SQL - POSTGRES
SQL - POSTGRES
John Cardozo
John Cardozo
temas
- Data Definition Language
- Columnas
- Tipos de datos
- Restricciones
- Creación y eliminación de tablas
- Primary key
- Foreign key
- Columnas
- Data Manipulation Language
- INSERT
- UPDATE
- DELETE
-
Data Query Language
- SELECT
- JOIN
local - cloud
Postgres

ElephantSQL
Amazon RDS for PostgreSQL
elementos básicos
Tablas
Campos
Relaciones

Tablas
Repositorio de datos
diseño: planificación
Información de soporte
Información de negocio
Modelo Entidad Relación
Requerimientos
estructura: tablas
| campo 1 | campo 2 | campo 3 |
|---|---|---|
| dato11 | dato12 | dato13 |
| dato21 | dato22 | dato23 |
| dato31 | dato32 | dato33 |
campos
registros
Nombre único en la base de datos
La estructura está definida por los campos
Relación entre tablas a través de llaves
datos = registros
| codigo | nombres | apellidos |
|---|---|---|
| 001 | Valeria | Medina |
| 002 | Emilio | Barrera |
| 003 | Catalina | Giraldo |
| 004 | Luciana | Urueña |
campos = 3
registros = 4
Datos almacenados en una tabla
estructura: campos
nombre
valor por default
tipo
obligatorio
llave primaria
llave foránea
descriptor del campo
Valor al crear un registro
entero, caracter, fecha, boolean
Indica si el campo es requerido
Identificador único
Relación con otras tablas
Al menos un campo de la tabla debe ser llave primaria
Dominio
Conjunto de posibles valores
obligatorios
opcionales
llaves
comandos psql
Conexión local
psqlConexión remota
psql -h hostname -U usuario -d basedatosLista de bases de datos
\lUsar una base de datos
\c basedatosLista de tablas de la
base de datos en uso
\dtCrear una base de datos
create database basedatos;Eliminar una base de datos
drop database dbname;Importar una base de datos
psql basedatos < dump.sqlCrear un usuario
create user mi_username
with password 'mi_password';Lista de usuarios
\duEliminar usuario
drop user usuarioAyuda
\?\hSalir
\qdata definition language
data definition language
Define la estructura de la base de datos
columnas: TIPOS DE DATOS
| Tipo de dato | SQL |
|---|---|
| Boolean | boolean, bool |
| Caracteres | varchar(n) text |
| Enteros | int, serial |
| Punto flotante | numeric(p, s) p: dígitos s: dígitos después del punto |
| Fechas y horas | date, time, timestamp |
columnas : restricciones
Estructura de una columna
nombre_de_columna type restriccion_de_columnaRestricciones de una columna
/* No puede tener valores nulos */
not null
/* No puede tener valores repetidos entre registros */
unique
/* Llave primaria */
primary key
/* References */
referencescreación y eliminación de tablas
Estructura de creación de tablas
create table nombre_de_tabla (
nombre_de_columna type restriccion_de_columna,
)Ejemplo de creación de tabla
create table cuenta(
id serial primary key,
username varchar(50) unique not null,
password varchar(50) not null,
email varchar (355) unique not null,
creado_en timestamp not null,
ultima_autenticacion timestamp
);Ejemplo de eliminación de tabla
drop table cuenta;Ejemplo de agregar una columna
alter table cuenta
add column observaciones varchar(45);llave primaria
/* Llave primaria en la
definición del campo */
create table cuenta(
id serial primary key,
username varchar(50),
);/* Llave primaria compuesta */
create table estudianteCurso
(
idEstudiante integer not null,
idCurso integer not null,
primary key (idEstudiante, idCurso)
);/* Llave primaria declarada
aparte del campo */
create table cuenta(
id serial not null,
username varchar(50),
primary key(id)
);Llave primaria compuesta: común en tablas de rompimiento
llave foránea
create table categoria(
id serial primary key,
nombre varchar(45) not null
);create table pelicula(
id serial primary key,
nombre varchar(45),
idCategoria int not null,
foreign key (idCategoria) references categoria(id)
);create table pelicula(
id serial primary key,
nombre varchar(45),
idCategoria int references categoria(id)
);Creación de tabla: Llave foránea declarada en el campo
Creación de tabla: llave foránea declarada aparte del campo
Tabla de referencia
data manipulation language
data manipulation language
Modifica la información almacenada en la base de datos
creación de datos: insert (1)
insert into nombre_tabla(columna1, columna2, …)
values (valor1, valor2, …);Sintaxis de INSERT
create table pelicula (
id serial primary key,
titulo varchar(255) not null,
sinopsis varchar(255),
year int
);Tabla de ejemplo
insert into pelicula (titulo)
values ('Avatar');Ejemplo de INSERT
- No necesita el valor del id porque es serial
- No necesita de sinopsis o year porque pueden ser valores nulos
creación de datos: insert (2)
create table pelicula (
id serial primary key,
titulo varchar(255) not null,
sinopsis varchar(255),
year int
);Tabla de ejemplo
insert into pelicula (titulo, year)
values
('Pulp Fiction', 1994),
('Ingloriuos Basterds', 2009),
('Django Unchained', 2012);Ejemplo de INSERT de varios registros
insert into pelicula (titulo, year)
values ('Kill Bill: Volume 1', 2003)
returning id;Ejemplo de INSERT retornando el valor del id
actualización de datos: UPDATE
create table pelicula (
id serial primary key,
titulo varchar(255) not null,
sinopsis varchar(255),
year int
);Tabla de ejemplo
update table
set columna1 = valor1,
columna2 = valor2 ,...
where
condicion;Sintaxis de UPDATE
update pelicula
set year = 2003;Actualiza todos los registros de la tabla
update pelicula
set year = 2003
where id = 3;Actualiza ALGUNOS los registros de la tabla
update pelicula
set year = 2003
where id = 1 or id = 5;eliminación de datos: delete
create table pelicula (
id serial primary key,
titulo varchar(255) not null,
sinopsis varchar(255),
year int
);Tabla de ejemplo
delete from nombre_tabla
where condicion;Sintaxis de DELETE
delete from pelicula;Borra todos los registros de la tabla
delete from pelicula
where id = 3;Borra ALGUNOS registros de la tabla
delete from pelicula
where id >= 2 and id <5;data query language
data query language
Obtiene información almacenada en la base de datos
obtención de datos: select (1)
create table pelicula (
id serial primary key,
titulo varchar(255) not null,
sinopsis varchar(255),
year int
);Tabla de ejemplo
select
columna_1,
columna_2,
...
from
nombre_tabla;Sintaxis de SELECT
select *
from pelicula;SELECT Básico: obtiene toda la información de una tabla
obtención de datos: select (2)
select *
from pelicula;Obtiene todas las columnas, todos los registros
select titulo, year
from pelicula;Obtiene algunas las columnas, todos los registros
select id, titulo
from pelicula
where year = 2020 or year = 2001;Obtiene algunas las columnas, algunos los registros
obtención de datos: select (3)
select *
from pelicula
order by titulo;Obtiene todos los registros ordenados ascendentemente
select *
from pelicula
order by titulo desc;Obtiene todos los registros ordenados descendentemente
select *
from pelicula
order by year, titulo;Obtiene todos los registros ordenados por varias columnas
select *
from pelicula
order by year desc, titulo asc;Obtiene todos los registros ordenados por varias columnas
Ordenamiento
EJERCICIO: select (1)
create table empleados(
id serial primary key,
nombres varchar(25) not null,
apellidos varchar(25) not null,
edad int,
ciudad varchar(50)
);Creación de la tabla
insert into empleados
(nombres, apellidos, edad, ciudad)
values
('Carolina', 'Ramirez', 37, 'Medellin'),
('Claudia', 'Cardona', 38, 'Medellin'),
('Aida', 'Gomez', 41, 'Bogota'),
('Javier', 'Corredor', 40, 'Medellin'),
('Jorge Mario', 'Cardona', 29, 'Medellin'),
('Dany', 'Ramirez', 45, 'Margarita'),
('Fernet', 'Lozano', 42, 'Buenos Aires'),
('Brian', 'Ramirez', 19, 'New Jersey'),
('Johanna', 'Lozano', 35, 'Bogota'),
('Diana', 'Cardozo', 38, 'Bogota'),
('Laura', 'Rodriguez', 25, 'Medellin')
;Creación de registros
EJERCICIO: select (2)
Consultas
- Seleccione todas las columnas de todos los empleados en la tabla.
- Seleccione todas las columnas de todos los empleados con edad superior a 40 años.
- Seleccione los nombres y apellidos de únicamente 3 empleados menores de 40 años.
- Seleccione los nombres, apellidos y edad de los empleados de la ciudad de "Medellin".
- Selecciones los apellidos, nombres y ciudad de los empleados entre los 35 y 40 años de edad.
- Seleccione los nombres y edad de los empleados con apellido "Ramirez".
- Seleccione los apellidos, nombres y edad de los empleados cuyo apellido empieza por la letra "C" ordenados por la ciudad y por la edad ascendentemente.
obtención de datos: filtros (1)
| Operador | Descripción |
|---|---|
| = | Igual |
| > | Mayor a |
| < | Menor a |
| >= | Mayor o igual a |
| <= | Menor o igual a |
| <> o != | Diferente |
| and | Operador lógico AND (y) |
| or | Operador lógico OR (o) |
obtención de datos: filtros (2)
select *
from pelicula
where (id >= 1 and id < 5) or year = 2013;Filtro de datos con AND y OR
select *
from pelicula
where year in (2013, 2018, 2020);Filtro de datos con operador IN
select *
from pelicula
where titulo like '%love%';Filtro de datos con operador LIKE
select *
from pelicula
where year between 2005 and 2010;Filtro de datos con operador BETWEEN
obtención de datos: filtros (3)
select *
from pelicula
where year = 2008
limit 5;Filtro de datos con LIMIT
select *
from pelicula
where year = 2008
limit 5 offset 3;Filtro de datos con LIMIT y OFFSET
select *
from pelicula
where sinopsis is null;Filtro de datos comparando NULL
select id, titulo as title
from pelicula
where sinopsis is not null;Filtro de datos asignando un alias (AS)
funciones agregadas
select avg(edad) from empleados;avg: promedio de una columna
select count(*) from empleados;count: cantidad de registros
select max(edad) from empleados;max: máximo valor de una columna
select max(edad) from empleados;min: mínimo valor de una columna
select sum(edad) from empleados;sum: suma de valores de una columna
funciones: fechas
SELECT age(current_date,'2001-12-05');age: calcula la edad dadas 2 fechas
select current_date;current_date: fecha actual
select current_time;current_time: hora actual
select current_timestamp;current_timestamp: fecha y hora actual
funciones: string
select length(apellidos)
from empleados;length: longitud de un string
select concat(apellidos, ' ', nombres)
from empleados;concat: concatena varias cadenas
select left(nombres, 3)
from empleados;left: primeros n caracteres
select right(apellidos, 3)
from empleados;right: últimos n caracteres
select substring(nombres, 2, 3)
from empleados;substring: desde, cuantos
select lower(apellidos)
from empleados;lower: minúsculas
select upper(nombres)
from empleados;upper: mayúsculas
select position('a' in nombres)
from empleados;position: caracter en cadena
funciones: matemáticas
select div(20, 8);div: división
select abs(-10);abs: valor absoluto
select ceil(12.1);ceil: redondea hace arriba
select floor(12.4);floor: redondea hacia abajo
select pi();pi
select mod(20, 8);mod: módulo de división
select power(2, 8);power: potencia
select sqrt(3.4);sqrt: raíz cuadrada
select round(12.4);round: redondea al más cercano
joins
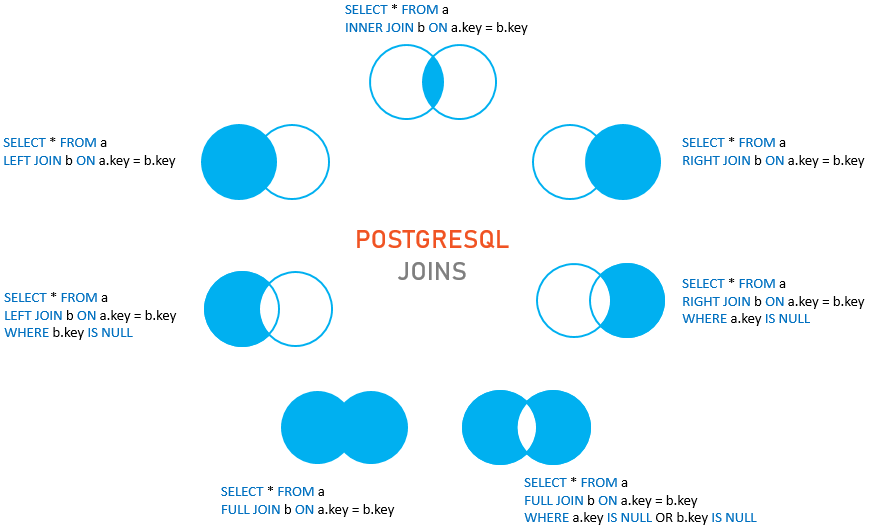
joins: tablas de ejemplo
create table canasta_a (
id int primary key,
fruta varchar (100) not null
);
create table canasta_b (
id int primary key,
fruta varchar (100) not null
);
insert into canasta_a (id, fruta)
values
(1, 'manzana'),
(2, 'naranja'),
(3, 'banano'),
(4, 'fresa');
insert into canasta_b (id, fruta)
values
(1, 'naranja'),
(2, 'manzana'),
(3, 'melon'),
(4, 'pera');Tablas de ejemplo
| id | fruta |
|---|---|
| 1 | manzana |
| 2 | naranja |
| 3 | banano |
| 4 | fresa |
tabla: canasta_a
| id | fruta |
|---|---|
| 1 | naranja |
| 2 | manzana |
| 3 | melon |
| 4 | pera |
tabla: canasta_b
joins: inner join
INNER JOIN retorna un conjunto de filas que contiene las filas en la tabla izquierda que hagan match con las filas de la tabla derecha
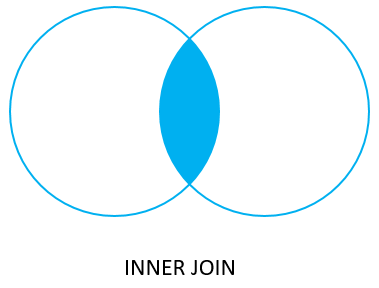
SELECT
a.id id_a,
a.fruta fruta_a,
b.id id_b,
b.fruta fruta_b
FROM
canasta_a a
INNER JOIN canasta_b b ON a.fruta = b.fruta;| id_a | fruta_a | id_b | fruta_b |
|---|---|---|---|
| 1 | manzana | 2 | manzana |
| 2 | naranja | 1 | naranja |
Ejemplo de filas resultantes
joins: LEFT join
LEFT JOIN retorna un conjunto de filas de la tabla izquierda con la filas que hagan match (si las hay) con la tabla derecha. Si no hay match el lado derecho tendrá valores nulos.
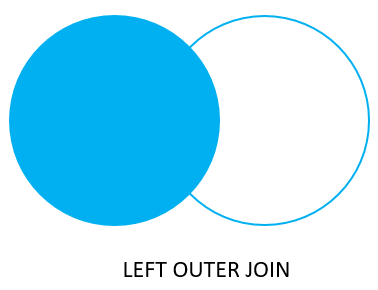
SELECT
a.id id_a,
a.fruta fruta_a,
b.id id_b,
b.fruta fruta_b
FROM
canasta_a a
LEFT JOIN canasta_b b ON a.fruta = b.fruta;| id_a | fruta_a | id_b | fruta_b |
|---|---|---|---|
| 1 | manzana | 2 | manzana |
| 2 | naranja | 1 | naranja |
| 3 | banano | null | null |
| 4 | fresa | null | null |
Ejemplo de filas resultantes
joins: LEFT join con where
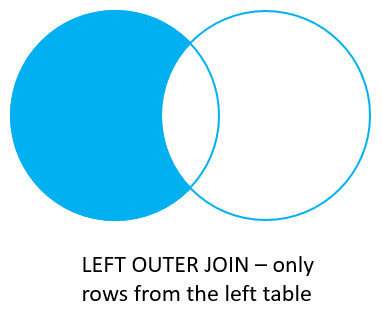
select
a.id id_a,
a.fruta fruta_a,
b.id id_b,
b.fruta fruta_b
from
canasta_a a
left join canasta_b b on a.fruta = b.fruta
where b.id is null;| id_a | fruta_a | id_b | fruta_b |
|---|---|---|---|
| 3 | banano | null | null |
| 4 | fresa | null | null |
Ejemplo de filas resultantes
joins: RIGHT JOIN
RIGHT JOIN genera un conjunto de filas que contiene todas las filas de la tabla derecha con las filas que hagan match de la tabla izquierda. Si no hay match, el lado izquierdo tendrá valores nulos.
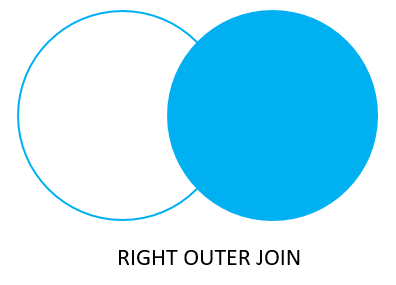
select
a.id id_a,
a.fruta fruta_a,
b.id id_b,
b.fruta fruta_b
from
canasta_a a
right join canasta_b b on a.fruta = b.fruta;| id_a | fruta_a | id_b | fruta_b |
|---|---|---|---|
| 2 | naranja | 1 | naranja |
| 1 | manzana | 2 | manzana |
| null | null | 3 | melon |
| null | null | 4 | pera |
Ejemplo de filas resultantes
joins: RIGHT JOIN con where
Si sólo se quiere obtener las filas de la tabla derecha pero no las de la tabla izquierda utilizando la cláusula WHERE.
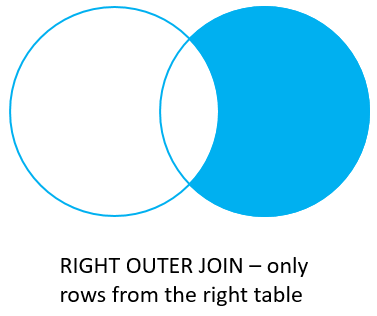
select
a.id id_a,
a.fruta fruta_a,
b.id id_b,
b.fruta fruta_b
from
canasta_a a
right join canasta_b b on a.fruta = b.fruta
where a.id is null;| id_a | fruta_a | id_b | fruta_b |
|---|---|---|---|
| null | null | 3 | melon |
| null | null | 4 | pera |
Ejemplo de filas resultantes
joins: FULL JOIN
FULL JOIN genera un conjunto de filas que contiene todas las filas de la tabla izquierda y derecha, con las filas que hagan match en ambos lados. Si no hay match, el lado que no haga match contiene valores nulos.

select
a.id id_a,
a.fruta fruta_a,
b.id id_b,
b.fruta fruta_b
from
canasta_a a
full join canasta_b b on a.fruta = b.fruta;| id_a | fruta_a | id_b | fruta_b |
|---|---|---|---|
| 1 | manzana | 2 | manzana |
| 2 | naranja | 1 | naranja |
| 3 | banano | null | null |
| 4 | fresa | null | null |
| null | null | 3 | melon |
| null | null | 4 | pera |
Ejemplo de filas resultantes
joins: FULL JOIN con where
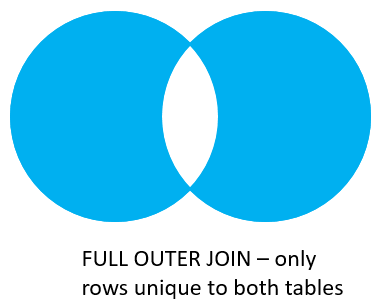
select
a.id id_a,
a.fruta fruta_a,
b.id id_b,
b.fruta fruta_b
from
canasta_a a
full join canasta_b b on a.fruta = b.fruta
where a.id is null or b.id is null;| id_a | fruta_a | id_b | fruta_b |
|---|---|---|---|
| 3 | banano | null | null |
| 4 | fresa | null | null |
| null | null | 3 | melon |
| null | null | 4 | pera |
Ejemplo de filas resultantes
ejemplo práctico
ejemplo práctico
Proyectos
ejemplo: diagrama entidad relación



Llave primaria
Campo obligatorio
Campo opcional
Llave foránea opcional
ejemplo: data definition language
create table usuarios(
id serial primary key,
nombres varchar(45) not null,
email varchar(45)
);create table proyectos(
id serial primary key,
titulo varchar(45) not null,
descripcion varchar(45),
idGerente int references usuarios(id)
);create table integrantes(
idUsuario int references usuarios(id) not null,
idProyecto int references proyectos(id) not null,
primary key(idUsuario, idProyecto),
activo bool
);Tabla: usuarios
Tabla: proyectos
Tabla: integrantes
ejemplo: data manipulation language
insert into usuarios (nombres, email)
values
('John Lennon', 'john@gmail.com'),
('Paul McCartney', 'paul@gmail.com'),
('George Harrison', 'george@gmail.com'),
('Ringo Starr', 'ringo@gmail.com');insert into proyectos (titulo, descripcion, idGerente)
values
('Abbey Road', 'Hecho en 1969', 1),
('Stg. Pepper', 'Hecho en 1967', 1),
('Help', 'Hecho en 1965', 3),
('Let it Be', 'Hecho en 1970', 2);insert into integrantes (idProyecto, idUsuario, activo)
values
(1, 1, true), (1, 2, true), (1, 3, false),
(2, 3, true), (2, 1, false), (2, 4, true),
(3, 4, false), (3, 2, true); Tabla: usuarios
Tabla: proyectos
Tabla: integrantes
ejemplo: data query language (1)
select count(*) as cantidad
from usuarios;Cantidad de usuarios
select
p.titulo,
u.nombres
from
usuarios u
inner join proyectos p on p.idGerente = u.id
order by p.titulo;Proyectos ordenados alfabéticamente con sus respectivos gerentes
select
u.nombres,
p.titulo
from
usuarios u
inner join integrantes i on u.id = i.idUsuario
inner join proyectos p on p.id = i.idProyecto and i.activo = true
order by u.nombres, p.titulo;Integrantes de proyectos ordenados alfabéticamente por nombre y por proyecto
john cardozo
johncardozo@gmail.com