Information Geometry
and Diffeomorphisms
Klas Modin

Collaborators


Sarang Joshi
Martin Bauer
Boris Khesin
Gerard Misiolek


Geometric hydrodynamics
Riemannian geometry
of diffeomorphisms
Information geometry
Riemannian geometry
of statistics
Arnold (1966)
Rao (1945), Amari (1968)
?
(Topic of the talk)
Overview
-
Pre-Riemannian geometry: relation between probability densities and diffeomorphisms
-
Geometry of optimal mass transport (OMT)
-
Wasserstein vs. Fisher-Rao
-
Optimal information transport (OIT)
-
Application: random sampling
- Finite dimensional analogue (of OIT)
The two spaces
Probability densities
\[\mathrm{Prob}(M)=\{ \mu\in\Omega^n(M)\mid \mu>0, \int_M \mu = 1\}\]
Diffeomorphisms
\[\mathrm{Diff}(M)=\{ \varphi\in C^\infty(M,M)\mid \text{smooth }\varphi^{-1}\}\]
\(M\) compact (Riemannian) manifold
The centerpiece:
Moser's principal bundle

Two versions:
\(\pi(\varphi) = \varphi_*\mu_0\) (left action)
\(\pi(\varphi) = \varphi^*\mu_0\) (right action)
Relevant in optimal mass transport
Relevant in information geometry
Optimal mass transport (OMT)

Monge problem, \(L^2\) version
Wasserstein distance
Symmetric by change of variables
Riemannian structure of OMT
Riemannian metric
Induces metric
[Benamou & Brenier (2000), Otto (2001)]
Invariance: \(\eta\in\mathrm{Diff}_{\mu_0}(M)\)
Exactly \(L^2\)-Wasserstein distance
Wasserstein vs. Fisher-Rao
Wasserstein
Fisher-Rao
Dependent on Riemannian structure of \(M\)
Independent of Riemannian structure of \(M \Rightarrow \mathrm{Diff}(M)\)-invariance
Degenerate \(\mathrm{Diff}(M)\)-metric compatible with Fisher-Rao
[Khesin, Lenells, Misiolek, Preston, 2013]
\(\dot H\) degenerate metric
Wanted: non-degenerate descending metric
Optimal information transport
[M., 2015]
Natural idea: Hodge decomposition for horizontal directions
Theorem: geodesics are locally well-posed
Theorem:
Any \(\varphi\in\mathrm{Diff}^s(M)\) admits unique factorization \[\varphi = \eta\circ\mathrm{Exp}_{\mathrm{id}}(\nabla f)\]
solves OIT problem
Horizontal lifting equations
Theorem: solution to optimal information transport is \(\varphi(1)\) where \(\varphi(t)\) fulfills
where \(\mu(t)\) is Fisher-Rao geodesic between \(\mu_0\) and \(\mu_1\)
Leads to numerical time-stepping scheme: Poisson problem at each time step
MATLAB code: github.com/kmodin/oit-random
Application: non-uniform sampling on \(M\)
Problem 1: given \(\mu_1\in\mathrm{Prob}(M)\) generate \(N\) samples from \(\mu_1\)
Most cases: use Monte-Carlo based methods
Special case here:
- \(M\) low dimensional
- \(\mu\) very non-uniform
- \(N\) very large
transport map approach
might be useful
[Bauer, Joshi, M., 2017]
Transport problem
Problem 1': given \(\mu_1\in\mathrm{Prob}(M)\) find \(\varphi\in\mathrm{Diff}(M)\) such that
Method:
- \(N\) samples \(x_1,\ldots,x_N\) from uniform distribution \(\mu_0\)
- Compute \(y_i = \varphi(x_i) \)
Diffeomorphism \(\varphi\) not unique!
Optimal transport problem
Problem 1'': given \(\mu_1\in\mathrm{Prob}(M)\) find \(\varphi\in\mathrm{Diff}(M)\) minimizing
under constraint \(\varphi_*\mu_0 = \mu_1\)
Studied case: (Moselhy and Marzouk 2012, Reich 2013, ...)
- \(\mathrm{dist}\) = \(L^2\)-Wasserstein distance
- \(\Rightarrow\) optimal mass transport problem
- \(\Rightarrow\) solve Monge-Ampere equation (heavily non-linear PDE)
Our notion:
- use optimal information transport
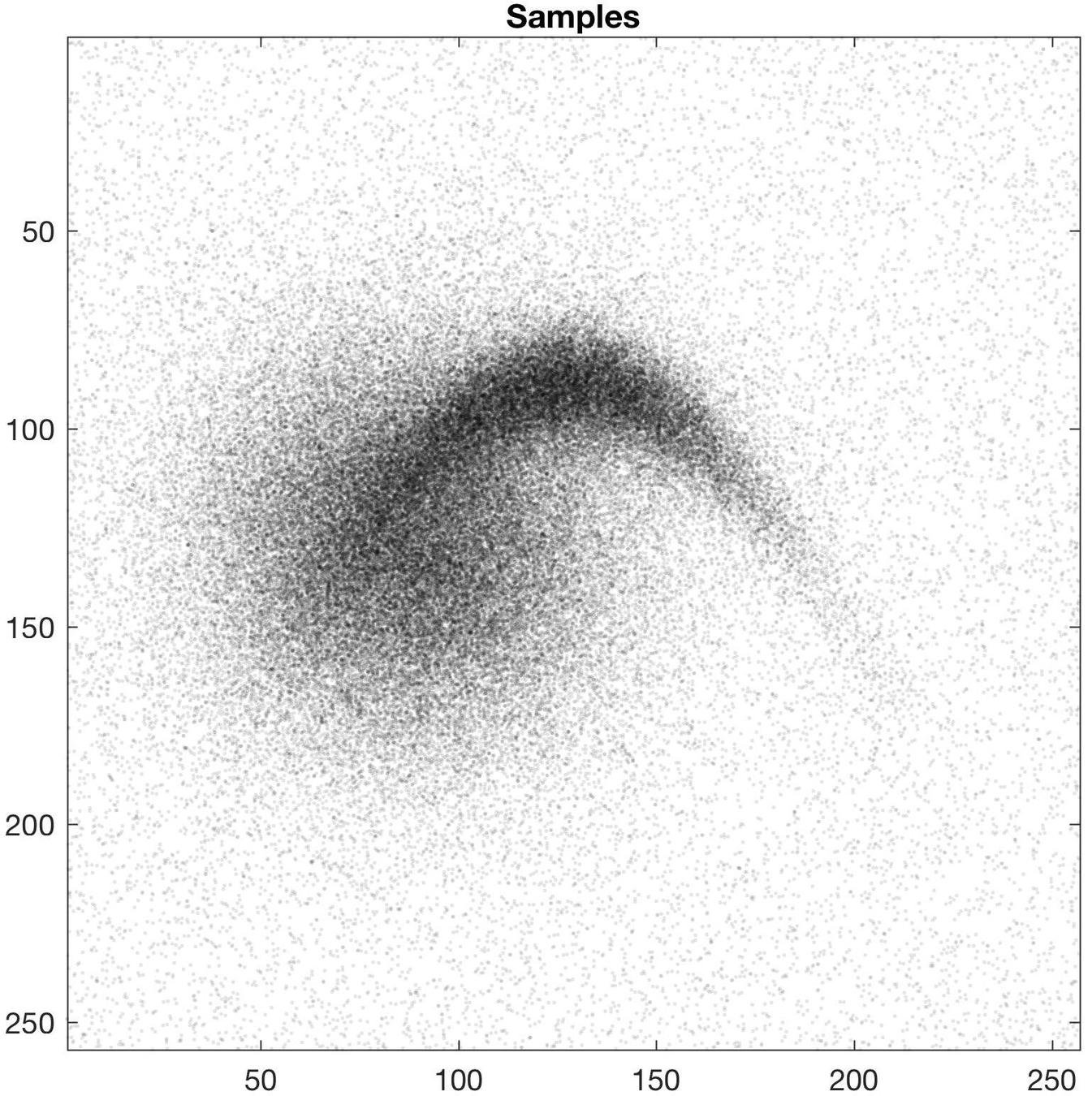
Simple 2D example
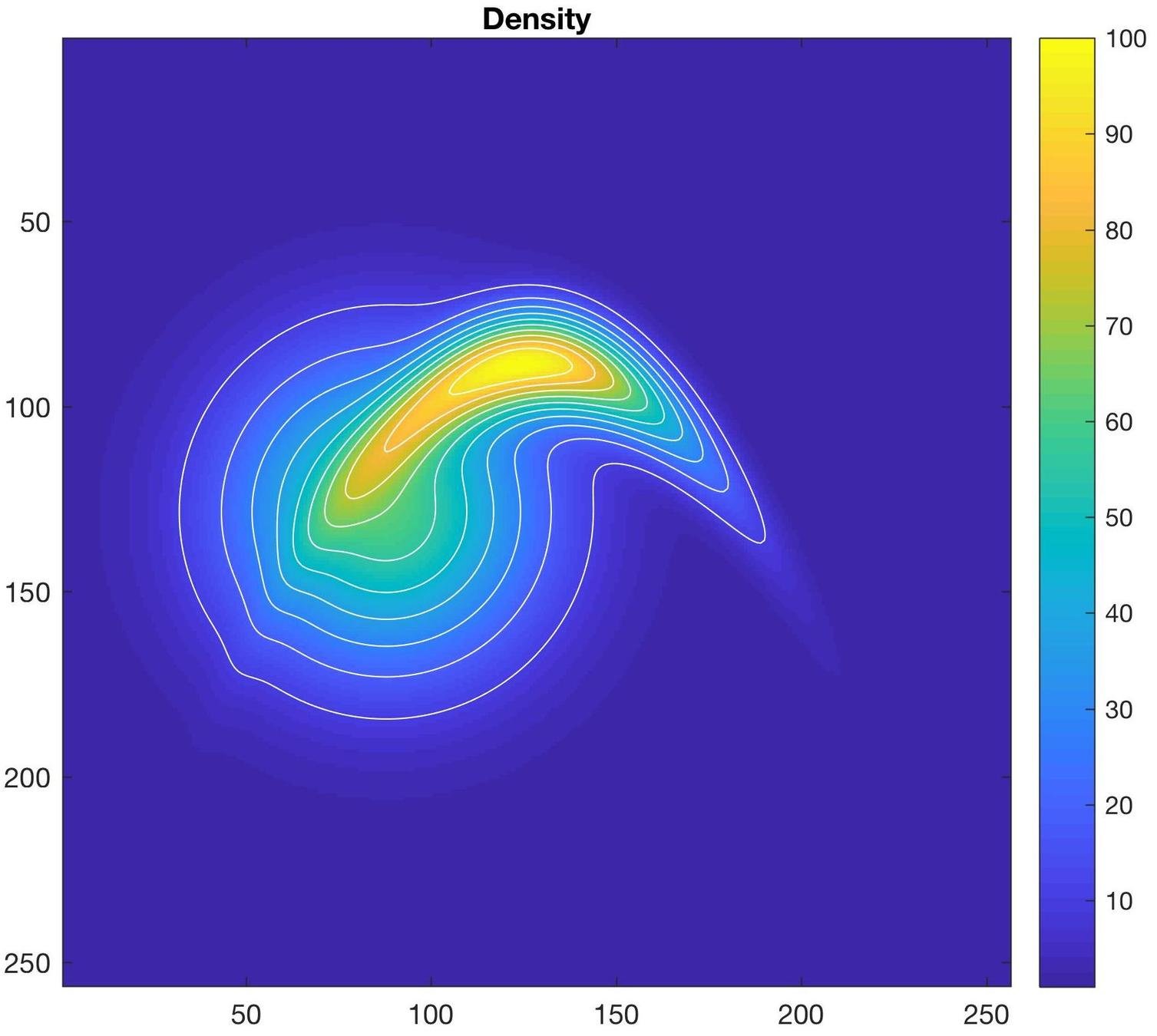
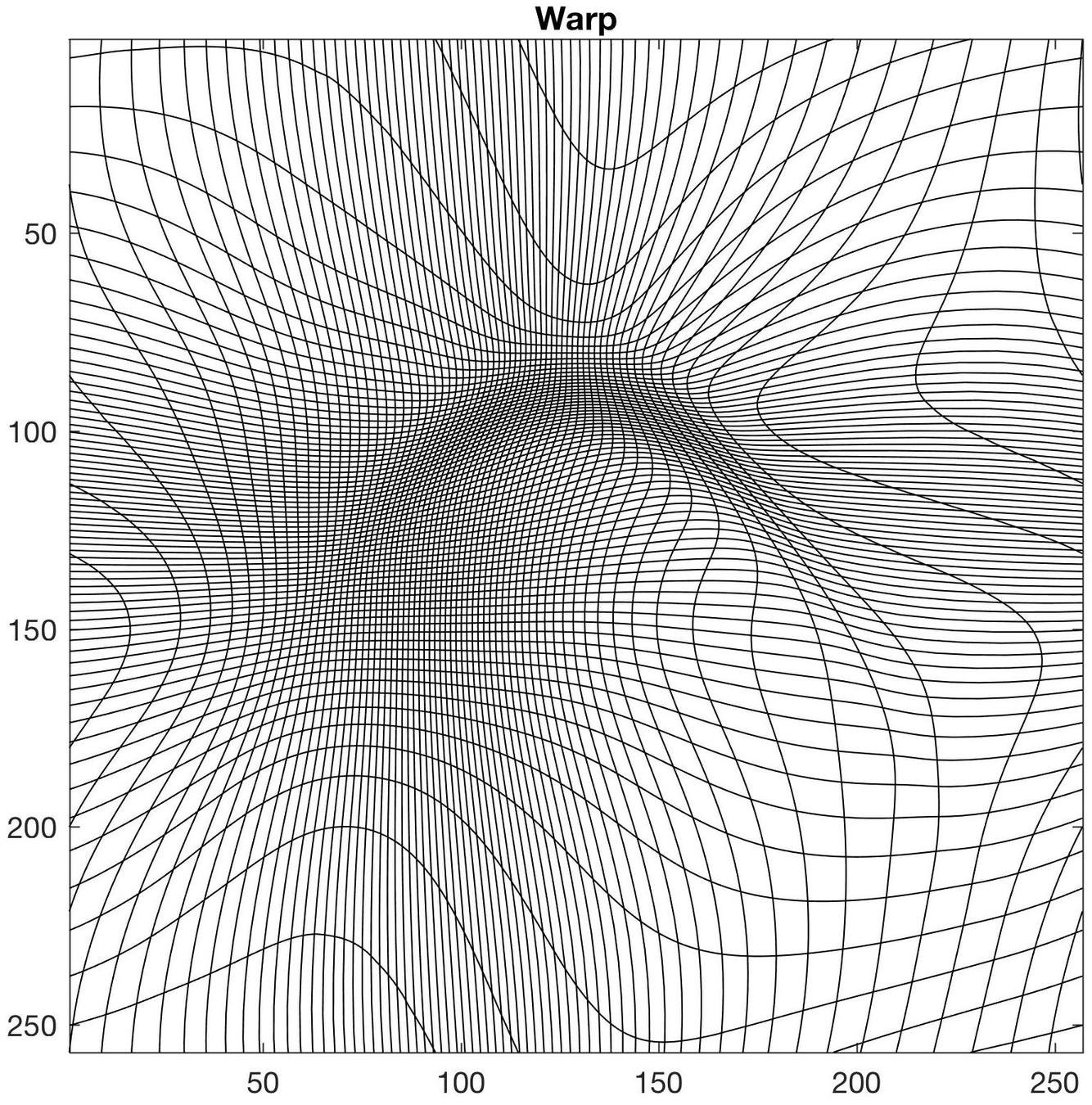
Warp computation time (256*256 gridsize, 100 time-steps): ~1s
Sample computation time (10^7 samples): < 1s
OIT in finite dim: manifold of inverse covariance matrices

[M., 2017]
Fisher-Rao metric on P(n)
Geodesics on P(n)

Explicit distance function
Geodesic equation
Homogeneous space structure
fiber
fiber
Principal bundle
Fisher-Rao invariance
Right action of GL(n) on P(n)
Compatible metric on GL(n)
horizontal slice
fiber
fiber
Horizontal distribution
horizontal slice
fiber
fiber
Gives QR and Cholesky factorizations of matrices
THANKS!
References:
- K. Modin
Generalized Hunter–Saxton equations, optimal information transport, and factorization of diffeomorphisms, 2015 - M. Bauer, S. Joshi, K. Modin
Diffeomorphic random sampling using optimal information transport, 2017 - K. Modin
Geometry of Matrix Decompositions Seen Through Optimal Transport and Information Geometry, 2017
Slides available at: slides.com/kmodin