNNs
y_{t} = \phi (W_{y}^{T} h_{t - 1} + b)
h_{t} = \phi ( W_{x}^T x_{t} + W_{h}^T h_{t - 1} + b )
x_{t}
h_{t - 1}
✨
can think of this as "memory"
sequence element
LSTM/GRU

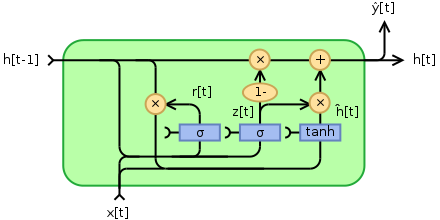
Long Short Term Memory (LSTM)
- has a longer term memory
- does a remember/forget computation
- really slow
Gated Recurrent Unit
- also has a memory
- handles remembering/forgetting differntly
- much faster, but still slow
x_{N - 2}
h_{N - 3}
x_{N}
x_{N - 1}
inputs
outputs
y_{0}
y_{3}
y_{2}
y_{1}
seq2seq
Encoder
Decoder
h_{N}
This thing is really useful
d_{0}
d_{1}
d_{2}
d_{3}
Show me the code
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(Encoder, self).__init__()
self.gru = nn.GRU(input_dim, hidden_dim)
def forward(self, x):
outputs, hidden = self.gru(x)
return outputs, hidden
class Decoder(nn.Module):
def __init__(self, output_dim, hidden_dim):
super(Decoder, self).__init__()
self.gru = nn.GRU(output_dim, hidden_dim)
self.out = nn.Linear(hidden_dim, output_dim)
def forward(self, x, hidden):
output, hidden = self.gru(x, hidden)
prediction = self.out(output[0])
return prediction, hidden
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, source, target_length, device):
input_length = source.size(0)
batch_size = target.shape[1]
# create something to hold the predicted outputs
outputs = torch.zeros(target_length, batch_size).to(self.device)
encoder_output, encoder_hidden = self.encoder(source)
#use the encoder’s hidden layer as the decoder hidden
decoder_hidden = encoder_hidden.to(device)
# we need an input here, in NLP we will typically use a special token
decoder_input = torch.tensor([0], device=device)
for t in range(target_length):
decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden)
outputs[t] = decoder_output
return outputssorry
model = Sequential()
model.add(GaussianNoise(0.01, input_shape=(n_steps_in, n_features)))
model.add(GRU(20, activation='relu'))
model.add(RepeatVector(n_steps_out))
model.add(GRU(20, activation='relu', return_sequences=True))
model.add(BatchNormalization())
model.add(TimeDistributed(Dense(1)))
model.compile(optimizer='adam', loss='mse')
model.summary()Or in Keras
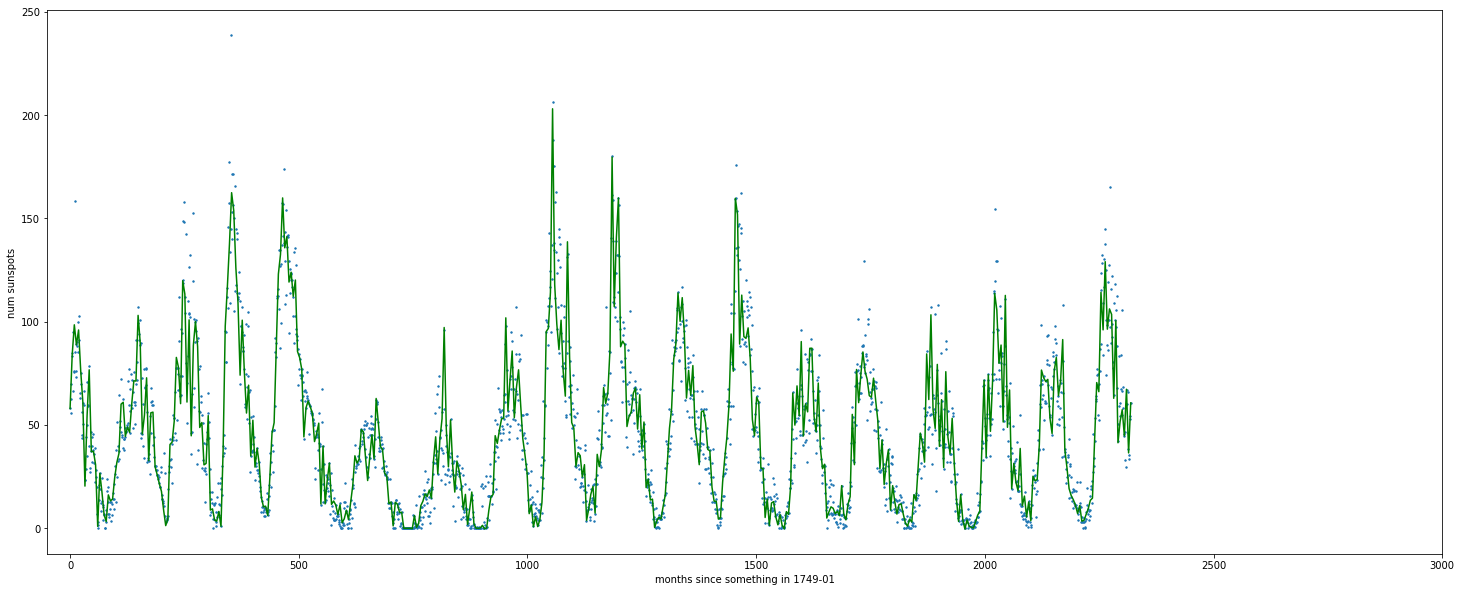
Real example I'm playing with
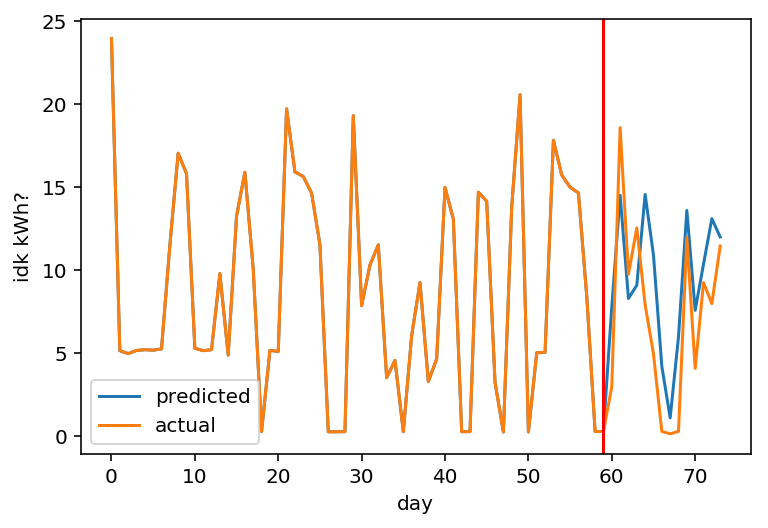
ugly matplotlib charts ftw
Problems with seq2seq
- they're really slow
- you can't parallelise the training
- that means they're really slow
- which means you can't build up HUGE general models (like we can in CV) and do transfer learning