Classification on Imbalanced Data
Indraneil Paul
IIIT Hyderabad
The Dataset
- Anonymized credit card transactions
- 28 Anonymized features
- 285K+ data points
- ~500 examples of fraud
The Problem
- Classifiers are designed with maximising accuracy in mind
- The metrics we strive to optimise assume uniform class distribution
Real life data sets very rarely have a uniform class distribution
- Implicit assumption of uniformity of misclassification cost
The cost of misclassifying members of the minority class is often higher
Methods Rectifying Class Imbalance
- Undersampling Methods
Random, NearMiss, CNN, ENN, RENN, Tomek Links
- Ensemble Methods
EasyEnsemble, BalanceCascade
- Synthetic Data Generation
SMOTE, ADASYN
-
Cost-Sensitive Learning
-
Oversampling Methods
Random, Cluster Based
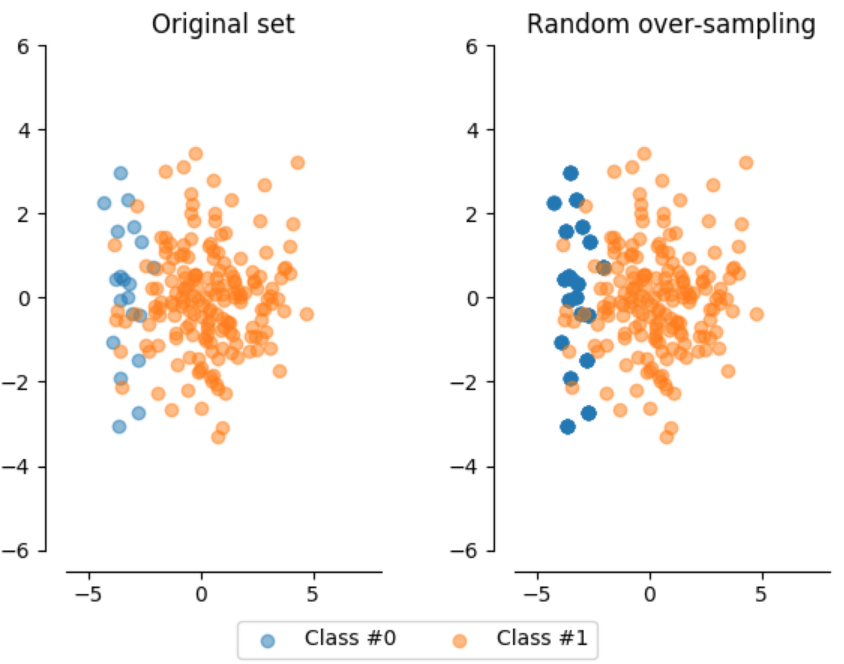
Random Over/Under Sampling
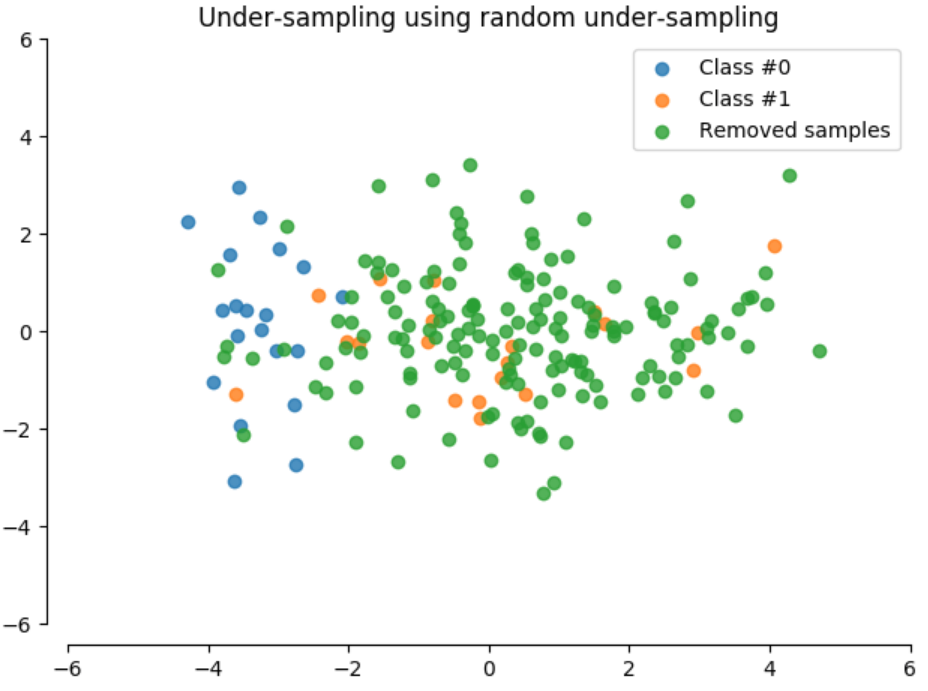
- Random Under Sampling
Randomly eliminates instances of the majority class
Usually results in severe information loss
- Random Over Sampling
Duplicates random instances of the minority class
Likely overfitting due to duplicating data points
NearMiss
- NearMiss 1
Selects the majority class samples whose average distances to three closest minority class samples are the smallest
- NearMiss 2
Selects the majority class samples whose average distances to three farthest minority class samples are the smallest
-
NearMiss 3
Takes out a given number of the closest majority class samples for each minority class sample
from imblearn.under_sampling import NearMiss
nm1 = NearMiss(version=1, return_indices=True)
nm2 = NearMiss(version=2, return_indices=True)
nm3 = NearMiss(version=3, return_indices=True)
X1_res, Y1_res, idx1_res = nm3.fit_sample(X, Y)
X2_res, Y2_res, idx2_res = nm3.fit_sample(X, Y)
X3_res, Y3_res, idx3_res = nm3.fit_sample(X, Y)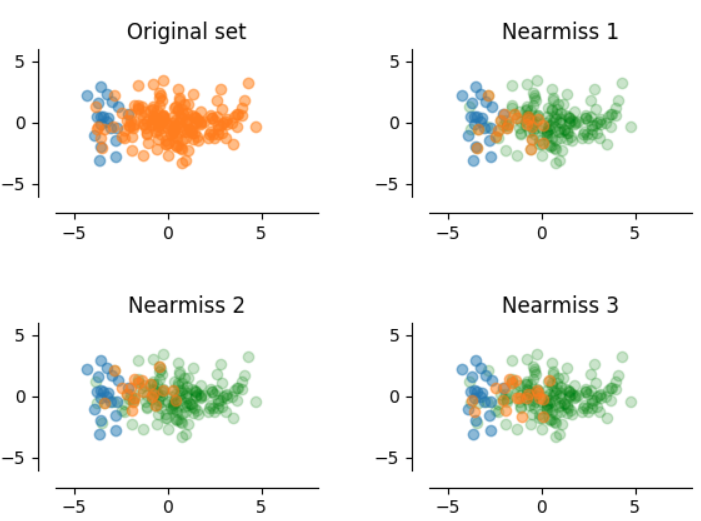
Easy Ensemble
- This method functions as an 'ensemble of ensembles'
from imblearn.ensemble import EasyEnsemble
ee = EasyEnsemble(n_subsets=3)
X_res, Y_res = ee.fit_sample(X, Y)
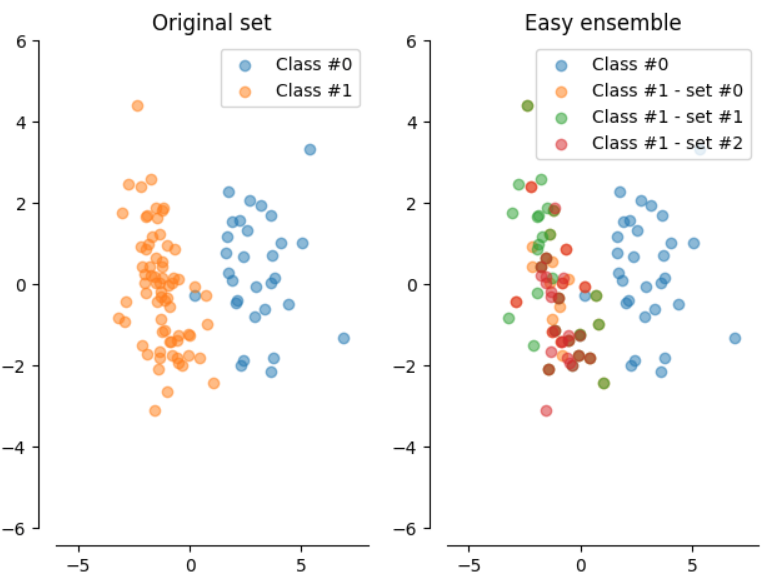
- Random subsets of the majority class, with as many members as the minority class are chosen, to train an AdaBoost ensemble with a threshold
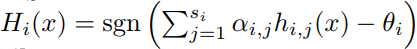
- Repeat for T iterations to get a strong hypothesis
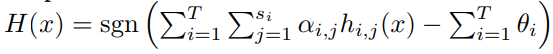
Balance Cascade
- Rejection cascade with multiple stages rejecting majority class data points previously correctly classified
from imblearn.ensemble import BalanceCascade
bc = BalanceCascade()
X_res, Y_res = bc.fit_sample(X, Y)
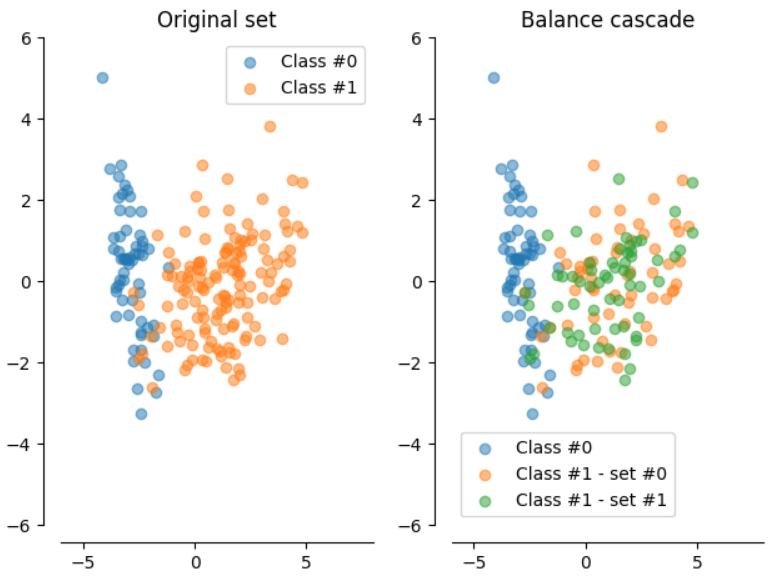
- Random subsets of the leftover majority class, with as many members as the minority class are chosen, to train an AdaBoost ensemble with a threshold
- Repeat for T iterations to get a strong hypothesis, each iteration working with a modified majority class
SMOTE
- For each point in minority class choose k closest neighbours
from imblearn.over_sampling import SMOTE
sm = SMOTE(kind='regular')
X_res, Y_res = sm.fit_sample(X, Y)
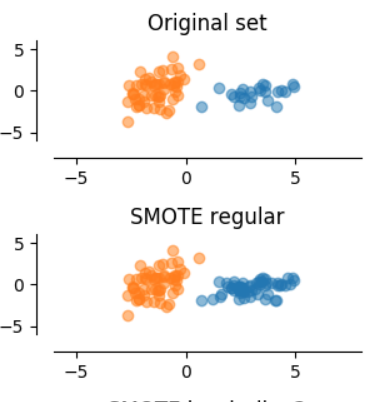
- Randomly choose r < k of the previously chosen neighbours
- Choose a random point along each line joining the minority class sample to its r previously chosen neighbours
- Create synthetic minority class instances at the chosen random points
ADASYN
- Creates synthetic samples using methodology of SMOTE
from imblearn.over_sampling import ADASYN
ada = ADASYN()
X_res, Y_res = ada.fit_sample(X, Y)
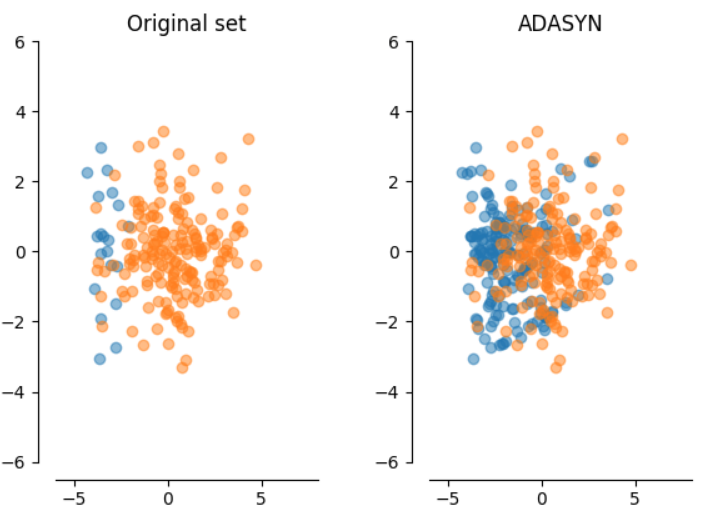
- Unlike SMOTE we do not randomly generate synthetic examples for every minority class sample
- The number of synthetic examples created per minority class sample depends on its learning difficulty
- Learning difficulty is proportional to the count of majority class neighbours
References
- https://chih-ling-hsu.github.io/2017/07/25/Imbalanced-Data-Classification
-
Exploratory Undersampling for Class-Imbalance Learning
Nguyen Thai-Nghe, Zeno Gantner, and Lars Schmidt-Thieme
- http://contrib.scikit-learn.org/imbalanced-learn/stable/api.html