Learning to Control the Specificity in Neural Response Generation
Zhang et al., ACL 2018
Paper reading fest 20180819
Contents
- Problem
- Ideas
- Architecture & Training method
- Experiment & Result
The Problem
Two major streams of research in NLP:
- task oriented dialog
- general purpose dialog (eg. chit-chat)
=> generative conversational model
Generative conversational
Approach
- Statistical machine translation (SMT)
Conversation is continuous of utterance-response where the model tries to "translates" response for each input.
=> best case: have 1-vs-1 match for utterance-response
Problem?
H: What's your name?
B: My name is B.
H: What's the weather like today?
B: I don't know.
H: Do you like her?
B: I don't know...
H: What do you know?
B: I don't kno....
Ideas
Two major ways to go:
Retrieval-based: Find the best-fit response
- Li et al. 2016a: A diversity-promoting objective function for neural conversation models.
- Zhou et al., 2017: Mechanism-aware
neural machine for dialogue response generation. - Xing et al. 2017: Topic aware neural response generation.
=> Overlay point: Seq2Seq model, rely on preexisting responses
Ideas
Generation-based:
- Serban et al. 2016: Building end-to-end dialogue systems using generative hierarchical neural network models.
- Cho et al., 2014: Learning phrase representations using rnn encoder-decoder for statistical machine translation.
Paper's idea
Response Specificity
introduce an explicit specificity control variable into a Seq2Seq model to handle different utterance-response relationships in terms of specificity.
Model's architecture
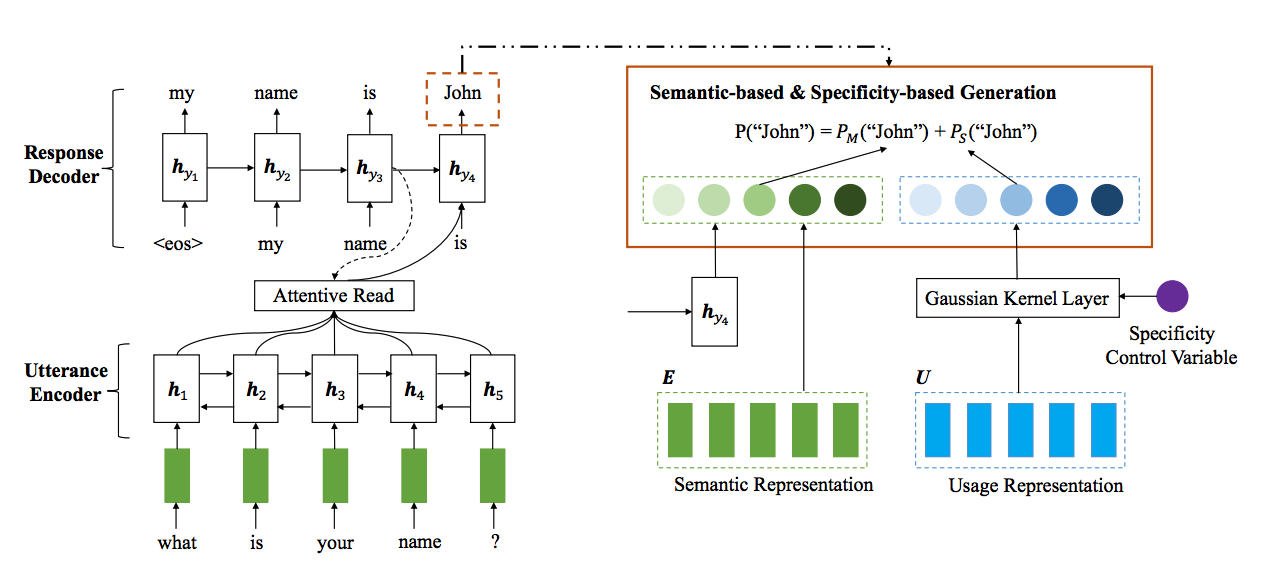
Encoder
Using: GRU
Decoder
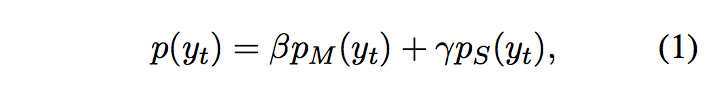
denotes the semantic-based generation probability
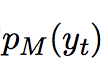
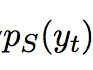
denotes the specificity-based generation probability
Each word in dataset have:
e: semantic representation
u: usage representation, mapped by usage embedding matrix U
Semantic-base part
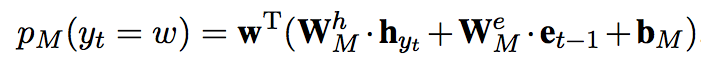
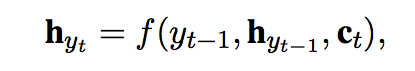
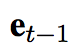
semantic representation of t-1 th generated word
w is vector of the word w
with f() is GRU unit
Specificity-based part
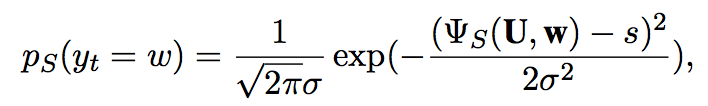
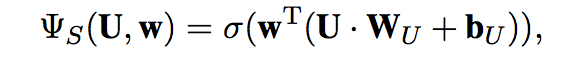
Using Gaussian Kernel
u: (usage) of word using sigmod func
s: the specificity control variable, value in [0,1]
Training method
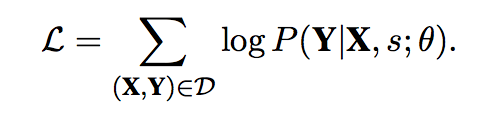
θ denotes all the model parameters
X,Y denotes utterance-response from training set D
s denotes the specificity control variable => need to calculate for each pair
Calculate s value
- Normalized Inverse Response Frequency (NIRF)
- Normalized Inverse Word Frequency (NIWF)
NIRF
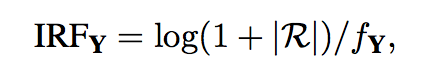
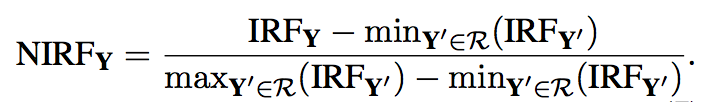
where:
|R|denotes the size of the response collection
f denote response Y corpus frequency in R
with Y is a response in response collection R
Normalization:
NIWF
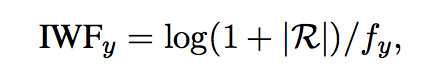
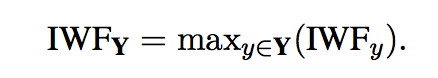
with y is a word in response Y in collection R
where:
f denote the number of responses in R containing the word y
so to calculate IWF of response Y
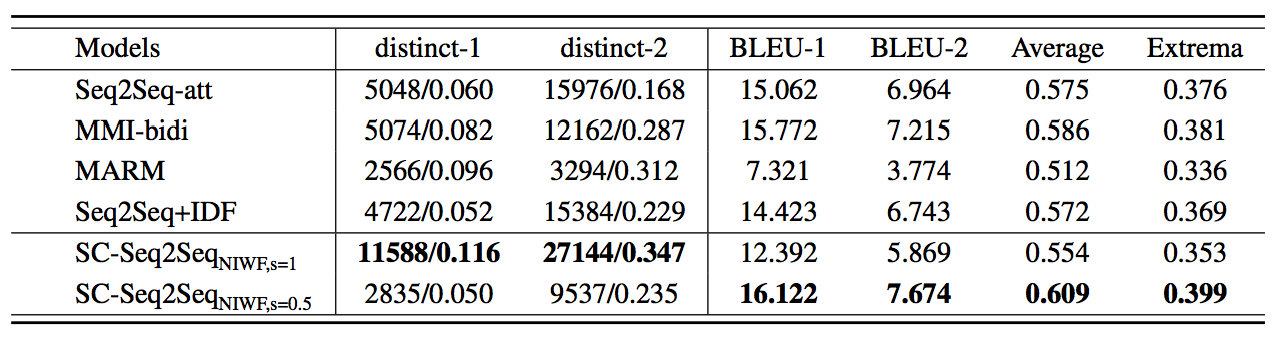
Experiment & Result
Evaluation points:
- distinct-1 & distinct-2: count numbers of distinct unigrams and bigrams in the generated responses
- BLEU point
Comparison