CS110: Principles of Computer Systems
Spring 2021
Instructors Roz Cyrus and Jerry Cain
PDF

Lecture 03: Layering, Naming, and Filesystem Design
- Today, we are going to start discussing the Unix version 6 file system.
- This is a relatively old file system (c. 1975), but it is open source, and was well-designed. Its design is relatively easy to understand
- Your second assignment is an adaptation of this file system
- Modern file systems (particularly for Linux) are, in general, descendants of this file system, but they are more complex and geared towards high performance and fault tolerance. In other words, they aren't the best file systems to learn from as your introduction to file systems. However, because of the beauty of open source, you can dig into the details of many modern file systems (e.g., the ext4 file system, which is the most common Linux file system right now)
- So, for example, when we say that a "sector is 512 bytes" in the introduction that follows, know that this is for the Unix v6 file system, and not a general rule.
- Some key takeaways from studying this file system:
- You're studying a part of computing history.
- You're analyzing a professional-grade abstraction that strongly influenced the construction of subsequent filesystems.
- You're learning details related to a particular file system, but with principles that are used in modern operating systems, too.
- This is not the only way to design a filesystem!
Thanks to Chris Gregg for providing this lovely overview motivating the study of this particular filesystem!
Lecture 03: Layering, Naming, and Filesystem Design
Just like RAM, hard drives (or, more likely these days, solid state drives) provide us with a contiguous stretch of memory where we can store information.
- Information in RAM is byte-addressable: even if you’re only trying to store a boolean (1 bit), you need to read an entire byte (8 bits) to retrieve that boolean from memory, and if you want to flip the boolean, you need to write the entire byte back to memory.
- A similar concept exists in the world of hard drives. Hard drives are divided into sectors (we'll assume 512 bytes), and are sector-addressable: you must read or write an entire sector, even if you’re only interested in a portion of it.
- Sectors are often 512 bytes in size, but not always. The size is determined by the physical drive and might be 1024 or 2048 bytes, or even some larger power of two if the drive is optimized to store a small number of large files (e.g. high definition videos for youtube.com)
- Conceptually, a hard drive might be viewed like this:
Thanks to Ryan Eberhardt for the illustrations and the text used in these slides.

Lecture 03: Layering, Naming, and Filesystem Design
- The drive itself exports an API—a hardware API—that allows us to read a sector into main memory, or update an entire sector on the drive with a new payload.
- In the interest of simplicity, speed, and reliability, the API is intentionally small, and might export a hardware equivalent of the C++ class presented right below.
- This is what the hardware presents us with, and this small amount of information is all you really need in order to start designing basic filesystems. As filesystem designers, we need to figure out a way to take this primitive system and use it to store a user’s files.
class Drive {
public:
size_t getNumSectors() const;
void readSector(size_t num, unsigned char data[]) const;
void writeSector(size_t num, const unsigned char data[]);
};
Lecture 03: Layering, Naming, and Filesystem Design
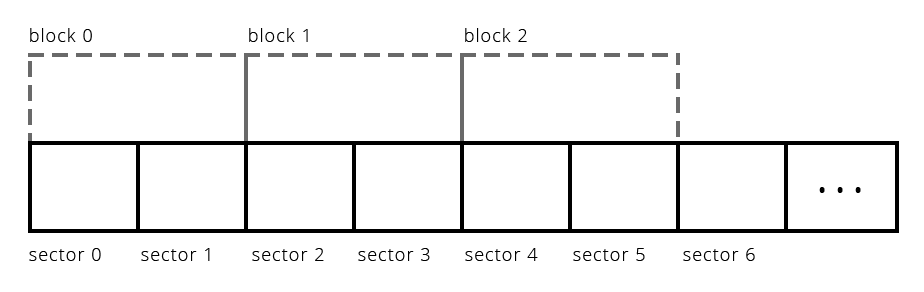
- Throughout the lecture, you may hear me use the term block instead of sector.
Sectors are the physical storage units on the hard drive. - The filesystem, however, generally frames its operations in terms of blocks (which are each comprised of one or more sectors).
- If the filesystem has a block size of 1024 (as below), then when it accesses the filesystem, it will only read or write from the disk in 1024-byte chunks. Reading one block—which can be thought of as a software abstraction over sectors—would be framed in terms of two neighboring sector reads.
- If the block abstraction defines the block size to be the same as the sector size (as the Unix v6 filesystem does), then the terms blocks and sectors can be used interchangeably (and the rest of this slide deck will do precisely that).
Lecture 03: Layering, Naming, and Filesystem Design
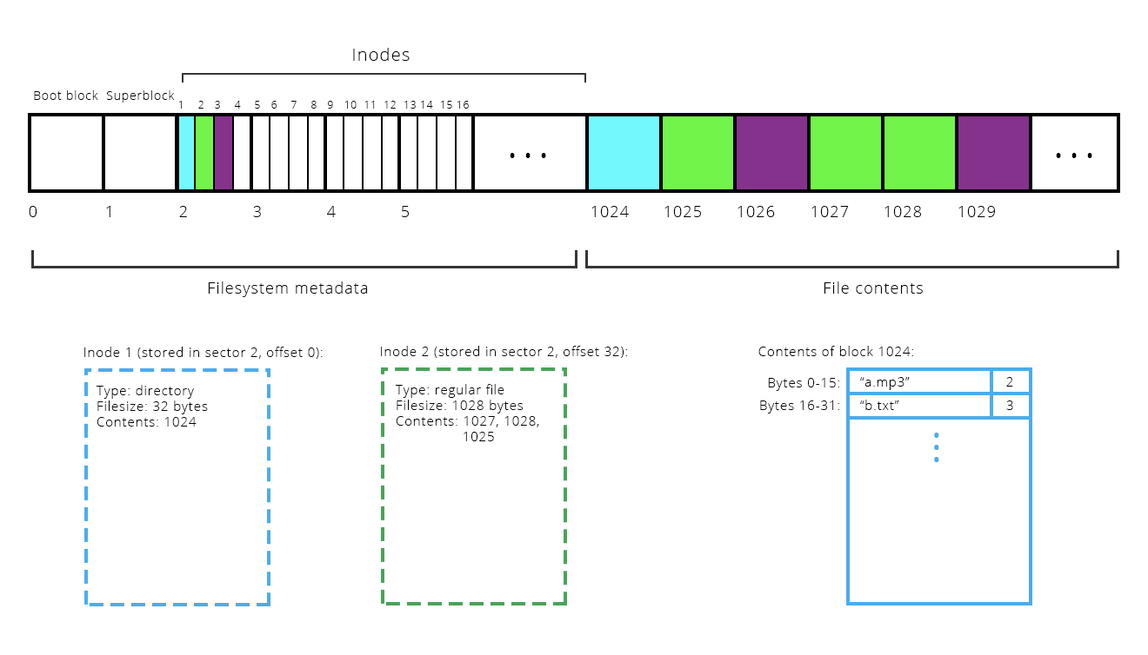
- The diagram below shows how raw hardware could be leveraged to support filesystems as we're familiar with them. There's a lot going on in the diagram below, so we'll use the next several slides to dissect it and let you know what's going on.
- I will provide a high level explanation of how the physical hardware of the drive is accessed and otherwise manipulated.
- We'll dedicate live lecture time to go into the details.
Lecture 03: Design Principles
- CS110 touches on many design principles over the course of the quarter, but let's focus on three relevant to our discussion of file systems!
- Abstraction
- Modularity and Layering
- Naming and Name Resolution
- Abstraction separates behavior from implementation.
poohbear@myth53:/usr/class/cs110$ ls
ARCHIVE.README emails include lib private_data samples tools
cgi-bin final-tests lecture-examples local repos staff WWW
poohbear@myth53:/usr/class/cs110$ ls -1
ARCHIVE.README
cgi-bin
emails
final-tests
include
lecture-examples
lib
local
private_data
repos
samples
staff
tools
WWW
poohbear@myth53:/usr/class/cs110$- Take a look at the result of the linux commands, ls and ls -1.
- How are files stored on the computer?
- If everything is a stored as a 0 or 1, there must be some abstraction that manages the separation between internal representation of files and their external presentation.
- There are an infinite number of ways to store files but the behavior of a file system is well-defined.
Lecture 03: Design Principles
- CS110 touches on many design principles over the course of the quarter, but let's focus on three relevant to our discussion of file systems!
- Abstraction
- Modularity and Layering
-
Naming and Name Resolution
-
What kinds of things does an operating system designer need to think about when designing a filesystem?
- How are the files stored? What is the actual low-level form of the file storage, keeping in mind that all files need to ultimately be reachable?
- What is the relationship between a file's name and its data location?
- Are small files stored differently than large files?
- How are files deleted so that the space doesn't go to waste?
- Can two file names refer to the same file? How?
- Where does file metadata get stored if it, like the files themselves, is to persist?
Lecture 03: Design Principles
- CS110 touches on many design principles over the course of the quarter, but let's focus on three relevant to our discussion of file systems!
- Abstraction
- Modularity and Layering
- Naming and Name Resolution
-
If we go with the -i flag, we gain a little insight into filesystem implementation.
- Recall that each file is associated with a data structure called an inode, as we saw in our illustrations a few slides back. For a computer, it is easier to keep track of a file with a number, but for a human, the textual name is better. The -i flag exposes these ids of those inodes.
- The implementation of our filesystem will define many isolated abstractions that interact with one another through clean, relatively simple interfaces. That's classic modularity.
- There's a special form of modularity referred to as layering. Layering is relevant to filesystem design, because our first software abstraction—we even call it the block layer—layers on top of the the sector abstraction and insulates all other parts of the filesystem from the hardware.
poohbear@myth53:/usr/class/cs110$ ls -i
802561586 ARCHIVE.README 802961215 final-tests 802423769 lib 802423057 repos 802467899 tools
802468377 cgi-bin 802423705 include 802423781 local 802454315 samples 802422787 WWW
802709431 emails 802422993 lecture-examples 802468395 private_data 802454357 staffLecture 03: Design Principles
- CS110 touches on many design principles over the course of the quarter, but let's focus on three relevant to our discussion of file systems!
- Abstraction
- Modularity and Layering
- Naming and Name Resolution
- The distinction between inodes and filenames is an example of naming and name resolution.
- Given a file's name (and, more concretely, its absolute or relative pathname), there has to be code that can figure out what the inode is that is associated with that particular path.
- Today's live lecture will further illustrate how layering, naming, and name resolution influence the design and implementation a filesystem.
- Awesome stuff, I promise.
poohbear@myth53:/usr/class/cs110$ ls -i
802561586 ARCHIVE.README 802961215 final-tests 802423769 lib 802423057 repos 802467899 tools
802468377 cgi-bin 802423705 include 802423781 local 802454315 samples 802422787 WWW
802709431 emails 802422993 lecture-examples 802468395 private_data 802454357 staff