Hadoop
A. Fraga, V. Ostertag, A. Ruiz Rodriguez
Friday 16th of November 2017
Cranfield University

Hadoop presentation
Plan

INTRODUCTION
HISTORY
SOME BASICS
HOW IT WORKS
IMPLEMENTATION
CONCLUSION
Introduction
Hadoop presentation
Cranfield University
Cranfield University
Hadoop presentation
Hadoop
open-source


Memory storage

Big datasets processing
Developed in Java
HDFS
MapReduce (+ YARN since 2.0)
Cranfield University
Hadoop presentation
Goals & utilities
Handle hardware failures


used to do:
Marketing analysis

Machine learning

Data mining

Image processing
History
Hadoop presentation
Cranfield University

Cranfield University
Hadoop presentation
Chronology

2006
Released by Doug Cutting and Mike Cafarella


Hadoop
Cranfield University
Hadoop presentation
Chronology
2008
Yahoo moves its web index to Hadoop

Fastest system to sort a terabyte (209 seconds)

2009
Sort a terabyte in 62 seconds

2012
YARN is introduced
Cranfield University
Hadoop presentation
Success

Widely used:


Some basics
Hadoop presentation
Cranfield University

Cranfield University
Hadoop presentation
Map

[1, 2, 3, 4, 5, 6]
[1, 4, 9, 16, 25, 36]
Apply a function to every element.
Example:

map using square function
Cranfield University
Hadoop presentation
Reduce
Reduce a set of data to one value using an accumulator
[1, 2, 3, 4, 5, 6]
21
Example:
reduce using the sum accumulator
In Hadoop, we use MapReduce
So, what is it?
Cranfield University
Hadoop presentation
How it works
Hadoop presentation
Cranfield University
Cranfield University
Hadoop presentation
Nodes

Master nodes
Slave nodes
(manager)
(worker)
Data Node
Task tracker

Name node
Job tracker
Cranfield University
Hadoop presentation
HDFS
Client
Name node

150 Mo file
64 Mo
64 Mo
22 Mo
Data node 1
Data node 2
Data node 3
example.txt
example.txt
Cranfield University
Hadoop presentation
HDFS
Name node

"example.txt"
=
Data node 1 + Data node 2 + Data node 3
Cranfield University
Hadoop presentation
Backup
Name node
Secondary name node
Rack 1
Rack 2

Data Node 1.2
Data Node 1.5
Data Node 2.1
By default, saved 3 times


Cranfield University
Hadoop presentation
Jobs

Client
Job tracker

submits jobs
slave node
Task tracker
Create the task
heartbeat
Map
Reduce
Name node
Write / read
1
2
3
5
4
Cranfield University
Hadoop presentation
To do

Code the Mapper Class
Code the Reduce Class
Code the main
No need to worry about anything else!
Cranfield University
Hadoop presentation
YARN
What if I don't want to use MapReduce?
YARN
Framework that allows us to use other data processing
No more limitations!
Implementation
Hadoop presentation
Cranfield University

Cranfield University
Hadoop presentation
What we want to do
Count the number of words in a string
We will code in JAVA using Hadoop
... Let's see how easy it is!
Cranfield University
Hadoop presentation
First step : main

We'll start by initializing the problem at hand:
WordCount
Text
String
Program's name
Variable ready to be solved
1
2
public class WordCount {
public static void main(String[] args) throws Exception {
// New configuration
Configuration conf = new Configuration();
// I want to create a new job
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
...
}
...
}
1
2
Cranfield University
Hadoop presentation
Cranfield University
Hadoop presentation
Mapper
Now, we want to use a mapper to count the words
WordCount
Text
String
Map
("word", 1)
("word", 1)
("word", 1)
("word", 1)
3
Result of the mapper for each processor
...
// My job will convert unstructured data into structured data
job.setMapperClass(TokenizerMapper.class);
...
3
Custom Mapper to create
Cranfield University
Hadoop presentation
Cranfield University
Hadoop presentation
Reduce
Then, we need to sum all the results
Text
String
Map
("word", 1)
("word", 1)
("word", 1)
("word", 1)
Hadoop
("word", (1,1,1,1))
Reduce
("word", 4)
Reduce
Gather the data
4
5
Cranfield University
Hadoop presentation
...
// Then it will combine local results
job.setCombinerClass(IntSumReducer.class);
// Then it will reduce everything
job.setReducerClass(IntSumReducer.class);
// But do it with this format
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
...
4
5
Custom Reducer class
Cranfield University
Hadoop presentation
Output

...
// Defining Input and output path
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// Ok Job, do what I want you to do
System.exit(job.waitForCompletion(true) ? 0 : 1);Cranfield University
Hadoop presentation
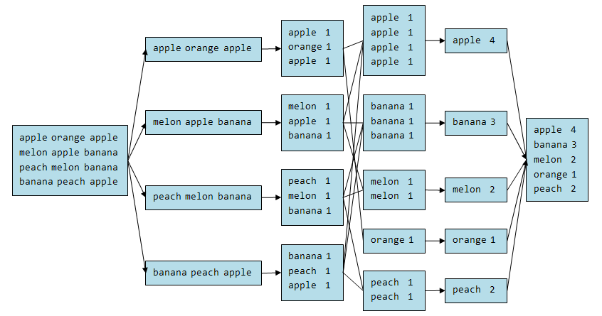
Example
Conclusion
Hadoop presentation
Cranfield University


MPI
Hadoop

Cranfield University
Hadoop presentation
Conclusion
