Apache Spark
Scala vs Python
Taras Lehinevych
Agenda
- Apache Spark
- Resilient Distributed Datasets
- DataFrame
- Datasets
- Summary
Apache Spark
- Open source cluster computing framework
- Originally developed at the UC Berkley
- Provides interface for programming entire clusters with implicit data parallelism and fault-tolerance
- Hadoop ecosystem
Apache Spark
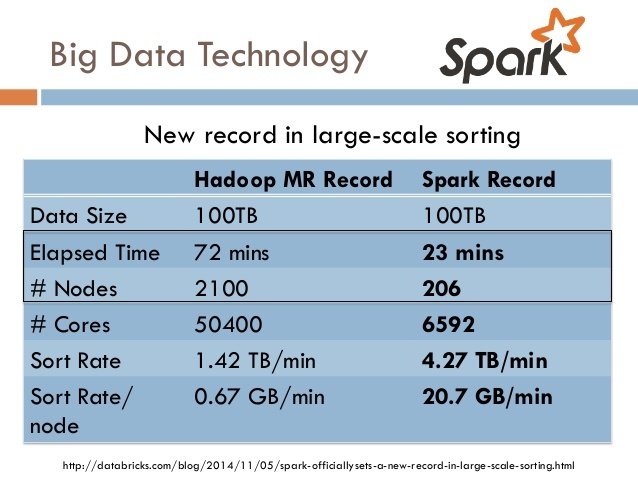
Apache Spark
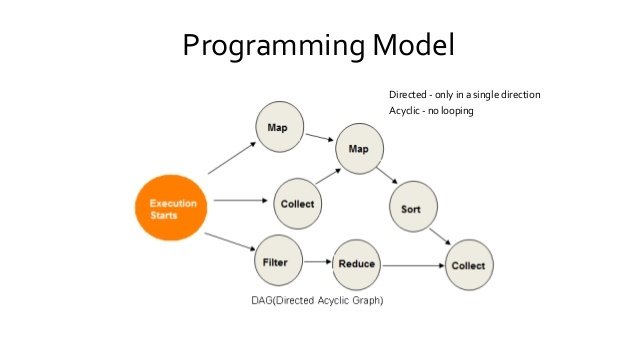
Text
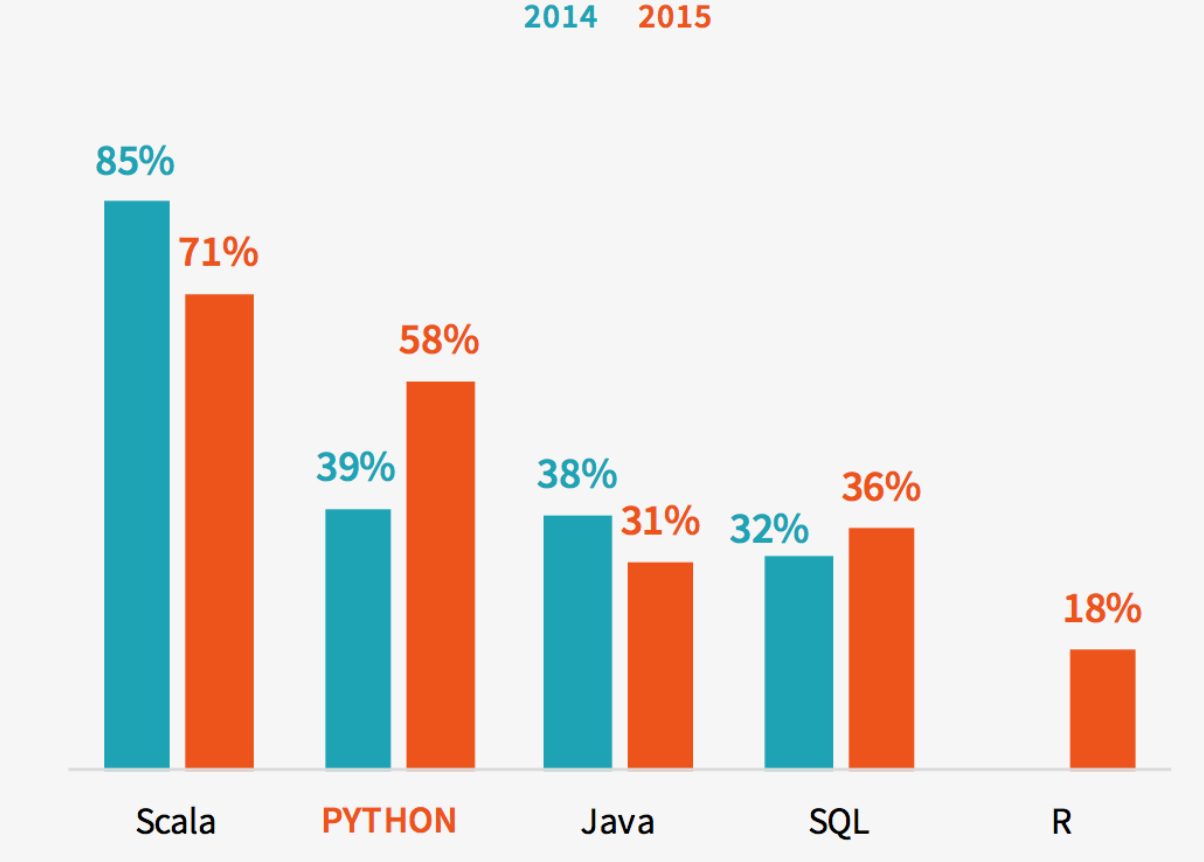
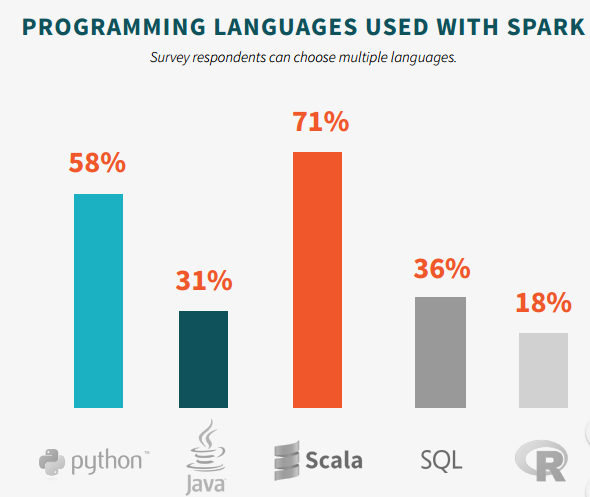
Spark Survey 2015
Resilient Distributed Datasets (RDD)
Dataset – variable or object:
- HDFS, S3, Hbase, JSON, text, local
- Transformed RDD
- RDD – immutable
Distributed:
- Distributed in cluster, one variable
- Partitions (atomic)
Resilient:
- Restoring after error
- Save operation over data
RDD
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")Python
Scala
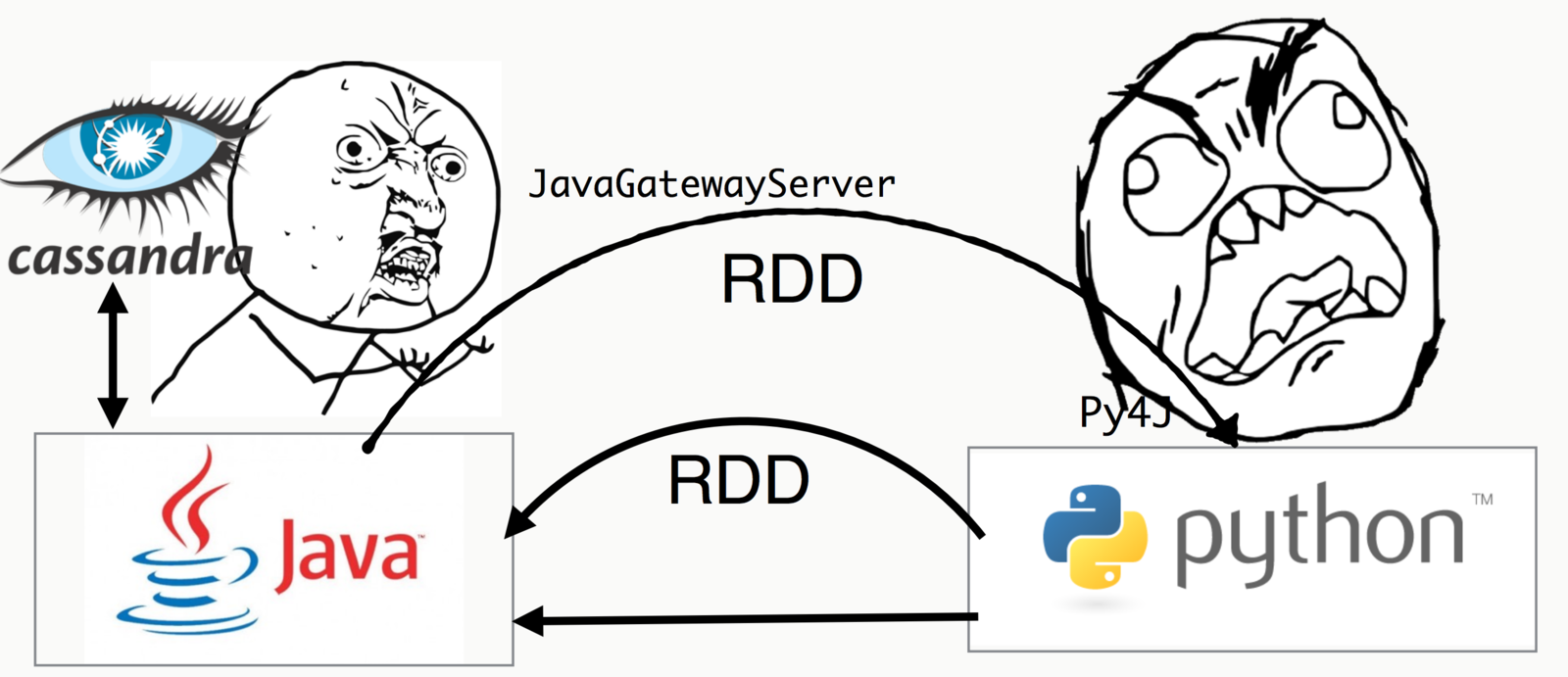
Why Not Python + RDD?
Why Not Python + RDD?
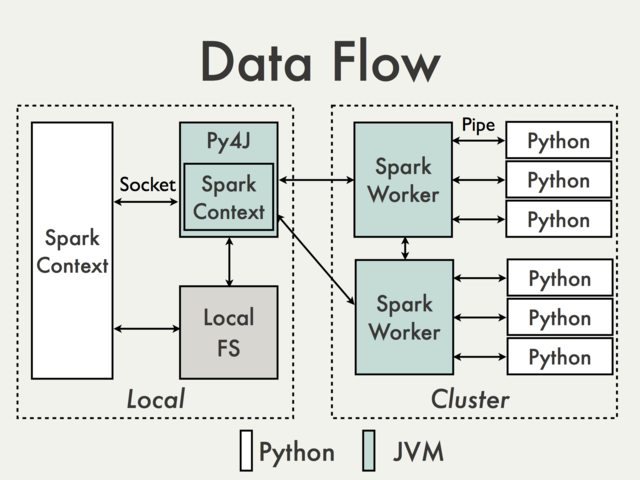
RDD
Advantage:
- familiar object-oriented programming style
- compile-time type-safety
Disadvantage:
- Java serialization
- Overhead of garbage collection
- Process based executors versus thread based
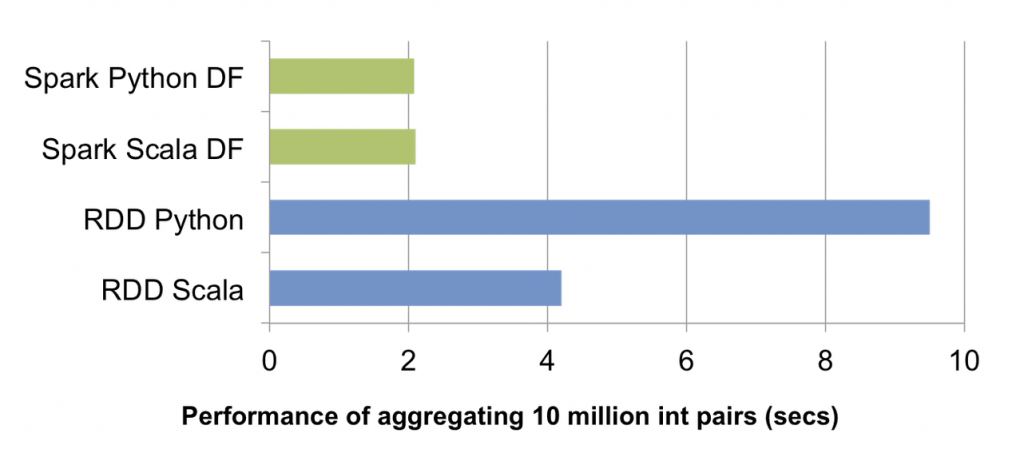
Performance
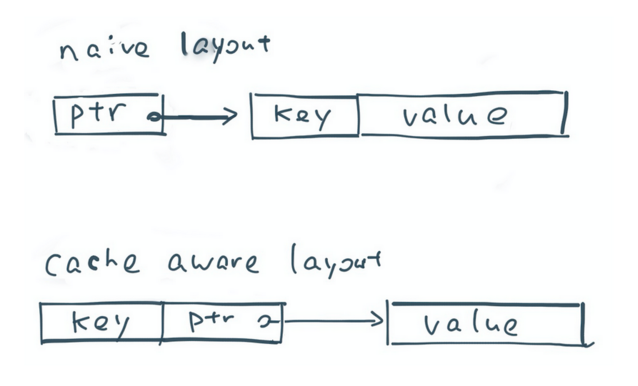
DataFrame
- Spark 1.3
- Part of Tungsten initiative
- Schema
- Pass only data over nodes
- API for building a relational query plan that Spark’s Catalyst optimizer can then execute
DataFrame
DataFrame
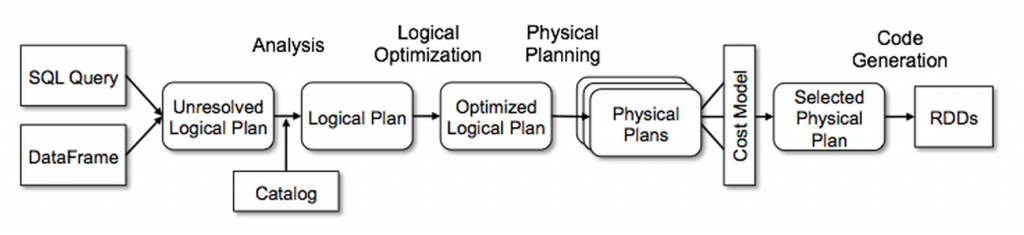
DataFrame
joined = users.join(events, users.id == events.uid)
filtered = joined.filter(events.date >= "2016-04-23")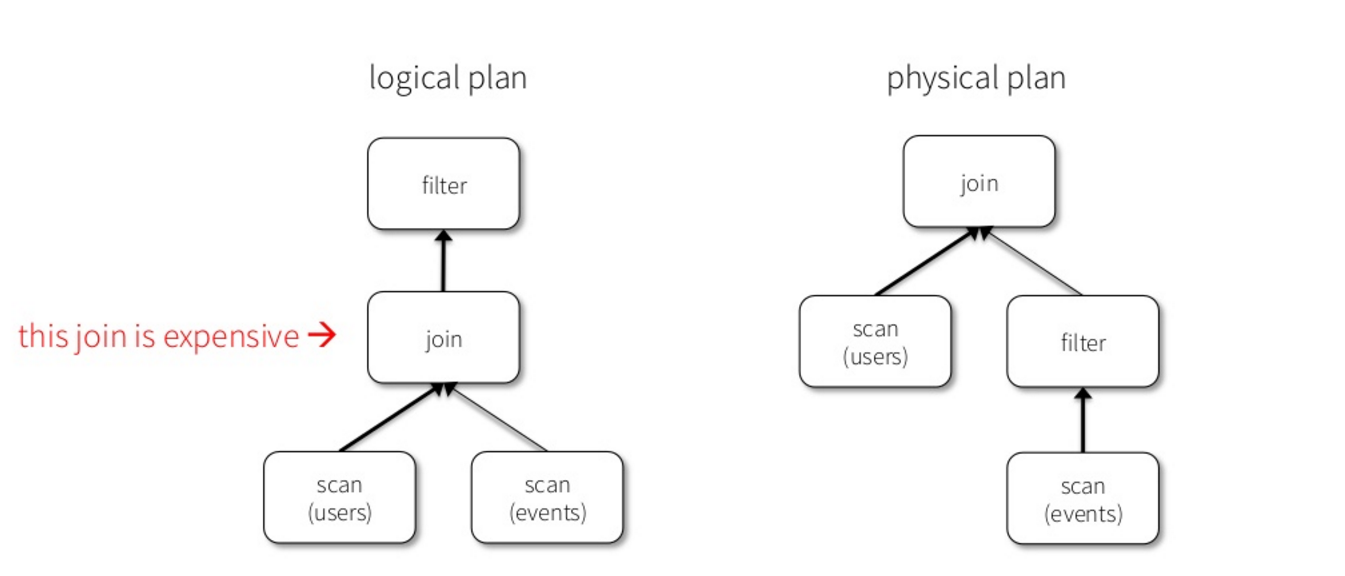
DataFrame
val textFile = sc.textFile("hdfs://...")
// Creates a DataFrame having a single column named "line"
val df = textFile.toDF("line")
val errors = df.filter(col("line").like("%ERROR%"))
// Counts all the errors
errors.count()
// Counts errors mentioning MySQL
errors.filter(col("line").like("%MySQL%")).count()
// Fetches the MySQL errors as an array of strings
errors.filter(col("line").like("%MySQL%")).collect()textFile = sc.textFile("hdfs://...")
# Creates a DataFrame having a single column named "line"
df = textFile.map(lambda r: Row(r)).toDF(["line"])
errors = df.filter(col("line").like("%ERROR%"))
# Counts all the errors
errors.count()
# Counts errors mentioning MySQL
errors.filter(col("line").like("%MySQL%")).count()
# Fetches the MySQL errors as an array of strings
errors.filter(col("line").like("%MySQL%")).collect()DataFrame
Advantage:
- Performance (schema, off-heap storage)
- Spark’s Catalyst optimizer
Disadvantage:
- Compile-time type-safety
- Query-oriented
Dataset
Preview in Spark 1.6
Best of both worlds:
- object-oriented programming style
- compile-time type-safety
- Catalyst query optimizer
- off-heap storage mechanism
Dataset
- Encoders which translate JVM representations (objects) into Tungsten binary format.
- Spark has built-in encoders which are very advanced in that they generate byte code to interact with off-heap data and provide on-demand access to individual attributes without having to de-serialize an entire object.
- Spark does not yet provide an API for implementing custom encoders, but that is planned for a future release.
Dataset
NO PYTHON SUPPORT

Dataset
val lines = sc.textFile("/wikipedia")
val words = lines
.flatMap(_.split(" "))
.filter(_ != "")
val counts = words
.groupBy(_.toLowerCase)
.map(w => (w._1, w._2.size))RDDs
Datasets
val lines = sqlContext.read.text("/wikipedia").as[String]
val words = lines
.flatMap(_.split(" "))
.filter(_ != "")
val counts = words
.groupBy(_.toLowerCase)
.count()Dataset
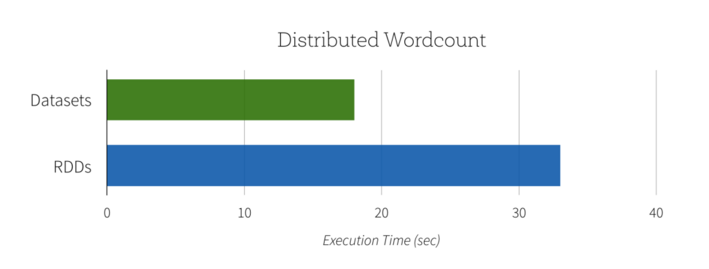
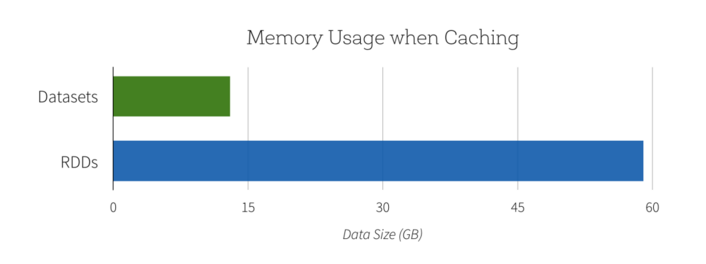
Dataset
Performance optimization
Custom encoders
Python Support
Unification of DataFrames with Datasets
Summary
DataFrame is the best option for Python and production
Waiting for Dataset + Python
Sources
Databricks Blog - databricks.com/blog
Cloudera Engineerig Blog- blog.cloudera.com
Spark Community (mailing list)
Contacts
Website - https://taraslehinevych.me
Email - info@taraslehinevych.me
Twitter - @lehinevych
Thank you
Questions?