Deep Address Parser Brownbag
Jinkela Huang (v-jinkhu)
Mentor: George Wang
Manager: Alex Chiang
Outline
- Design Architecture
- word2vec
- Lexicon
-
Delexicalization
- Data processing for training
- Delexicalization test
- Reduce Memory
- Report
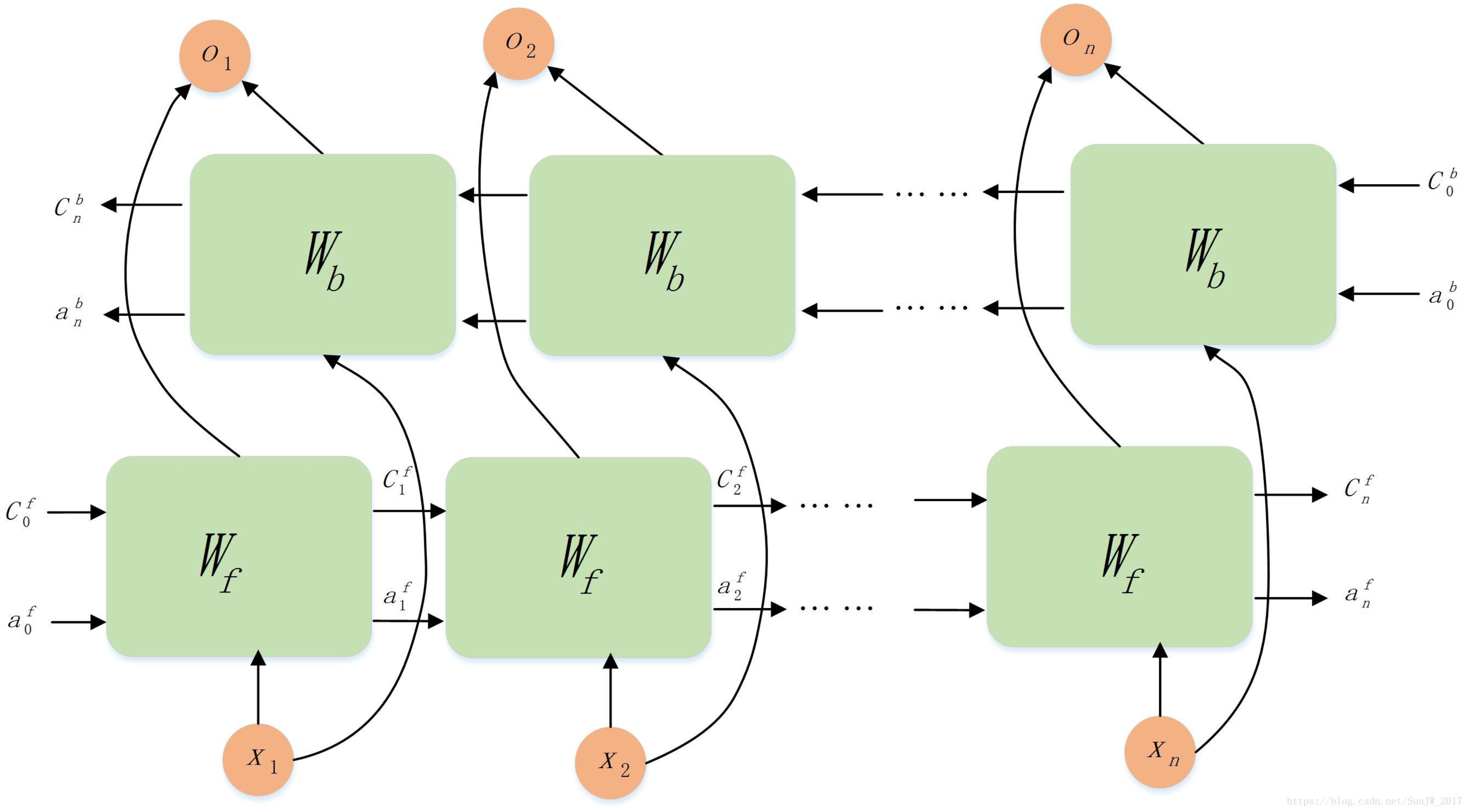
Design Architecture
Our Model
BOS Rua Canindé, 102, São Paulo, Brasil EOS
O B-road I-road B-house_number B-city I-city B-country pt-br
What We Want To Train
Encoding to floating point matrix
Output probability matrix
Words Input
Tags Output
language code
Training Flowchart
Words Input
Tags Input
encoding
AP model using TF with Keras
Our
Module
Test
encoding
biLSTM
* Model design is based on paper: A bi-model based rnn semantic frame parsing model for intent detection and slot filling (Link)
UML
NLUModel
word2vec
DataIniter
KerasModelHelper
Report
Builder
TrainData
Source
TestData
Source
DelexicalizationTest
DataSource
Association
Inherit
word2vec
Brasil
...
Brasil: 6
Rua: 3
Canindé: 7
...
Word To Unsigned int Map
Word Input
Embedding
Layer
B-country
...
I-road: 4
B-country: 9
I-city: 5
...
Tag To Unsigned int Map
Tag Input
| 0 | 1 | ... | 8 | 9 | ... | 39 |
|---|---|---|---|---|---|---|
| 0 | 0 | ... | 0 | 1 | ... | 0 |
One Hot encoding
6
9
Brasil
Word To Vector Map
Word Input
| 0 | 1 | ... | 98 | 99 |
|---|---|---|---|---|
| 0.01 | 0.13 | ... | 0.19 | 0.11 |
vector
a lot of sentence
Input
gensim
word2vec training
word2vec
Lexicon
Barcelona
Word Input
| 0 | 1 | ... | 98 | 99 |
|---|---|---|---|---|
| 0.21 | 0.03 | ... | 0.19 | 0.11 |
vector
6
Get All Possible Tags
Of Word Input
City: 4
Province: 7
| 100 | ... | 104 | ... | 107 | 108 | ... | 149 |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
Word To Vector Map
Delexicalization
Data processing
for training
Tag2WordDict
- We create mapping Tag2WordDict:
- Key is each word in Train Data.
- Value is the most corresponding tag of this word.
...
Brasil: country
Toledo: city
615: house_number
Guilherme: road
...
Original Data
Training Data
| Words | Tags |
|---|---|
| BOS São Paulo EOS | O B-city I-city pt-br |
| Words | Tags |
|---|---|
| BOS São Paulo EOS | O B-city I-city pt-br |
| BOS city Paulo EOS | O B-city I-city pt-br |
| BOS São city EOS | O B-city I-city pt-br |
Replace word by Tag2WordDict
Delexicalization test
Words
| number | number | number |
|---|
Tags
| 0.85 | 0.72 | 0.76 |
|---|
Probability
| 567 | 2nd | ave |
|---|
Round 1
Round 2
| 567 |
road_w |
ave |
|---|
Words
| number | road | number |
|---|
Tags
| 0.84 | 0.83 | 0.74 |
|---|
Probability
Round 3
| 567 | road_w | type_w |
|---|
Words
| number | road | type |
|---|
Tags
| 0.87 | 0.90 | 0.96 |
|---|
Probability
Merge
User given expanding rate Tr between 0~1
For example: \(Tr=0.9\)
Words
Probability
merge 567, road_w
because \(0.87<Tr\)
and
\(0.87<0.90\)
Words
| road_w | type_w |
|---|
567 |
road_w |
type_w |
|---|
| 0.87 | 0.90 | 0.96 |
|---|
Round 4
Words
Tags
0.89 |
0.94 |
|---|
Probability
| road_w | type_w |
|---|
road |
type |
|---|
|
road |
road |
type |
|---|
Tags
|
0.89 |
0.89 |
0.94 |
|---|
Probability
\(\times 2\)
\(\times 2\)
get result tags
| road | road | type |
|---|
Tags
| 0.89 | 0.89 | 0.94 |
|---|
Probability
| number | road | type |
|---|
| 0.87 | 0.90 | 0.96 |
|---|
| number | road | number |
|---|
| 0.84 | 0.83 | 0.74 |
|---|
| number | number | number |
|---|
| 0.85 | 0.72 | 0.76 |
|---|
avg
0.776
0.807
0.910
0.907
Reduce Memory
Use Generator
def generator(features, labels, batch_size):
batch_words = np.zeros((batch_size, ...))
batch_tags = np.zeros((batch_size, ...))
while True:
for i in range(batch_size):
# choose random index in Data (but how?)
index = random.choice(DataSize,1)
batch_words[i] = some_processing_1(words[index])
batch_tags[i] = some_processing_2(tags[index])
yield batch_words, batch_tagslinecache
import linecache
linecache.getline(linecache.__file__, 8)Get any line from a file, while attempting to optimize internally, using a cache.
Report
train size = 19356
test size =25808
normal
word2vec
94.950208%
95.810693%
delexicalization
95.539979%
delexicalization
test
90.277966%
92.260949%
delexicalization
92.260949%
delexicalization
test
94.811467%
lexcion
94.669825%
delexicalization
94.628734%
delexicalization
test
train size = 1000
test size =25808
normal
word2vec
47.582906%
delexicalization
79.918302%
delexicalization
test
70.644397%
83.244223%
delexicalization
83.244223%
delexicalization
test
73.698637%
lexcion
85.942183%
delexicalization
85.851784%
delexicalization
test
80.092816%