The Sentences Commentary Text Archive
Creating and Publishing a Critical Corpus
By Jeffrey C. Witt | @jeffreycwitt | Loyola University Maryland
DLL Meeting, University of Oklahoma
June 25–26, 2015
jcwitt@loyola.edu |http://jeffreycwitt.com
http://scta.info |http://lombardpress.org
An Old Aspiration:
16th Century LinkedData

This 1564 edition is a witness to the fact that early on, medieval Sentences commentaries were understood as part of a larger inter-dependent corpus.
To understand a particular question of Thomas of Strasbourg requires us to understand his discussion in the light of previous discussions.
Our Question
How can we prepare editions today that not only provide basic access to the text, but also allow us to re-use this data to map and visualize multiple categories of inter-textual relationships within a given corpus?
For example: referenced passages, dependent arguments, derivative paragraphs, quotation re-use, parallel discussions, common topics of discussion
Problems with a traditional workflow
1) The workflow produces limited access that pales in comparison to the kind of dissemination made possible through the Internet.
2.) It encourages us to work in isolation to the point that scholars may often be working on the same text and not even know that someone else is working on that text.
3. Texts produced in this manner are incredibly difficult to revise.
4. The static and un-revisable nature of the text discourages the contribution of novices and beginners.
5. The texts produced are not as critical as they could be. For example: they can't produce on demand collations of witnesses, nor facilitate consultation of actual manuscript witnesses.
6. The production of an isolated edition tends to promote "silo-ed" data rather than "linked" data. It makes it extremely hard for us trace the web of connections present in the commentary tradition and leaves us with the kind of piecemeal connections seen in the 16th century edition shown above or in the footnotes of a modern critical edition.
To Repeat
The point is that print-only editions that do not offer us re-usable data, isolate the text from the rest of the corpus, making analysis and comparison of the genre as whole difficult, if not impossible.
Wish List
1. Allow anyone, anywhere, to view any manuscript witness
2. Enable researchers to quickly determine whether or not a transcription has been started.
3. Allow anyone anywhere, novice or expert, to begin transcribing a text, identifying references, connections, and relationships.
4. Immediately and automatically incorporate those transcriptions (in progress or completed) into the larger corpus
5. Allow automated format of a traditional print text with traditional and familiar critical apparatus.
6. Provide one web-viewing platform that can display all transcriptions. Stop the website creation wheel.
7. Allow instant web viewing of transcriptions in draft stage and in print-ready published stage.
8. Allow instant views of manuscript witnesses along side text for comparison and consultation
9. Automatically allow visualization of inter-textual connections alongside text and in indices.
10. Provide automated statistical analysis, customizable to unique queries. Be able to refine queries to time periods or select authors (e.g. Franciscan, Dominican). Be able to restrict queries to different parts of a text (e.g. distinction 1) throughout the entire corpus.
In sum, the goal is to organize transcriptions, editions, and related data in ways that are open and reusable both for intended uses and for those not yet anticipated.
Wishlist Item 1:
ALL witnesses to ALL Sentences commentaries should, in ONE place, be accessible, comparable, navigable and linked to relevant information about the text in question (e.g. status of transcriptions, how to start a transcription, etc).
"Universally Accessible"


"Comparable"
"Universally Accessible and Comparable (Live demo)"
Linked


Navigable
Linked and Navigable (Live Demo)
Wish List Item 2
Enable researchers to quickly determine whether or not a transcription has been started.
Identify the Status of Transcription of Witness

Identify the Status of Transcription of Witness (live demo)
Ascertain Status in a User Friendly Visualization

Ascertain status of a text (live demo)
Allow anyone anywhere, novice or expert, to begin transcribing a text, identifying references, connections, and relationships.
Wish List Item 3
Fork a repository,
then submit a pull request

Example of Code Review and Merge


Easily Review Changes in a Pull Request
Wish List Item 4
Immediately and automatically incorporate those transcriptions (in progress or completed) into the larger corpus.
Once the new repository has been started, it becomes visible in the database.
Here you can see the status of the student's transcription as "draft"


5) Allow automated format of a traditional print text with traditional and familiar critical apparatus
6) Provide one web viewing platform that can display all transcriptions. Stop website creation wheel.
Wish List Items 6 and 7
Using the RDF archive in print production


Avoid the Website Wheel




This can be repeated at the touch of button for every commentary in the database
7) Allow instant digital viewing of transcriptions in draft stage and in print-ready published stage
8) Allow instant views of manuscript witnesses along side text for comparison and consultation
9) Automatically allow visualization of intertextual connections alongside text, in indices, and in statistical graphs.
10) Provide automated statistical analysis, customizable to unique queries. (e.g. chart author frequency or quotation frequency. Limit query to time periods, in select authors (e.g. Franciscan, Dominican). Restrict queries to different parts of a text (e.g. distinction 1, book 1, etc)
Wish List 7, 8, 9, 10






Statistics and Metrics

Statistics and Metrics (live demo)

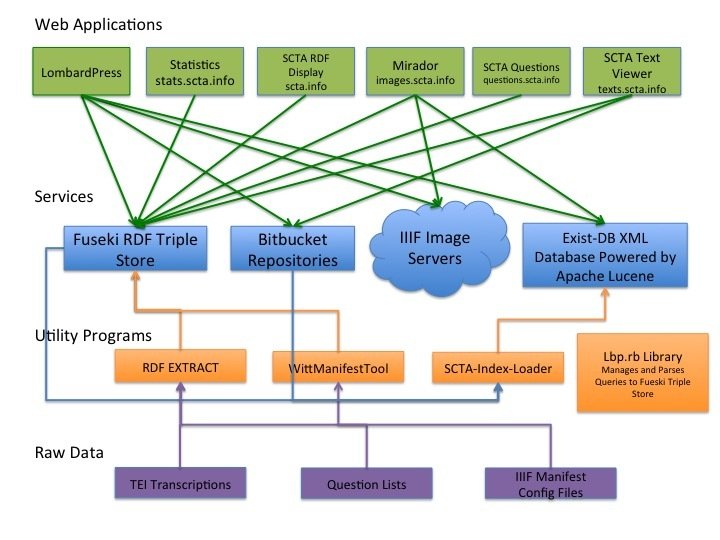
Aspirations
Create a suggested readings algorithm for primary sources
Create a suggested readings algorithm for secondary sources
Challenges and Concerns
- Schema Interoperability
- Semantic versioning standards for TEI texts that clarify a text's relationship to a previous version (i.e. has the text changed? or has the encoding changed? or both?)
- Standards and Guidelines for TEI to RDF mapping.
Questions?