准备工作
-
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.2.3
-
调整你的docker daemon memory limit to 6gb
-
git clone git@git.realestate.com.au:cheng-li/elasticsearch-demo.git
-
安装chrome插件-postman
-
在postman里import collection with link - https://www.getpostman.com/collections/b1d7e094d1d4c5af79ee
In SCOPE
- 核心概念
- 系统原理
- 功能展示
OUT SCOPE
- API细则
- 配置细则
- 详细的DSL
- 性能优化
"elasticsearch"
WHAT is it?
分布式
搜索引擎
数据库
lucene
开源
日志分析
我是搜索引擎
lucene与elasticsearch的前世今生
lucene是最先进功能最强大的搜索库
- 基于目录/文件结构的存储
- 非分布式
- 复杂的API
- 用java开发
- 使用者需要熟悉检索原理(各种索引结构)
elasticsearch是构建在LUCENE上的高级应用
-
封装成为service并提供RESTful API
-
NoSQL数据库风格的存储方式
-
提供分布式支持
- 提供强大且易用的DSL
核心概念
- 索引(index)
- 类型与映射(type&mapping)
- 文档(document)
- 分片(shard)
什么是(反向)索引表
| Term | Document # | Frequence | Position |
|---|---|---|---|
| Crazy | 1,2 | [2],[1] | [3,10],[1] |
| World | 3 | [1] | [5] |
| Hello | 3 | [4] | [1],[20],[55],[100] |
elasticsearch中的索引是什么
ES6.0之前按照elastic的官方描述,索引可以类比成关系数据库中的数据库。。。
反向索引表
类型映射
文
档
文
档
文
档
创建索引和获取索引
elasticsearch中的类型与映射是什么?
ES6.0之前, 按照elastic的官方描述,类型可以类比成关系数据库中的表,映射可以类比成表的schema
ES6.0之后, elastic官方已经修正了类型类比成数据库的说法
反向索引表
类型映射
文
档
文
档
类型映射
文
档
文
档
映射
ELASTICSEARCH中的映射主要描述了3个信息
- 文档中字段的数据类型(string,date,number)
- 文档中字段如何被索引
- 文档中的字段如何被检索
映射的组成
一个mapping由一个或多个analyzer组成, 一个analyzer又由一个或多个filter组成的。当ES索引文档的时候,它把字段中的内容传递给相应的analyzer,analyzer再传递给各自的filters。
POST /chathistories/messages
{
"content": "A Pretty cool guy!",
"date": "2018-04-18"
}{
"chathistories": {
"mappings": {
"messages": {
"properties": {
"content": {
"type": "text",
"analyzer": "standard_analyzer"
}
}
}
}
}
}
Standard Analyzer
Standard Token Filter
A Pretty cool guy!"
["Pretty", "cool", "guy"]
Lower Case Filter
["pretty", "cool", "guy"]

1
2
3
4
5
创建和获取mapping
elasticsearch中的文档就是j son
存储,检索以及分析的基本单位
可以类比成关系型数据库中的row/record/记录
创建和检索文档
elasticsearch的分片是什么
- 分片是最小级别的工作单元(worker unit)
- 每一个分片都是一个Lucene实例,其本身就是一个完整的搜索引擎
- 每一个分片上只保存所有索引中的部分数据
- 分片分为主分片和备份分片
- 分片是集群节点分发,转移数据的最小单位
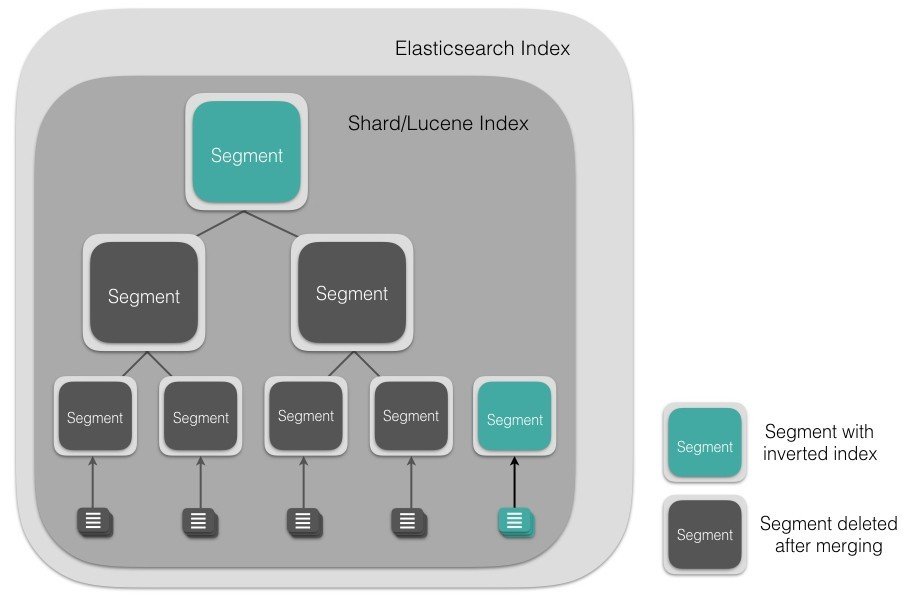
Mappings
回过头来再看下真实的ES INDEX
查看分片分配情况
我是分布式系统
es作为一个分布式系统需要具备哪些特性?
-
结点发现与选举
- 数据弥散
- 冗余与故障转移
- 路由
- 结点交互与数据同步
自动发现(discovery)
在ELASTICSEARCH中默认使用ZEN DISCOVERY作为发现模块,并提供单播及多播2种模式
当有新的结点准备就绪时,这个新结点应该可以加入到cluster并被其他结点发现。
当有结点出现故障,自动发现机制会从cluster移除这个结点并且通知其他结点不要在和这个结点通讯。
单播
单播配置下,可以通过提供一个主机列表作为路由列表,向指定的主机发送单播请求,配置如下:
discovery.zen.ping.unicast.hosts:["IP1:PORT1","IP2:PORT2"]zen的单播基于gossip算法
Gossip算法如其名,灵感来自办公室八卦,只要一个人八卦一下,在有限的时间内所有的人都会知道该八卦的信息,这种方式也与病毒传播类似,因此Gossip有众多的别名“闲话算法”、“疫情传播算法”、“病毒感染算法”、“谣言传播算法”。
多播
当新的结点就绪时,它会发送一个多播的ping请求到网段中,该请求只是用来通知所有能连接到节点和集群它已经准备好加入到集群中。
discovery.zen.ping.multicast.group: 224.2.2.4
discovery.zen.ping.multicast.port:54328
discovery.zen.ping.multicast.ttl:3
discovery.zen.ping.multicast.enabled:true节点类型
- master node
- data node
- client node/coordinating node
在Elasticsearch的集群中
所有的节点都:
- 能够和集群中所有的节点通讯
- 知道哪个节点存有哪些分片
- 能够接受客户端的请求
那么要master干嘛?
master选举与脑裂
故障发现
一般存在两个故障检测过程。第一个是主节点周期性的ping其他节点。第二就是其他节点周期的ping主节点。
数据弥散
分片(SHARD)是数据弥散的单位,当有新的结点加入时,SHARD会flat的弥散到各个结点
Node 1
Shard 1
Shard 2
Shard 3
Node 1
Node 2
Shard 1
Shard 3
Shard 2
Node 1
Node 2
Shard 1
Shard 2
Node 3
Shard 3
冗余与故障转移
ELASTICSEARCH的冗余是通过复制分片来实现的,一个主分片可以有多分复制分片。你可以在创建索引的时候设定主分片和复制分片的数量。注意:在索引被创建后主分片的数量不可以再更改,但是复制分片的数量还可以更改。
PUT http://localhost:9200/webstore/
{
"settings": {
"index": {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
}note: 同一个数据分片的主分片与复制分片不会被分配到同一个node上
Node 1
P0
P1
Node 2
R0
R2
Node 3
P2
R1
Node 1
P0
R0
故障转移
Node 2
R0
R2
Node 3
P2
R1
Node 1
P0
P1
Node 2
P0
R2
Node 3
P2
P1
故障恢复
Node 1
R0
R1
Node 2
P0
R2
Node 3
P2
P1
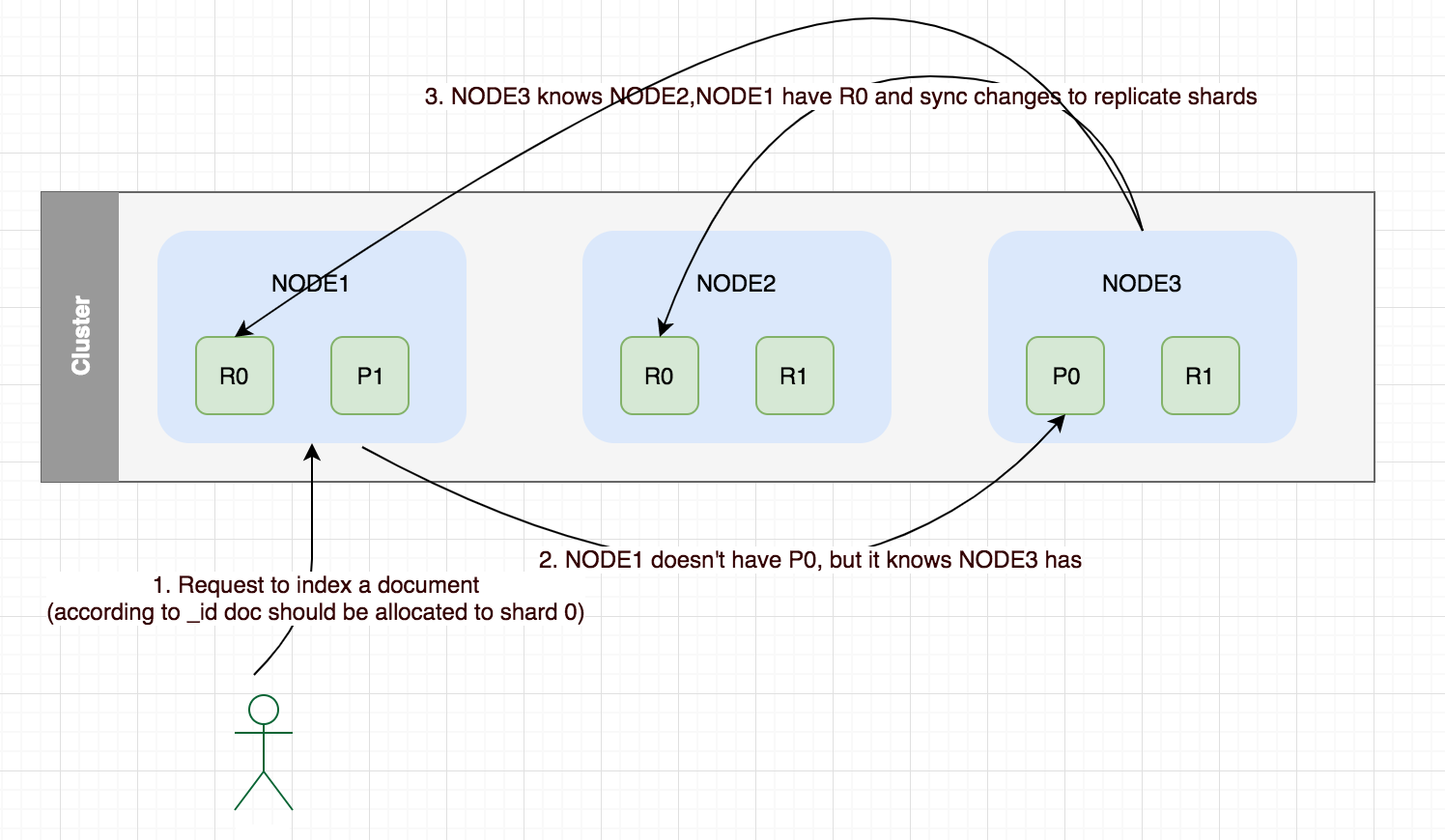
如何路由到数据分片
当你索引一个文档的时候,文档会被ELASTICSEARCH存放在单一主分片中, 然而ELASTICSEARCH如何决定应该将文档存放在哪个分片中呢?当你利用好路由功能,你可以大大加速你的检索速度,因为你不必要遍历所有的分片去检索你需要的文档。
SHARD_idx=hash(routing)%num_of_primary_shards
路由公式
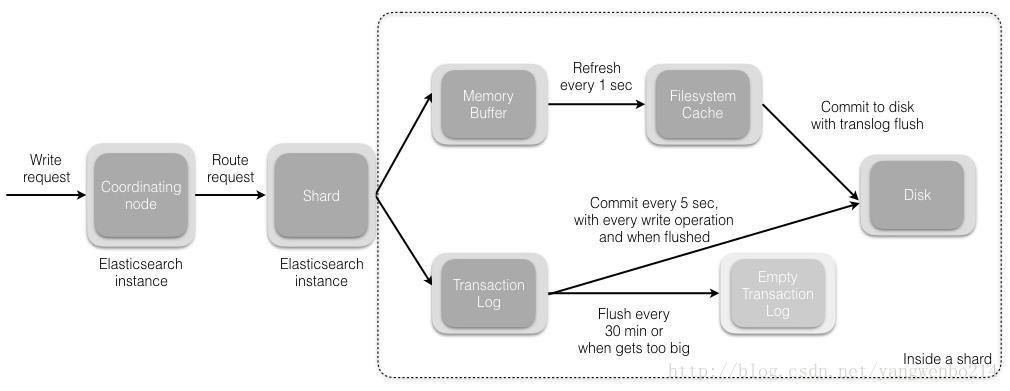
节点的交互和同步
新建,索引,删除文档
检索文档
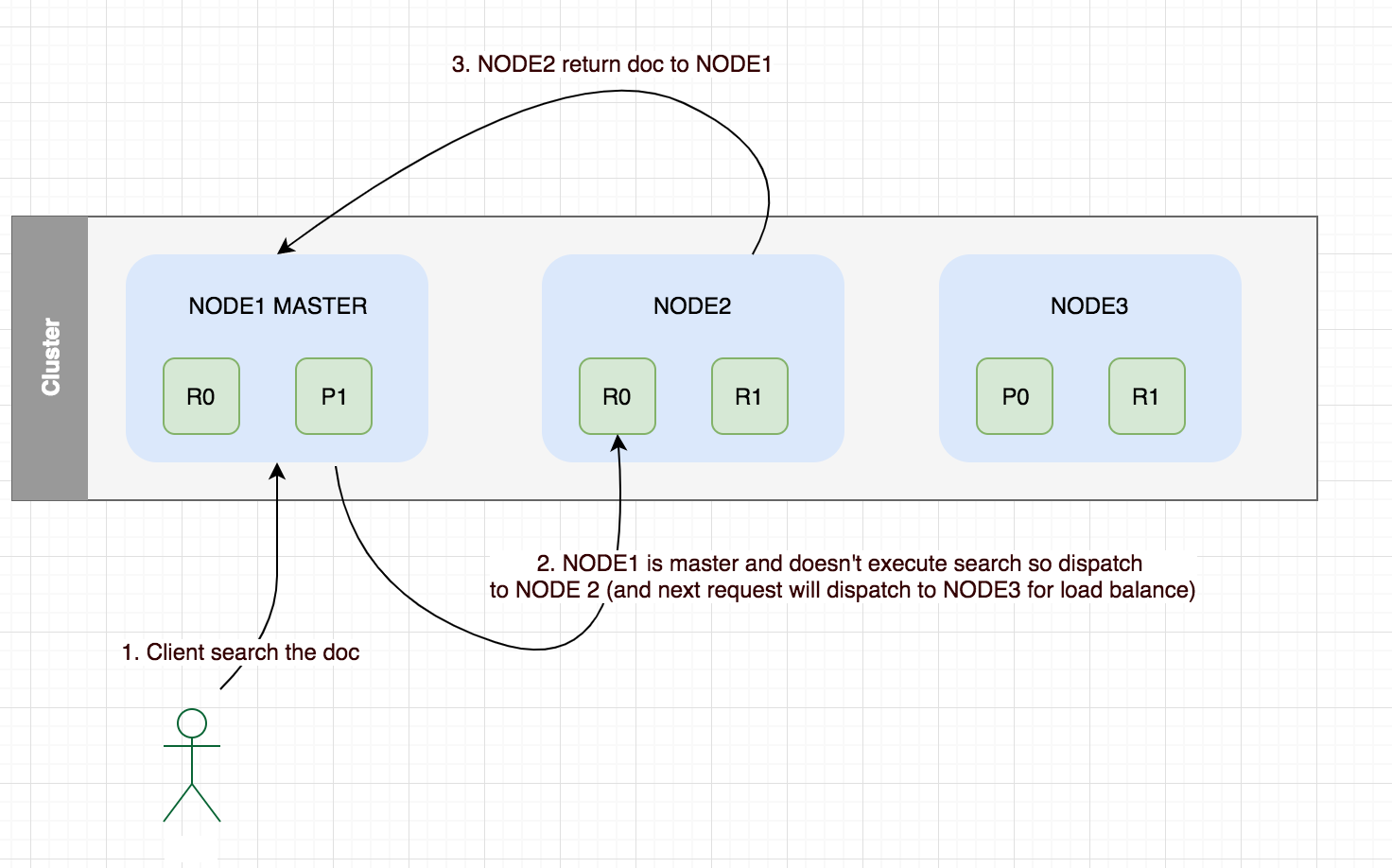

我是数据库
ELASTICSEARCH vs SQL DB
-
乐观并发控制 VS 悲观并发控制
- DSL vs SQL
- 最终一致性 vs 强一致性
- 大数据 vs 不是那么大的数据
- 全文检索 vs SQL语句
- 分词检索 vs SQL语句
ELASTICSEARCH vs mongodb
-
全文检索
- 分词检索
- 基于匹配度的排序
- 版本控制
我是日志容器

