history and social media:
an archiving failure?
frédéric clavert
@inactinique@hcommons.social
frederic.clavert@uni.lu
inactinique.net
- Why archiving social media posts?
- Case studies
- different ways to collect tweets
Why archiving and analysing social media posts?
Tweets are primary sources
They can help understand
- how people engage with history and the past
- how collective memories develop
Archived, they will help future historians understand our present
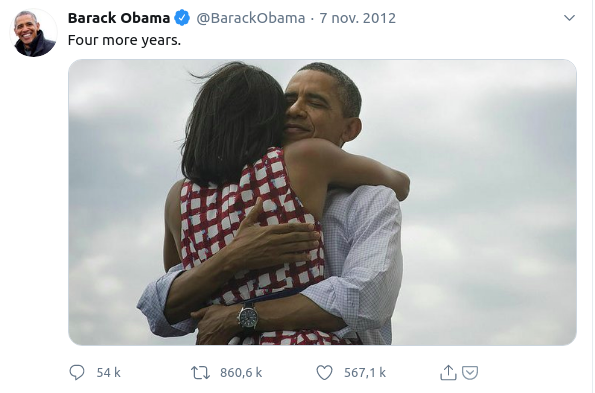
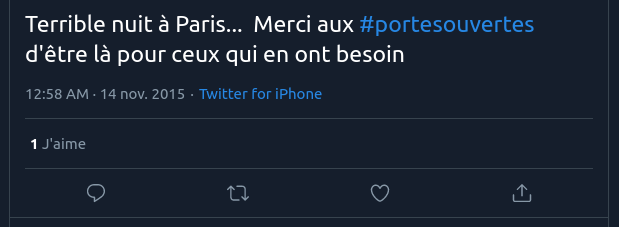
About this tweet, see: Joshua Sternfeld, « Historical Understanding in the Quantum Age », Journal of Digital Humanities, 3-2, 2014.
Tweet from the night of the Bataclan attack, with the #portesouvertes hashtag
Which social media?
The ones we can.
- Facebook/instagram data is hard to collect.
- Whatsapp / Snapchat are impossible to collect.
- Twitter/Reddit used to be collectable
- TikTok?
An application programming interface (API) is a computing interface which defines interactions between multiple software intermediaries.
source: wikipedia
Pitfalls
Who are we studying when collecting and analysing social media data?
- the demographics of social media is complicated (if not impossible) to understand
- the diversity of social media accounts
- people, institutions, groups, bots, etc.
What do we study with social media?
- Information circulation (memetics) where information is understood in a very wide meaning.
See: Dominique Boullier, « Big data challenges for the social sciences: from society and opinion to replications », arXiv:1607.05034 [cs], 2016. - Practices
- Activism
Any other ideas?
Case studies
#ww1 and #covid19
Engaging with the past:
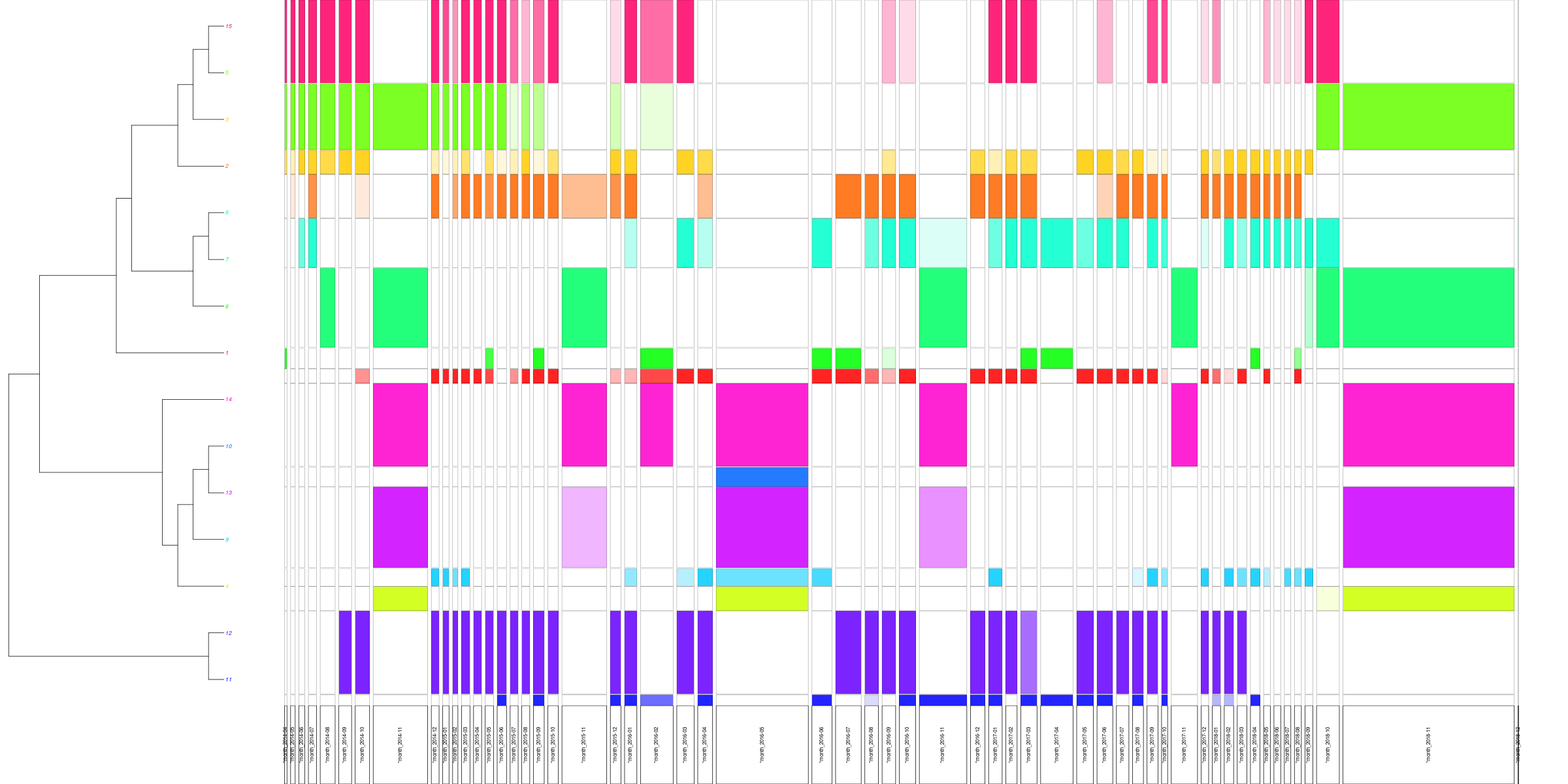
the Centenary of the First World War
- Unique series of commemoration
- 2014-2018
- Throughout Europe and North America
9 millions+ tweets collected

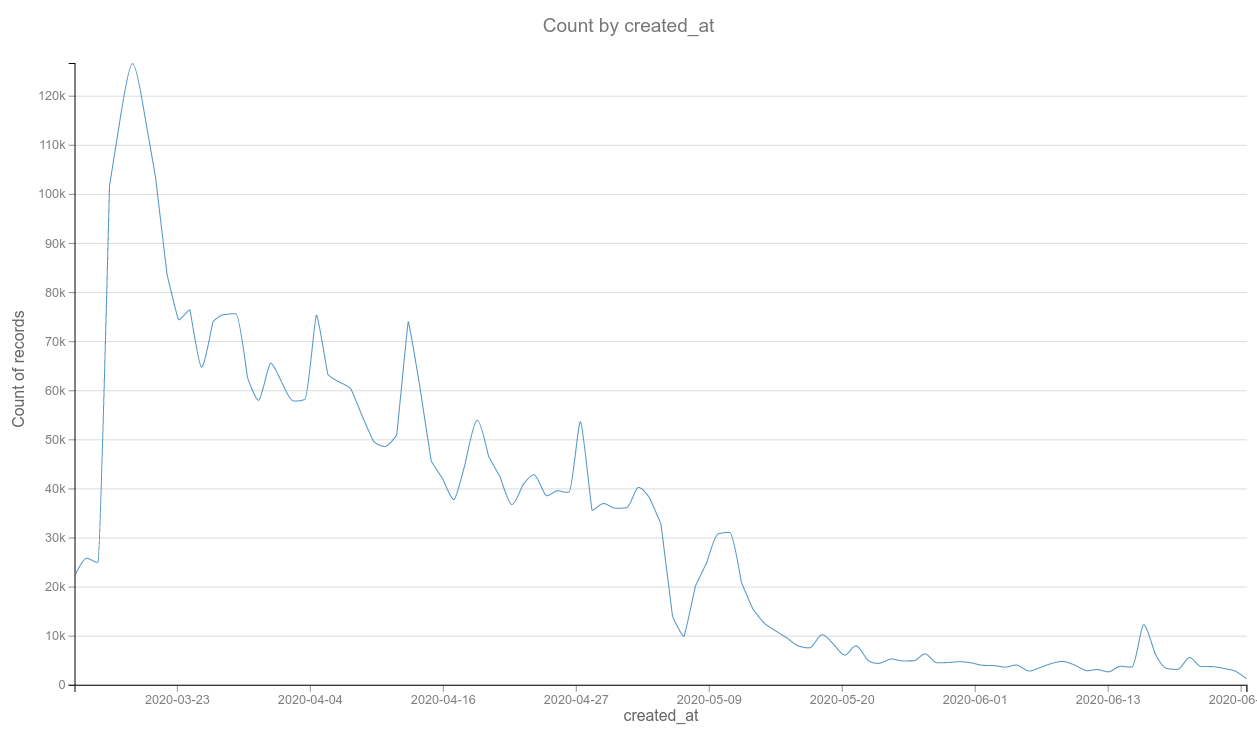
Memory in the making: #covid19fr
Background: John Hopkins University coronavirus map. Screenshot (7/7/2020)

Different ways
to collect tweets
Search API (v1.1)
- You can look for tweets in the past (up to 7 days)
- You can collect around 3000 tweets per hour
- No need to get a twitter developper account
Streaming API (v1.1)
- You can get up to 1% of the firehose (of the tweets published at a precise moment)
- Only tweets being published / will be published: necessity to anticipate
- You need a twitte developper account
API v2 academic product track
- Search
- 10 millions tweets pro month
- in the full history of Twitter
- but...
- Stream
- less than the 1%
Web scrapping
- Not Twitter TOS compliant
- Less metadata
- But you can get tweets up to 2006 (creation of Twitter)
Works now only with the search engine
DSA?
Web archives
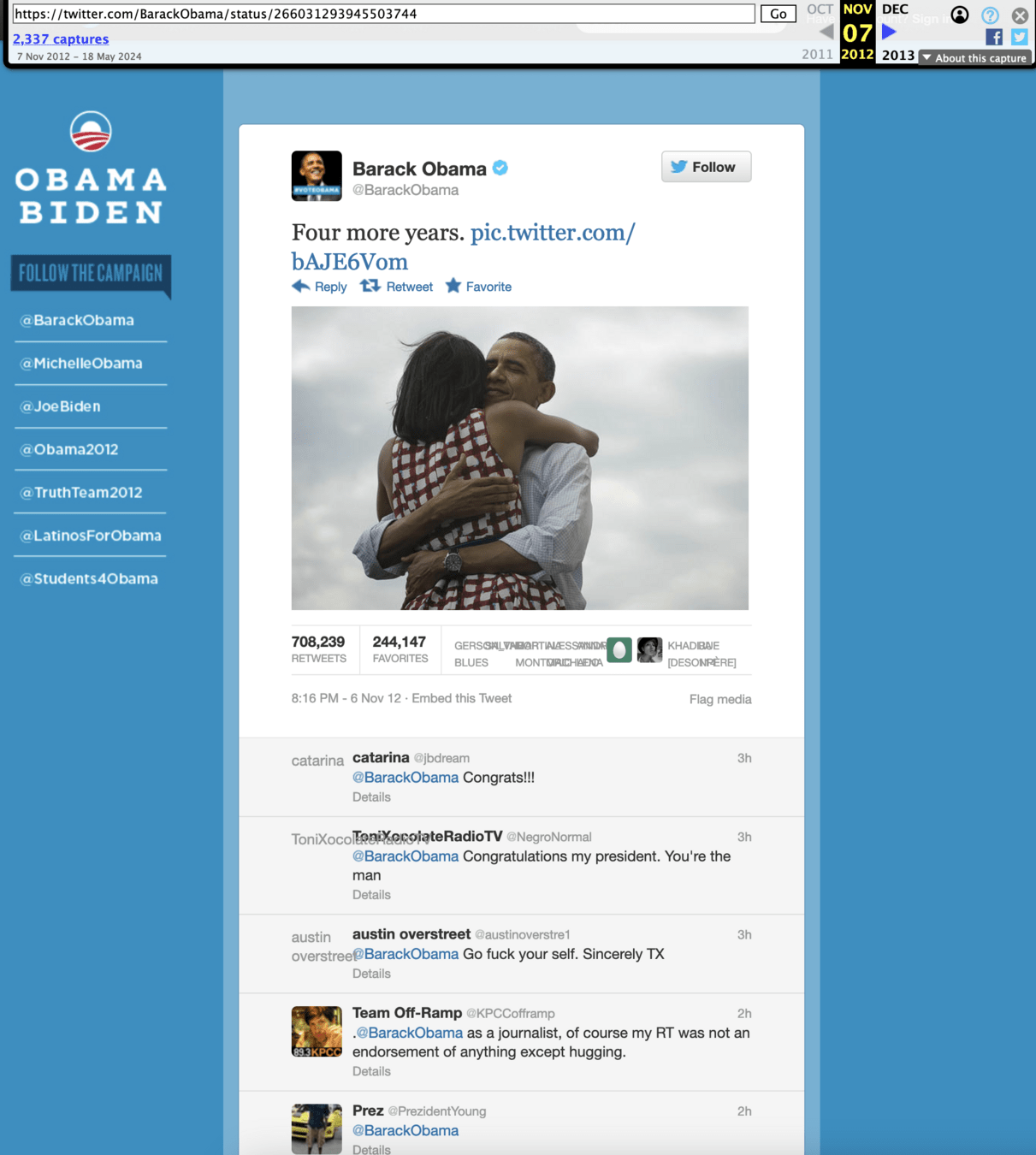
useless archive

halted success
our dependence on BigTech

Counterarchiving?
- Valérie Schafer, Gérôme Truc, Romain Badouard, Lucien Castex et Francesca Musiani, « Paris and Nice terrorist attacks: Exploring Twitter and web archives », Media, War & Conflict, , 2019, p. 1750635219839382.
- Evelien D’heer, Baptist Vandersmissen, Wesley De Neve, Pieter Verdegem et Rik Van de Walle, « What are we missing? An empirical exploration in the structural biases of hashtag-based sampling on Twitter », First Monday, 22-2, 2017.
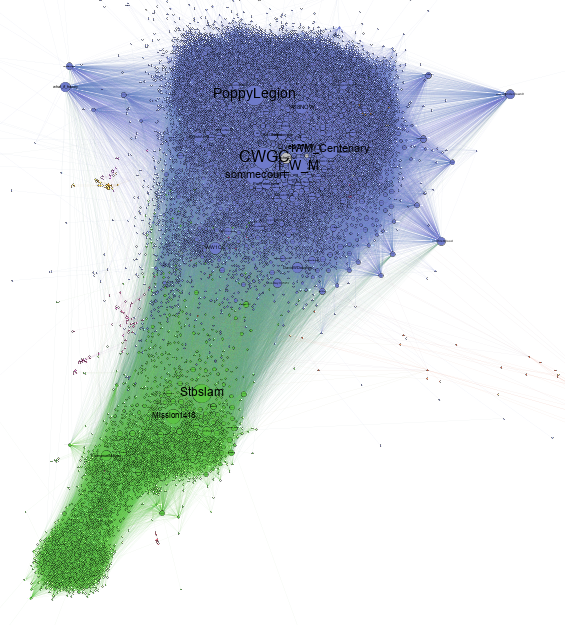
- Martin Grandjean, « A social network analysis of Twitter: Mapping the digital humanities community », Cogent Arts & Humanities, 3-1, 2016, p. 1171458.
- Michael Zimmer, « The Twitter Archive at the Library of Congress: Challenges for information practice and information policy », First Monday, 20-7, 2015.
- Shirley A. Williams, Melissa M. Terras et Claire Warwick, « What do people study when they study Twitter? Classifying Twitter related academic papers », Journal of Documentation, 69-3, 2013, p. 384‑410.
- Danah Boyd, Scott Golder et Gilad Lotan, « Tweet, tweet, retweet: Conversational aspects of retweeting on twitter », IEEE, 2010.
- Danah M Boyd et Nicole B. Ellison, « Social Network Sites: Definition, History, and Scholarship », Journal of Computer-Mediated Communication, 13-1, 2007, p. 210‑230.
- Hany M. SalahEldeen et Michael L. Nelson, « Losing My Revolution: How Many Resources Shared on Social Media Have Been Lost? », arXiv:1209.3026, , 2012.
- Jean-Christophe Peyssard, « Archiving Web Content ». https://halshs.archives-ouvertes.fr/cel-02130558/document
- Ben-David, Anat. 2020. « Counter-Archiving Facebook ». European Journal of Communication, mai, 026732312092206. https://doi.org/10.1177/0267323120922069.
- Two prez: «How to deal with 4 millions+ tweets when you are not a data scientist» (https://orbilu.uni.lu/handle/10993/35017)
- and «Twitter data as primary sources for historians: a critical approach» (with S. Papastamkou) (https://orbilu.uni.lu/handle/10993/37070)