Mozilla
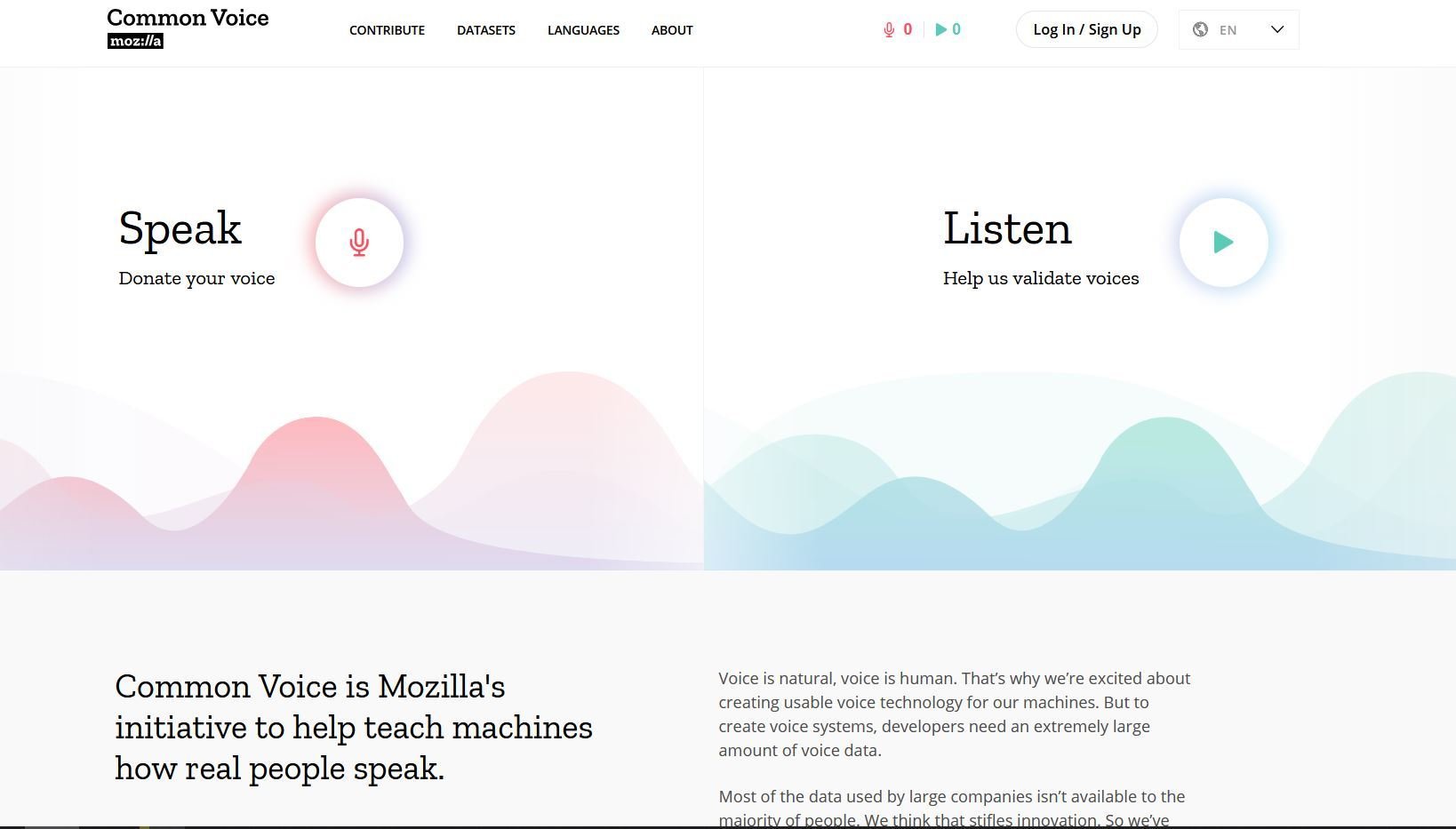
Common Voice

Hello......!
2020

ආයුබෝවන්!
kalindut@gmail.com
Im Kalindu thilanga

cc @ Mozilla UoK

Topics
- Introduction to Mozilla
- Brief about Common Voice
- Mozilla crowdsource
- Dataset
- Ways to engage in contributing into this project

Introduction to Mozilla
- Mozilla is a non-profit organization, it develops, spreads, and supports Mozilla products, thereby promoting exclusively free software and open standards, with only minor exceptions. we're a global community of technologists, thinkers, and builders working together to keep the internet alive and accessible.





Areas of contribution:
Helping Users
Testing & QA Coding
Marketing
Translation & Localization
Web Development
Firefox Marketplace Add-ons
Visual Design
Documentation & Writing Education
Rust Development
VR Development


What is crowdsource?
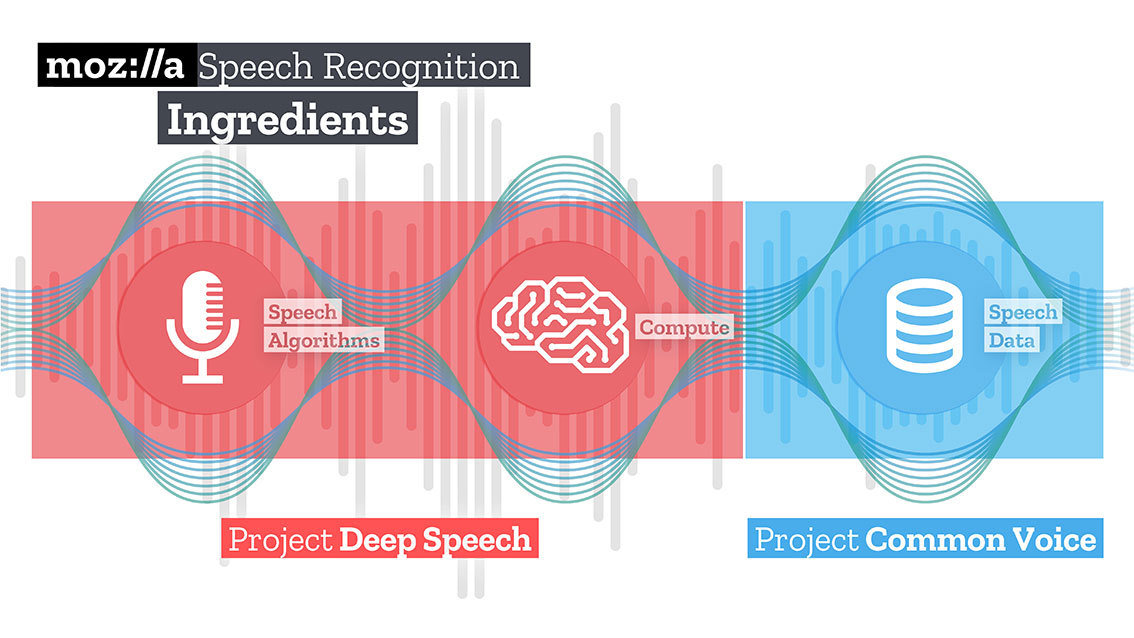
What is Common voice
- The common voice project is Mozilla’s initiative to make speech recognition software more open, accessible, and inclusive. You see, in order to create usable voice technology, an extremely large amount of voice data is required.
- we are gathering voices from all over the world in the hope to build the biggest open-source voice dataset around.
- This data can then be used to make open-source speech recognition that is as good as any commercial product in the market today.
Requirements, Project Directory Structure
- Nodejs
- npm
- yarn
- FFmpeg
- MariaDB or MySQL
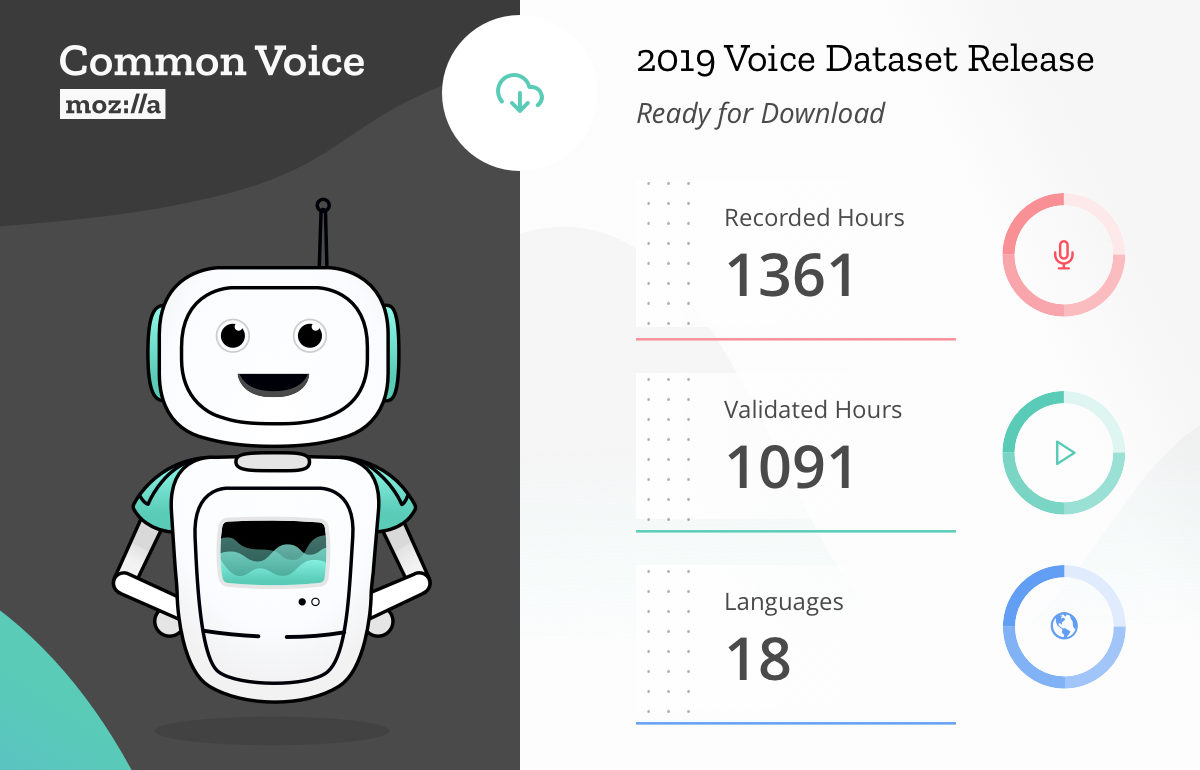
"Mozilla crowdsources the largest dataset of human"
voices available for use, including 18 different languages, adding up to almost 1,400 hours of recorded voice data from more than 42,000 contributors.

Today, we’re excited to share our first multi-language dataset with 18 languages represented, including English, French, German and Mandarin Chinese (Traditional), but also for example Welsh and Kabyle. Altogether, the new dataset includes approximately 1,400 hours of voice clips from more than 42,000 people.


Real?
Free?

YEAH..!
Hello..
Yeah How Can I Help You?
Can I Have A DataSet?
Follow Me !


https://voice.mozilla.org/en/datasets


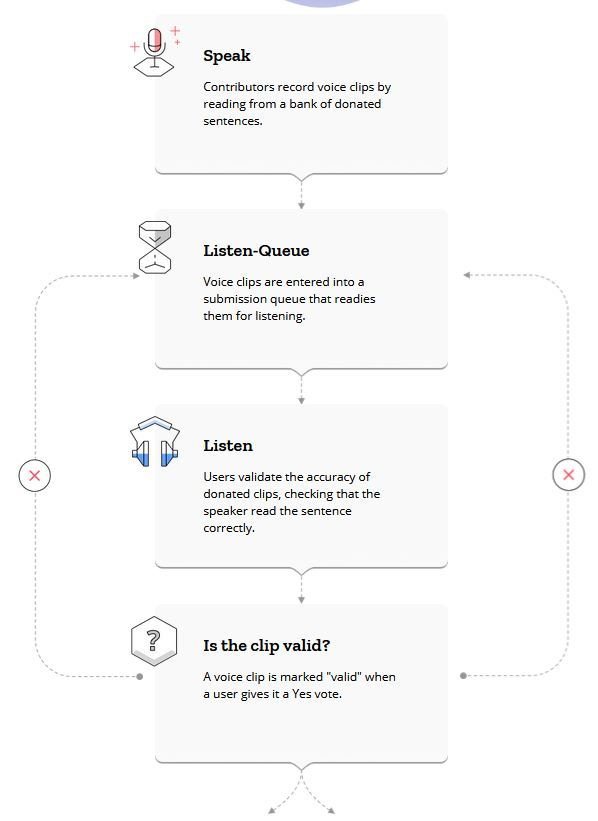
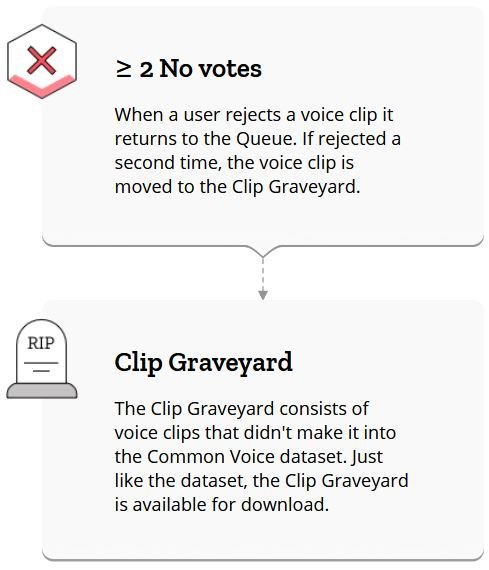
How does it works?
- We’re crowdsourcing an open-source dataset of voices. Donate your voice, validate the accuracy of other people’s clips, make the dataset better for everyone.
https://github.com/mozilla/DeepSpeech


Ways to engage in contributing
into this project
https://voice.mozilla.org/en
Visit Now