Context window,
personalized,
and stopping criteria.
Acme Design is a full service design agency.
- Context window
- Personalized
- Stopping criteria
Outline




Context window
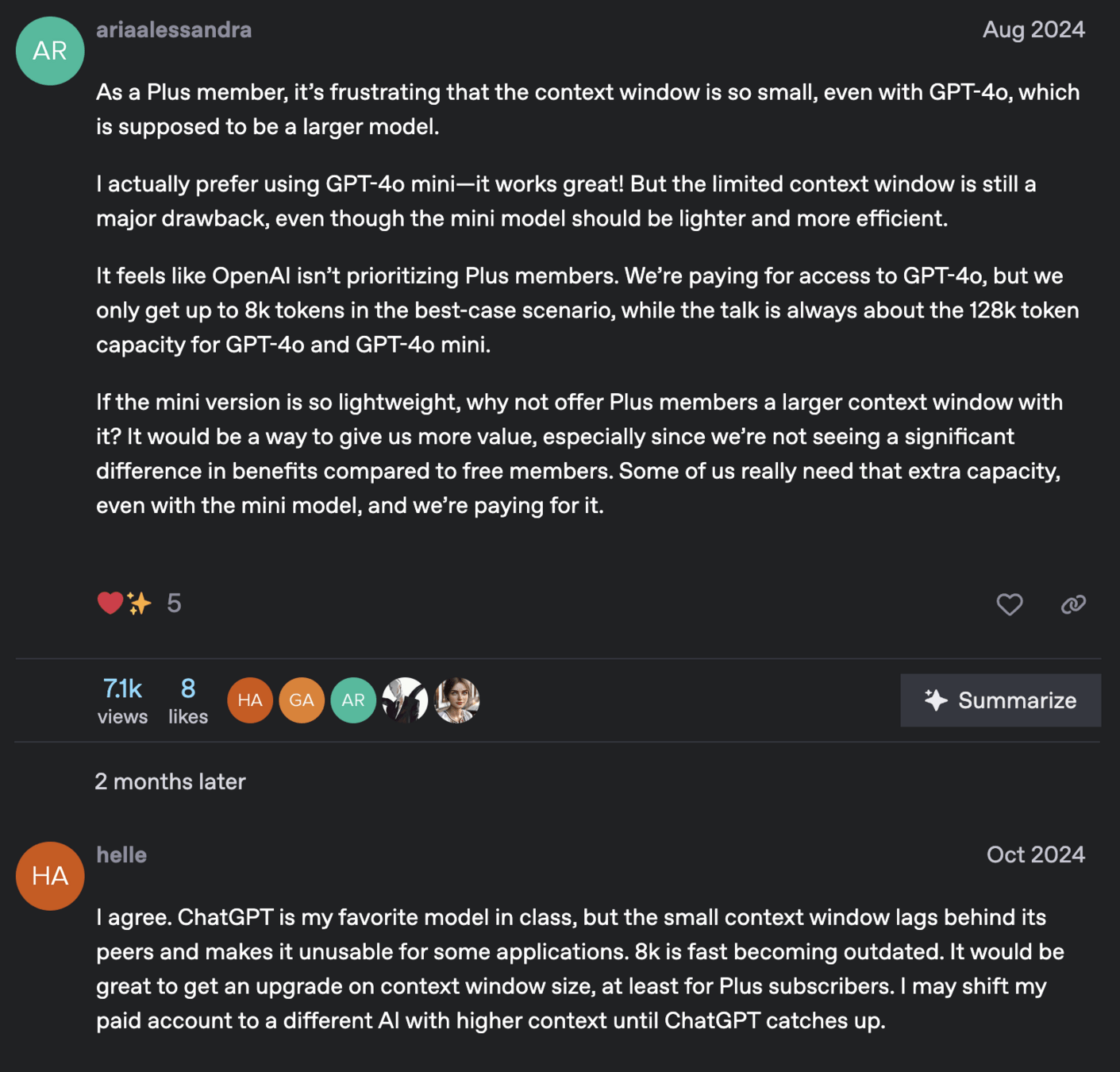
A context window is the maximum span of tokens (text and code) an LLM can consider at once
Including both the input prompt and output generated by the model

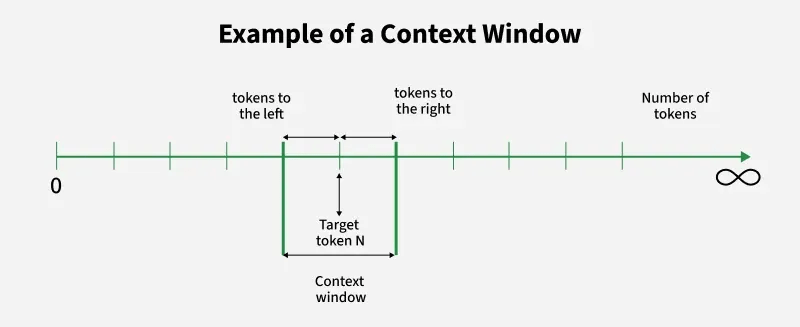
--> Hallucination ?
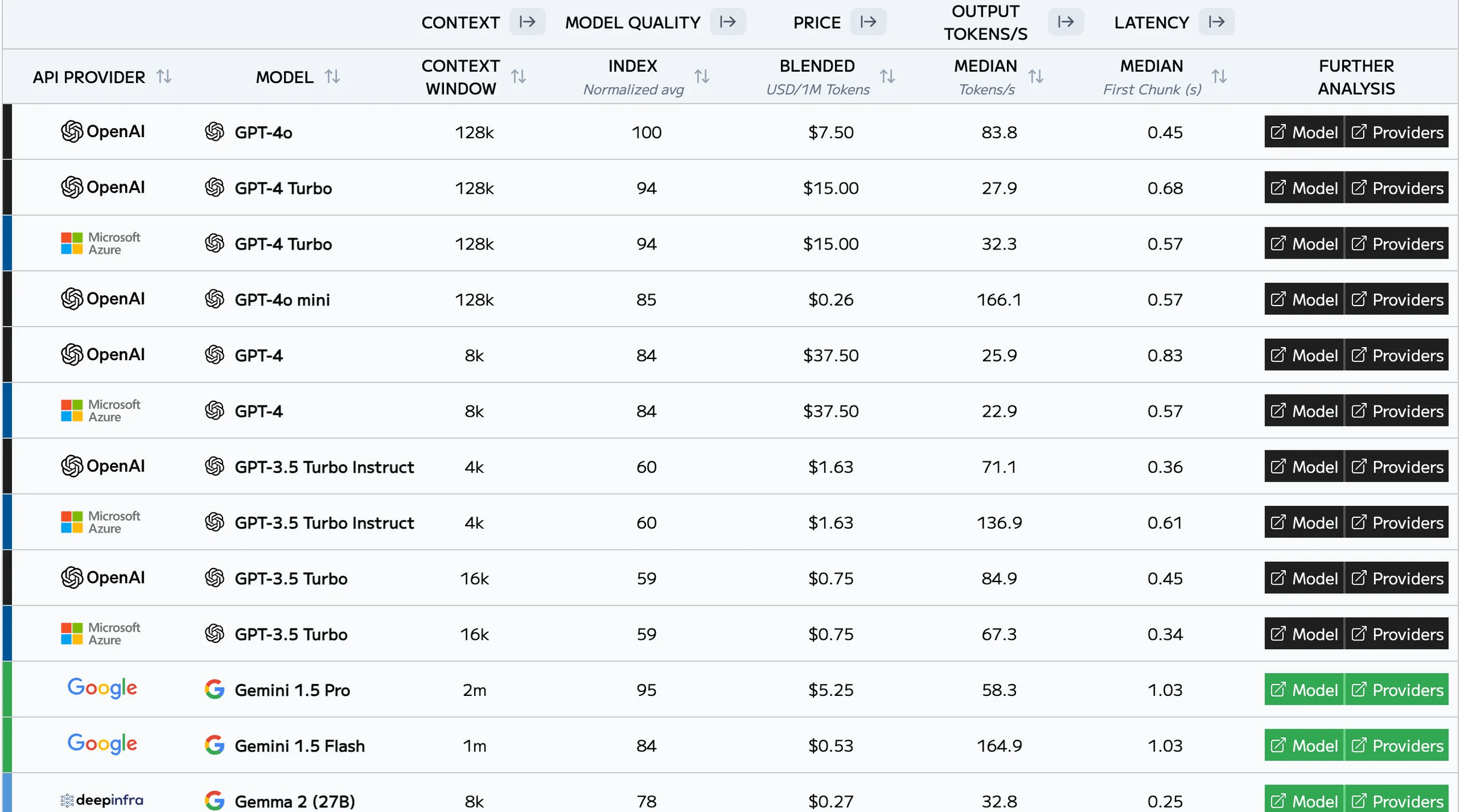
Model by use cases
| Case | Example | Model | Pros | Cons |
|---|---|---|---|---|
| Quality & Reasoning | Advanced research assistants, complex code generation, highly nuanced content creation, medical/legal text analysis, strategic decision support,... | - OpenAI GPT-4o - OpenAI GPT-4 Turbo / Microsoft Azure GPT-4 Turbo |
- Highest quality - Large context size |
- High price - High latency |
| Complex Data & Long Conversations | Document summarization (long papers, books), legal discovery, large codebase analysis,... | - Google Gemini 1.5 Pro - Google Gemini 1.5 Flash |
- Massive context size - High quality |
- Medium price - Very high latency |
| Real-Time Responses & Budget-Conscious | Chatbots (especially high-volume customer service), interactive content generation, real-time code suggestions, dynamic content creation,... | - OpenAI GPT-4o mini | - Very cheap price - Low latency |
- Low context size - Medium quality |
Discussion?

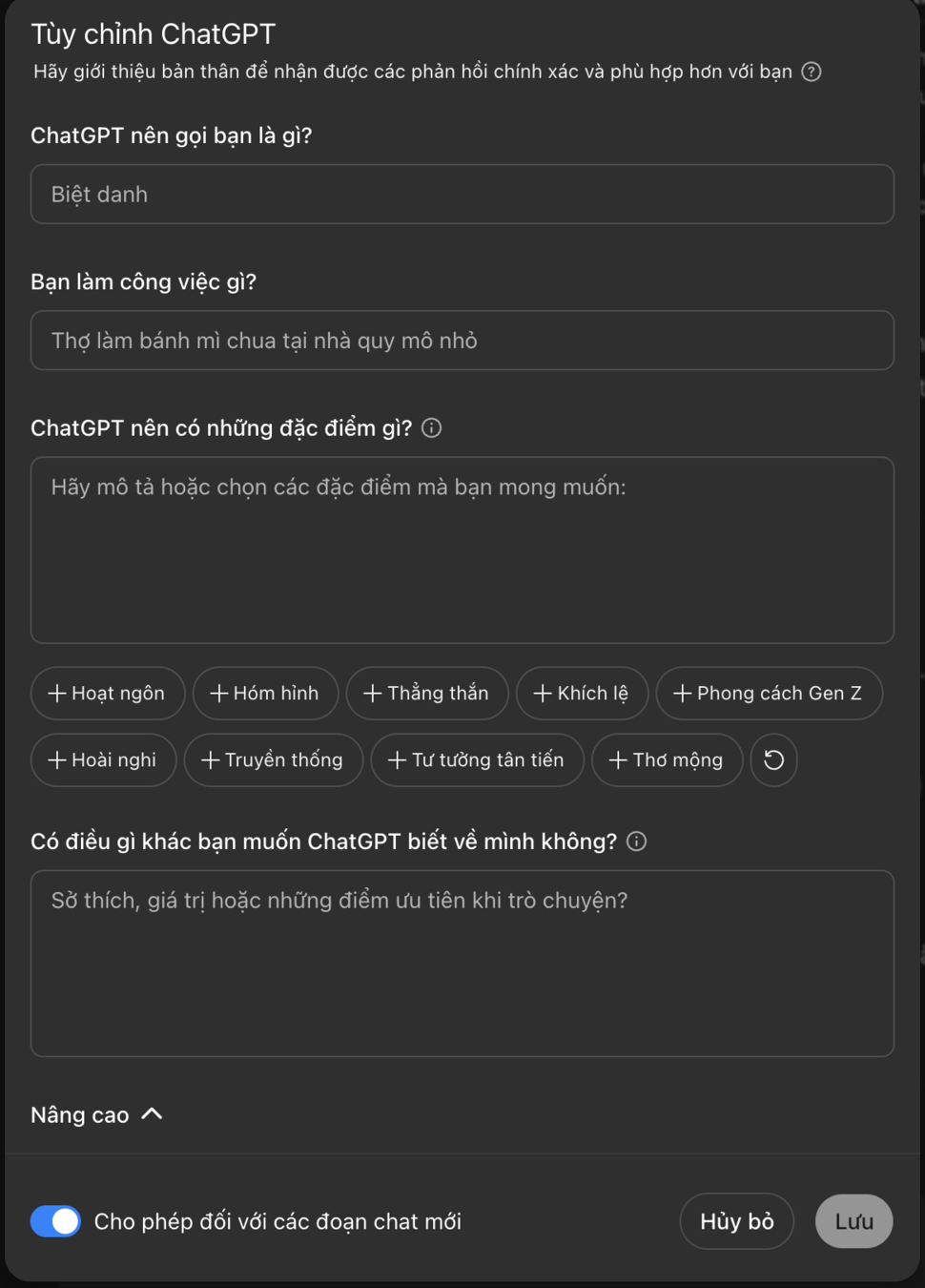
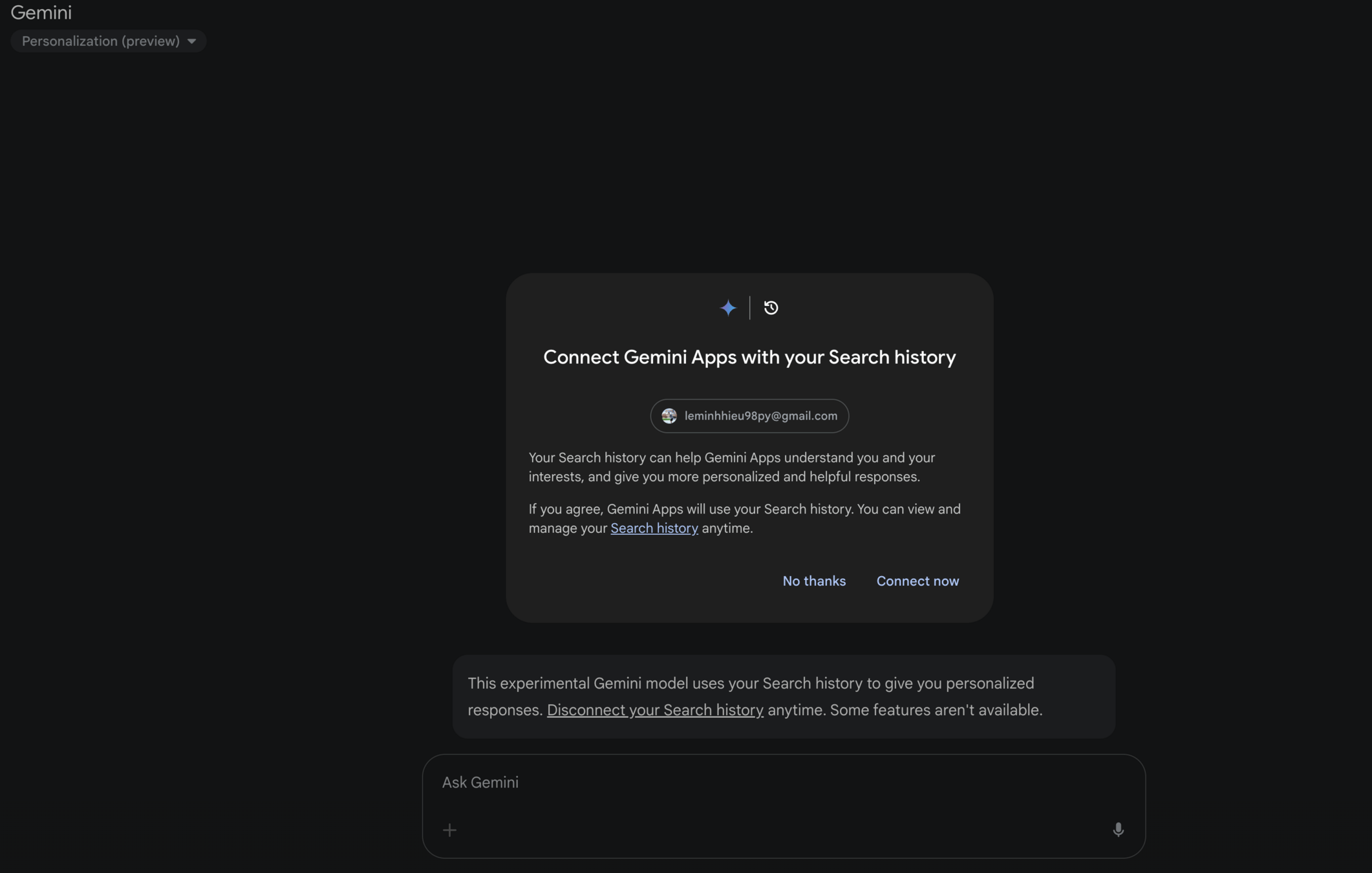
Personalized
- Users' interests, characters, and beliefs,... are different
- Better user experience
Why
- Tailoring the behavior and responses of LLMs to individual user preferences or specific contexts (language, tone, and content, etc.)
- Respond to users in a way that feels customized and personalized to them
What
How
No personalization at all. One model for everyone
Baseline
Giving the model a short description of who the user is
Prompt-based personalization
Adjust the model’s internal behavior based on real user data (train it to understand a specific user’s preferences more deeply)
Fine-tuned personalization
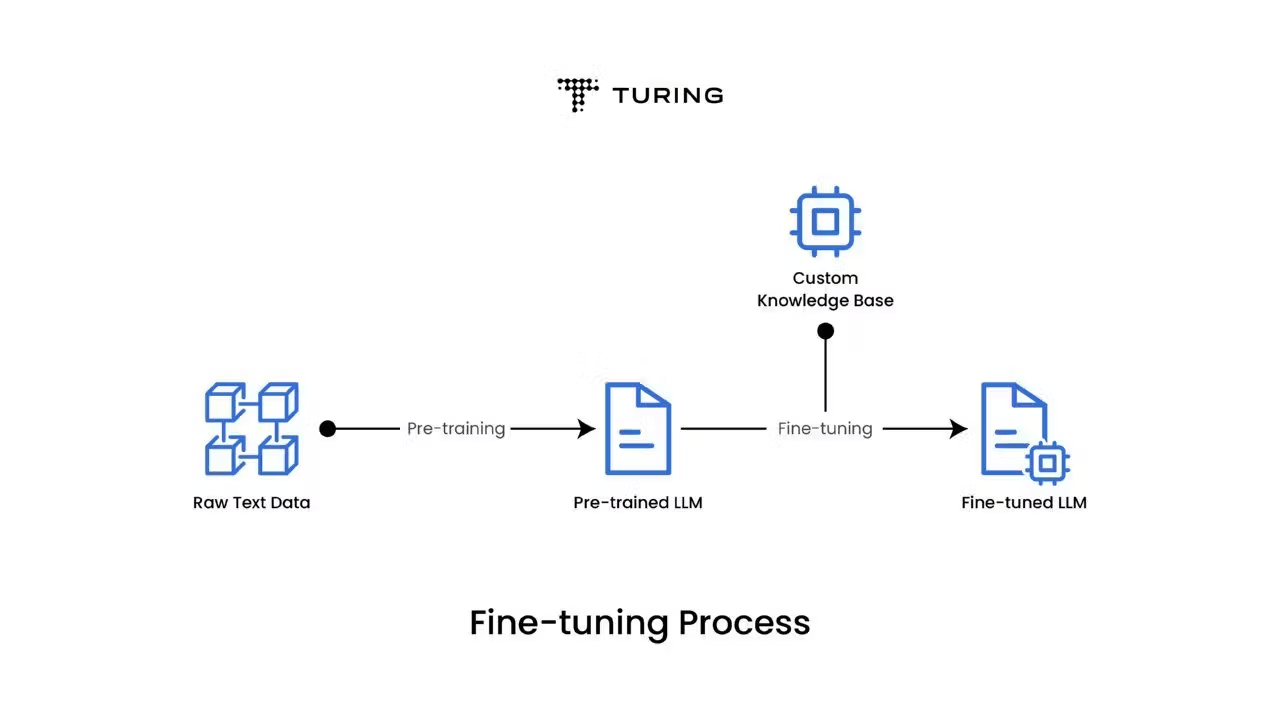
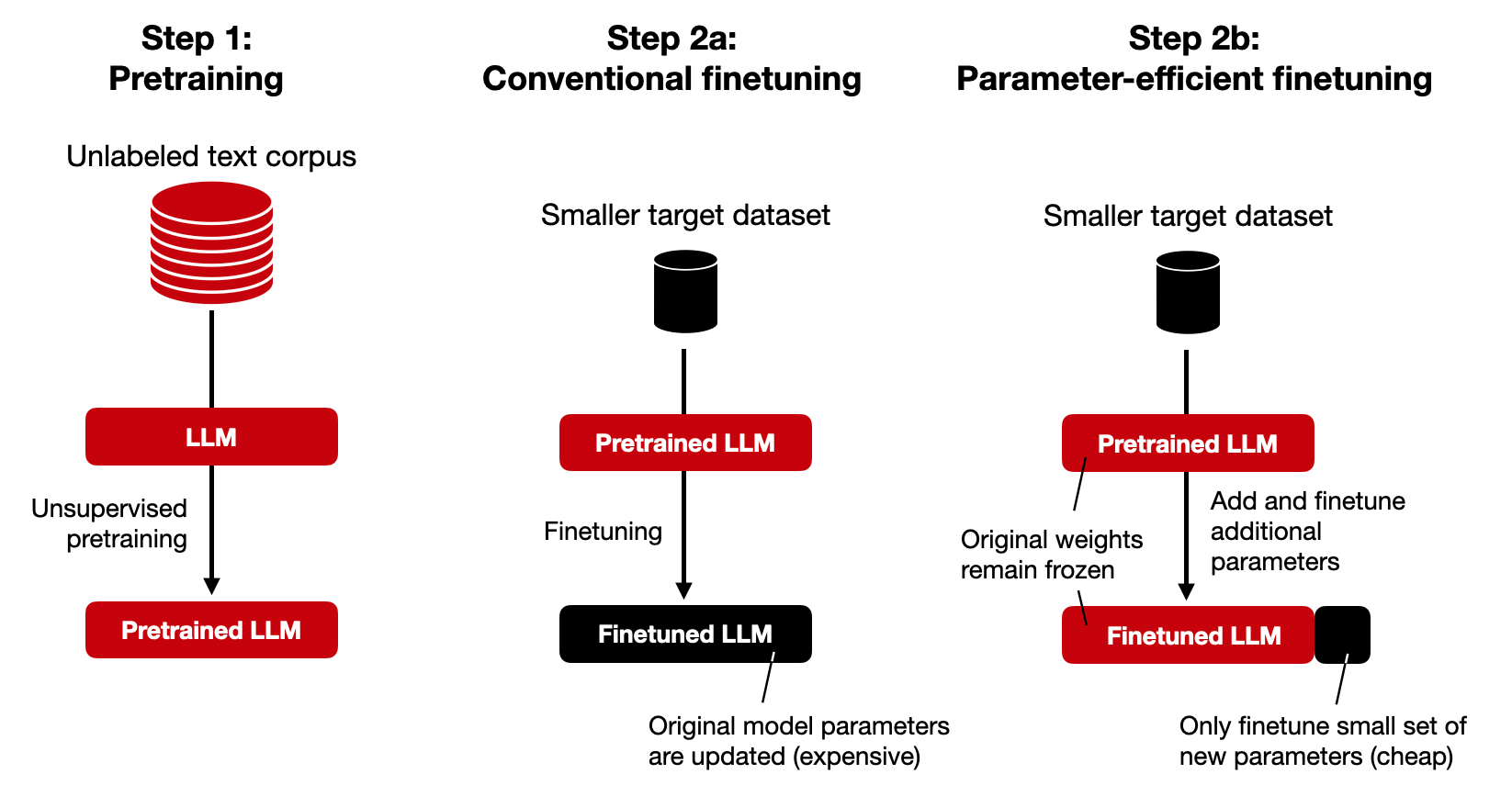
The idea of parameter-efficient finetuning techniques
| Method | Required Input | Concept | Advantages | Disadvantages |
|---|---|---|---|---|
| Baseline | Basic prompt | No personalization | Simple, fast | Not tailored to individual users |
| Prompt-based personalization | Prompt + user attributes | Use personal information inside the prompt | Easy to implement, no retraining needed | Limited effectiveness |
| Fine-tuning personalization | Personal data + model | Train a model specifically for each user | High effectiveness | Resource-intensive, requires personal data |
Comparision
- Social: Tiktok, Youtube, Spotify,...
- ChatGPT, Gemini,...
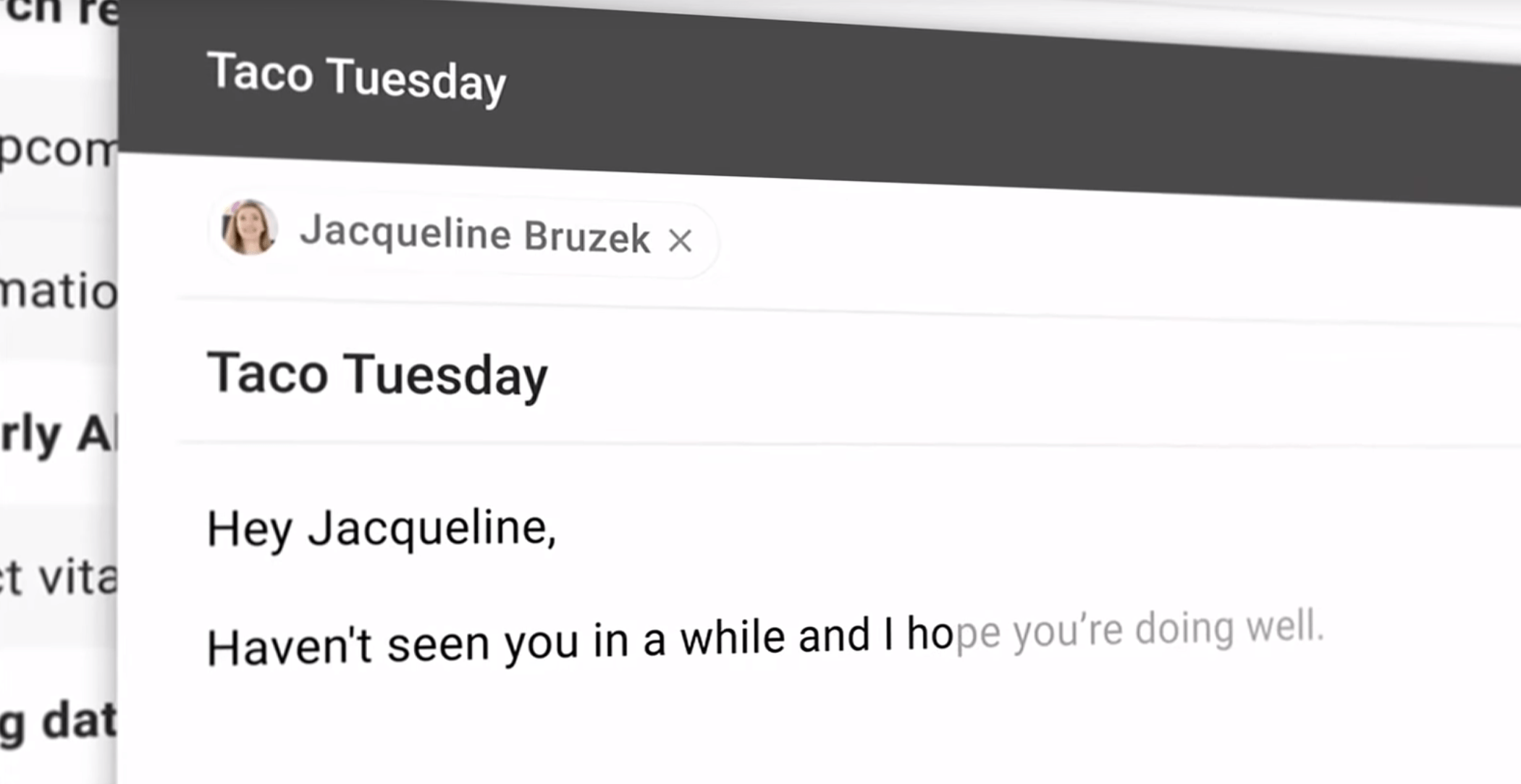
- Gmail's Smart Compose
- ...
Where
Discussion?

Stopping criteria
Criterias to stop the generated responses
-
Efficiency: Avoid wasting computational resources on generating unnecessary tokens
-
Quality: Generated output is relevant, coherent, and avoids excessive repetition
-
User Experience: can be significantly improved by controlling the length and format of responses
Why
Limit the number of tokens the model can generate.
openai.ChatCompletion.create(
model="gpt-4",
messages=chat_history,
max_tokens=512
)
Token Count / Max Tokens
How
✅ Pros
-
Simple and effective.
-
Prevents infinite or excessively long outputs.
⚠️ Cons
-
Might cut off meaningful output mid-sentence.
-
Doesn’t adapt based on context or content.
Token Count / Max Tokens
How
Define one or more string sequences that, when generated, immediately stop further output.
openai.ChatCompletion.create(
model="gpt-4",
messages=chat_history,
stop=["foo", "bar"]
)Special Stop Sequences
How
✅ Pros
-
Works well with tools/functions integration.
⚠️ Cons
-
Must know or enforce these sequences in the prompt.
-
Fragile if the model never emits the exact string.
Special Stop Sequences
How
Stop when the generated content semantically completes the task (e.g., completes a paragraph, finishes a function, etc.).
if response.endswith((".", "!", "?")) and not continuation_needed(response):
stop_generation = TrueSemantic Stopping
How
✅ Pros
-
Feels natural and human-like.
-
More flexible for open-ended generation.
⚠️ Cons
-
Harder to implement — requires post-processing or heuristics.
-
May need a second model or logic to evaluate “completion.”
Semantic Stopping
How
Some LLMs can be guided with a schema — they stop generating when the function/tool-call is formed correctly.
{
"functions": [
{
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {
"location": { "type": "string" }
}
}
}
]
}Function Calling & Tool Use
How
✅ Pros
-
Great for building agentic systems.
-
Guarantees structured outputs.
⚠️ Cons
-
Overhead in defining function schemas.
-
Not for freeform text generation.
Function Calling & Tool Use
How
Repetition Penalties, Top-p, Temperature,...
openai.ChatCompletion.create(
model="gpt-4",
messages=chat_history,
temperature=0.7,
top_p=0.9,
presence_penalty=0.6
)Sampling-based Criteria
How
✅ Pros
-
More natural termination in creative writing or poetry.
-
Encourages diverse but coherent outputs.
⚠️ Cons
-
Indirect — you’re guiding rather than explicitly stopping.
-
Needs fine-tuning and experimentation.