Scene Text Detection
and
Recognition of Hindi
Guided by:
Dr. Mitesh M. Khapra
Presented by:
Jaya Ingle
Date: 7/5/19
Department of Computer Science and Technology, IIT Madras
- To detect location and size text in the wild.
2. To recognize the text in cropped word image.


सेल्फी
जिला

भारत

Introduction
Challenges involved




Lightening Conditions
Varying orientation
Perspective distortion
Complex background
To solve any machine learning problem, we need
Before going on,
1. Data
2. Model
4. Learning Algorithm
3. Parameters
5. Loss Functions
Specifically in case of Indian languages(Hindi),
1. Data
1. Synthetic Dataset for Text Detection (Shubham's thesis)
2. Synthetic Dataset for Text Recognition(Hindi) (in this work)
So, we have generated artificial (or synthetic dataset) for Indian Languages (Tamil, Telugu, Punjabi, Malayalam, Hindi)

3. For test images, we have manually clicked the pictures and annotate them!







Cropped word dataset generation
Things required:
Hindi Wiki book database
Google fonts
1. Text
2. Font
3. Color of text
4. Background images
5. Rendering method
Discussed on next slide
Freely available on internet
using dictionary of background and foreground colors
Rendering method:
Unlike English, Unicode level information won't be sufficient to render text on image
We need glyphs level information in this case. Before that, we select, text, font, background. With the help of a few rendering libraries of Python, we were able to render text on the image.
we store glyphs and their positions in buffer
Till the buffer did not get empty, we keep rendering the glyphs on the surface and finally rendered surface is converted to the image.
कि
ि
क
will be rendered as
कि
glyphs will be क, ि with ordering between them
कि
Also applied distortion and noise to randomly selected 80% images
To solve any machine learning problem, we need
Before going into literature,
1. Data
2. Model
4. Learning Algorithm
3. Parameters
5. Loss Functions
Specifically in case of Indian languages,
1. Data
2. Model (Detection /Recognition)
Solutions of Text Detection
Regression based solutions
Segmentation based solutions

Groundtruth bounding box
Anchor box
text ?
text ?
Regression-based Model
- EAST: An Efficient and Accurate Scene Text Detector
text score map
Geometry map
rotation angle
left
right
top
bottom
It tries to directly predict word or text line predictions, which are further sent to Non Maximum Suppression (NMS)
Network
Loss
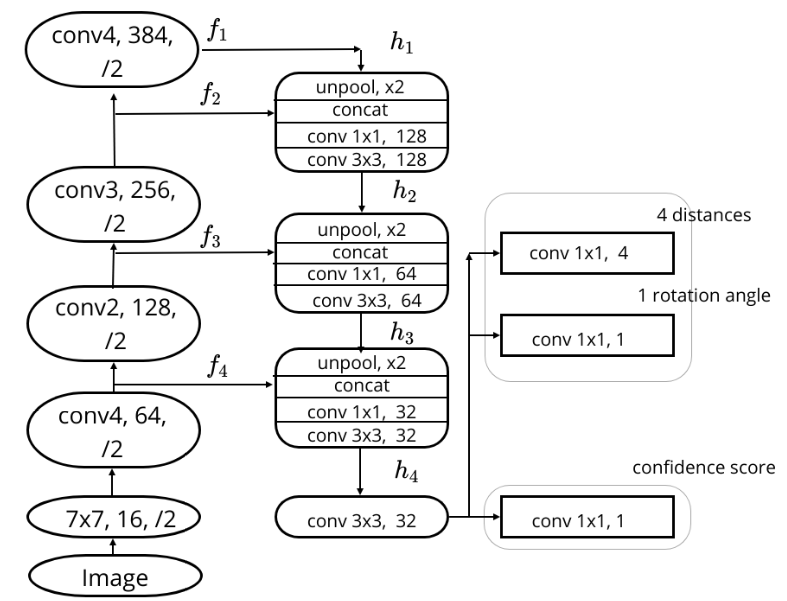
\[ = L_{scoremap} + \lambda_g L_{gemoetry} \]
\[L_{scoremap} \]
= balanced cross entropy between predicted
and ground truth score map
\[L_{geometry} \]
= IoU loss + 1- cos(angle_p, angle_gt)
Results
Implementational details
- 5M synthetic images are used for training
- Batch size = 8, trained for 99k steps
- 2 K80 GPUs with 12 GB memory
- learning rate = 1e-4 (exponential decay)
- Adam optimizer
- Images resized 512 x 512
- 428 images are used for inference
- IoU threshold = 0.4
Training
Testing
| scale | Precision | Recall | F-measure |
|---|---|---|---|
| 512x512 | 0.6445 | 0.4441 | 0.5258 |
| Nearest multiple of 32 | 0.6788 | 0.4045 | 0.5069 |
*with IoU threshold as 0.4
Results
- Due to variations in scale of test images and not so satisfactory results, we finetuned the model on 300 real images
| scale | Precision | Recall | F-measure |
|---|---|---|---|
| 1024x1024 | 0.91100 | 0.68159 | 0.77977 |
| 512x512 | 0.954898 | 0.74334 | 0.83594 |
| 256x256 | 0.9421052 | 0.650121 | 0.76934 |
| nearest multiple of 32 | 0.93323 | 0.76150 | 0.83866 |
*with IoU threshold as 0.4
- We also experimented with different scales




Solutions of Text Detection
Regression based solutions
Segmentation based solutions
Groundtruth bounding box
Anchor box
text ?
text ?
Segmentation based model
- Pixel link
- Every pixel has 8 neighbours.
- If a pixel and one of its neighbours belong to same instance, the link between them will be predicted as positive, else negative.
Unlike regression method, which performs 2 types of tasks,
- Text/non-text prediction.
- location regression.
Here only text/non-text prediction is required. But 2 type of predictions are done:
- Pixel prediction.
- Link prediction.
positive pixel
negative pixel
positive link
negative link
Network
Loss
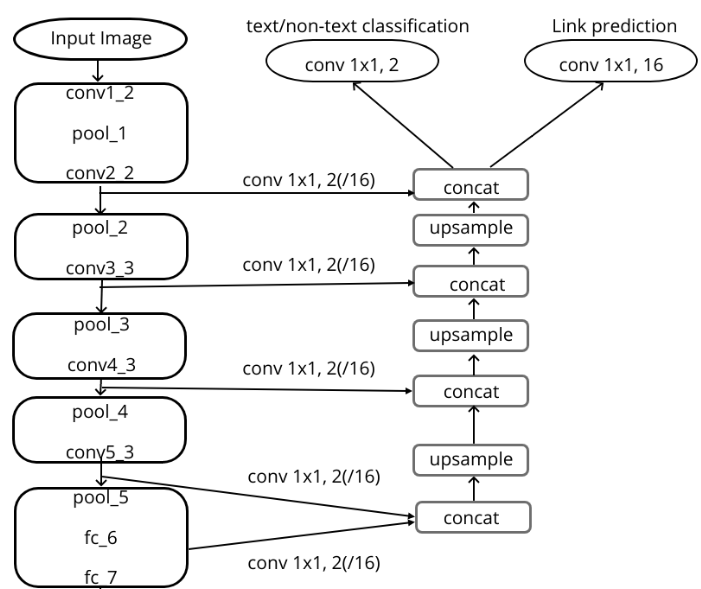
\[ = L_{link} + \lambda L_{pixel} \]
\[L_{link} \]
\[L_{pixel} \]
\[ \lambda \]
= instance balanced cross entropy
= 2
= Cross entropy on link x sum of W for +ve and -ve links
* With base network as VGG-16
Implementational details
Results
- 5M synthetic images are used for training
- Batch size = 8, trained for 99k steps
- 2 K80 GPUs with 12 GB memory
- learning rate = 1e-4 with momentum 0.9
- Images resized 512 x 512
- 428 images are used for inference
- IoU threshold = 0.4
Training
Testing
| Precision | Recall | F-measure |
|---|---|---|
| 0.4393 | 0.4534 | 0.42313 |
IoU threshold=0.4, link and pixel threshold=0.5
| Precision | Recall | F-measure |
|---|---|---|
| 0.52 | 0.5573 | 0.5380 |
After finetuning on 300 real images,
Effect on changing pixel threshold
Effect on changing link threshold
| Thres | Precision | Recall | F-measure |
|---|---|---|---|
| 0.5 | 0.520053 | 0.55730 | 0.53803 |
| 0.6 | 0.53269 | 0.57368 | 0.50153 |
| 0.7 | 0.538461 | 0.58166 | 0.55922 |
| 0.8 | 0.58377 | 0.62893 | 0.60551 |
| 0.9 | 0.57490 | 0.616604 | 0.59433 |
| Thres | Precision | Recall | F-measure |
|---|---|---|---|
| 0.5 | 0.52005 | 0.55730 | 0.53803 |
| 0.6 | 0.58115 | 0.63610 | 0.60738 |
| 0.7 | 0.57657 | 0.64183 | 0.60745 |
| 0.8 | 0.56045 | 0.63753 | 0.59651 |
* link thres=0.5, IoU thres=0.4
* pixel thres=0.8, IoU thres=0.4
Qualitative results



Comparison
EAST
Pixel link


Comparison
EAST
Pixel link


Comparison
EAST
Pixel link


Text Recognition
भारत
Unlike the relation between object detection and text detection, there are significant differences between object recognition and text recognition,
In text recognition, we have to predict the series of labels, that why this problem is posed as a sequence recognition problem.
भ + ा + र + त
Model
Vgg-16 as feature extractor
Map to sequence
BLSTM
BLSTM
Transcription
जिला
per-frame predictions
label sequence
height normalized feature maps
feature maps
input image
Transcription
To solve this a framework known as CTC ( Connectionist Temporal Classification)
- is to find the label sequence with the highest probability conditioned on the per-frame predictions
How to find this conditional probability?
- Since we didn't know the alignment of input and output sequence
- Also, there can be repeated label predicted in output
we need a mapping function which can map from output sequence to label sequence.
- It will first add a special symbol "-" in training symbol set
- In the ground truth label, "-" will be inserted between every distinct letter.
- While decoding, repeated letters between "-" are merged and then "-" are removed.
P(label seq|per-frame prediction)* = sum of P(output seq |per-frame prediction)
Such that the output seq can be mapped to label sequence.
The mapping function will map
ि ि ि-----जजज---लल----ा
जिला
So, the conditional probability will be framed as,
While decoding, we will return the output sequence with highest probability
*In reality, it is difficult to compute so we use forward-backward algorthm
Results
Implementational Details
Training
Testing
- 3M synthetic word images for training, 1M for validation.
- batch size = 32, trained for 63k steps, took 1 day.
- 3 K80 GPUS with 12 GB memory
- lr = 0.001, momentum=0.9
| Mean per char acc | Mean full sequence acc | Mean edit distance |
|---|---|---|
| 0.651006 | 0.419540 | 0.2968 |
- 1740 real images have been used for testing
Total number of labels = 129
[ 128 (according to Unicode representation) + 1 (unknown label) ]
Qualitative Results








अधिनियम
कालोनी
स्वल्पाहार
नित्यानंद
विभागाध्यक्ष
मंगलमय
Mistakes

इटास्पी

इलेक्टनिक्स

अभिवान

इबलिंग
डेन

सर्वशेष्ठ

विशाम

अघिनर्थ

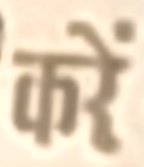
कों

पथम

रकूल

ज

दं

द

सं
Its not only model's mistake!
Distorted images
Conclusion
- A simple model can extract text out of the image, given the image should not be much distorted and the text is correctly written
- The structure of Hindi symbols are complex and can be easily confused with other characters.
Possible future work
- An end-to-end trainable framework for detection and recognition.
- An approach to solve multilingual text detection and recognition.
- A better evaluation metric for text detection, since most of the current metric, is borrowed from object detection and in the object case, if some part is neglected, it won't make much difference.
- A lightweight model, which can easily be incorporated in mobile phones.