How combinatorial solvers generate proofs
or: "A thousand ways of learning"
Disclaimers
- New presentation
- First part is totally not complete
- Literature for first part is "on request"
- Little expertise in MIP or SMT
Content
- First part: abstracting solving technologies
- Second part: connecting IntSat, CutSat, cdcl-cuttingplanes*
Part 1:
abstracting solving technology
(my) logic background
- CNF
- clause
- assignment
- satisfying assignment
- Theory T
- Formula φ
- Structure α
- Model M
- Constraint program, mixed integer program, answer set program ...
- constraint, linear inequality, rule ...
- valuation, fact list ...
- (feasible) solution ...
- Logical consequence: T ⊨ φ
- learned clause, valid cut, propagation, ground formula, derived lemma in proof ...
Abstracting solvers
Input: theory T
Output: sat (+ model) / unsat (+ proof; reason)
Search: incrementally refine partial structure α
Learn: extend T with φ s.t. T ⊨ φ
Propagation: derive ψ s.t. T ∪ α ⊨ ψ
and ψ forces refinement of α
Conflict: T ∪ α ⊨ ψ and T ∪ α ⊨ ¬ψ
Backjump: weaken α by analyzing φ
Why learn?
"Search language"
- check consistency of φ in α
- check which refinements φ enforces on α
- analyze φ for backjump
- combine φ and φ' to valid formula φ''
- ...
Typical search language is simple.
Learning allows to introduce complex concepts
as a set of simple formulas in the search state.
CDCL
Input: CNF theory T
Search: assign true/false to literals
Learn: extend T with resolvent φ of clauses in T
Propagation: unit clauses ψ under α in T trigger refinement of α
Conflict: for each literal l in a conflict clause,
T ∪ α ⊨ ¬l
Backjump: undo literal assignments until 1UIP learned clause is no longer conflicting
Input: logic program T
Grounding: transform T into equivalent CNF T'
Search, Learn, Propagation, Conflict, Backjump:
as in CDCL
Answer Set Programming *
Ground-and-solve
Constraint Programming
Input: rich set of constraints T
Flatten: transform T into equivalent "quantor-free" T'
Search: simple bounds on variables in T'
Propagation: unit propagation, backed by a clause c s.t. φ ⊨ c for some formula φ in T'
Conflict, Learn, Backjump: as in CDCL
Lazy clause generation
Input: rich set of constraints T
Search: simple bounds on variables in T
Lazy grounding: transformation of φ into "quantor-free" φ' triggered by α
Propagation: unit propagation, backed by a clause c s.t. φ' ⊨ c
Conflict, Learning, Backjump: as in CDCL
Lazy grounding
IDP
SAT Modulo Theories
Input: set of rich theories T1, T2, ... connected to T0 (CNF)
Search: Boolean decisions on T0
Grounding:
- Skolemization: ∃x: φ(x) transforms to φ(Ski)
- Pattern-based instantiation: Ɐx: φ(x) ⊨ φ(C)
Propagation: theory-specific (e.g. Gaussian reasoning), but backed by a clause c s.t. Ti ⊨ c
Conflict, Learning, Backjump: as in CDCL
Input: linear inequalities (cuts) over ℚ and ℤ
objective function O
search: variable splitting tree,
tracking lower and upper bound wrt O
Learn special types of cuts:
- cover cut
- Gomory fractional cut
- ...
Mixed Integer Programming *
Branch-and-bound
Cover cut:
given
s.t.
derive
Gomory cut
Rounding of fractional solution
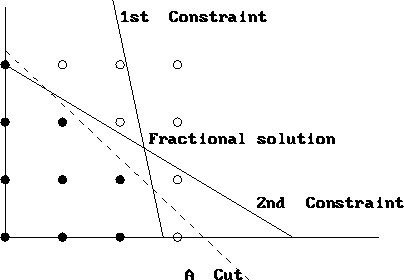
Is this "conflict learning"?
Symmetric Explanation Learning
Input: T, symmetry group Σ of T
Propagation: triggers symmetric learning
- learn σ(φ) for each "asserting" φ, generator σ of Σ
- if σ(φ) propagates or is conflicting, learn σ(φ)
- else forget σ(φ) when φ is no longer asserting
Learn often, forget often!
Closing thoughts
- Techniques are moving closer together
- "Mainly differ" in what / when they learn
- Main divide: SAT-based vs MIP-based?
- Logic vs Arithmetic
- What about local search / metaheuristics?
- Does CPLEX simulate a cutting plane proof system?
- Where are the polynomial calculus (PC) systems?
- Even though PC is better understood theoretically!
Part 2:
On IntSat & CutSat
IntSat
- "The IntSat Method for Integer Linear Programming"
- 2014 - Robert Nieuwenhuis (Barcelogic SMT solver)
- Input: theory of linear inequalities over ℤ
Goal: combine search and CP proof
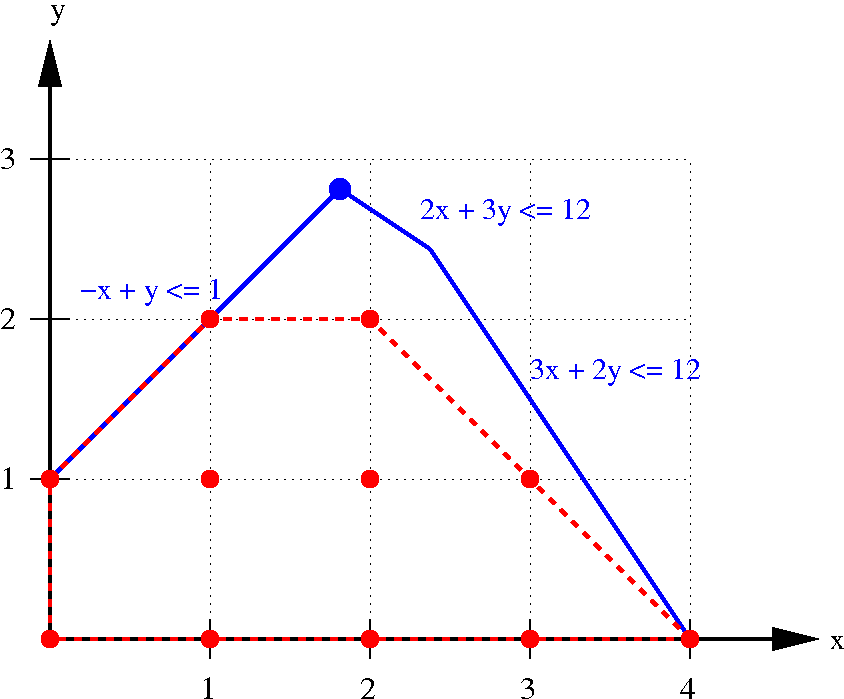
IntSat
Not always possible to derive unsat cut from conflict:
Theory:
Decisions:
Propagations:
"Resolvent":
IntSat
Linear theory is always convex!
IntSat
3D example!
IntSat
Solution: mix resolution and CP proof system
Learned cut:
Learned clause:
* learned clause is forgotten after backjump over its level
CutSat
- "Cutting to the Chase"
- 2011 - Jovanović, De Moura (Microsoft, Z3 SMT solver)
- Input: theory of linear inequalities over ℤ
Goal: combine search and CP proof
CutSat
Decide only extremal bounds!
Theory:
Decisions:
with bounded variables:
Same conflict...
CutSat
Weaken and round propagators until they are "tight":
Weaken:
Resolve:
Round:
CutSat
Graphical equivalent:
CutSat
Graphical equivalent:
Optional: back to 3D
CDCL-CuttingPlanes
Theory:
Decisions:
with bounded 1-0 variables
<=>
Round-to-one:
Resolve:
<=>
Equivalent to CutSat?
Closing thoughts
- Follow-up paper:
"Improving IntSat by expressing disjunctions of bounds as linear constraints" - Build "PolyCalcSat"?
- Combining proof systems is a simple idea!
- Why does IntSat immediately forget the learned clause?