Not Only SQL
Just for you...



Population actuelle mondiale: 7.3 milliards d'humains.
Prévisions pour 2015: 1.5 Milliards de smartphones vendue
Si personnes n'est équipés de smartphone, en 1 seule année :
20% de la population mondiale posséderait cet équipement
En multipliant par le produit cartésien l'âge et la localisation géographique
On s'aperçoit plus aisément de la masse gigantesque de données potentielle exploitable
... et on parlerais même de Small Data :)


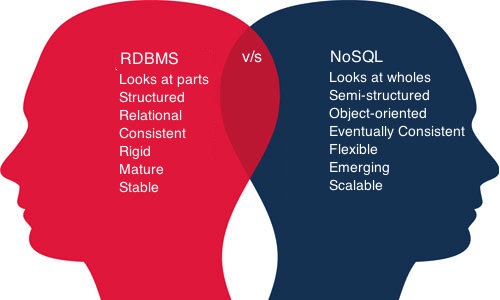
Ne veux pas dire...Not SQL

Retour en arrière...
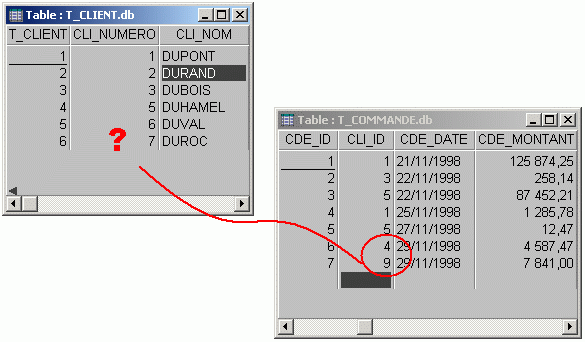
Les SGBDR, une vielle histoire

Edgar Frank Codd
Informaticien/Mathématicien Britanique, inventeur du SGBDR chez IBM (1970)

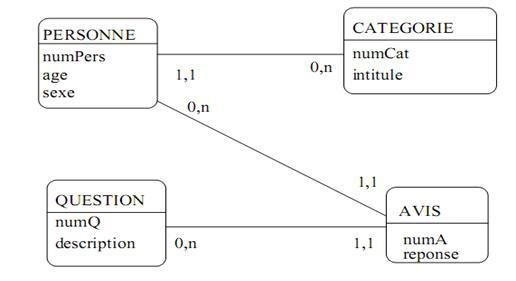
MCD/MLD/MPD en étoile
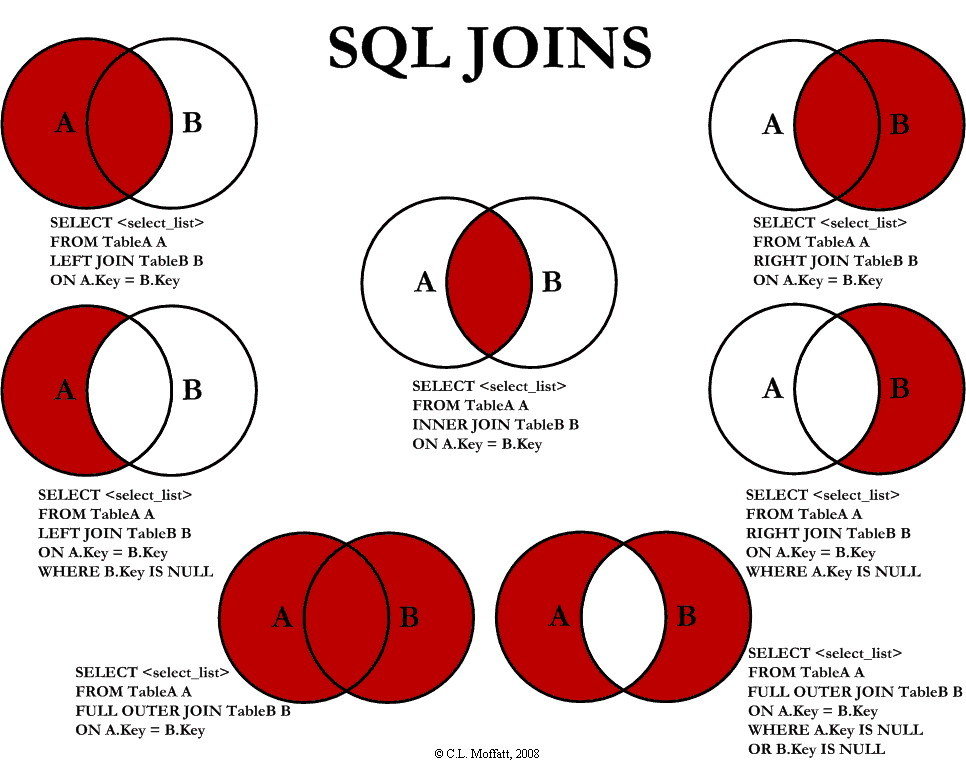
Un modèle relationnel
12 règles de Codd
Les 12 règles de Codd sont un ensemble de règles édictées par Edgar F. Codd, conçues pour définir ce qui est exigé d'un système de gestion de base de données (SGBD) afin qu'il puisse être considéré comme relationnel (SGBDR)
Unicité
Garantie d'accès
Traitement des valeurs nulles
Catalogue lui-même relationnel
Sous-langage de données
Mise à jour des vues
Insertion, mise à jour, et effacement de haut niveau
Indépendance physique
Indépendance logique
Indépendance d'intégrité
Indépendance de distribution
Règle de non-subversion
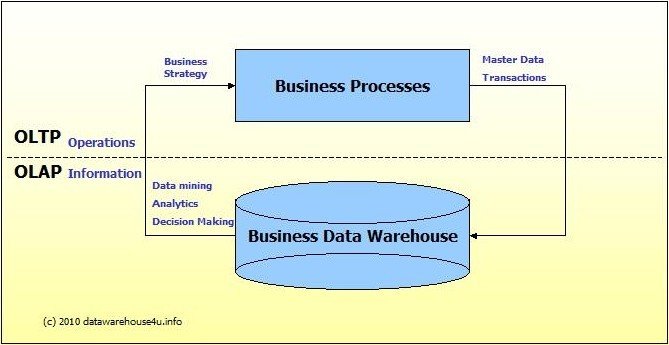
2 Types de SGBD: de OLTP à OLAP
OLTP: Online Transactional Processing
Besoin d'interroger une base de données transactionnel classique
OLAP: Online Analytical Processing
Besoin de parcourir un grand nombre de données pour analyse de statistiques et monitoring
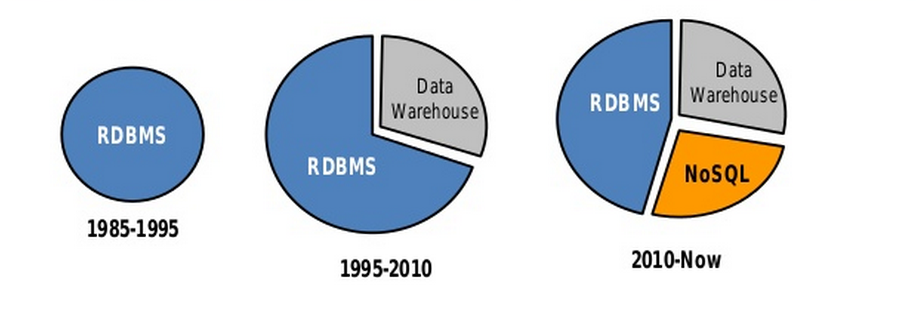


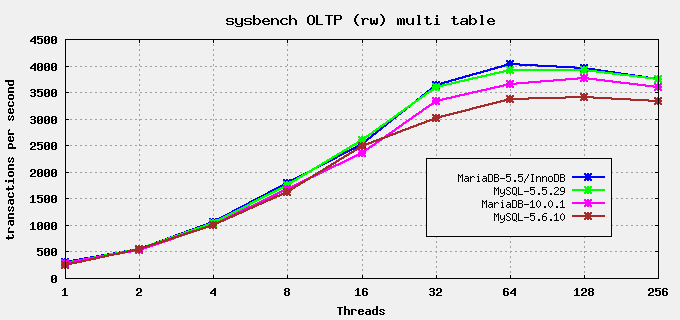
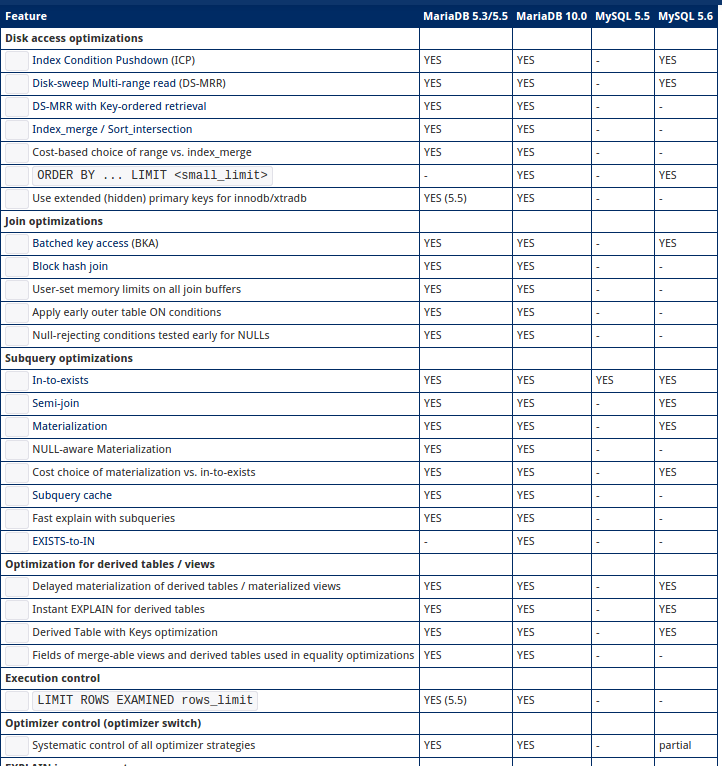
MariaDB Vs MySQL
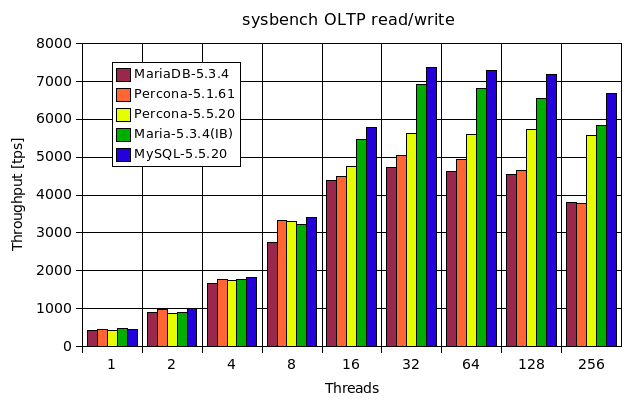


Pourquoi choisir MariaDB?
- De nombreuses améliorations de l'optimiseur dans MariaDB 5.3.
- 100% Compatible avec le MYSQL
- Réplication plus rapide et plus sure
- Réplication parallèle
- Améliorations pour le sous-système d'entrées/sorties asynchrone d'InnoDB
- Les indexes pour le moteur MEMORY(HEAP) sont plus rapides. D'après un test simple, 24% plus rapide sur les INSERT pour des indexes entiers et 60% plus rapide pour les indexes sur une colonne en CHAR(20).
- Le cache de clés segmenté pour MyISAM. Peux accélérer les tables MyISAM jusqu'à 4x.
- Taille de hachage ajustable pour MyISAM et Aria. Peut grandement améliorer le temps d'arrêt (passer d'heures à minutes) lorsque beaucoup de tables MyISAM/Aria sont utilisées avec des clés délayées.
- CHECKSUM TABLE est plus rapide.
- Les performances de conversion de jeu de caractères ont été améliorées.
- Le gain de vitesse moyen est de 1 à 5% (d'après sql-bench) mais peut être supérieur pour des gros jeux de résultats avec tous les caractères
- Pool de threads dans MariaDB 5.1 et encore plus avancé dans MariaDB 5.5. Permettant de faire tourner MariaDB avec plus de 200.000 connections et avec un gain de vitesse notable lorsque de nombreuses connexions sont utilisées simultanément.
- L'utilisation du moteur de stockage Aria permet d'effectuer plus rapidement des requêtes complexes
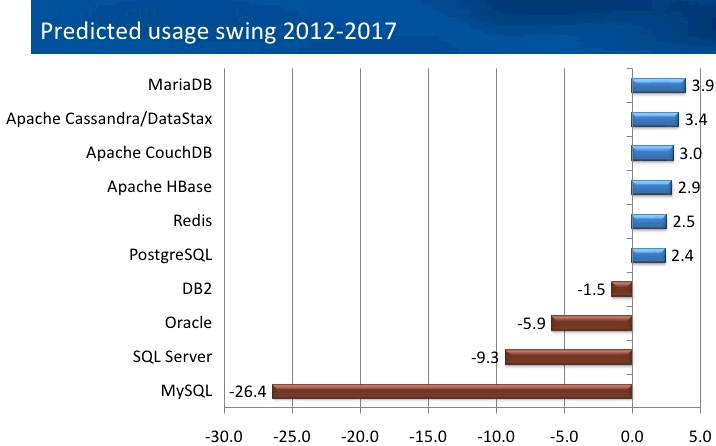
Prédictions des usages pour 2017
Installation de MariaDB
sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 1BB943DB echo deb http://ftp.igh.cnrs.fr/pub/mariadb//repo/5.5/ubuntu $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/MariaDB.list
sudo apt-get update
sudo apt-get install mariadb-server

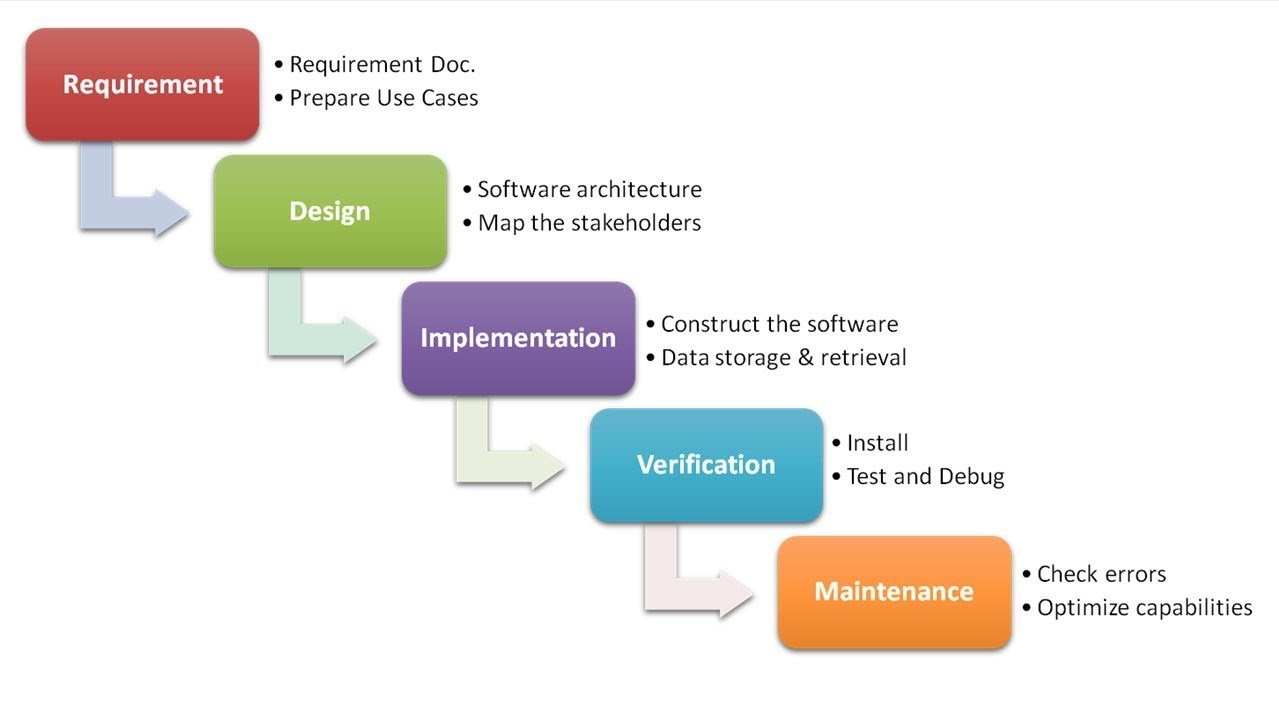
Comment tous l'information est gérée?
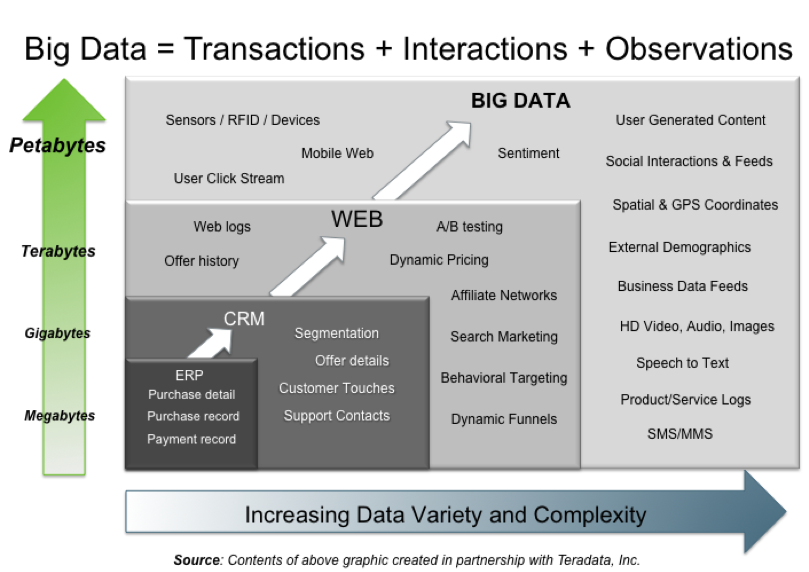
Comment en est-on arrivé là?
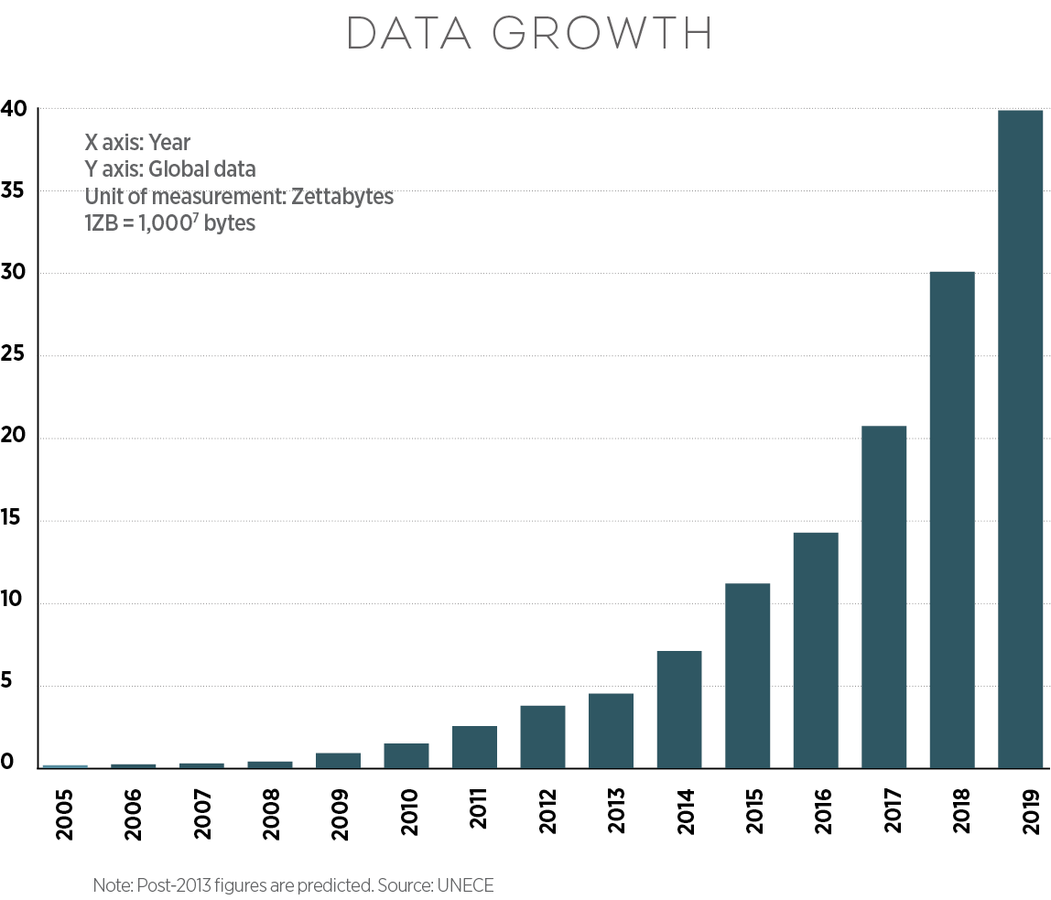

Infrastuctures logicielles et architecturales

Algorithme MapReduce de Google pour trier et grouper l'information sur les machine
- MapReduce est un modèle de programmation massivement parallèle adapté au traitement de très grandes quantités de données.
- Les programmes adoptant ce modèle sont automatiquement parallélisés et exécutés sur des clusters.
- Le système de traitement temps réel assure le partitionnement et le plan d'exécution des programmes tout en gérant les inhérentes pannes informatiques et indisponibilités.
- Une application typique MapReduce traite plusieurs téra-octets de données et exploite plusieurs milliers de machines.
Hadoop est un projet Open Source géré par Apache Software Fundation basé sur le principe Map Reduce et de Google File System, deux produits Google Corp.
Il est tout à fait adapté aux stockages de grande taille et aux analyses de type "ad hoc" sur de très grandes quantité de données.
+ Yahoo Corp, 1.5 téra-octet de données a été trié en 62 secondes
+ Facebook ingère 15 térabytes de nouvelles données/jour



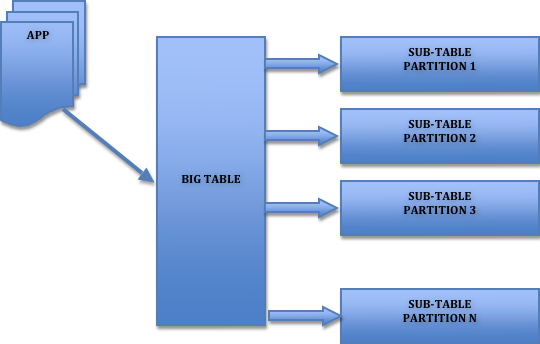
BigTable est un système de gestion de base de données compressées, haute performance, propriétaire, développé et exploité par Google
C'est une base de données orientée colonnes, dont se sont inspirés plusieurs projets libres, comme HBase, Cassandra ou Hypertable.
Apache Spark est un framework de traitements Big Data open source construit pour effectuer des analyses sophistiquées et conçu pour la rapidité et la facilité d’utilisation.
Spark présente plusieurs avantages par rapport aux autres technologies big data et MapReduce comme Hadoop et Storm.
Spark propose un framework complet et unifié pour répondre aux besoins de traitements Big Data pour divers jeux de données, divers par leur nature

+ L’architecture de Spark est très rapide et corrige les lenteurs d’Hadoop, dues à son architecture (Hadoop MapReduce travaillait directement avec les fichiers sur le disque en HDFS)
+ Spark va charger les données en mémoire vive de façon à pouvoir optimiser de
multiples traitements.
+ Il est typiquement de 10 à 100 fois plus rapide que Hadoop MapReduce.
+ Spark a trié 100 To en 1 406 secondes sur un cluster Amazon ec2 de 207 noeuds de 244 Go de mémoire et disque SSD (réalisé par Databricks).
+ Spark, le Big Data analytique est en train de réaliser peu à peu la promesse d’un traitement volumineux en temps réel.
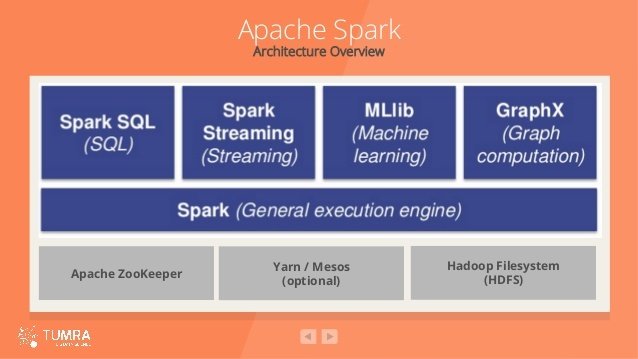
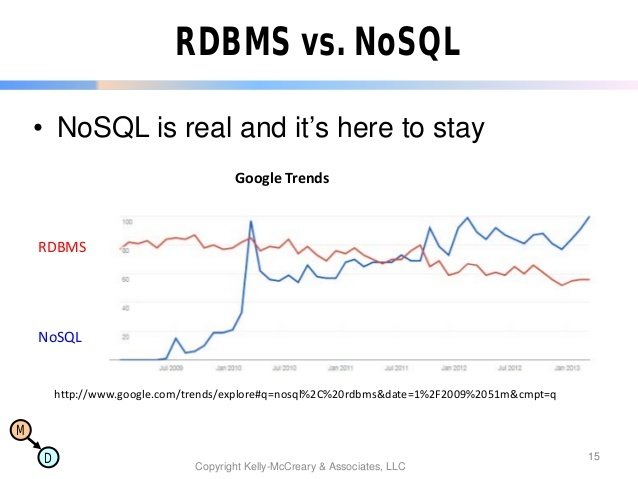
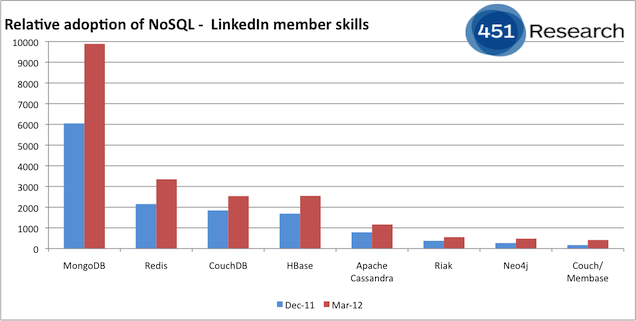
Le mouvement NoSQL est-il une avancée ?
Problèmatique: L’idée de bases de données relationnelles n’est pas nouvelle et souffre de son ancienneté face au besoins de volumétrie et matériels actuels des plateforme du Web.
+ La victoire du relationnel dans le passé est incontournable, c'est une révolution sans précédent
+ Une base de données relationnelle est idéale pour assurer d’excellentes performances et l’intégrité des données sur un serveur dont les ressources sont par définition limitées.
+Avec l’avènement de l’informatique distribuée, il ne s’agit plus de faire au mieux par rapport au matériel, mais d’adapter les contraintes logicielles aux possibilités d’extension offertes par la multiplication des machines.
+ Les besoins ont changé, les types de données manipulées ont aussi évolué dans certains cas, de même que les ressources matérielles.
+ Les besoins se sont modifiés lorsque les sites web dynamiques ont commencé à servir des millions d’utilisateurs.
+ Enfin, le mouvement NoSQL constitue une évolution dès lorsque l’on sait en profiter
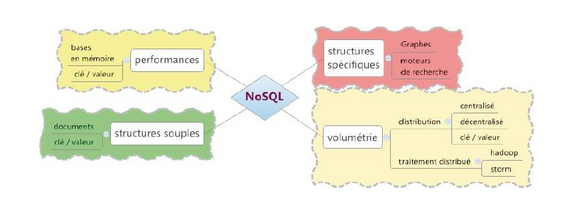
Les différentes familles du NoSQL
+ Paires clé-valeur : les moteurs NoSQL les plus simples manipulent des paires clés valeur, ou des tableaux de hachage, dont l’accès se fait exclusivement par la clé.
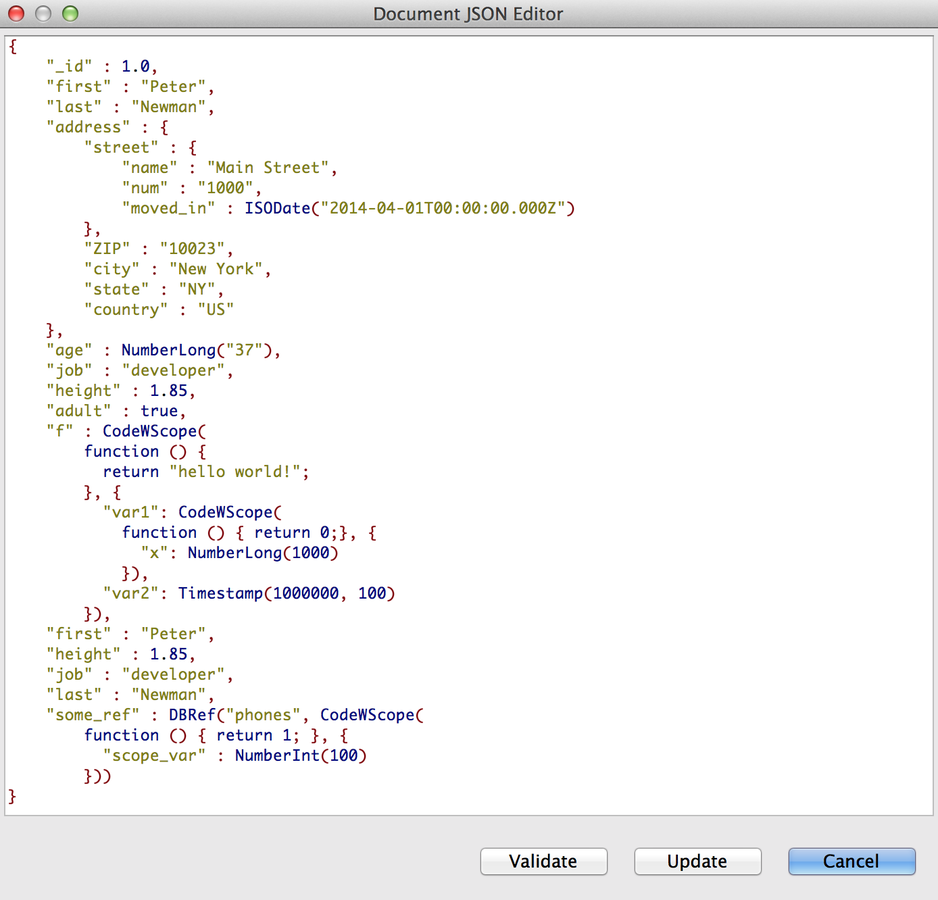
+ Les moteurs orientés documents : le format de sérialisation et d’échange de données le plus populaire est aujourd’hui le JSON.
+ Les moteurs orientés colonnes : chaque ligne est identifiée uniquement par une clé, ce qu’on appelle dans le modèle relationnel une clé primaire, et les données de la ligne sont découpées dans
des colonnes.
+ Index inversé: un index inversé est une correspondance entre un terme, ou du contenu,et sa position dans un ensemble de données, par exemple un document ou une page web.
+ Structures particulières: il nous reste juste à regrouper les moteurs NoSQL qui nerentrent pas dans les catégories précédentes, comme les moteurs orientés graphe.
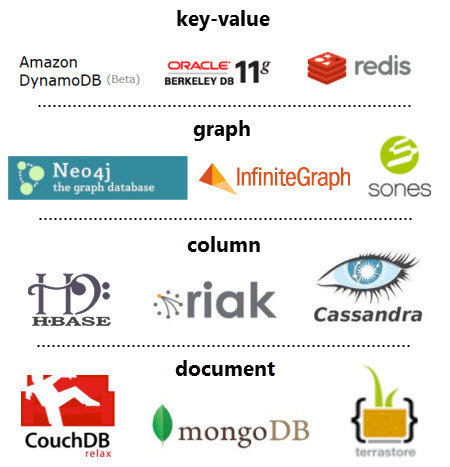
Les 4 grandes familles NoSQL
Bases de données orientés colonnes
+ Les colonnes sont statiques pour une base relationnelle, elles sont dynamiques pour une base de données orientée colonnes
+ Possibilité d'ajouter des colonnes dynamiquement sans le stockage pour les valeurs Null.
+ Pour des raisons de performances les colonnes sont triées sur le disques
+ Les écritures sont séquentielles pour éviter les latences de disques durs (persistéeset commitées
+Prévues pour stocker des millions de colonnes, ce qui en fait des bases adaptées au stockage one-to-many.
Exemple: Cassandra de Facebook pour les messages et HBase sont des solutions de BDD orientées colonnes. Cassandra permettait à Facebook d'accéder aux messages échangés entre utilisateurs et aux messages comportant certains mots.
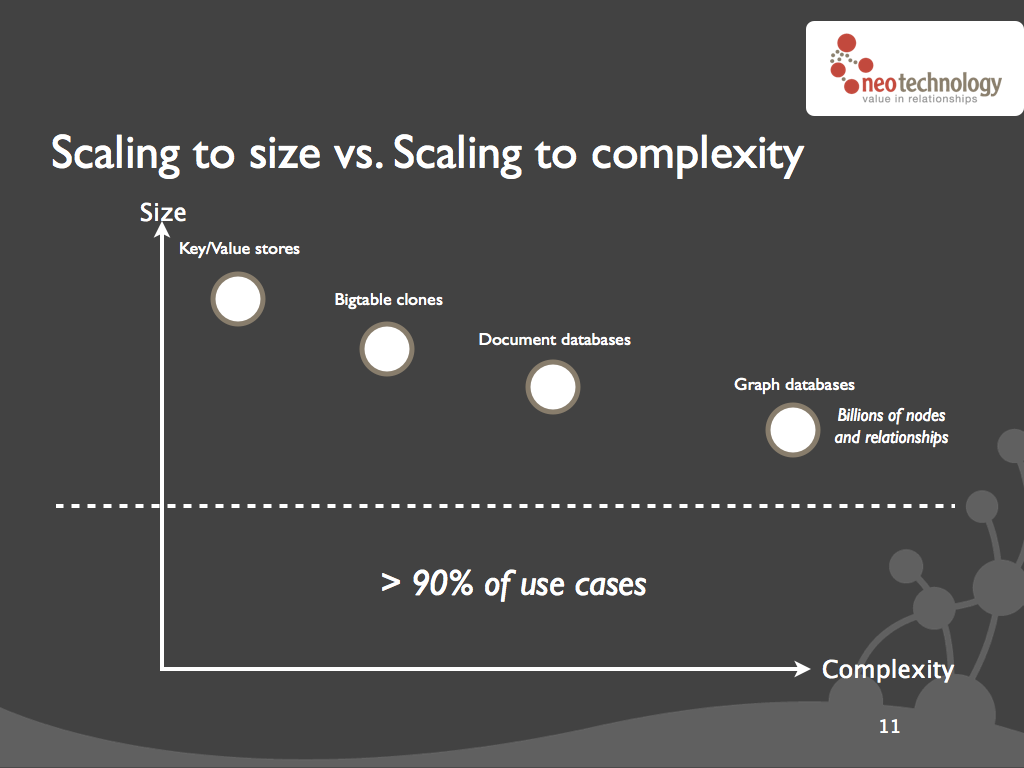
Bases de données orientées graphes.
Les bases de données orientés graphes n'ont pas pour but premier de résoudre des problèmes de performances mais plutôt de palier à des problèmes impossibles à résoudre avec des BDD relationnelles tel que les Graphs (arbre, matrice...)
Exemple: Neo4J semble être actuellement la solution la plus mature.
Base de données clé-valeur
+ Les bases de données clé-valeur sont de grosses tables de hashage, leur légitimité se trouve dans le fait que les entités sont, dans une grande partie des cas, rapatriées à partir d'un identifiant.
+ On peux choisir le niveau de consistance. ce niveau est défini par un quorum correspondant aux nombres de réponses de la part des partitions pour lequel on considère les données consistante.
Exemple: Redis ou DynamoDB
Bases de données orientées documents
+ Elles sont une évolution des bases de données clé-valeur, où à une clé, est associé un document dont la structure est libre.
+ De part son modèle, ces BDD se pré destine au stockage d'informations one-to-one et one-to-many et au stockage d'informations de session, de données de fichiers, pages web, etc
Exemple: MongoDB ou CouchDb
Les 4 grandes familles NoSQL
+ Les principes du relationnel en regard du NoSQL
+ Les structures de données
+ L’agrégat: L’agrégat permet de créer une unité d’information complexe .
+ La centralité de la donnée
+ La modélisation de l'organisation d'information
+ La rigidité du modèle relationnel
+ Le partitionnement de données
+ Rapidité de développement d'application
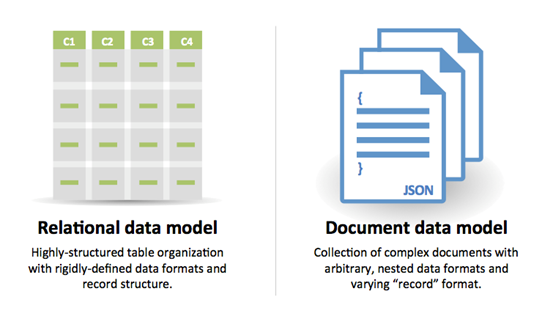
Les différences et points communs du NoSQL et SGBDR
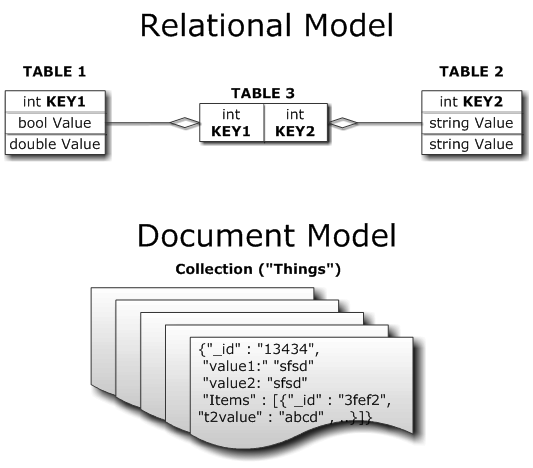


+ Évolutivité des méthodes de projets Agiles, Scrum, XP...
+ Robustesse vs. Souplesse des entrées/sorties et du format JSON
+ Temps de réponse et disponibilité
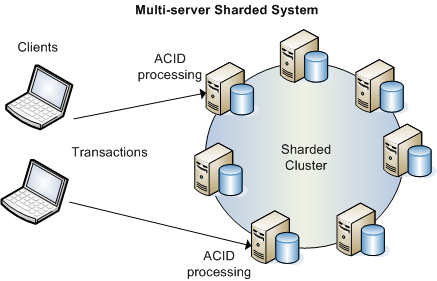
+ Réplication et Sharding des noeuds
+La volumétrie de données
+ Le besoin: transactionnel, analytique, traitements par lots...
+ Le besoin fonctionnels des applications
+ Maturité, documentation, communauté
3 points communs des moteurs NoSQL
-
Le schéma implicite
-
Le langage SQL
-
Le logiciel libre.


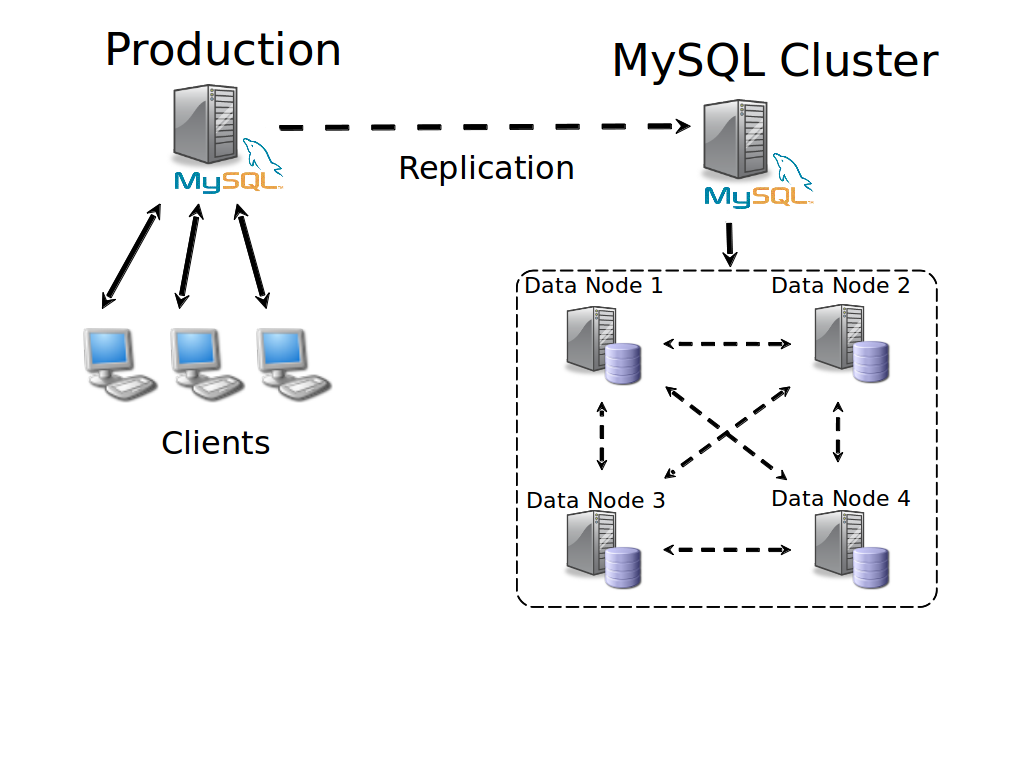
Replication MASTER-MASTER | MASTER-SLAVE
- Le partitionnement horizontal
- Le partitionnement vertical
- Le partitionnement par liste
- Le partitionnement par intervalle
- Le partitionnement par hash
- Sous-partitionnement
- ...
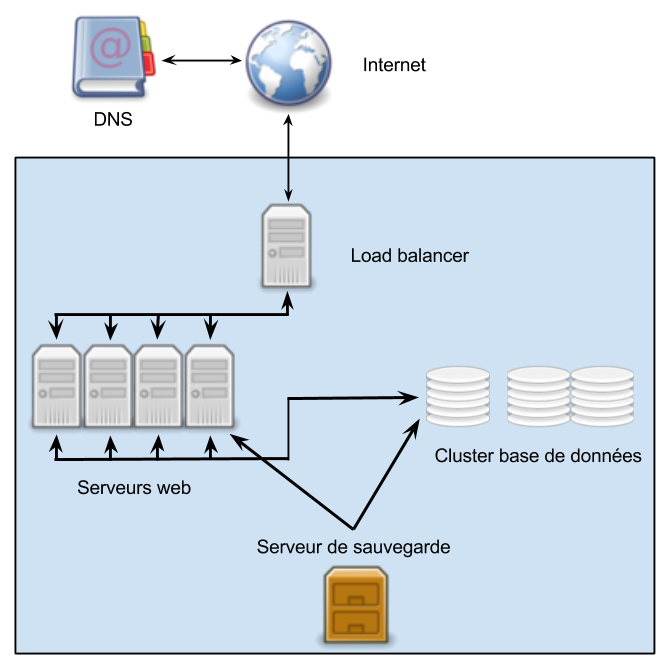
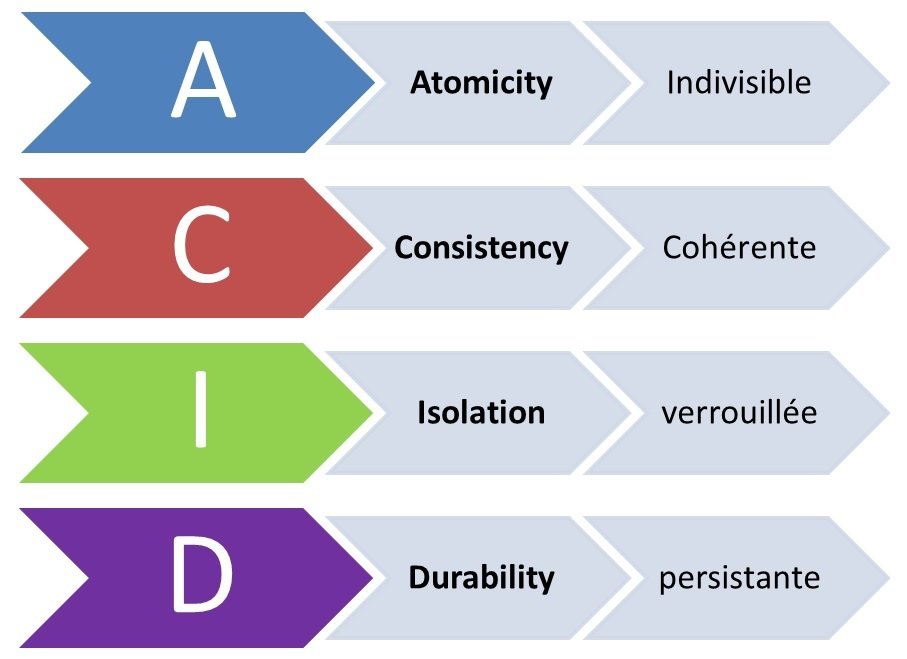
SGBDR: Transactions et répartitions ACID



- Amélioration des performances
Certains moteurs NoSQL ont pour but d’augmenter au
maximum les performances de la manipulation des données, soit pour offrir un espacede cache en mémoire intermédiaire lors du requêtage de SGBDR, soit en tant que SGBD à part entière, qu’il soit distribué ou non
- Assouplissement de la structure
Pour s’affranchir de la rigidité du modèle relationnel,
les moteurs NoSQL simplifient la plupart du temps la structure des données (utilisations de schémas souples comme le JSON, relâchement des contraintes, pas d’intégrité référentielle entre des tables, pas de schéma explicite au niveau du serveur).
- Structures spécifiques
Certains moteurs NoSQL sont dédiés à des besoins spécifiques,
et implémentent donc une structure et des fonctionnalités focalisées sur un cas d’utilisation.
- Volumétrie
L’un des aspects importants des moteurs NoSQL est leur capacité à monter
en charge. C’est sans doute même la raison première de la création du mouvement NoSQL.
Supporter des volumétries importantes passe par une distribution du stockage et
du traitement.
Avantages du NoSQL
NoSQL: Théorème de CAP
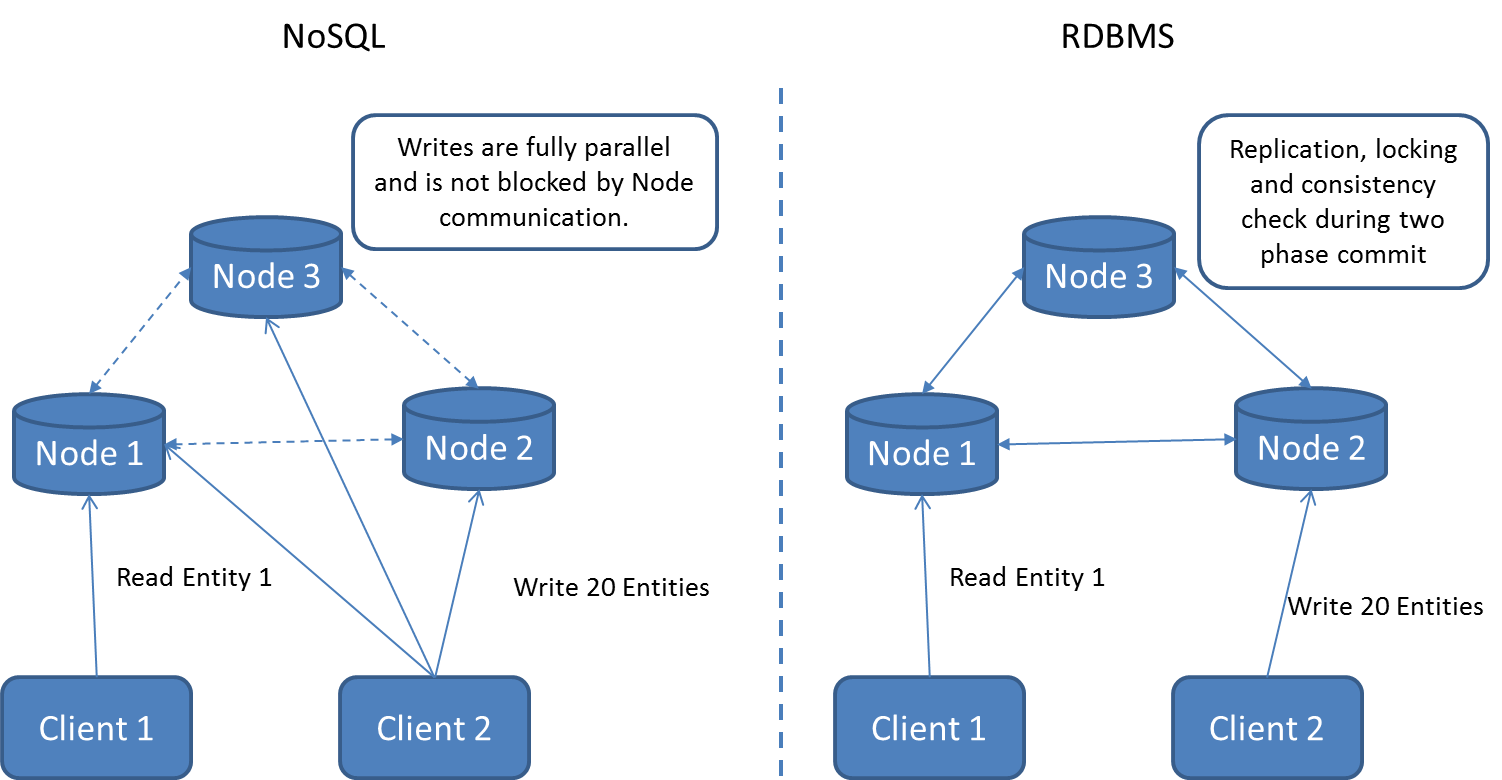
Cohérence (Consistency) : Tous les noeuds du système voient exactement les mêmes données au même moment
Disponibilité (Availability) : Les données sont à tout moment disponibles, si un noeud ne répond plus ce ne doit pas empêcher les autres de continuer à fonctionner correctement.
Résistance au morcellement (Partition-Tolerance) : En cas de pertes de messages entre les noeuds, le système doit continuer à fonctionner normalement.

Réplication automatique et autosharding dans MongoDB
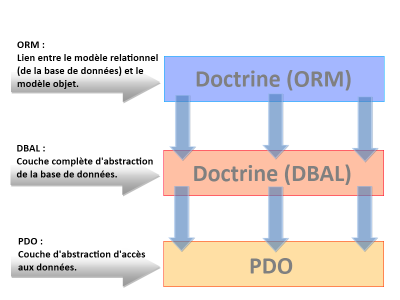
Le défaut d’impédance

Les ORM



+ Manipulation de documents et collections de documents
+ Autosharding et réplication automatique.
+ Les champs d'un enregistrement sont libres
+ Redondance - Simplification de tâches (backups, ... )
+ Possibilité d'indexer les champs des documents
+ Protocole : natif, question-réponse sur un socket.
+ Format BSON écris en C++
+ Simplicité d'utilisation du point de vue du développement client
+ Peut être utilisé comme système de gestion de fichier avec GridFS inclus
+ Prise en charge la réplication via un modèle maître-esclave pour la tolérance au pannes et répartition de charges
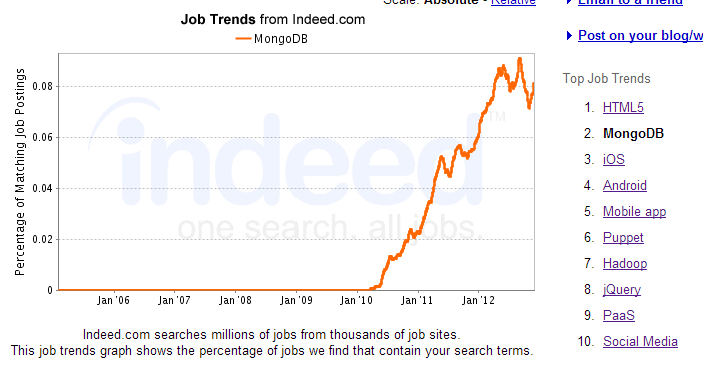
+ L'un des plus populaires moteurs NoSQL et des plus performant du marché
+ Utilisé par de gros acteurs Google, Twitter, Ebay
Points Forts

Mongo 3 en marche!
Installation
http://doc.ubuntu-fr.org/mongodb
* apt-get install mongodb *

Installation du client PHP
sudo pecl install mongo
extension=mongo.so
Premières instructions en Mongo Shell
show dbs
use test
show collections
db.post.find()
db.post.findOne()
db.post.insert()
db.post.update()
db.post.find({vue:{$gt: 4000}})
db.post.find({vue:{$gt: 2000}}).limit(2)
db.post.find({vue:{$gt: 2000}}).limit(2)
db.post.find({vue:{$gt: 2000}}).sort({vue: -1}).limit(2)
db.pages.find({visible: {$exists: true}})
db.unicorns.find({loves: {$in:['apple','orange']}}
db.unicorns.find({gender: 'f',$or: [{loves: 'apple'},{weight: {$lt: 500}}]})
db.unicorns.update({weight: 590}, {$set: { name: 'Roooooodles'})
db.unicorns.update({name: 'Pilot'}, {$inc: {vampires: -2}})
db.unicorns.update({name: 'Aurora'}, {$push: {loves: 'sugar'}})
...
Répartition de charges dans Mongo
3 notions à connaître
- L' indexation qui permet d’effectuer des requêtes rapides sur les collections
- Le Sharding qui permet de répartir une collection sur plusieurs serveurs
- Les ReplicaSet qui dupliquent les données pour en garantir la disponibilité et l’intégrité
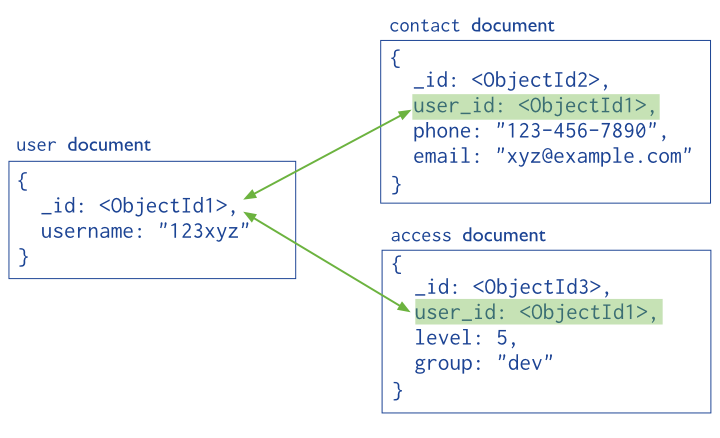
Les collections sont à MongoDB ce que les tables représentent dans une base de données relationnelle classique et les documents correspondent aux enregistrements
Contrairement à une base de données relationnelle avec un modèle normalisé, qui permet d’éviter les redondances et les dépendances incohérentes entre les tables
Chaque document JSON peut contenir la totalité d’un
objet métier.
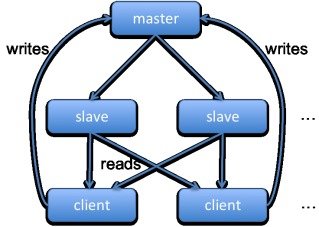
La réplication sous Mongo
La réplication se doit de garantir la redondance des données, ainsi que le basculement automatique etinvisible des applications clientes en cas de panne matérielle ou logicielle.
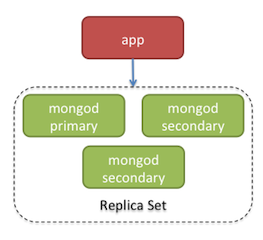
Un Replica Set est composé de trois nœuds physiques au minimum
• Un nœud Maître
• Un nœud Esclave
• Un nœud Arbitre
1./ L’application cliente doit communiquer avec le nœud Maître pour ses transactions d’écriture et de lecture.
2./ Sur le nœud Esclave, la lecture seule est autorisée
3./ Le nœud Arbitre n’a qu’un rôle de supervision
4./ Si le nœud Maître connaît un arrêt de service, le nœud Arbitre désigne alors l’Esclave comme nouveau Maître.
5./ L’opération est invisible aux applications clientes et aucune perte de données n’est à déplorer
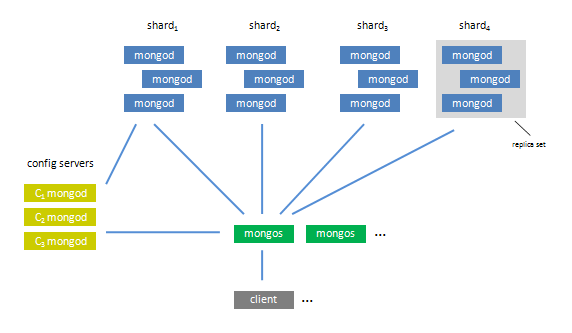
Le sharding sous Mongo
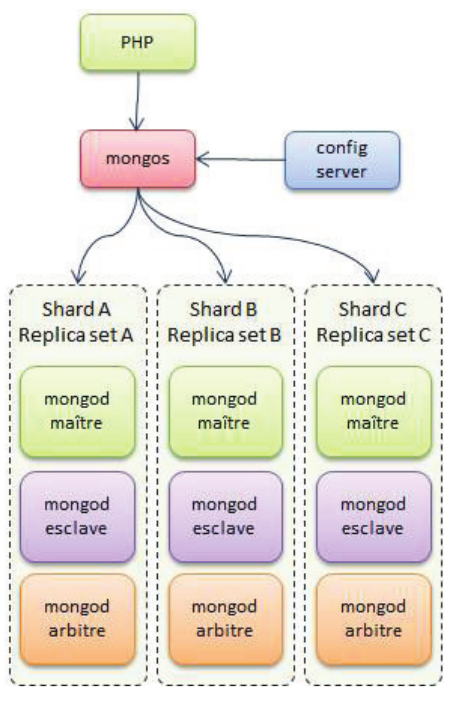
+ Fonctionnalité phare de MongoDB, le sharding définit
les partitions horizontales d’une collection.
1./ Après avoir définis les shards physiques, composés des différents Replica Sets disponibles, il est nécessaire de choisir une clé de sharding.
2./ L’accès à une collection se fait de manière transparente à travers un nœud relais, appelé le Mongos qui est le véritable aiguilleur de notre architecture MongoDB
3./ Ce sont des sortes de routeurs, connectés aux nœuds de configuration. Les nœuds de configuration stockent
et répliquent les données de configuration comme les informations relatives aux différents shards ou la localisation des données sur les serveurs
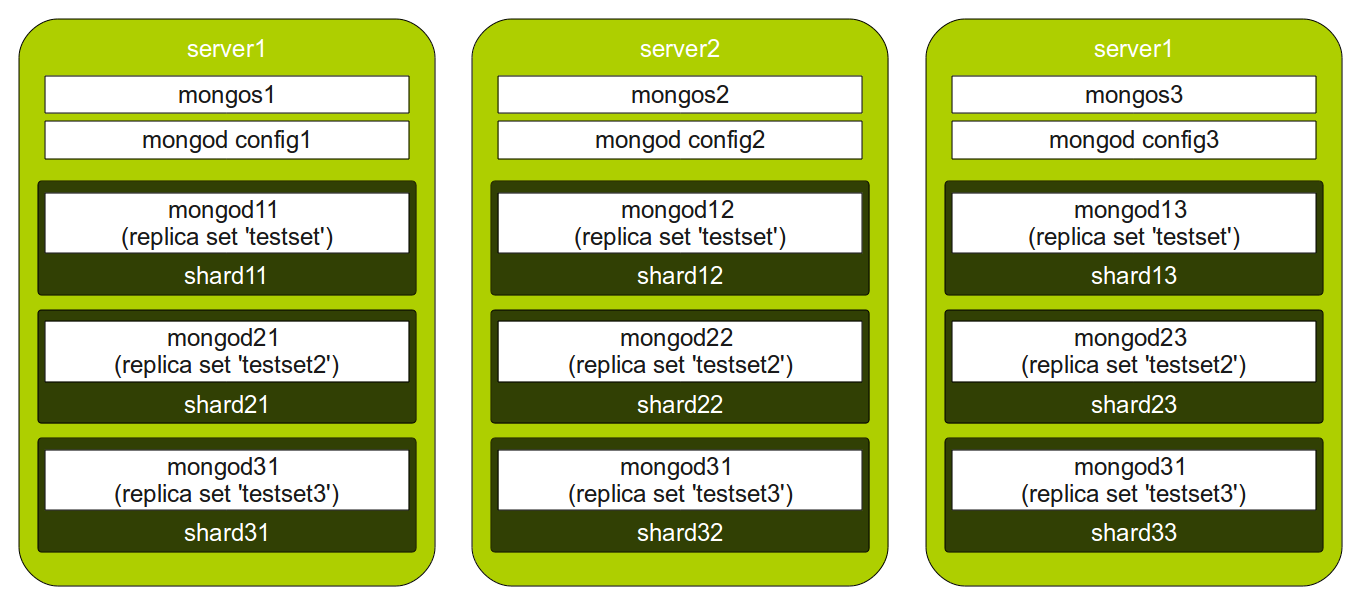
Autosharding et réplication automatique

+ Redis est une base de données open source de type clefs-valeurs mono-threadée.
+ Une grosse HashMap, mais avec des données peu structurées
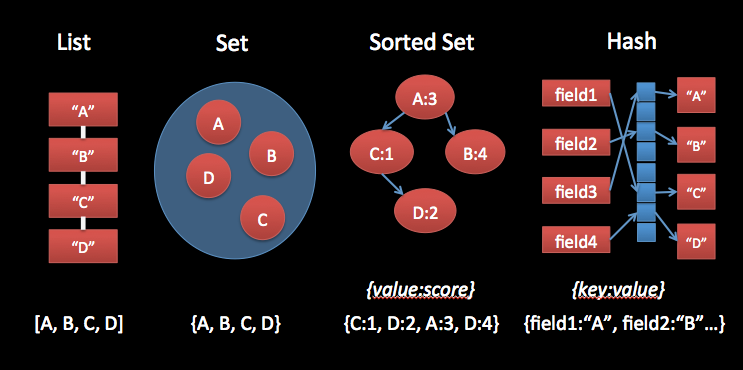
+ Type de stockage: Chaînes de caractères, Listes, Hash, Set, Set triés
+ Très simple d'utilisation et vitesse de lecture et d'écriture est vertigineuse
+ Toutes les opérations sont atomiques
+ Philosophie: Pas de WHERE mais avec un système de Clef
+ Limités par la taille de RAM car Redis garde toutes ses données en mémoire vive
+ Redis sauvegarde régulièrement ses données sur le disque dur
+ Supporte la réplication sur de multiples serveurs.
Présentation
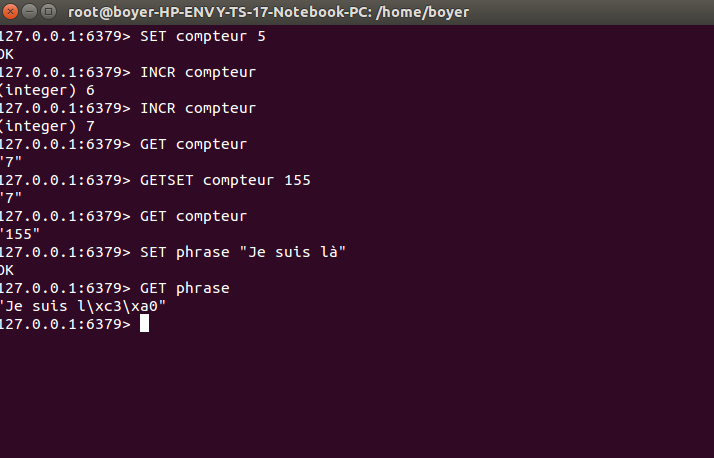
String
+ Une clef, on peut y associer une valeur (integer, string, float, image...)
+ La limite est de 1 Go.
+ Les commandes associées sont SET, GET, INCR, DECR, et GETSET.
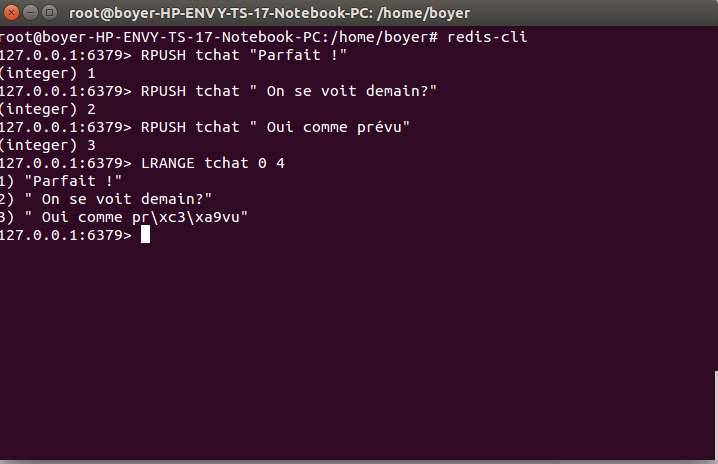
Listes
+ Les listes de Redis sont des listes liées.
+ Rapide d'insérer un élément en tête ou en queue de liste.
+ Idem pour la vitesse d'accès à un élément dans la liste par son index.
+ Les commandes commencent en général par L comme List et sont RPUSH et LPUSH qui permettent respectivement d'ajouter un élément en fin ou en début de liste
+ LRANGE pour obtenir une partie des éléments de la liste et LINDEX pour obtenir un seul élément de la liste
+ LLEN pour obtenir la taille de la liste.
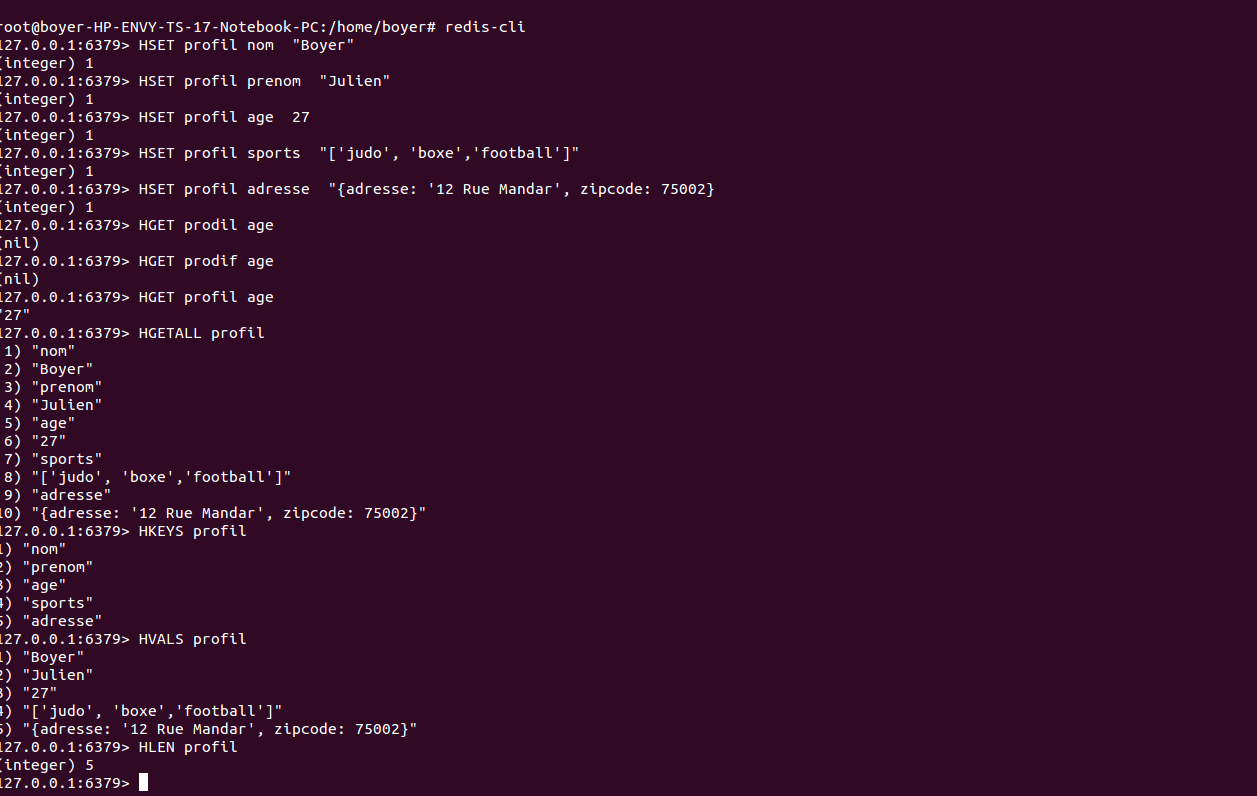
Hash
+ Permet de stocker un enregistrement de couples de clef/valeurs.
+ Les commande sont HSET, HGET, HLEN, mais aussi HGETALL
+ HINCRBY pour incrémenter un compteur dans la hash
+ HKEYS et HVALS pour obtenir toutes les clefs ou valeurs
+ HDEL pour faire le ménage.
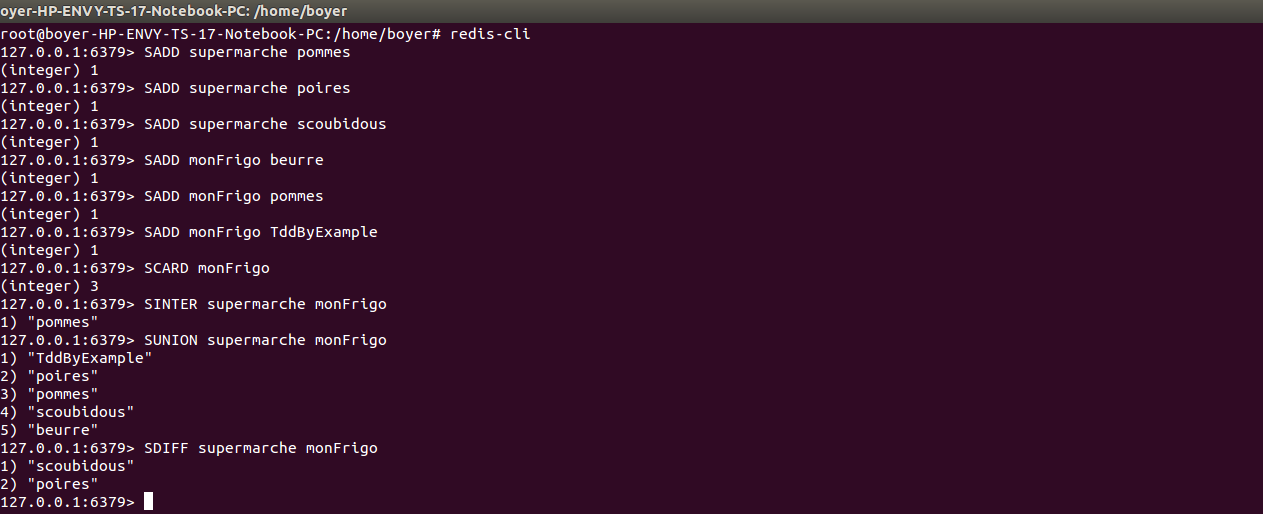
SET
+ Les Sets sont des collections d'objets non ordonnées.
+ Les commandes commencent toutes avec un S comme Set
+ Les commandes sont SADD pour ajouter une valeur à un set
+ SCARD pour obtenir la taille (cardinalité) d'un set
+ SINTER, SUNION, SDIFF qui permettent respectivement d'obtenir l'intersection, l'union et la différences entre 2 sets.
+ SINTERSTORE permet de stocker dans un nouveau set l'intersection de 2 autres.
+ Similaires à des Sets mais avec des scores ce qui permet de faire des tris
+ Les commandes commencent toutes par Z comme Zorted Set.
+ ZADD, ZCARD, ZINTER, ZUNION, ZDIFF (avec Z)
+ ZRANGE, ZRANGEBYSCORE et ZRANK qui tirent parti des scores des données stockées.
SET TRIES
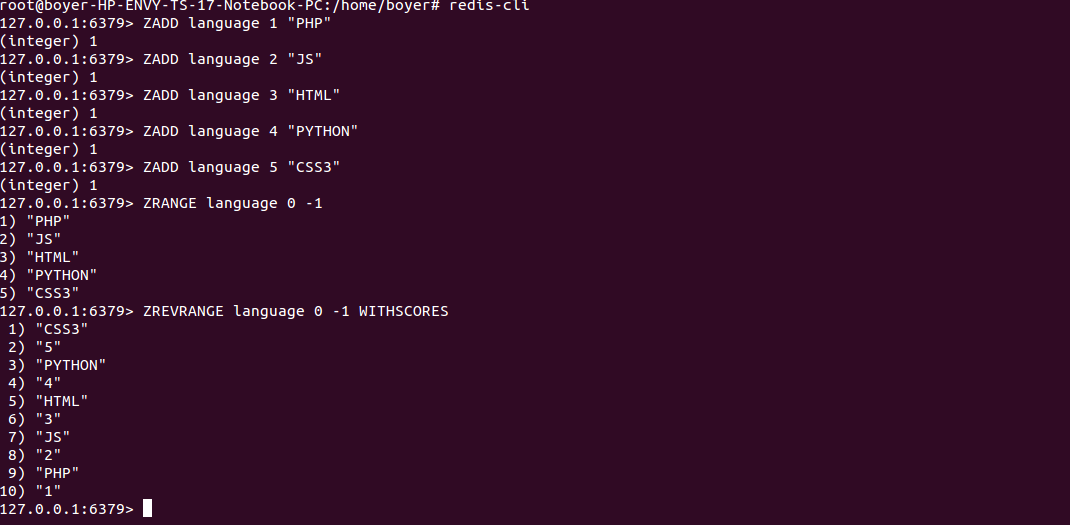
Possibilités offertes
- Une API Pub/Sub qui permet de poster et de recevoir des messages sur des Channels
- Durée de vie à une clef (EXPIRE clef / EXPIREAT ) : purge ses données automatiquement
- Passer une série de commandes dans une transaction (MULTI et EXEC) si la clef change (WATCH)
- Utiliser plusieurs bases de données (16 disponibles)
- Brancher un ou plusieurs slaves: la réplication est extrêmement rapide ;
- Scripter des commandes dans le serveur avec le langage Lua
-
Multiplier les slaves pour accéder à vos données en lecture et ne garder qu'un master pour les écritures.