Robot Learning
Ken Nakahara, Cong Wang, Zdravko Dugonjic, Robin Koch, Max Haufe, and Johannes Busch
Learning, Adaptive Systems, and Robotics (LASR) Lab
Research Seminar


v1.0
Structure of the Course
- You will have to find a group of 2 students (exceptions possible).
- Each group can select a topic to work on.
- Each topic consists of 3-4 papers.
- The group will have to read the papers, write a report, and present the topic in front of the course.
- The presentation, including questions, should take about 45 minutes.
- The presentation/report should contain:
- Explanation of the provided papers.
- Information on additional papers that fit the respective topic.
- A comparison/Analysis of common patters of the papers.
- Discussion of the topic.
- We will propose a number of topics, but feel free to propose your own.
Evaluation and Grading
- Both the presentation and the report will be graded individually.
- Every group will partner up with a second group. The groups will
- be tasked to lead the question round after the presentation of the other group.
- write a review of the report of the respective other group. The final grading will be done by the course supervisors, but the reviews will be taken into account.
- Attendance will be checked and is mandatory for passing the course.
- Absence must be excused (e.g., with a doctor's note).
- You can miss up to one seminar unexcused without repercussions.
- Missing too many seminars can lead to failing the course.
Schedule
- The seminars will take place from 18.11.25-03.02.26, which leaves the first group 4 weeks to prepare. Every seminar will consist of two presentations with questions.
- Please sign up by filling out the selection form on Opal until 23.10.
- You can select three preferences from the list presented today or put in your own topic (please confirm the topic with us beforehand).
- You can select three preferences for your presentation date.
- You can also tell us if there are dates that you absolutely cannot present at.
- Preference 1 is your first choice. Do not select the same topic/date twice.
Submission Deadlines
- Report/Slideset: 06.02.26
- Partner Group Review: 20.03.26
Available Topics
Latent World Models
Papers:
Hafner, et al. - Dream to Control: Learning Behaviors by Latent Imagination
Hafner, et al. - Mastering Atari with Discrete World Models
Hafner, et al. - Mastering Diverse Domains through World Models
Hafner, et al. - Training Agents Inside of Scalable World-Models
Goal:
Show the evolution of Latent World Models. Pay special attention to what features contribute to a suitable representation for latent imagination.
Source: Hafner, et. al.
Diffusion-Generative Models
Papers:
Ho, et. al. - Denoising Diffusion Probabilistic Models
Song, et. al. - Denoising Diffusion Implicit Models
Song, et. al. - Consistency Models
Karras, et. al. - Elucidating the Design Space of Diffusion-Based Generative Models
Goal:
Explain the different mathematical formulations of diffusion models and show how they can be unified. This can be framed as a tutorial on diffusion models.
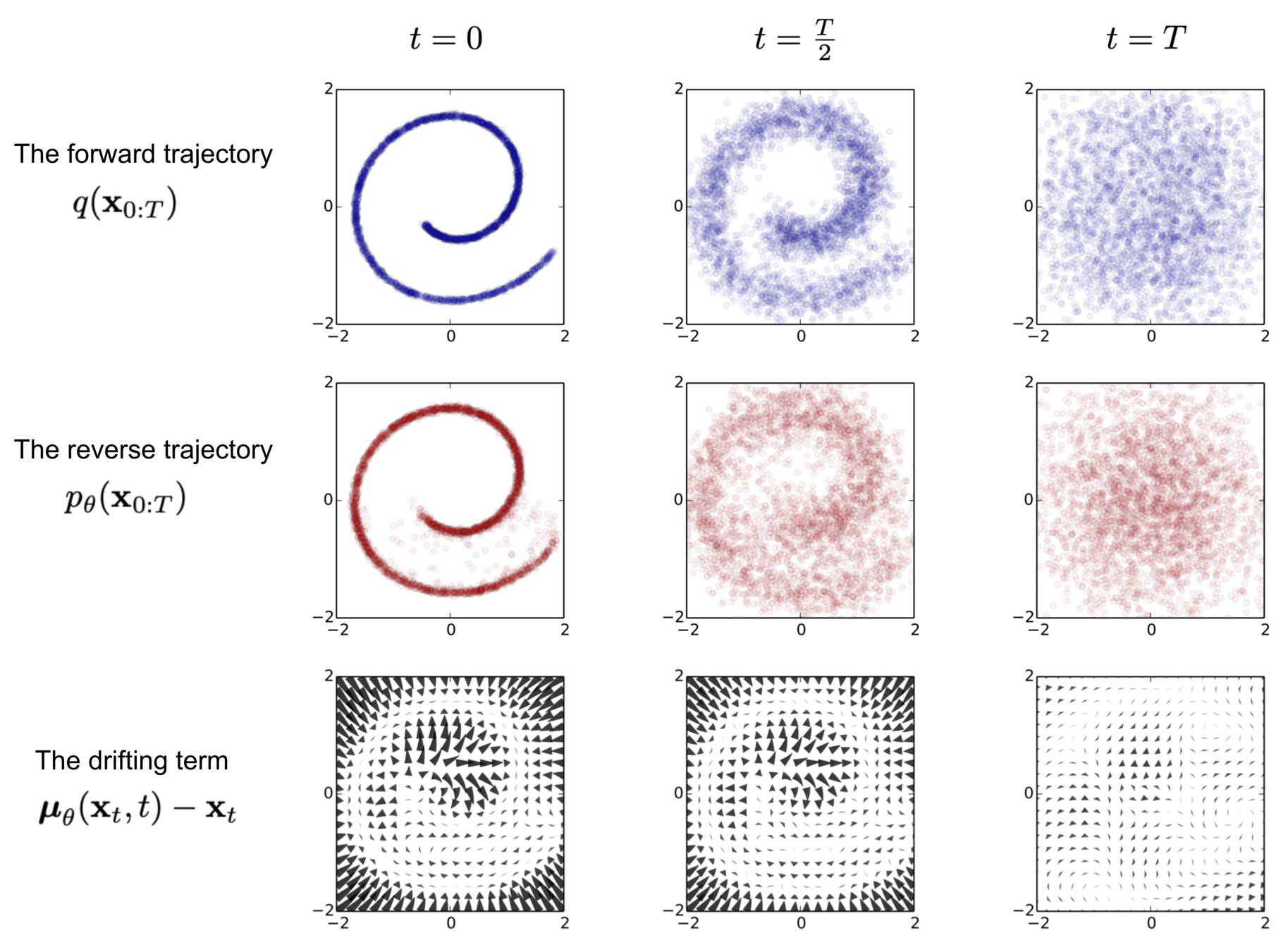
Source: Sohl-Dickstein, et. al.
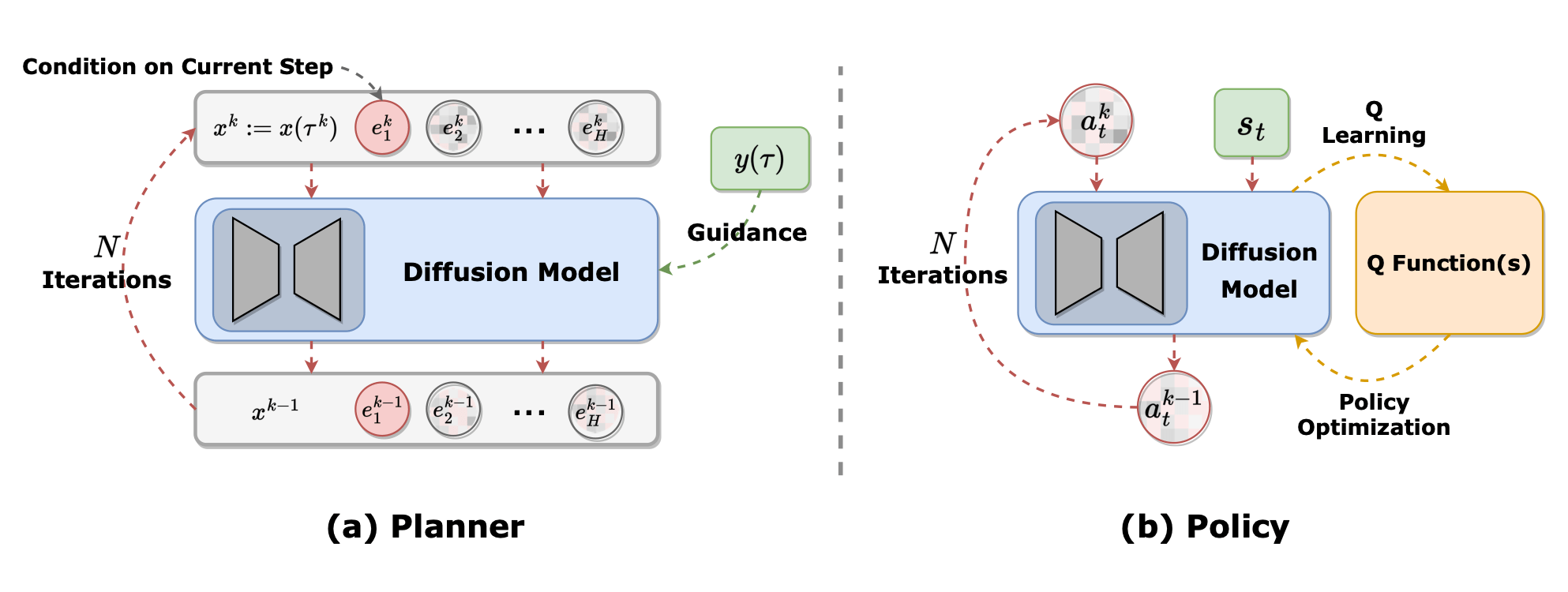
Diffusion Policies vs Diffusion Planners
Papers:
Chi, et al. - Diffusion Policy: Visuomotor Policy Learning via Action Diffusion.
Wang, et al. - Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning.
Ajay et al. - Is Conditional Generative Modeling all you need for Decision-Making?
Lu et al. - What makes a good diffusion planner?
Goal:
Explain and contrast different approaches how diffusion models can be used to model distributions of actions (diffusion policies) or state-dynamics (diffusion planners). Outline their respective strengths and weaknesses.
Source: Zhu, et. al.
Language-Conditioned Imitation Learning
Papers:
Reuss et al. - Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals
Liang et al. - SkillDiffuser: Interpretable Hierarchical Planning via Skill Abstractions in Diffusion-Based Task Execution
Zhang et al. - Language Control Diffusion: Efficiently Scaling Through Space, Time, and Tasks
Peschl et al. - From Code to Action: Hierarchical Learning of Diffusion-VLM Policies
Goal:
Compare different approaches to condition diffusion-based imitation learning pipelines on language queries. Pay special attention to the distinction between diffusion policies and diffusion planning.
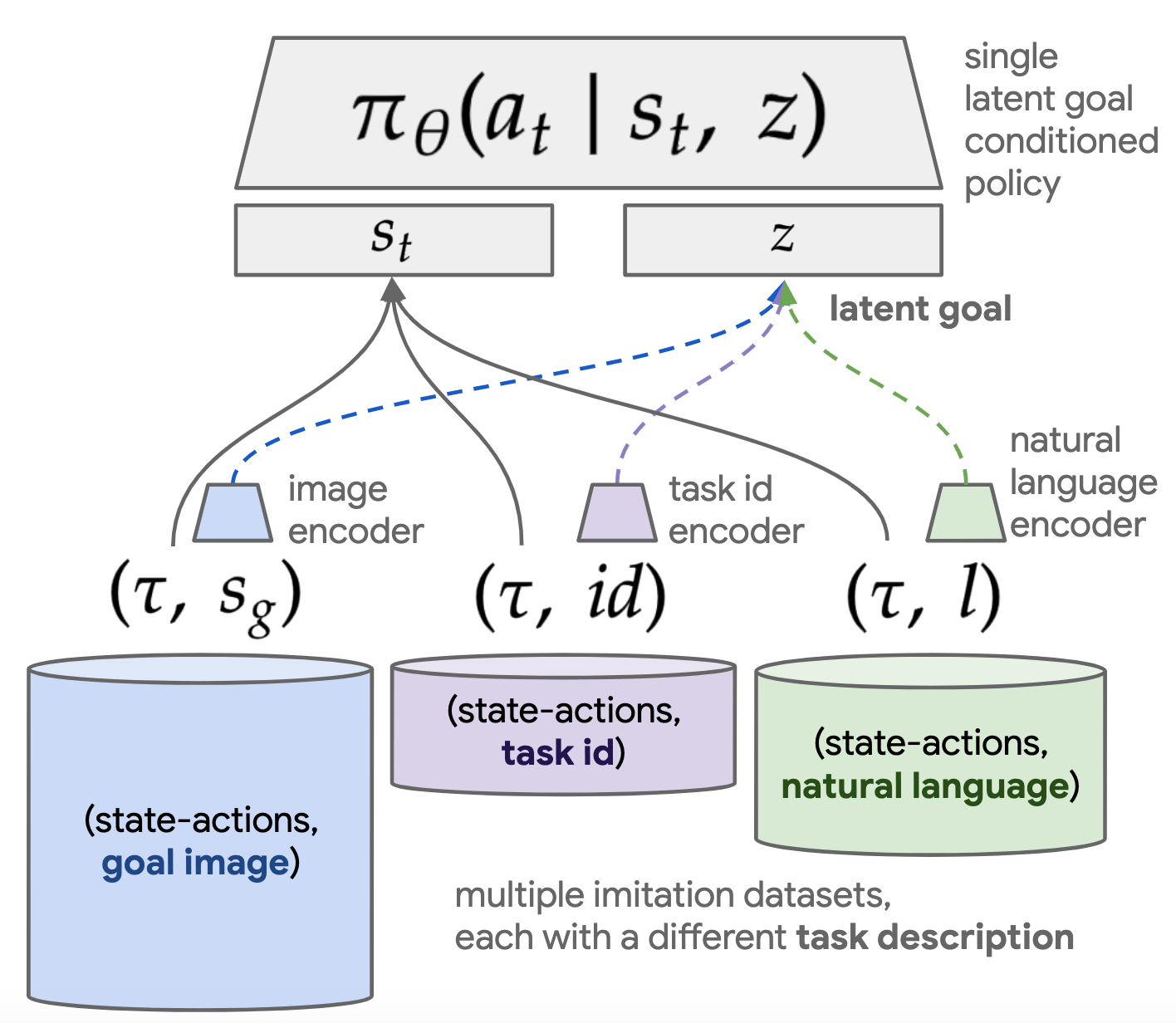
Source: language-play.github.io
Mental States Attribution to Robotics
Papers:
Thellman et al. - Mental State Attribution to Robots: A Systematic Review of Conceptions, Methods, and Findings
Thellman et al. - Do You See what I See? Tracking the Perceptual Beliefs of Robots
Thellman et al. - Does the Robot Know It Is Being Distracted? Attitudinal and Behavioral Consequences of Second-Order Mental State Attribution in HRI
Koban et al. - It feels, therefore it is: Associations between mind perception and mind ascription for social robots

Source: Thellman et al.
Robot Intent Expression and Communication
Papers:
Prascher et al. - How to Communicate Robot Motion Intent: A Scoping Review
Bodden et al. -A flexible optimization-based method for synthesizing intent-expressive robot arm motion
Yi et al. - Your Way Or My Way: Improving Human-Robot Co-Navigation Through Robot Intent and Pedestrian Prediction Visualisations.
Abe et al. Human Understanding and Perception of Unanticipated Robot Action in the Context of Physical Interaction
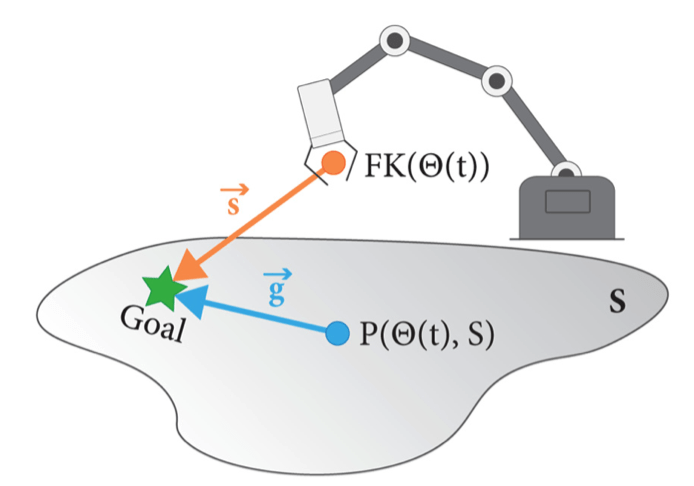
Source: Bodden et al.
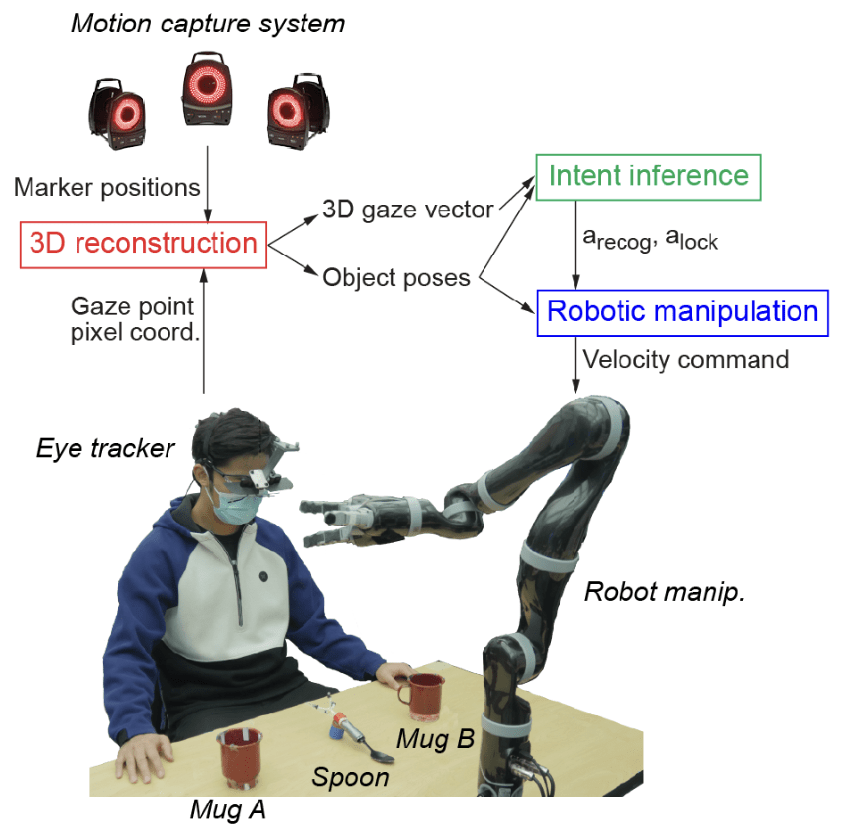
Human Intention Estimation in HRI
Papers:
Belardinelli - Gaze-Based Intention Estimation: Principles, Methodologies, and Applications in HRI
Belardinelli et al. - Intention estimation from gaze and motion features for human-robot shared-control object manipulation
Arreghini et al. - Predicting the Intention to Interact with a Service Robot: the Role of Gaze Cues
Xiaoyu Wang et al. Gaze-Based Shared Autonomy Framework With Real-Time Action Primitive Recognition for Robot Manipulators
Source: Xiaoyu Wang et al.
Knowledge Representation in Service Robotics
Papers:
Beetz et al. - Know Rob 2.0 — A 2nd Generation Knowledge Processing Framework for Cognition-Enabled Robotic Agents
Hughes et al. - Foundations of spatial perception for robotics: Hierarchical representations and real-time systems
Paulius et al. - A Survey of Knowledge Representation in Service Robotics
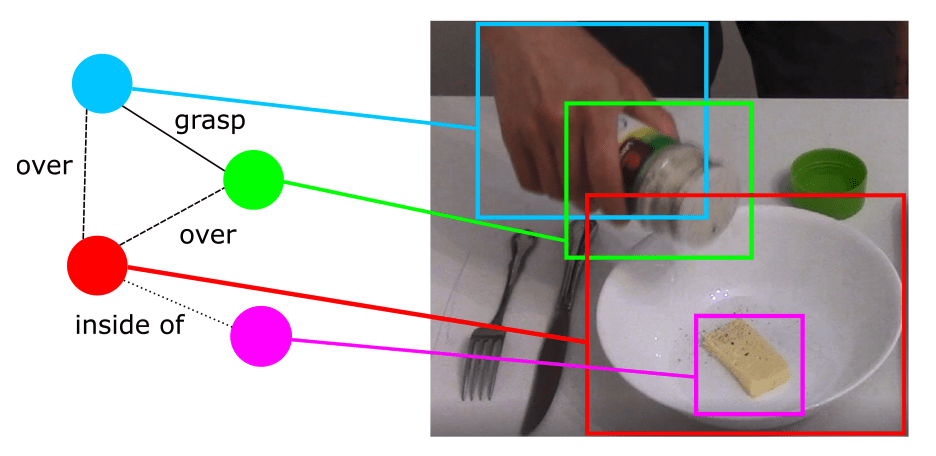
Source: Paulius et al.
Learning Robust Dexterous Grasping
Papers:
Zhang, et al. - RobustDexGrasp: Robust Dexterous Grasping of General Objects from Single-view Perception
Zhong, et al. - DexGrasp Anything: Towards Universal Robotic Dexterous Grasping with Physics Awareness
Zhao, et al. - Embedding high-resolution touch across robotic hands enables adaptive human-like grasping
Source: Zhao, et al.

Bimanual Manipulation with Multi-fingered Robotic Hands
Papers:
Lin, et al. - Learning Visuotactile Skills with Two Multifingered Hands
Chen, et al. - Bi-DexHands: Towards Human-Level Bimanual Dexterous Manipulation
Shaw, et al. - Bimanual Dexterity for Complex Tasks
Source: Shaw, et al.

Imitation Learning for Humanoid Robots
Papers:
He, et al. - OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning
Li, et al. - OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation
Qiu, et al. - Humanoid Policy ∼ Human Policy
Source: He, et al.

Foundation Models in Robotics
Papers:
Kawaharazuka, et al., Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications
Physical Intelligence - π0.5: a Vision-Language-Action Model with Open-World Generalization
NVIDIA - GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Source: Physical Intelligence

Unified Tactile Representation (1/2)
Source: completechildrenshealth.com.au

Unified Tactile Representation (2/2)
Papers:
Higuera, et al. - Sparsh: Self-supervised touch representations for vision-based tactile sensing
Gupta, et al. - Sensor-Invariant Tactile Representation
Rodriguez et al. - Cross-Sensor Touch Generation



Deep Net
Learning Simulation from Data
Papers:
Alonso, et al. - Diffusion for World Modeling: Visual Details Matter in Atari
Kanervisto, et al. - World and Human Action Models towards gameplay ideation
Chen, et al. - Model as a Game: On Numerical and Spatial Consistency for Generative Games
Motamed, et al. - Do generative video models understand physical principles?
Source: https://diamond-wm.github.io/
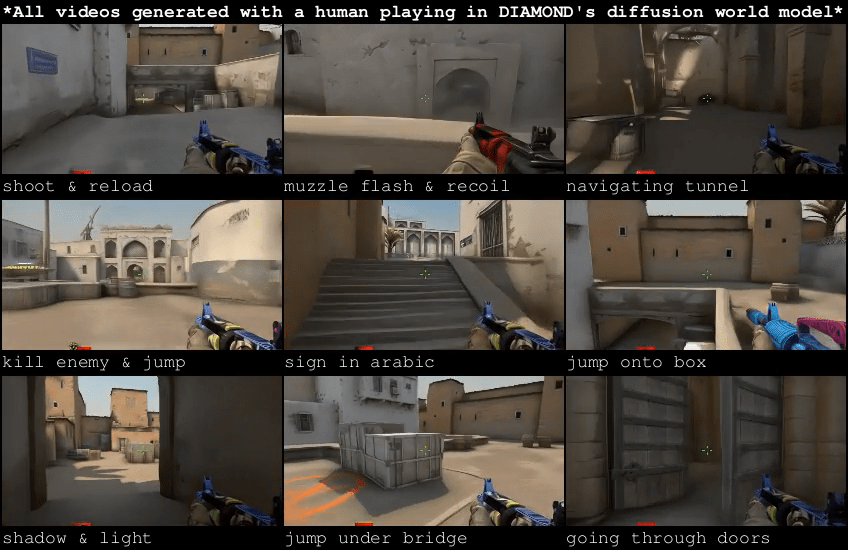
Conscious Machine
Papers:
Chalmers - Facing Up to the Problem of Consciousness
Joseph LeDoux, et al. - Consciousness beyond the human case
Farisco, et al. - Is artificial consciousness achievable? Lessons from the human brain

Goal: Discuss the term of consciousness and its usage with current state-of-the-art intelligent systems.
Control strategies for Tendon-Driven Hands
Papers:
-
K. Shaw and D. Pathak, “Demonstrating LEAP Hand v2: Low-Cost, Easy-to-Assemble, High-Performance Hand for Robot Learning,”
-
Y. Toshimitsu et al., “Getting the Ball Rolling: Learning a Dexterous Policy for a Biomimetic Tendon-Driven Hand with Rolling Contact Joints,”
-
C. C. Christoph et al., “ORCA: An Open-Source, Reliable, Cost-Effective, Anthropomorphic Robotic Hand for Uninterrupted Dexterous Task Learning,”
-
A. Zorin et al., “RUKA: Rethinking the Design of Humanoid Hands with Learning,”
Goal:
It is difficult to control tendon-driven robot hands that do not possess a joint-angle encoder. This work should present and compare some of the approaches used to control such tendon-driven robot hands.

Source: A. Zorin et al., “RUKA: Rethinking the Design of Humanoid Hands with Learning,”
Tactile Pose and Shape Estimation
Papers:
- E. K. Gordon, B. Baraki, H. Bui, and M. Posa, “Active Tactile Exploration for Rigid Body Pose and Shape Estimation,”
-
J. Lee and N. Fazeli, “ViTaSCOPE: Visuo-tactile Implicit Representation for In-hand Pose and Extrinsic Contact Estimation,”
-
M. Comi, Y. Lin, A. Church, A. Tonioni, L. Aitchison, and N. F. Lepora, “TouchSDF: A DeepSDF Approach for 3D Shape Reconstruction Using Vision-Based Tactile Sensing,”
Goal:
Present and compare the approaches used for tactile pose and shape estiamtion.
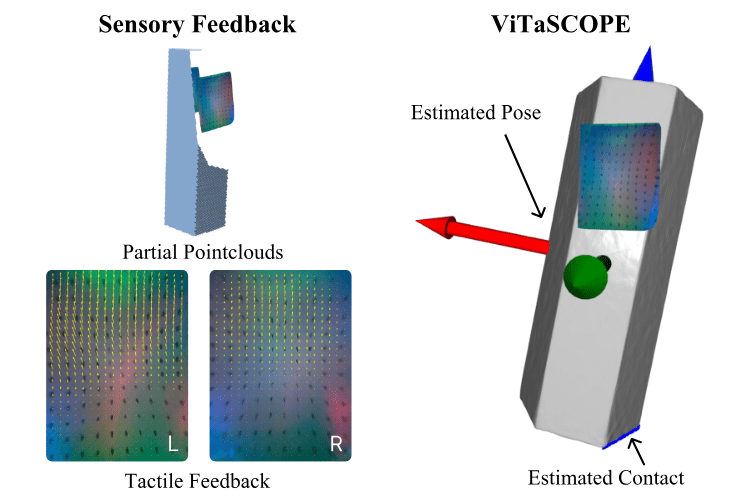
Source:J. Lee and N. Fazeli, “ViTaSCOPE: Visuo-tactile Implicit Representation for In-hand Pose and Extrinsic Contact Estimation,”
Lensless Imaging
Papers:
- S. Li et al., “Lensless camera: Unraveling the breakthroughs and prospects,”
- Y. Perron, E. Bezzam, and M. Vetterli, “A Modular and Robust Physics-Based Approach for Lensless Image Reconstruction,”
- S. S. Khan, V. Sundar, V. Boominathan, A. Veeraraghavan, and K. Mitra, “FlatNet: Towards Photorealistic Scene Reconstruction from Lensless Measurements,”
- K. Monakhova, J. Yurtsever, G. Kuo, N. Antipa, K. Yanny, and L. Waller, “Learned reconstructions for practical mask-based lensless imaging,”
Goal: Present and compare the approaches used for lensless imaging.
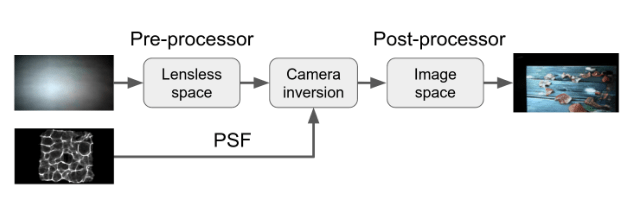
Source: Y. Perron, E. Bezzam, and M. Vetterli, “A Modular and Robust Physics-Based Approach for Lensless Image Reconstruction,”
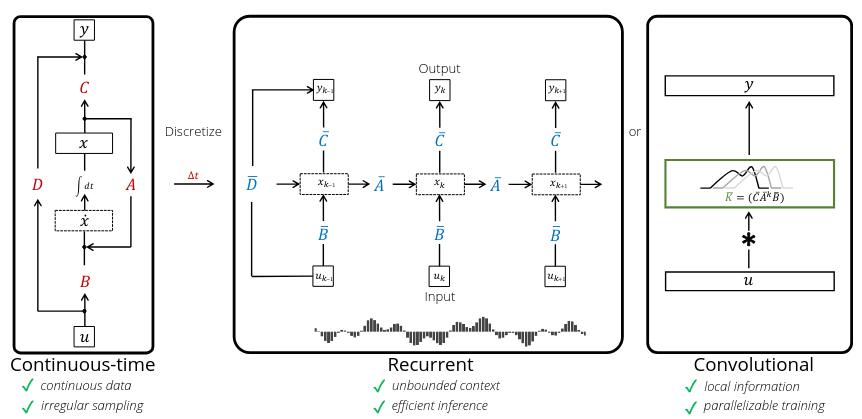
State Space Models as Transformer Alternatives
Overview:
Transformers are computationally
expensive at inference due to quadratic
complexity in sequence length. State space
models (SSMs) offer an efficient alternative.
Goal: Provide an overview of SSMs and
their different representations
(ex. RNN & CNN) [1].
Discuss these representations and improvements in Structured SSMs (S4) [2] and Mamba [3]. Compare Mamba's performance against Transformers in sequence modeling tasks.
Papers:
[1] Gu, Albert, et al. "Combining recurrent, convolutional, and continuous-time models with linear state space layers."
[2] Gu, Albert, Karan Goel, and Christopher Ré. "Efficiently modeling long sequences with structured state spaces."
[3] Gu, Albert, and Tri Dao. "Mamba: Linear-time sequence modeling with selective state spaces."
Source: [1]