Aim 3: Posterior Sampling and Uncertainty
September 20, 2022
Problem Statement (refresher)
retrieval of \(x\) is ill-posed
sample \(\hat{x}\) without access to \(p(x)\)
A Brief History on Langevin Dynamics
3. [Kadkhodaie, 21] \(\mathbb{E}[x \mid \tilde{x}] = \tilde{x} + \sigma^2 \nabla_x \log~p(x)\)
0. Langevin diffusion equation
2. [Song, 19 & 21] Noise Conditional Score Networks
4. [Kawar, 21] Stochastic Denoising
Stochastic Denoising With an NCSN
Algorithm 1: Stochastic image denoiser, [Kawar, 21]
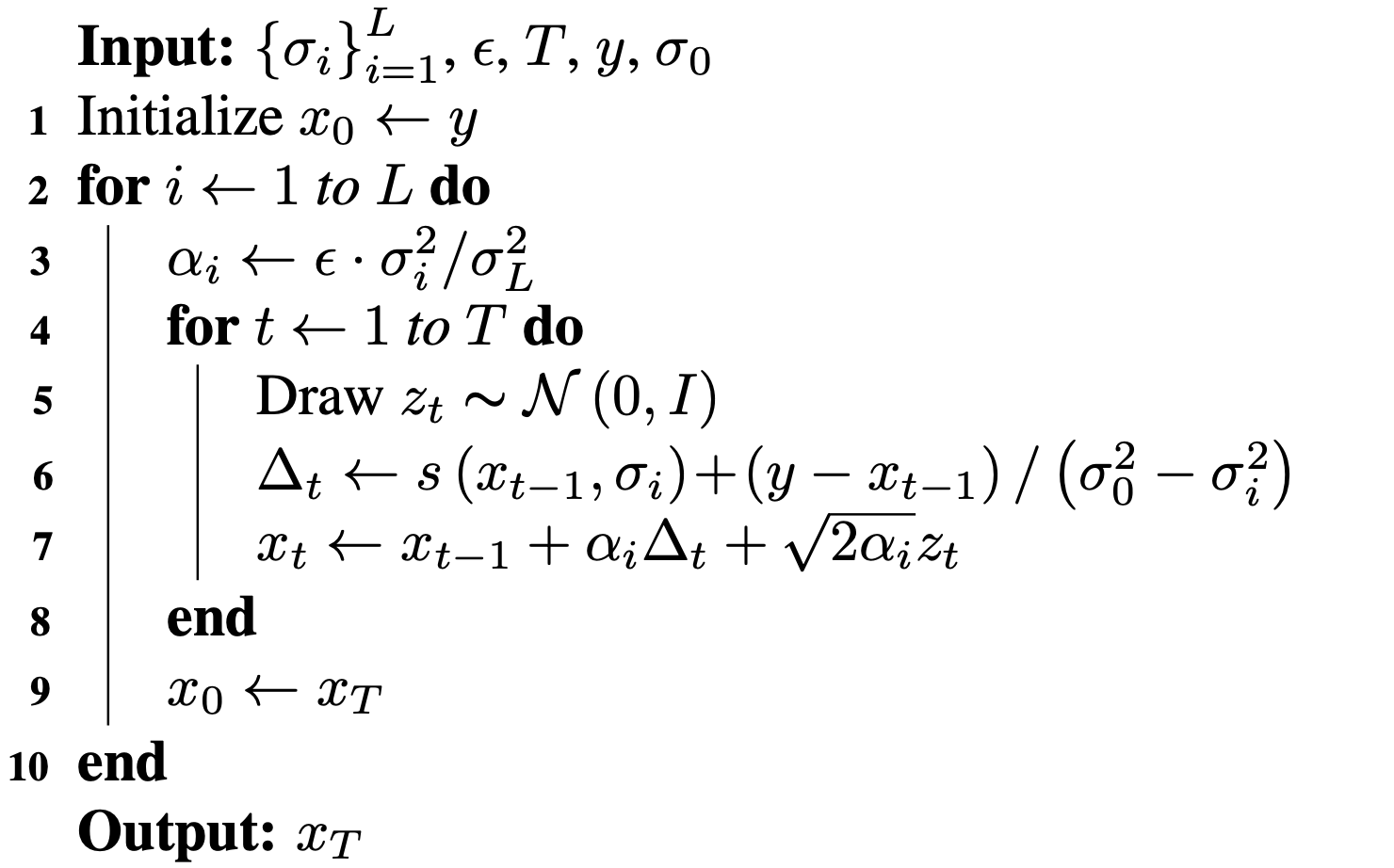
Training an NCSN on Abdomen CT - I

Figure 2: Some example images from the validation split.

Figure 1: Some augmented example images from the training split.
Training an NCSN on Abdomen CT - II
Noise scales: \(\{\sigma_i\}_{i=1}^L,~\sigma_1 > \sigma_2 > ... > \sigma_L = 0.01\)
(from Song, 21)
Hardware: 8 NVIDIA RTX A5000 (24 GB of RAM each)

Preliminary Sampling Results - I
We set \(\epsilon = 1 \times 10^{-6},~T = 3\) in Algorithm 1
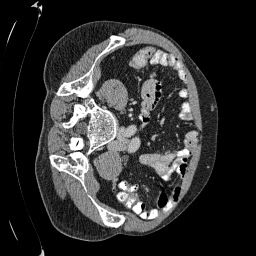
Original
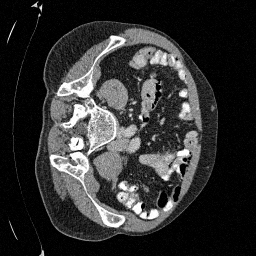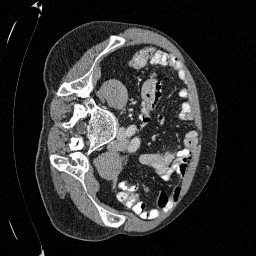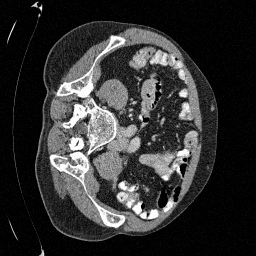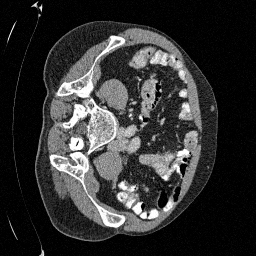
Sampled

\(\sigma_0 = 0.1\)
Perturbed
Preliminary Sampling Results - II
We set \(\epsilon = 1 \times 10^{-6},~T = 3\) in Algorithm 1
Original
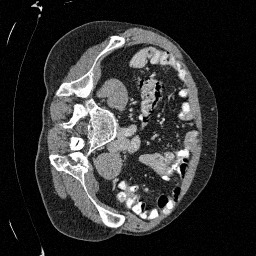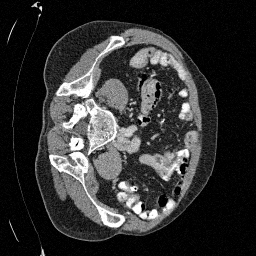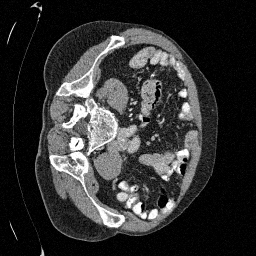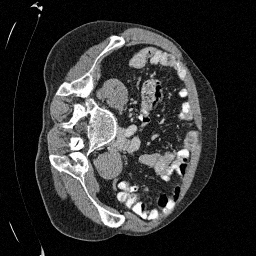
Sampled

\(\sigma_0 = 0.2\)
Perturbed
Preliminary Sampling Results - III
We set \(\epsilon = 1 \times 10^{-6},~T = 3\) in Algorithm 1
Sampled
\(\sigma_0 = 0.1\)
Perturbed
\(\sigma_0 = 0.2\)

\(\sigma_0 = 0.3\)
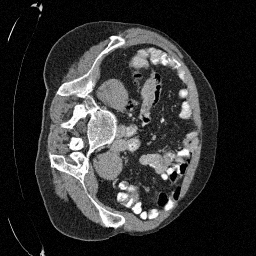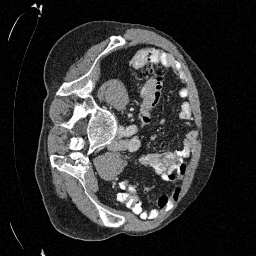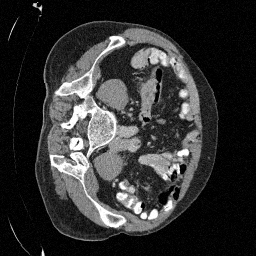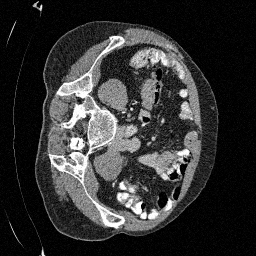

\(\sigma_0 = 0.4\)
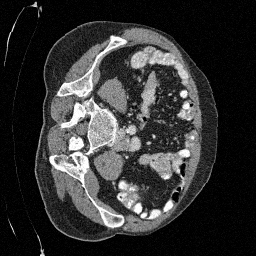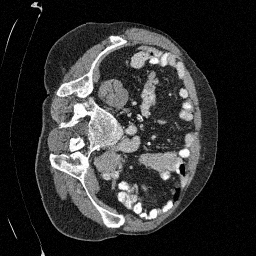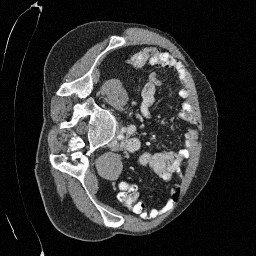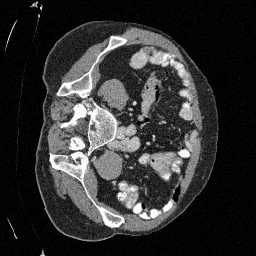
Original
Preliminary Sampling Results - IV
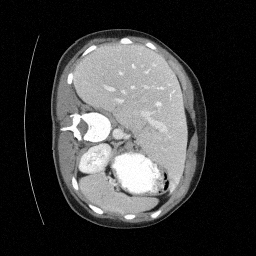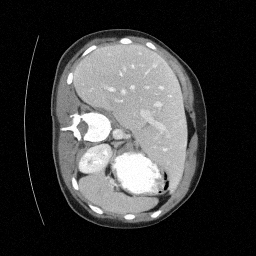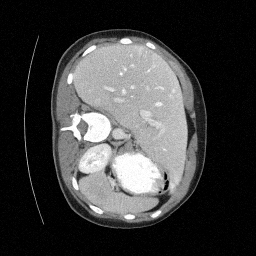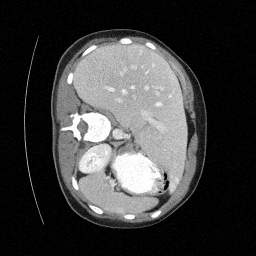
Sampled

Perturbed

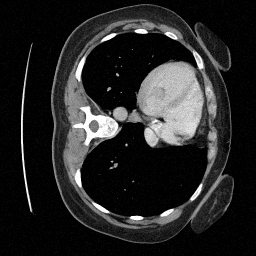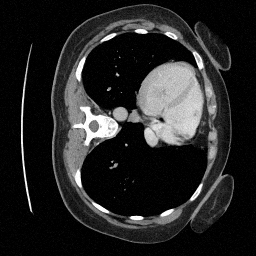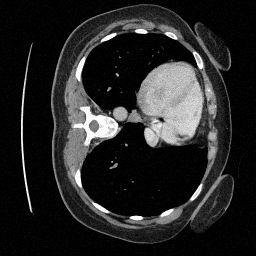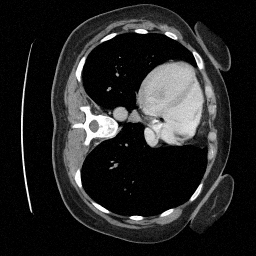

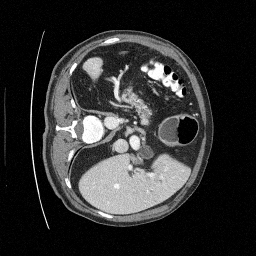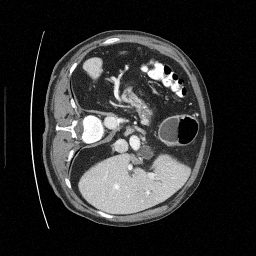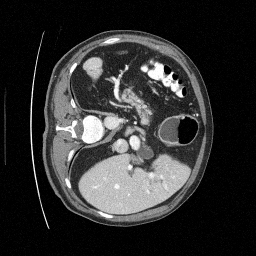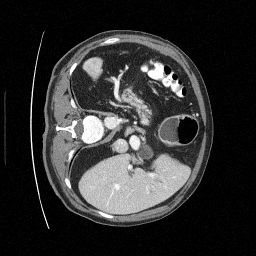

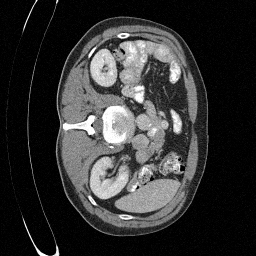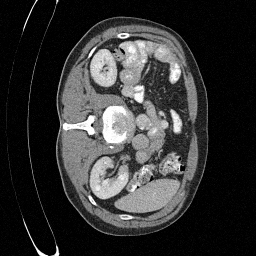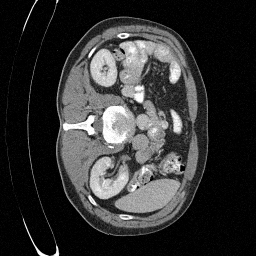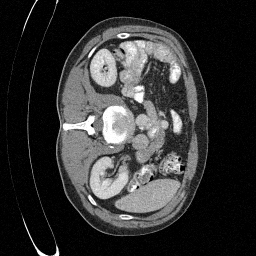
Preliminary Sampling Results - III
We sample \(8\) times for \(128\) validation images


Next Steps: Score SDE
0. Ito process
1. [Anderson, 82] Reverse-time SDE
\(\implies\)
2. [Song, 21] SDE Score Network
Denoising Reverse-time SDE
Denoising Reverse-time SDE
Euler-Maruyama discretization
Next Steps
1. Increase image size to 512 x 512
2. Different noise priors other than Gaussian
3. Use of a pretrained denoiser vs score network
4. Questions?