DB hw4
2016,KO
outline
1.所以這個作業到底在幹嘛
2.如何處理檔案
3.import
4.query without index (恭喜你 75分拿到了)
5.create index
6.query with index (恭喜你 96分拿到了)
不負責任聲明
1.我只有96我也不知道為什麼
2.裡面可能有土方法
3.code我都沒編譯過

這個作業到底在幹嘛
main檔:用來執行程式跟算時間
db.h:用來宣告db class,還有他的所有變數和成員函式
db.cpp:用來定義成員函式們
請一邊打開作業看一看,不然會看無
1.由於那三個csv檔實在有夠大,所以我們要把他們讀進來,並只取需要的資訊(ori、dest、arrdelay),存在新的txt檔案裡
2.query的時候就只要從我們的txt檔裡找資料query就好,不再需要那些csv
3.若要create index,就是針對那堆資料做sort,並記錄他們的位置在哪裡,之後query時就只要跳到那個位置找資料就好
db.h
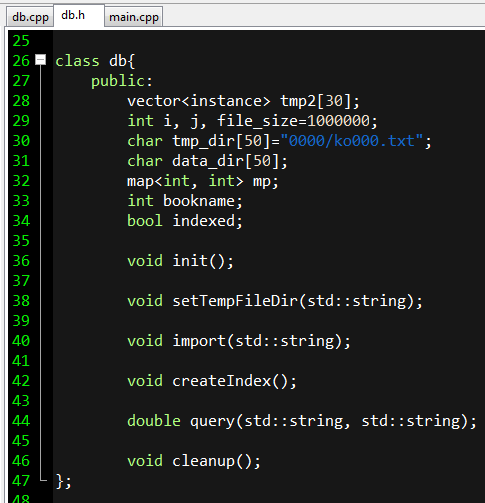
需要什麼變數就自己加在這裡
把陣列清空空,把數量歸零等等
指定那些txt檔要放在什麼資料夾裡
讀進csv,存入txt
sort並記錄位置
跳到該位置,累加delay,最後算平均
陣列清空空,數量歸零
如何處理檔案
讀檔
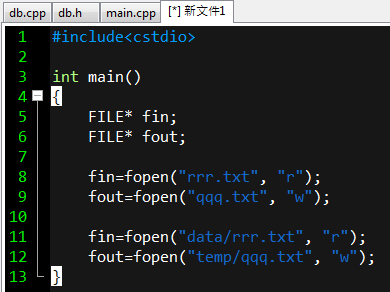
fin代表讀進的檔案
fout代表要寫出的檔案
若檔案放在資料夾裡,就在檔案名稱前面加斜線以及資料夾名稱
若檔案的名稱不是固定的字串
就用一個char[]存起來
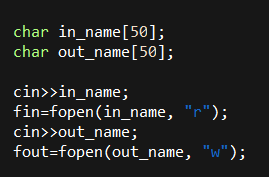
現在我們可以來看看
setTempFileDir(string dir)
這個function了
此時out_name就會變成 "temp/out.txt"了
這樣就好!!!
恭喜你set_tmp_dir已完成
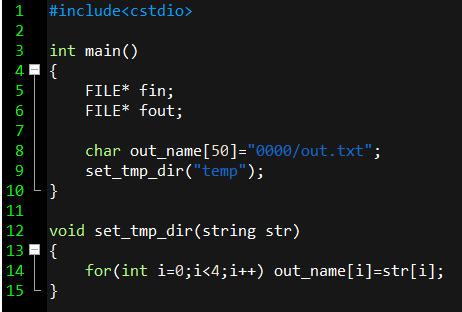
import也是一樣的,但他是直接給"data/2006.csv",所以只要直接把in_name改成跟它一樣就好
此時in_name就變成 "data/2006.csv"了
接下來要把東西讀進來再印出去
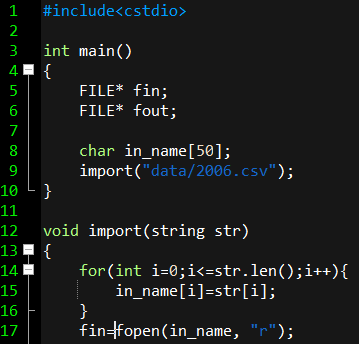

所謂的csv檔就是一堆用逗點分隔的字串,可以用fgets一次讀一行
可以印出來試看看,看它裡面長什麼樣子
除了第一行是標題之外,其他每一行都是資料,可以用while(fgets(s, 1000, fin))來把他們讀光光
讀進來一行之後,就用數逗點的方法找出origin、dest、arrdelay,並印到fout裡
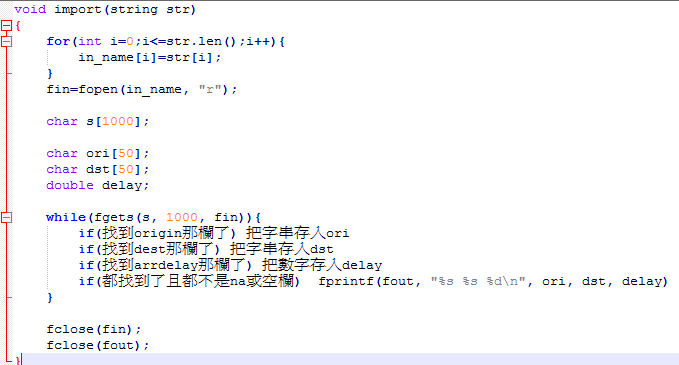

out.txt裡面看起來會像這樣
由於大概有兩千多萬筆資料,
所以我每到一百萬筆時就會開一個新的txt檔來寫,
不過就算不這麼做也是可以的
至於如何數逗點、如何把字串變成數字,如何判斷空欄或是NA,就看個人創意了~~
恭喜import完成
好了最煩的部分已經結束了
query without index
據說做完這步有75分
由於沒有index,所以每次query都要把所有的資料都看過一遍,只要是起點和終點都符合的資料,就把delay累加起來
最後回傳delay的平均值
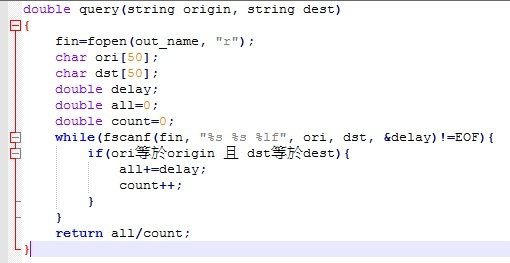
所有資料都看過一次,若符合,就把delay累加起來,最後回傳平均值
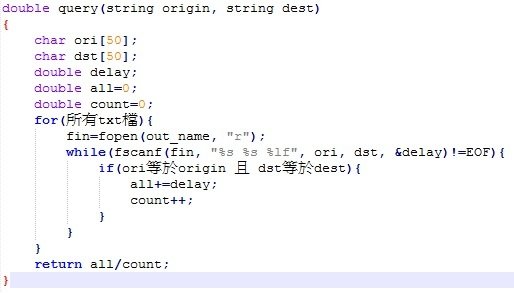
如果你有分成好幾個txt檔來存的話,就要每個都打開來看過
(沒有分的話可以直接跳過這頁)
恭喜你query完成啦 75分到手
如果很累的話可以改天再繼續create index
XD
create index
要做的事情是什麼呢?
1.把所有(origin, dest)的組合都用一個數字h來表示
2.把每一筆資料都按照他的h值來sort過
3.紀錄每一種h的起始位置
h要怎麼選才好呢
我用的是很懶的方法
h=(origin[0]-'A')*11881376+(origin[1]-'A')*456976+(origin[2]-'A')*17576+(dest[0]-'A')*676+
(dest[1]-'A')*26+(dest[2]-'A')
大家可以自己想個聰明方法
把每一筆資料都讀進來,算出它的h值,並將它跟delay一起存入vector裡,存完後sort,再印到新的txt檔裡

對了別忘記index
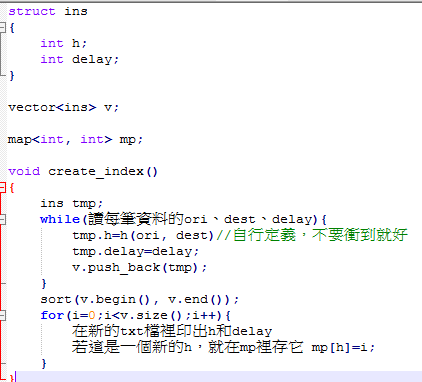
用一個map去記錄每一種h首次出現的位置

存起來的檔案大概會長這樣
盡量讓每一行都對齊(即每一行長度一樣)
這樣待會query會比較好操作
好了 create index也完成了
很簡單吧
query with index
每次query的時候,算出要query的(ori,dest)對應的h值
從mp裡找出此h值從檔案裡的哪一行開始
offset=mp[h]
接著來介紹fseek這個function
它可以直接把游標跳到檔案裡n個字元後的位置
例如
fseek(fin, 100, SEEKSET)
就可以從檔案的第100個字元開始讀
所以你要知道自己的檔案裡每行是幾個字元,
例如k個
然後將offset*=k;
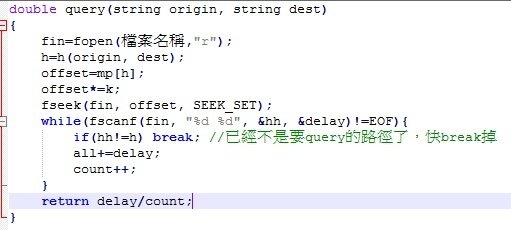
加總所有delay,等到下一筆資料的h已經不是要query的h時就break出來
return 平均值
結束啦恭喜
有問題的8/1以前都可以問我喔