Convolutional Neural Networks






So Far - Fully Connected Networks
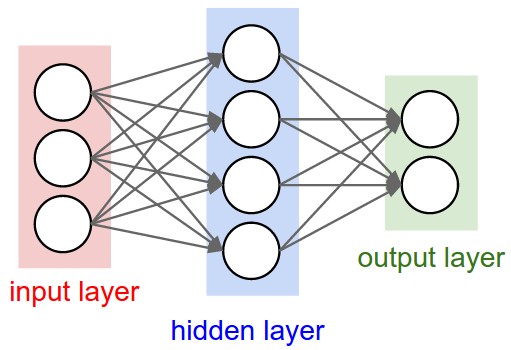
Flattened Input
Full Connectivity

Courtesy: Keelin Murphy
@MurphyKeelin
Image Analysis

256
256
Fully Connected Model:
W1 will have size 256 x 256 x 3
W1, b1
flatten
Loss of spatial information
Input Layer
First Hidden Layer
Wm, bm
Courtesy: Keelin Murphy
@MurphyKeelin
Convolutional Neural Networks

Input Layer
First Hidden Layer
Feature 1
Feature 2
Feature 3
Feature 4
Feature 5
1) Each "channel" of neurons represents 1 feature
2) Each neuron connects only to a small "receptive field"
3) Neurons in the same channel share the same weights (detect the same feature in different locations)
Channels
Courtesy: Keelin Murphy
@MurphyKeelin
Convolutional Neural Networks



Output after applying weights to input data
Courtesy: Keelin Murphy
@MurphyKeelin

Learning Features in Layers
Early Layers
Final Layers
Courtesy: Keelin Murphy
@MurphyKeelin
Terminology



Padding:
Patch-size=
Filter-size=
Kernel-size=
3x3
Stride=1x1

Padding=valid
Padding=same
Courtesy: Keelin Murphy
@MurphyKeelin
Network Layer Types
Convolutional Layer

Fully-Connected
(Densely-Connected) Layer

Max-Pool Layer

Dropout
Layer
Courtesy: Keelin Murphy
@MurphyKeelin

Tensorflow Convolutional Tutorial

Softmax
Courtesy: Keelin Murphy
@MurphyKeelin
Resources for Deep-Learning
Courses:
https://www.coursera.org/specializations/deep-learning
http://www.fast.ai
General:
http://cs231n.github.io/
http://neuralnetworksanddeeplearning.com
http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial
https://ayearofai.com
https://machinelearningmastery.com/
Research:
https://arxiv.org/ (for research literature)
Other:
https://github.com/kailashahirwar/cheatsheets-ai (cheat-sheets for programming)
https://aiexperiments.withgoogle.com (fun stuff with neural nets)
Courtesy: Keelin Murphy
@MurphyKeelin