CS110: Principles of Computer Systems

Spring 2021
Instructors Roz Cyrus and Jerry Cain
PDF
Lecture 04: Understanding System Calls
-
System calls (syscalls) are functions that executables rely on to interact with the OS and request some core service be executed on their behalf.
- Examples of system calls we've already seen this quarter:
open,read,write,close,stat, andlstat. We'll see many others in the coming weeks. - Functions like
printf,malloc,fopen, andopendirare not syscalls. They're C library functions that themselves rely on syscalls to get their jobs done.
- Examples of system calls we've already seen this quarter:
- Unlike traditional user functions (the ones we write ourselves,
libcandlibstdc++library functions), system calls need to execute in some privileged mode so they can access data structures, system information, and other OS resources intentionally and necessarily hidden from user code. - The implementation of
open, for instance, needs to access all of the filesystem data structures for existence and permissioning. Filesystem implementation details should be hidden from the user, and permission information should be respected as private. - The information loaded and manipulated by
openmusn’t be visible to the user functions that callopen. Restated, privileged information shouldn't be discoverable. - That means the OS needs a different call and return model for system calls than we have for traditional functions.
Lecture 04: Understanding System Calls
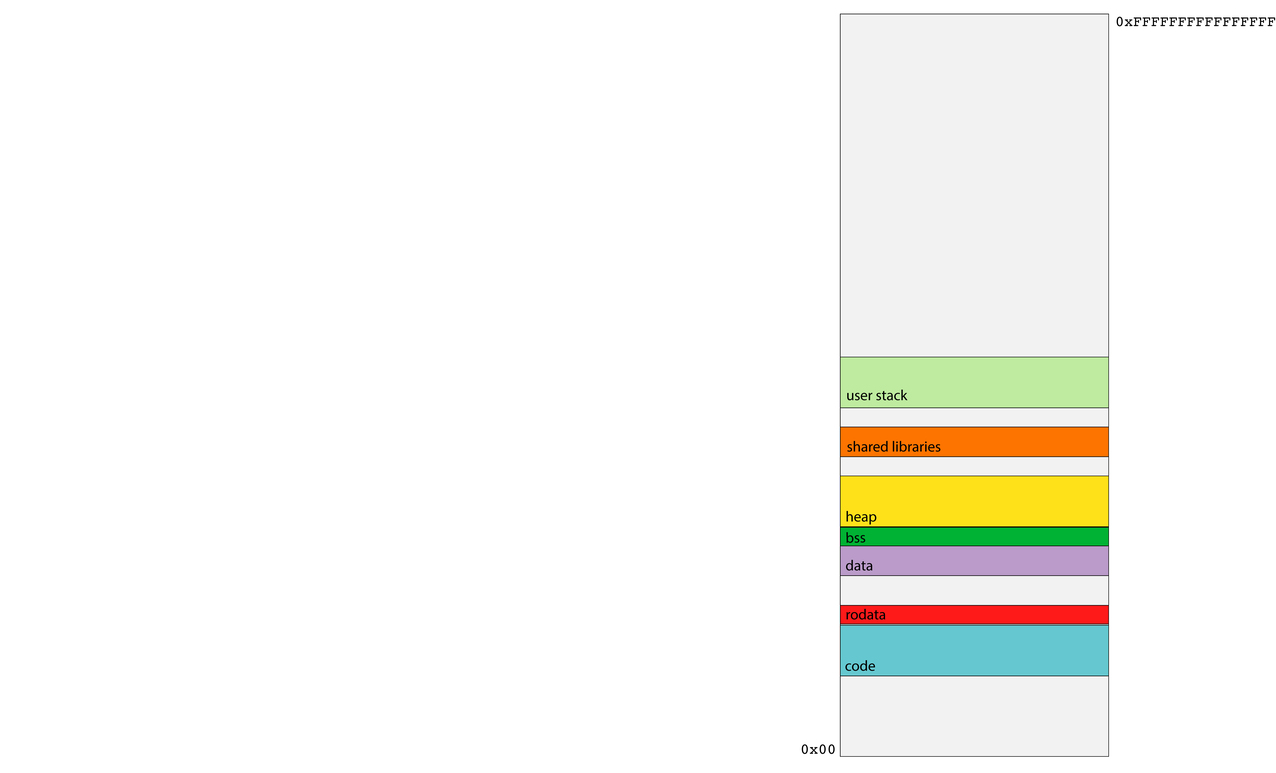
- Recall that each process operates as if it owns all of main memory.
- The diagram on the right presents a 64-bit process's general memory playground that stretches from address 0 up through and including 2^64 - 1.
- CS107 and CS107-like intro-to-architecture courses present the diagram on the right, and discuss how various portions of the address space are cordoned off to manage traditional function call and return, dynamically allocated memory, global data, and machine code storage and execution.
- No process actually uses all 2^64 bytes of its address space. In fact, the vast majority of processes use a miniscule fraction of what they otherwise think they own.
- That means the OS needs a different call and return model for system calls than we have for traditional functions.

Lecture 04: Understanding System Calls
- Recall the code segment stores all of the assembly code instructions specific to your process. The address of the currently executing instruction is stored in the %rip register, and that address is typically drawn from the range of addresses managed by the code segment.
- The data segment intentionally rests directly on top of the code segment, and it houses all of the explicitly initialized global variables that can be modified by the program.
- The heap is a software-managed segment used to support the implementation of
malloc,realloc,free, and their C++ equivalents. It's initially very small, but grows as needed for processes requiring a good amount of dynamically allocated memory. - The user stack segment provides the memory needed to manage user function call and return along with the scratch space needed by function parameters and local variables.

Lecture 04: Understanding System Calls
- There are other relevant segments that haven't been called out in prior classes, or at least not in CS107.
- The rodata segment also stores global variables, but only those which are immutable—i.e. constants. As the runtime isn't supposed to change anything read-only, the segment housing constants can be protected so any attempts to modify it are blocked by the OS.
- The bss segment houses the uninitialized global variables, which are defaulted to be zero (one of the few situations where pure C provides default values).
- The shared library segment links to shared libraries like
libcandlibstdc++with code for routines like C'sprintf, C'smalloc, or C++'sgetline. Shared libraries get their own segment so all processes can trampoline through some glue code—that is, the minimum amount of code necessary—to jump into the one copy of the library code that exists on behalf of all processes.
Lecture 04: Understanding System Calls
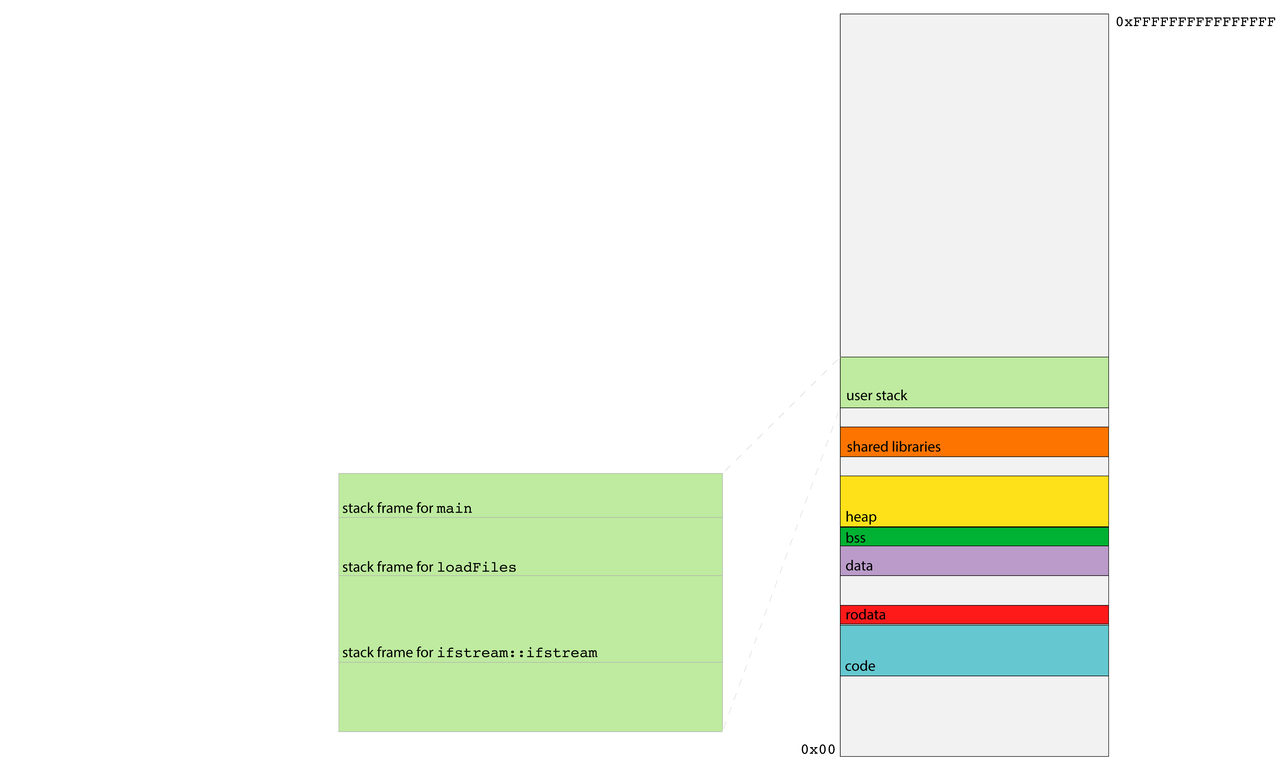
- The user stack maintains a collection of stack frames for the trail of currently executing user functions.
- 64-bit process runtimes rely on
%rspto track the address boundary between the in-use portion of the user stack and the portion that's on deck to be used should the currently executing function invoke a subroutine. - The x86-64 runtime relies on
callqandretqinstructions for user function call and return. - The first six parameters are passed through
%rdi,%rsi,%rdx,%rcx,%r8,
and%r9. The stack
frame is used as
general storage for
partial results that
need to be stored
somewhere other
than a register (e.g.
a seventh incoming parameter)
Lecture 04: Understanding System Calls
- The user function call and return protocol, however, does little to encapsulate and privatize the memory used by a function.
- Consider, for instance, the execution of
loadFilesas per the diagram below. BecauseloadFiles's stack frame is directly below that of its caller, it can use pointer arithmetic to advance beyond its frame and examine—or even update—the stack frame above it. - After
loadFilesreturns,maincould use pointer arithmetic to descend into the ghost ofloadFiles's stack frame and access
dataloadFiles
never intended to
expose. - Functions are
supposed to be
modular, but the
function call and
return protocol's support for modularity and privacy is pretty soft.
Lecture 04: Understanding System Calls
- System calls like
openandstatneed access to OS implementation detail that should not be exposed or otherwise accessible to the user program. - That means the activation records for system calls need to be stored in a region of memory that users can't touch, and the system call implementations need to be executed in a privileged, superuser mode so that it has access to information and resources that traditional functions shouldn't have.
- The upper half of a process's address space is kernel space, and none of it is visible to traditional user code.
- Housed within kernel space is a kernel stack segment, itself used to organize stack frames for system calls.
-
callqis used for user function call, butcallqwould dereference a function pointer we're not permitted to dereference, since it resides in kernel space. - We need a different call and return model for system calls—one that doesn't rely on
callq.

Lecture 04: Understanding System Calls
- The relevant opcode is placed in
%rax. Each system call has its own opcode (e.g. 0 forread, 1 forwrite, 2 foropen, 3 forclose, 4 forstat, and so forth). - The system call arguments—there are at most 6—are evaluated and placed in
%rdi,%rsi,%rdx,%r10,%r8,
and%r9. Note the fourth parameter is%r10, not%rcx. - The system issues a software interrupt (also known as a trap) by executing
syscall, which prompts an interrupt handler to execute in superuser mode. - The interrupt handler builds a frame in the kernel stack, executes the relevant code, places any return value in
%rax, and then executesiretqto return from the interrupt handler, revert from superuser mode, and execute the instruction following thesyscall. - If
%raxis negative,errnois set to abs(%rax) and%raxis updated to contain a -1. If%raxis nonnegative, it's left as is. The value in%raxis then extracted by
the caller as any return value would be.
Lecture 04: Creating and Coordinating Processes
- Until now, we have been studying how programs interact with hardware, and now we are going to start investigating how programs interact with the operating system.
- In the CS curriculum so far, your programs have operated as a single process, meaning, basically, that one program was running your code, line-for-line. The operating system made it look like your program was the only thing running, and that was that.
- Now, we are going to move into the realm of multiprocessing, where you control more than one process at a time with your programs. You will tell the OS, "do these things concurrently", and it will.
Lecture 04: Creating and Coordinating Processes
-
New system call:
fork- Here's a simple program that knows how to spawn new processes. It uses system calls named
fork,getpid, andgetppid. The full program can be viewed right here.
- Here's the output of two consecutive runs of the above program.
- Here's a simple program that knows how to spawn new processes. It uses system calls named
int main(int argc, char *argv[]) {
printf("Greetings from process %d! (parent %d)\n", getpid(), getppid());
pid_t pid = fork();
assert(pid >= 0);
printf("Bye-bye from process %d! (parent %d)\n", getpid(), getppid());
return 0;
}
myth60$ ./basic-fork
Greetings from process 29686! (parent 29351)
Bye-bye from process 29686! (parent 29351)
Bye-bye from process 29687! (parent 29686)
myth60$ ./basic-fork
Greetings from process 29688! (parent 29351)
Bye-bye from process 29688! (parent 29351)
Bye-bye from process 29689! (parent 29688)Lecture 04: Creating and Coordinating Processes
-
forkis called once, but it returns twice.-
getpidandgetppidreturn the process id of the caller and the process id of the caller's parent, respectively. - As a result, the output of our program is the output of two processes.
- We should expect to see a single greeting but two separate bye-byes.
- Each bye-bye is inserted into the console by two different processes. The OS's process scheduler dictates whether the child or the parent gets to print its bye-bye first.
-
forkknows how to clone the calling process, synthesize a nearly identical copy of it, and schedule the copy to run as if it’s been running all along.- Think of it as a form of process mitosis, where one process becomes twins.
- All segments (data, bss, init, stack, heap, text) are faithfully replicated to form an independent, protected virtual address space.
- All open descriptors are replicated, and these copies are donated to the clone.
-
Lecture 04: Creating and Coordinating Processes
- Here's why the program output makes sense:
- Process ids are generally assigned consecutively. That's why 29686 and 29687 are relevant to the first run, and why 29688 and 29689 are relevant to the second.
- The 29351 is the pid of the terminal itself, and you can see that the initial
basic-forkprocesses—with pids of 29686 and 29688—are direct child processes of the terminal. The output tells us so. - The clones of the originals are assigned pids of 29687 and 29689, and the output is clear about the parent-child relationship between 29686 and 29687, and then again between 29688 and 29689.
- Differences between parent calling
forkand child generated by it:- The most obvious difference is that each gets its own process id. That's important. Otherwise, the OS can't tell them apart.
- Another key difference:
fork's return value in the two processes- When
forkreturns in the parent process, it returns the pid of the new child. - When
forkreturns in the child process, it returns 0. That isn't to say the child's pid is 0, but rather thatforkelects to return a 0 as a way of allowing the child to easily self-identify as the child. - The return value can be used to dispatch each of the two processes in a different direction (although in this introductory example, we don't do that).
- When
Lecture 04: Creating and Coordinating Processes
- You might be asking yourself, How do I debug two processes at once? This is a very good question!
gdbhas built-in support for debugging multiple processes, as follows:-
set detach-on-fork off- This tells
gdbto capture allfork'd processes, though it pauses each atfork.
- This tells
-
info inferiors- This lists the all of the processes that
gdbhas captured.
- This lists the all of the processes that
-
inferior X- Switch to a different process.
-
detach inferior X- Tell
gdbto stop watching the process before continuing it
- Tell
- You can see an entire debugging session on the
basic-forkprogram right here.
-
Lecture 04: Creating and Coordinating Processes
-
forkso far:-
forkis a system call that creates a near duplicate of the current process. - In the parent process, the return value of
forkis the child'spid, and in the child, the return value is 0. This enables both the parent and the child to determine which process they are. -
All data segments are replicated. Aside from checking the return value of
fork, there is virtually no difference in the two processes, and they both continue afterforkas if they were the original process. - There is no default sharing of data between the two processes, though the parent process can
wait(more next time) for child processes to complete. - You can use shared memory to communicate between processes, but this must be explicitly set up before making
forkcalls. More on that in discussion section.
-