Enabling Machine-Actionable Semantics for Comparative Analyses of Trait Evolution
Project Meeting Oct 2017
RENCI
Architecture
API-first
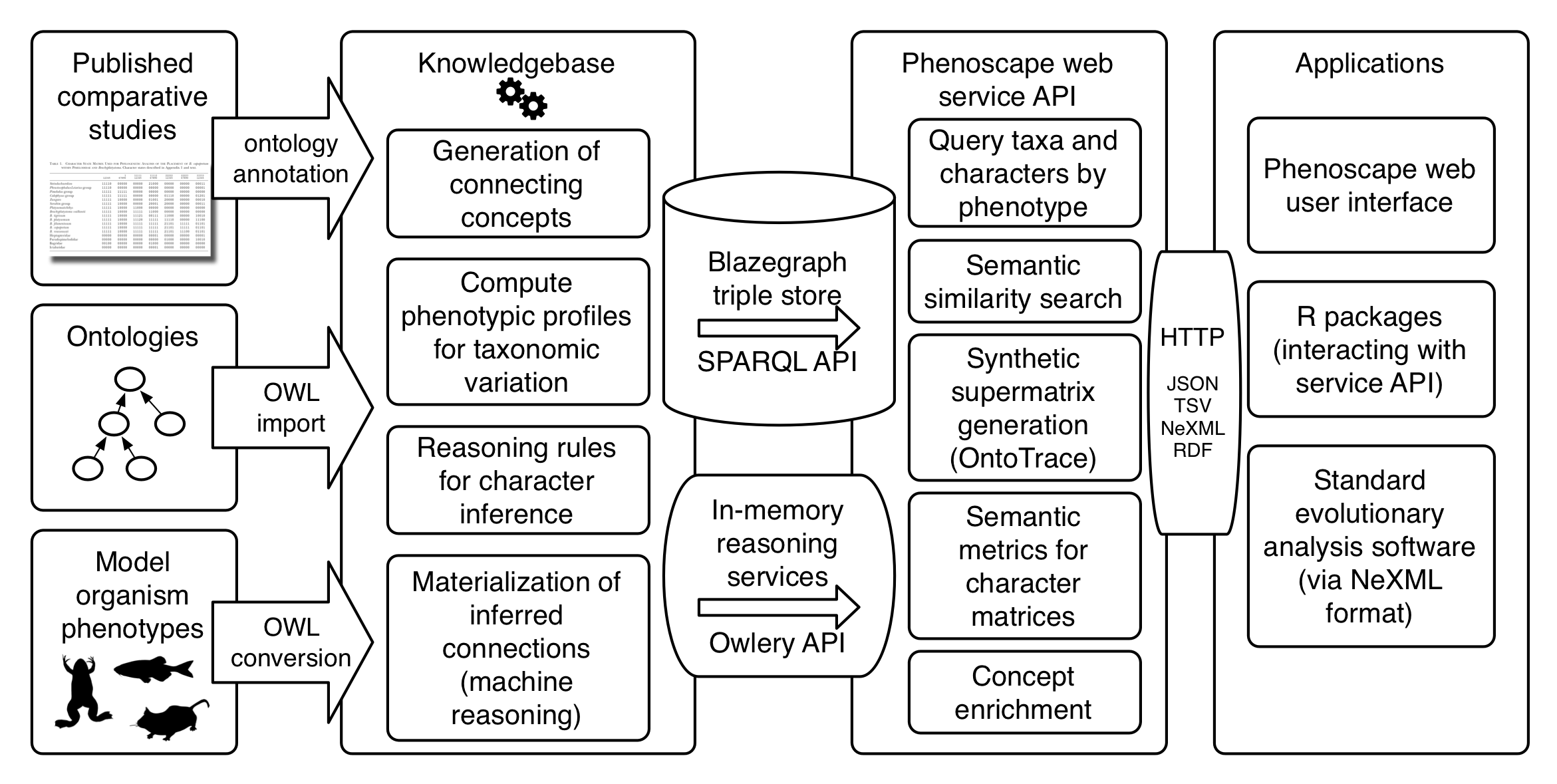
Consequences of API first
- Most reporting through query answering, not web UI
- Report analysis through client-side tools
- Opportunity for literate programming platforms
- Jupyter notebooks
- Rmarkdown documents
- Opportunity for QC automation
- Automatic testing
- Continuous integration
Deliverable I:
Cross-study matrix synthesis and calibration
Ontotrace
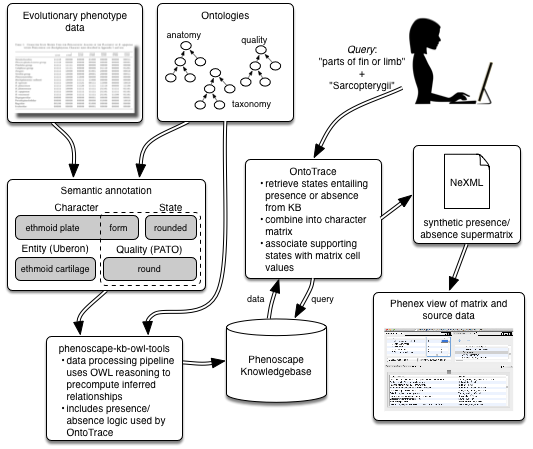
Ontotrace works because the problem is highly bounded
- Number of character states := 2
- State values = { "present", "absent" }
- Character = <entity>: <amount>
Character inference, schematically
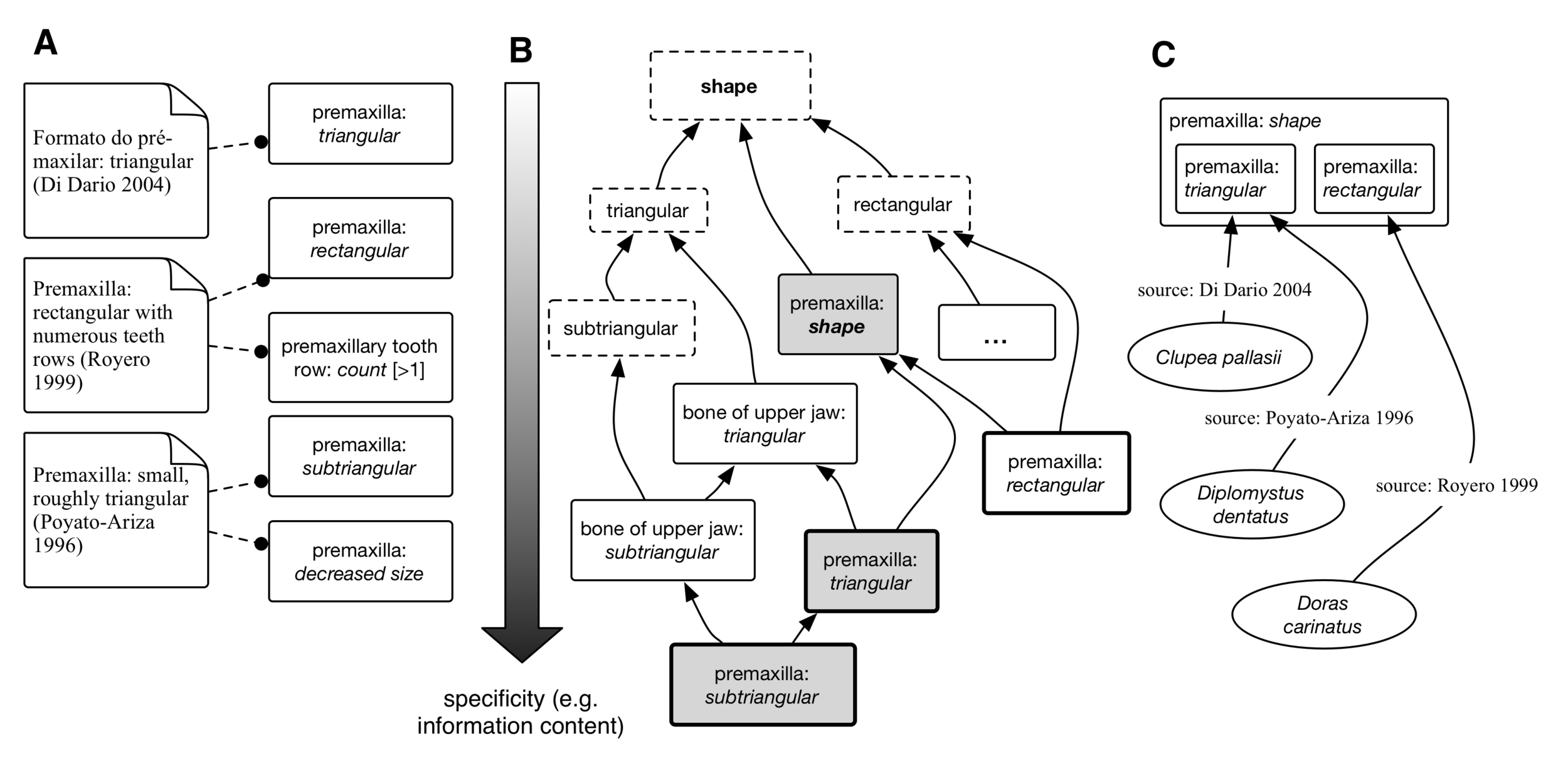
Unconstrained character and state synthesis is a combinatorial problem
- In first approximation
|\cup_{E \in M}(S(E))| \times |\cup_{Q \in M}(S(Q))|
|\cup_{E \in M}(S(E))| \times |\cup(S(A))|
- There can be hundreds of states subsumed by a synthetic character.
Using statistics and machine learning to constrain character inference and state consolidation
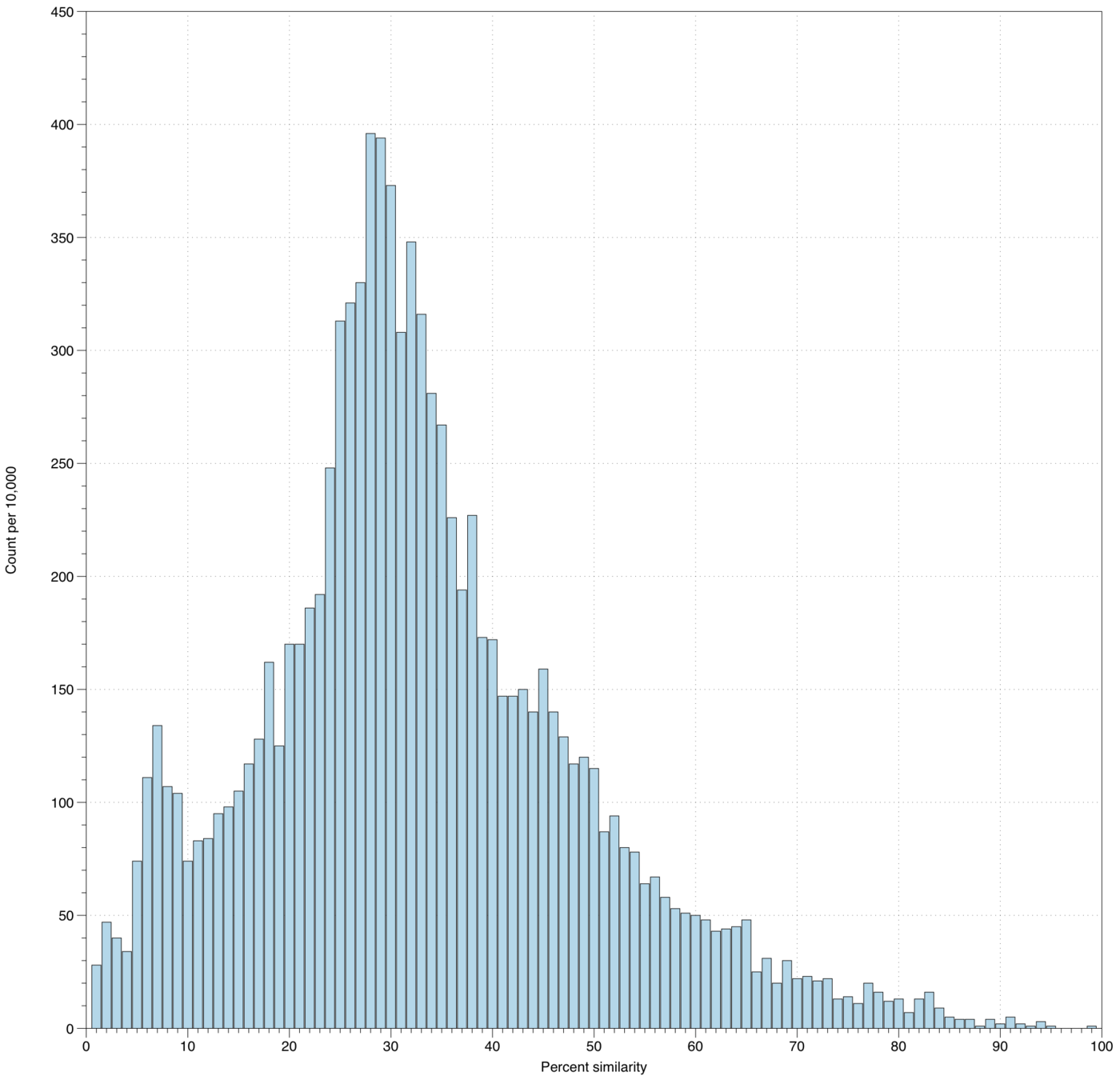
- Use semantic similarity-derived statistics to tell "good" from "bad" matrices?
- What is a desirable "semantic information content" as an objective function?
- Quantify the semantic coherence of (consolidated) character states