Deep Dive

目的
GraphQLリテラシーを高め
武器を増やし
各自が適切な判断を下せるようになる為
Before

After

アジェンダ
- GraphQLの作者の紹介
- GraphQLの概要の説明
- GraphQLサーバーの仕組み
- Handson
- アンチパターン
- GraphQLの使われ方
Origin
Lee Byron

-
GraphQLの父
- Facebook社
- 彼の目標はGraphQLをWeb Platformの標準にする事
- プロジェクトは2012年から社内で進行
- 全て彼の引いたスケジュールに沿って進行しているらしい

GraphQLはDSL
- 特定のタスク向けに設計された言語
- SQLとか、GraphQLとかも
- Dockerfileや各種yamlも基本的にそう
GraphQL Schemaの基本要素
情報検索の為のQueryの木を構築
データ操作の為のMutationの木を構築
それらをSchemaという木の部分木として持つ
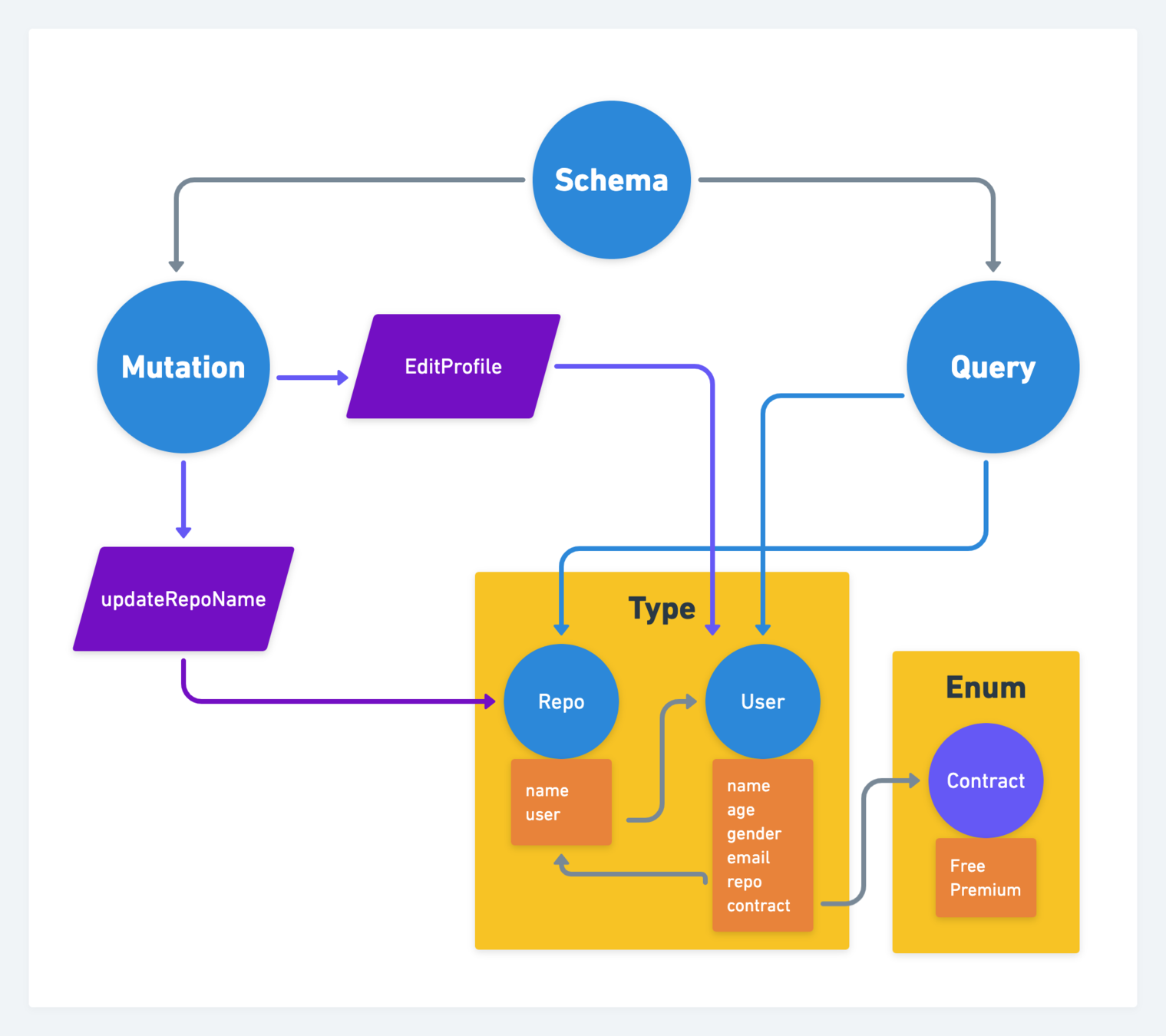
Example
この例だと、Schema木には部分木としてQueryしかいないのがわかる
つまり、データ検索しかできなく、データ操作が不可
この様に、QueryとMutationを必ずセットで提供しなくても良い
type Author {
id: Int!
firstName: String!
lastName: String!
posts(findTitle: String): [Post]
}
type Post {
id: Int!
title: String!
author: Author!
}
type Query {
posts: [Post]
}
schema {
query: Query
}Operation
Operation
Schemaを定義したらそのSchemaを前提にした操作を記述できる
これは静的・動的に記述できる
この操作はOperationと呼ばれている (英訳そのまま
Types
- query
- mutation
- subscription
- describes
@で始める
@で始まる印を付ける
デコレータみたいなもの
どんな処理がされるかはSchemaからはわからないので命名と型定義が重要
他の部分も基本的に最終的にはPremitiveな値が返って来るぐらいしか定義できていない
ので、そんなものかもしれない
directive @deprecated(
reason: String = "No longer supported"
) on FIELD_DEFINITION | ENUM_VALUE
type ExampleType {
newField: String
oldField: String @deprecated(reason: "Use `newField`.")
}概要のまとめ
- GraphQLはDSL
- そのフォーマットに沿ってAPIsのSchemaを定義できる
- そのSchemaを前提にしたOperationの記述が可能
- Directiveの定義も可能
GraphQL Serverの実装
GraphQL Serverとは
- GraphQLで定義されたSchemaに許されるOperationを全て実行できるサーバーの事
- 接続の際に/graphqlに繋ぐサンプルが多いが、全てWebsocket等で実装しても行ける
- 重要なのは、schemaで許されるoperationを解決できる事
GraphQLの最小用途
operationさえ解決できれば何でもok
同一プロセスでも良いし、実際同一プロセスにengineとclient同梱のアプリも割とある
operation textとvariablesをengineに与えて計算させる。
engineは基本的に誰かが作った便利なライブラリがあって、それらはresolverを要求する実装が多い
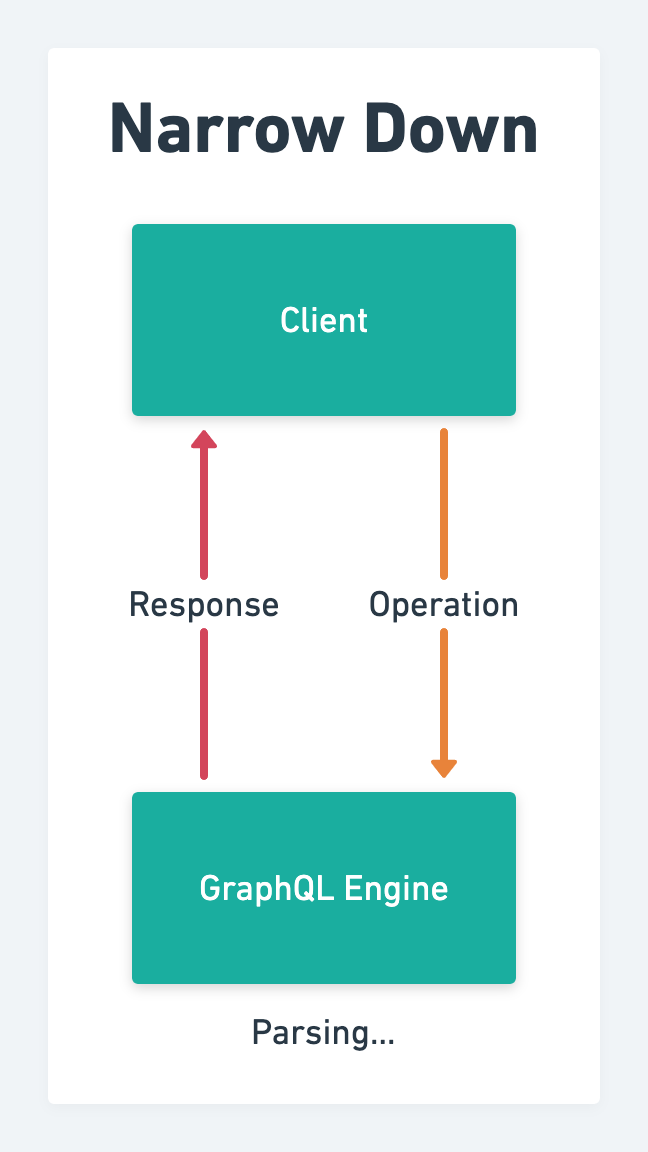
Parsing Operation
engineはmiddlewareを設定できたり、operation textを解析して対応するresolverに処理の移譲をする実装が多い
resolverはschema忠実なresolverの実装が必須
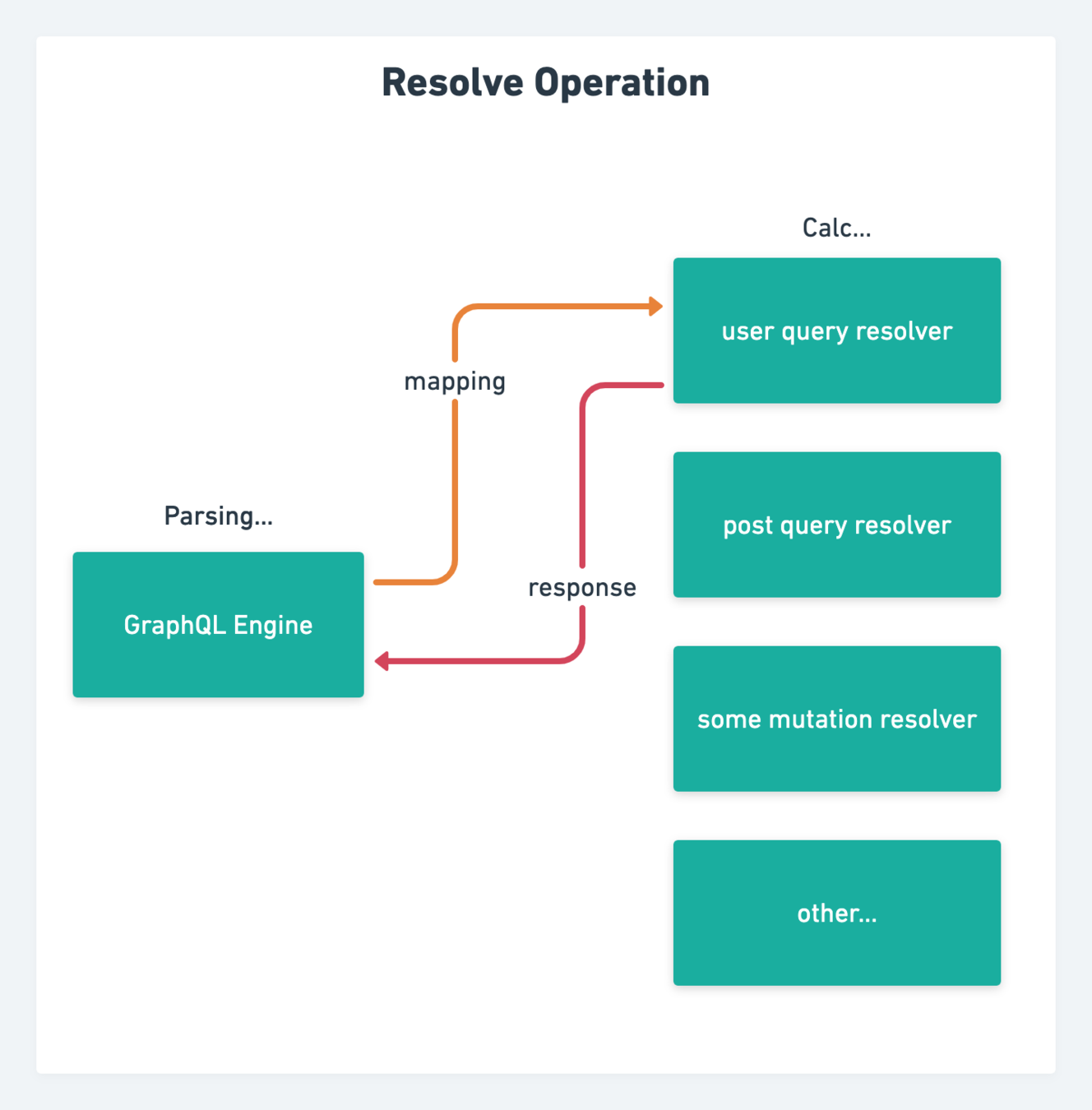
この機構をサーバー側に実装する必要がある
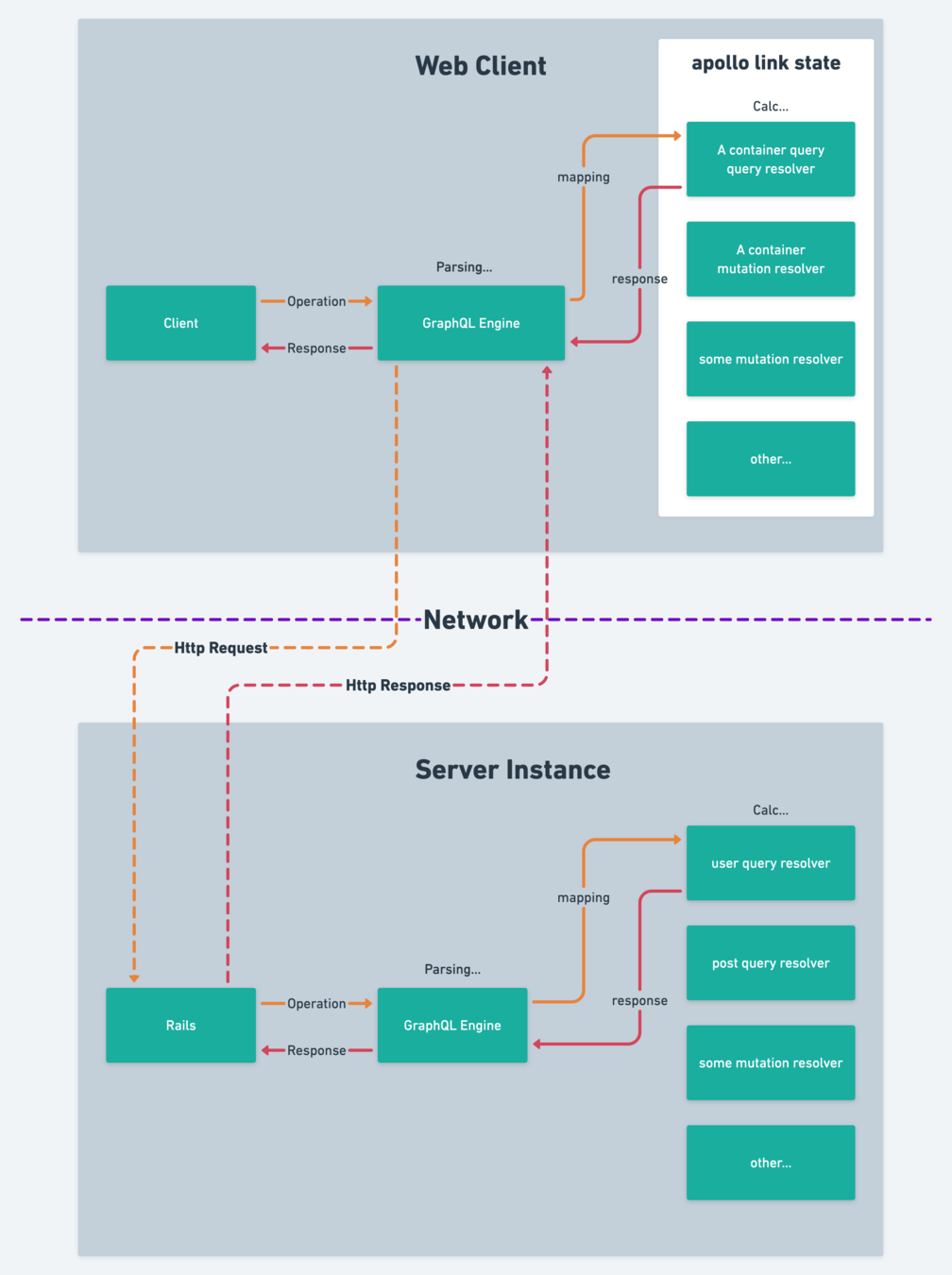
実装後の構成図
これはフロントが
Vue.jsとapollo link state
バックエンドがgraphql ruby
の図
フロントが一度operationを構文解析し、フロント側のresolver又はcache機構で解決可能なoperationならそこで解決する。
解決できないoperationならHTTP等を利用してサーバー側にoperationの解決を依頼し、その結果をフロント側で利用する
Hands on
- GraphQLのschemaを書いてみる (5分)
-
graphql-codegenを触る (20分)
- 環境構築 (5分
- ts (5分
- react apollo (5分
- resolver (5分
Hands on参考資料
https://qiita.com/mizchi/items/fb9f598cea94d2c8072d
環境準備
$ mkdir graphql-handson
$ cd graphql-handson
$ npm init
// 作業内容をgit管理したい方はどうぞ
$ git init
$ brew install gibo
$ gibo dump macOs node > .gitignore
// -----------
$ touch codegen.yml
$ mkdir ./graphql
$ touch ./graphql/schema.graphql
$ yarn add graphql @graphql-codegen/cli @graphql-codegen/typescriptcodegen.yml
overwrite: true
schema:
- ./graphql/schema.graphql # or - http://localhost:3000/graphql
generates:
./client/gen/graphql-client-api.ts:
plugins:
- typescript1. Schema定義
schema.graphqlファイルに定義してください
挑戦したい方は自由に書いてください
初めてであまりよくわからない方は上に貼ってあるGraphQL-codegenのSchemaを参考に書いてみてください
参考にすると良いサイト
Custom scalar typeの定義
type Author {
id: ID!
firstName: String!
lastName: String!
posts(findTitle: String): [Post]
}
type Post {
id: ID!
title: String!
author: Author!
}
type Query {
posts: [Post]
}
schema {
query: Query
}schema.graphqlをベースに生成
$ yarn graphql-codegen --config codegen.ymlschema.graphqlをベースに生成
$ yarn graphql-codegen --config codegen.yml続きはこちら
Practice
アンチパターン
RESTの場合だとURLとHTTP Methodをセットにして、resolverならずcontrollerに処理を投げている
なので、GraphQLを使ったからと言ってエンドポイントの設計はなくならないし、無計画に量産してはならない
あくまでもGraphQLのルールのおかげでRESTだと実装が難しかった物がGraphQLの明確なレールやエコシステムのおかげで簡単になっているだけであり、それらを活かさないとGraphQLを使っている意味が殆どなくなる
柔軟でメンテナンスビリティの高い開発をサポートするためにGraphQLに寄り添う。
GraphQLのスタックを導入しただけでは、柔軟でメンテナンスビリティの高いシステムは手に入らない。
(Redux, Vuex, Component system, その他同様。
技術に振り回させない
GraphQLの使われ方
番外編
ネタ編
firestoreと繋ぐ
GraphQLでSchemaを定義 or しない
front側にclientもresolverも設置
clientのrequestをfirestoreに飛ばし、responseをformatに沿って直す
課題
エラーやバグが出た際の特定難しい
黒魔術感あってメンテむずい
AppSyncの方がマシ
※ AppSync登場前に巷でチラホラ流行っていたネタ
トレンド編
apollo link state
- @clientディレクティブ
- Bullet Two
- Bullet Three
@clientディレクティブをqueryとかmutationに付けて、client側でそれを解決をする
Schemaはclient用のを定義すれば、codegenでclient用のコード出力が可能
用途としてはReduxやVuexをやめて、GraphQL、Apollo1本で行こう!って感じ
query myQuery {
todos {
id
title
checked
selected @client
}
}
query {
user(id: 1) @client {
name {
last
first
}
}
}