Scrapy
Desbravando dados web em massa
#/usr/bin/env python
def about():
me = {
'name': 'Igor Santos',
'email': 'igr.exe@gmail.com',
'github': 'https://github.com/igr-santos',
'websites': [
'http://pythonclub.com.br',
'http://pythonmg.com.br',
'http://igorsantos.me'
],
}
return me
if __name__ == '__main__':
me = about()
print meHow to install Scrapy?
- Python 2.7
- Python PIP
- pip install Scrapy
Dependencies (lxml, OpenSSL)
apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devSpiders
Lugar onde você define o comportamento personalizado para o rastreamento e análise de páginas para um site específico
Spiders
- Raspagem, Rastreamento e Extração de dados
- Execução de forma assíncrona
- Scrapy Selectors (XPath and CSS)
Spiders
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2] + '.html'
with open(filename, 'wb') as f:
f.write(response.body)Item
Estruturar dados coletados pelos Spiders
Item
- dictionary-like API
- Field objects
Item and Item Loaders
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)from scrapy.loader import ItemLoader
from myproject.items import Product
def parse(self, response):
l = ItemLoader(item=Product(), response=response)
l.add_xpath('name', '//div[@class="product_name"]')
l.add_xpath('name', '//div[@class="product_title"]')
l.add_xpath('price', '//p[@id="price"]')
l.add_css('stock', 'p#stock')
l.add_value('last_updated', 'today') # you can also use literal values
return l.load_item()Pipeline Item
Executa ação sobre determinado Item e define se deve ou não ser processado
Pipeline Item
Comportamentos mais comuns, implementados em Pipeline Item:
- Limpeza dos dados HTML
- Validação dos dados (Verificar se Item possui determinados campos)
- Validação de Item duplicado
- Armazenamento em base de dados
Pipeline Item
import json
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return itemPipeline Item
# settings.py
ITEM_PIPELINES = {
'pythOnRio.pipelines.DuplicatesPipeline': 300,
'pythOnRio.pipelines.JsonWriterPipeline': 800,
}Overwiew
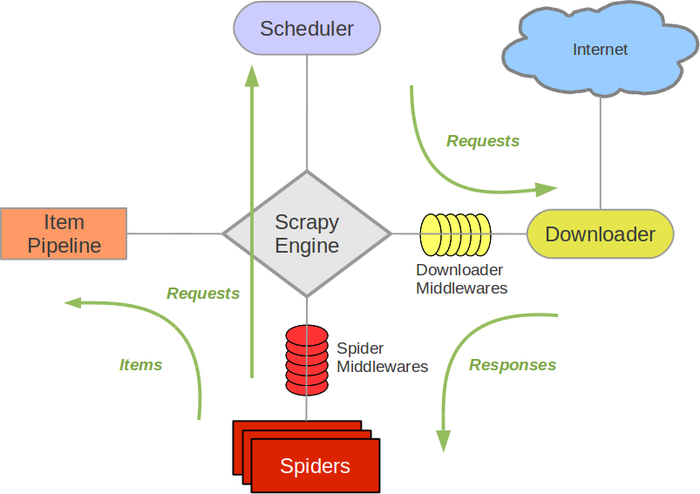
Command Line Interface
- startproject
- runspider
- crawl
- shell
Scrapy and PyJobs
Armazenar ofertas de emprego em Python, com intuito de gerar uma API para disponibilizar esses dados
Links interessante
- Documentação Scrapy (http://doc.scrapy.org/en/latest/)
- Documentação Scrapyd (http://scrapyd.readthedocs.org/en/latest/)
- Snippets Srapy (http://snipplr.com/all/tags/scrapy/)