Phi failover
Background
- Phi is now our main source of truth for incident detection and troubleshooting
- Production services rely on phi for metrics 24/7
- Phi is an service built internally so we need to support it
De-risking Phi
SRE laid out the risks Phi is currently subjected to and a mitigation plan for those.
You can view it in detail on confluence https://confluence.condenastint.com/pages/viewpage.action?spaceKey=PLAT&title=Derisking+Phi
Failover mechanism for Phi
- CNAME for fastly syslog endpoint
- Deployment of Phi on prod-eu-central-1
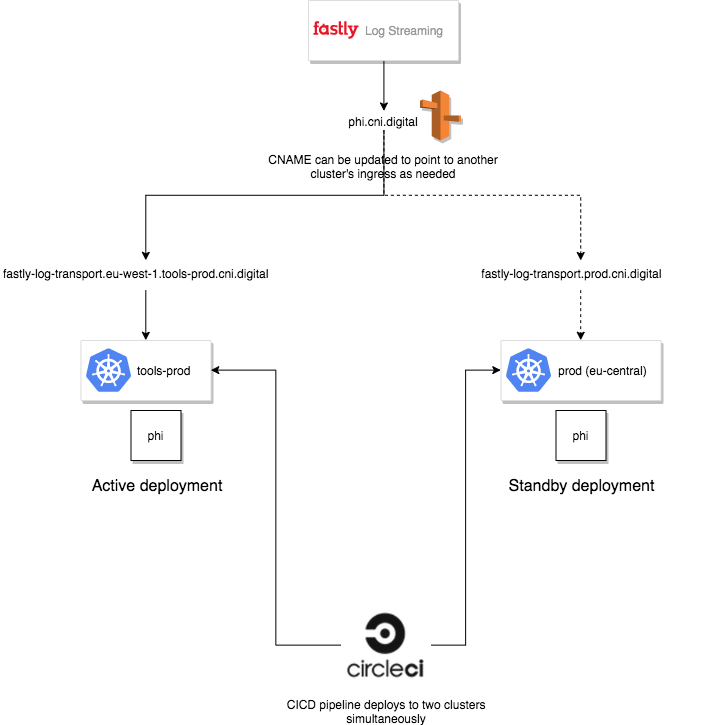
Performing failover
-
Simulate unavailability in tools-prod cluster: Scaled down ingress deploy to 0
-
Switch CNAME value to `fastly-log-transport.prod.cni.digital`
-
Switch CNAME value back to `fastly-log-transport.eu-west-1.tools-prod.cni.digital`
-
Stop connections being sent to prod-eu-central-1 (Scale ingress deploy down and up)
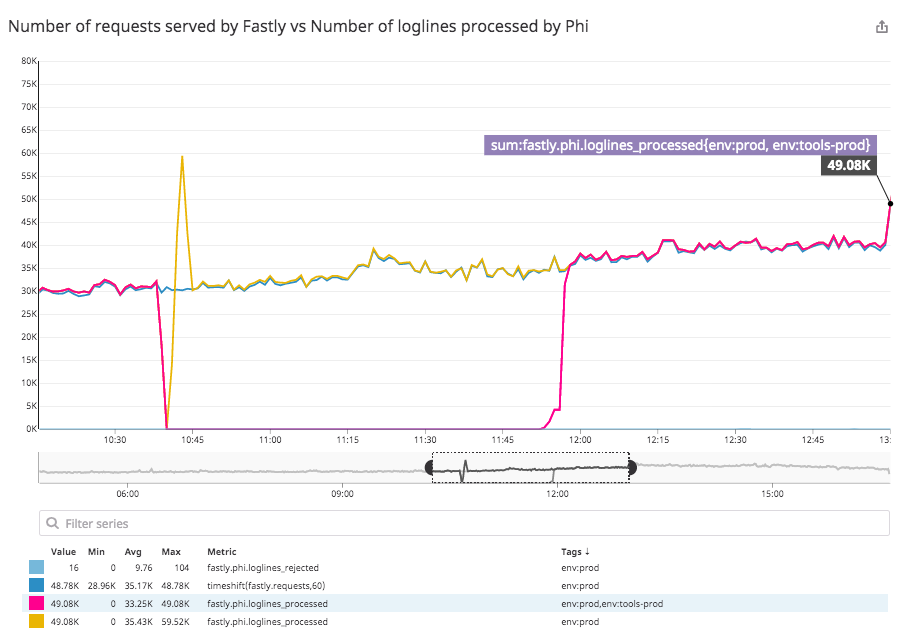
Results
-
10:38 - requests to tools prod dropped straight away as expected
-
It took <3 minutes for Phi to pick up buffered logs from Fastly
-
After another 2 minutes Fastly and Phi were in sync with real time logs/metrics
-
When changing CNAME back to tools-prod endpoint, tools prod started to converge and matched Fastly metrics 100% 1 minute after connections were completely dropped on prod (k8s deploy replicas: 0)
Next step(Backlog):
(Potentially) Failover performed automatically via Route53 health checks