Beating the curse of dimensionality in deep neural networks by learning invariant representations
Leonardo Petrini
joint work with
Francesco Cagnetta, Alessandro Favero, Mario Geiger, Umberto Tomasini, Matthieu Wyart


Learning high dimensional data:
the curse of dimensionality

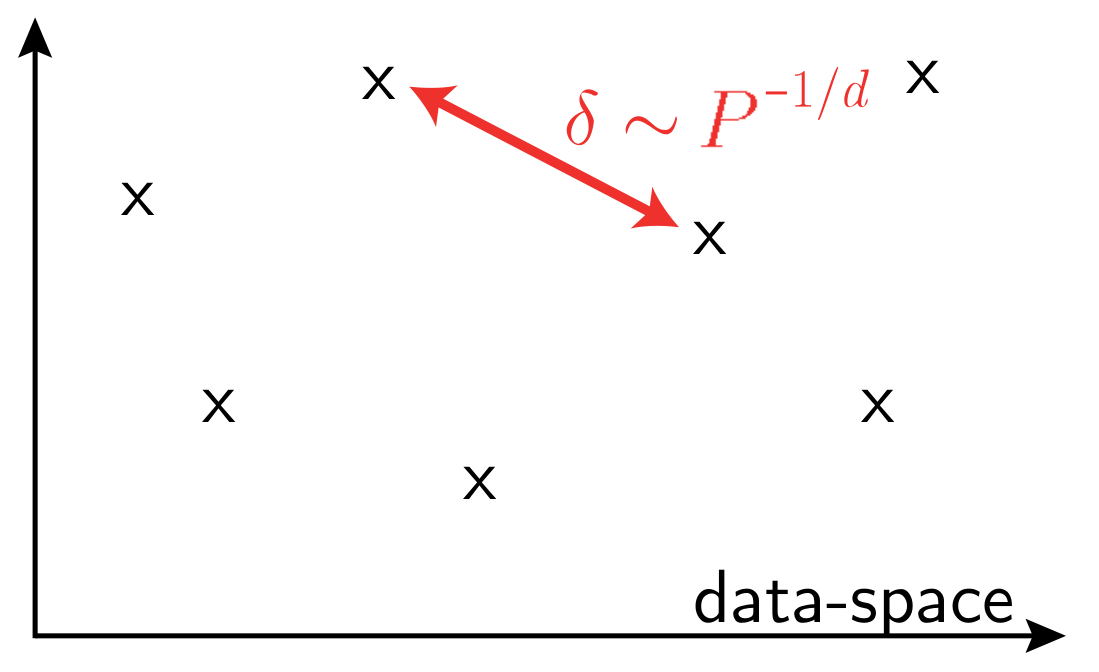
\(P\): training set size
\(d\) data-space dimension
- Prerequisite for artificial intelligence: make sense of high-dimensional data
- e.g. learn to classify images from examples
- Images live in high dimensions, e.g. \(1'000\times1'000 = 10^6\) pixels
- Even measures of effective dimension give \(d_\text{eff} \sim 10^2\)
- \(\rightarrow\) curse of dimensionality = no efficient sampling is possible (need exponential number of points).

To be learnable, real data must be highly structured
Deep learning
- Learning from examples a function in high-dimensions with artificial neural networks:
- Training:
- Testing:
- Training:


deep net

correct prediction!!
dog
parameters optimized with gradient descent to achieve correct output
e.g. > 90% accuracy for many algorithms and tasks


Language, e.g. ChatGPT
Go-playing

Autonomous cars

Pose estimation
etc...
Understanding deep learning success
- Successful in many high-dimensional tasks
- Many open questions:
- What is the structure of real data that makes them learnable?
- How is it exploited by deep neural networks?
- How much data is needed to learn a given task?
Language, e.g. ChatGPT
Go-playing
Autonomous cars
Pose estimation
etc...
Understanding deep learning success
- Successful in many high-dimensional tasks:
- Many open questions:
- What is the nature of real-data structure?
- How is it exploited by deep neural networks?
- How much data is needed to learn a given task?
\(P\): training set size
\(d\) data-space dimension
-
Curse of dimensionality:
- Images live in high dimensions, e.g. \(1'000\times1'000 = 10^6\) pixels
- \(\rightarrow\) no efficient sampling is possible;
- To be learnable, real data must be highly structured.
Learning relevant data representations
-
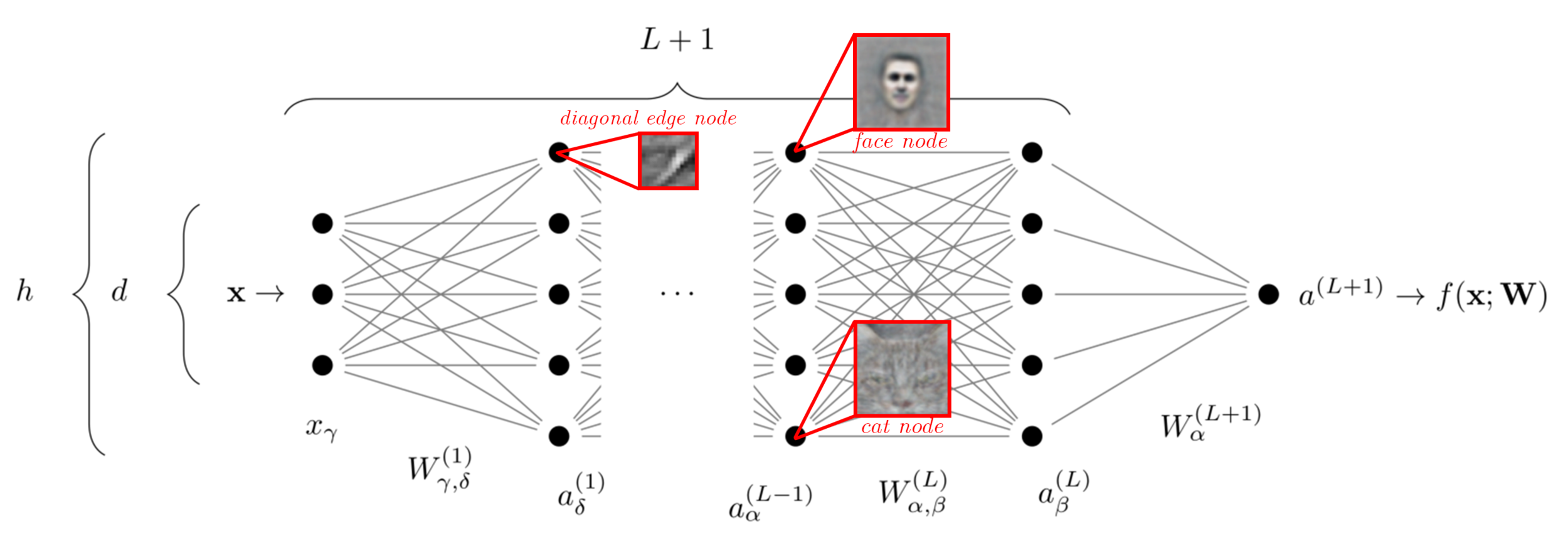
Hypothesis: deep learning success is in its ability to exploit data structure by learning representations relevant for the task:
- Deeper neural network layers respond to higher-level, more abstract features in a hierarchical manner;
- Are more abstract representations lower dimensional?
- Empirically: dimensionality of internal representations is reduced with depth \(\rightarrow\) lower dimensionality of the problem \(\rightarrow\) beat the curse.
- Deeper neural network layers respond to higher-level, more abstract features in a hierarchical manner;
Ansuini et al. '19
Recenatesi et al. '19
adapted from Lee et al. '13
How is dimensionality reduction achieved?
...
dog
face
paws
eyes
nose
mouth
ear
edges
Data invariances allow dimensionality reduction
Focus of Part I
Focus of Part II
Mossel '16, Poggio et al. '17, Malach and Shalev-Shwartz '18, '20 Petrini et al '23 (in preparation)
Bruna and Mallat '13, Petrini et al. '21, Tomasini et al. '22
...
dog
face
paws
eyes
nose
mouth
ear
edges
text:
images:
- Dimensionality of the problem can be reduced by becoming invariant to aspects of the data irrelevant for the task:
-
Semantic invariance. Related to hierarchical structure of the task (higher-level features are a composition of lower-level features). Features can have different synonyms.
- Deformation invariance. The relevant features are sparse in space, their exact position does not matter.
-
Semantic invariance. Related to hierarchical structure of the task (higher-level features are a composition of lower-level features). Features can have different synonyms.
Intro summary
- Learning high-d tasks \(\rightarrow\) curse of dimensionality;
- Deep learning is successful on these tasks;
- \(\implies\) real data is highly structured;
- Deep networks beat the curse by exploiting this structure?
- Evidence: DNNs' learn representations that are
- Hierarchical;
- Low dimensional;
- Our approach: characterize dimensionality reduction through data invariances to gain understanding and possibly predict sample complexity (i.e. how many points are needed to learn a task).
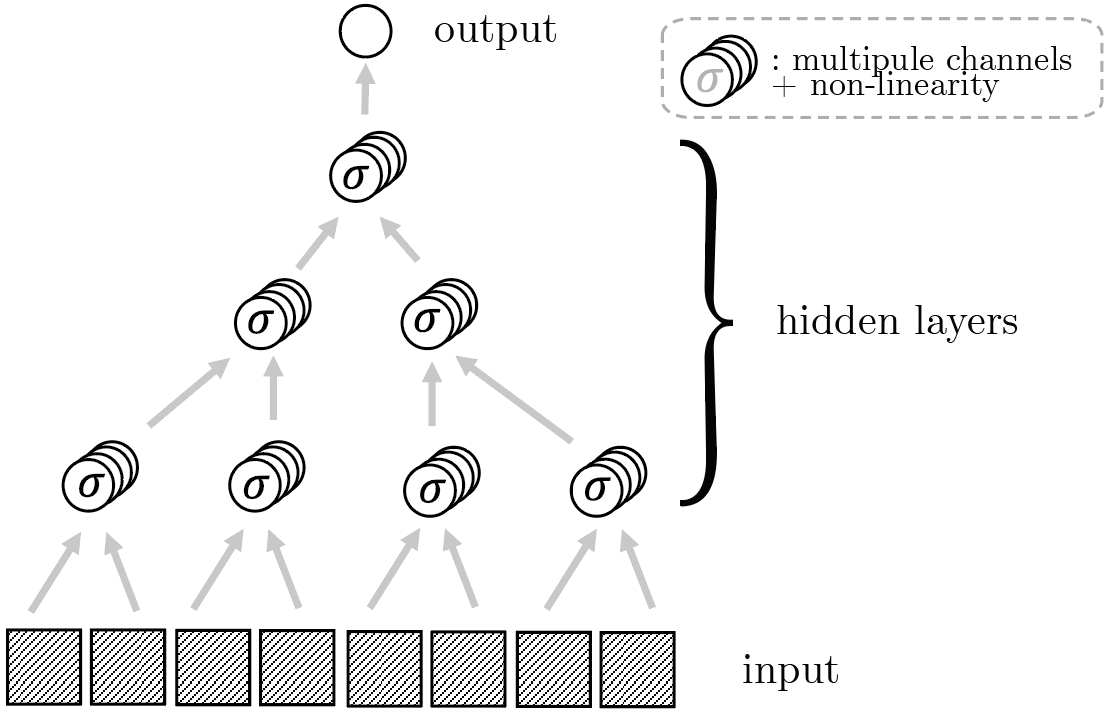
Learning Hierarchical Tasks with Deep Neural Networks:
The Random Hierarchy Model
Part I
...
dog
face
paws
eyes
nose
mouth
ear
edges
Previous works:
- Hierarchical tasks can be represented by neural networks that are deep;
- Correlations between low-level features and task necessary to performance;
- ...
Poggio et al. '17
Mossel '16, Malach and Shalev-Shwartz '18, '20
Open questions:
- Can deep neural networks trained by gradient descent learn hierarchical tasks?
- How many samples do they need?
Physicist approach:
Introduce a simplified model of data
DNNs Learning Hierarchical Tasks: open questions
Q1: Can deep neural networks trained by gradient descent learn hierarchical tasks?
Q2: How many samples do they need?
Previous works:
- Hierarchical tasks can be represented by neural networks that are deep;
- Generative models of hierarchical tasks are introduced;
- Correlations between low-level features and task necessary to performance;
- .
Physicist approach:
introduce a simplified model of data
Poggio et al. '17
Mossel '16, Malach and Shalev-Shwartz '18, '20
adapted from Lee et al. '13
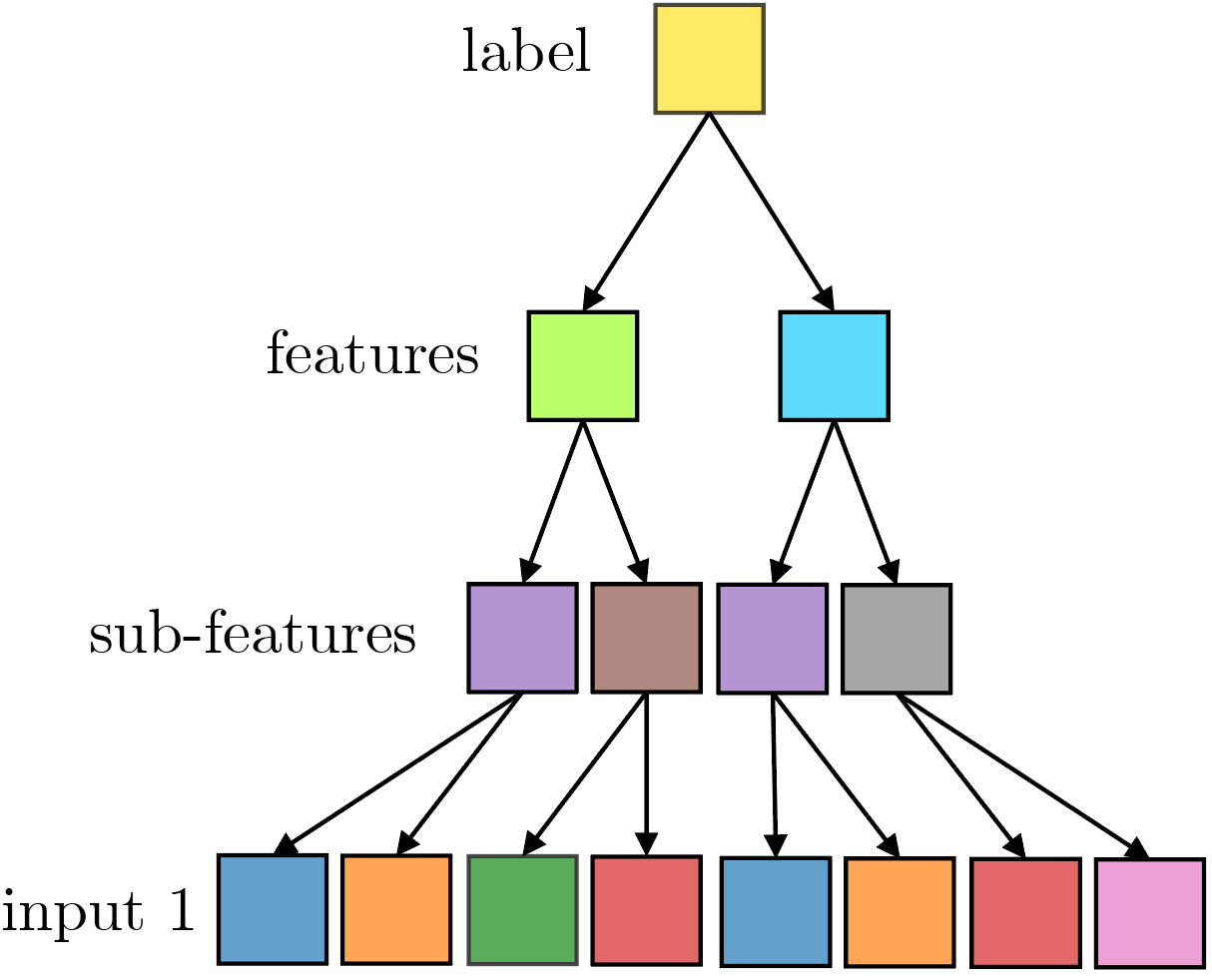
The Random Hierarchy Model (RHM)
Propose generative model of hierarhical data and study sample complexity of neural networks.
2) Finite vocabulary:
- Number of distinct classes is \(n_c\)
- Number of features is \(v\)
- Number of sub-features is \(v\)
- etc...
4) Random (frozen) rules:
- The \(m\) possible strings of a class are chosen uniformly at random among the \(v^s\) possible ones;
- Same for features, etc...
1) Hierarchy:
- any class (say dog) corresponds to a string of \(s\) features;
- a feature (say head) corresponds to a string of \(s\) sub-features;
- etc... Repeat \(L\) times.
- Dimension of data: \(d = s^L\)
3) Degeneracy:
- A class can be represented by \(m\) different strings of \(s\) features, out of \(v^s\) possible strings;
- A given feature corresponds to \(m\) strings of sub-features, etc...
- Two classes (or two features) cannot be represented by same string: \(m ≤ v^{s-1}\)
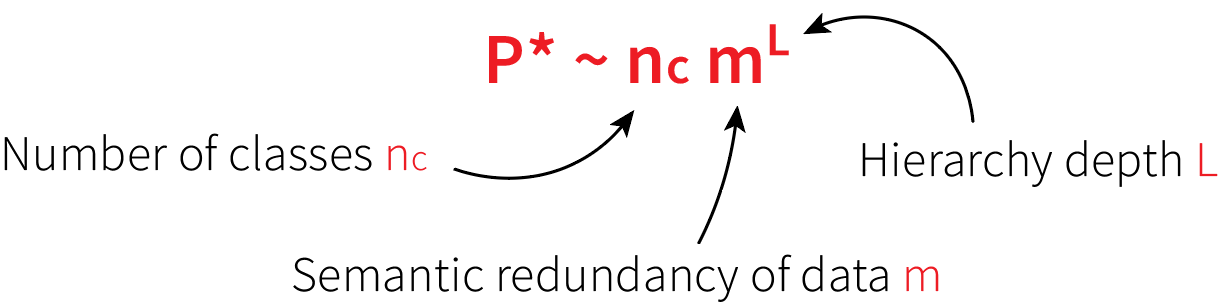
- \(P_\text{max} \sim n_c m^{\frac{s^L-1}{s-1}}\), exponential in \(d\).
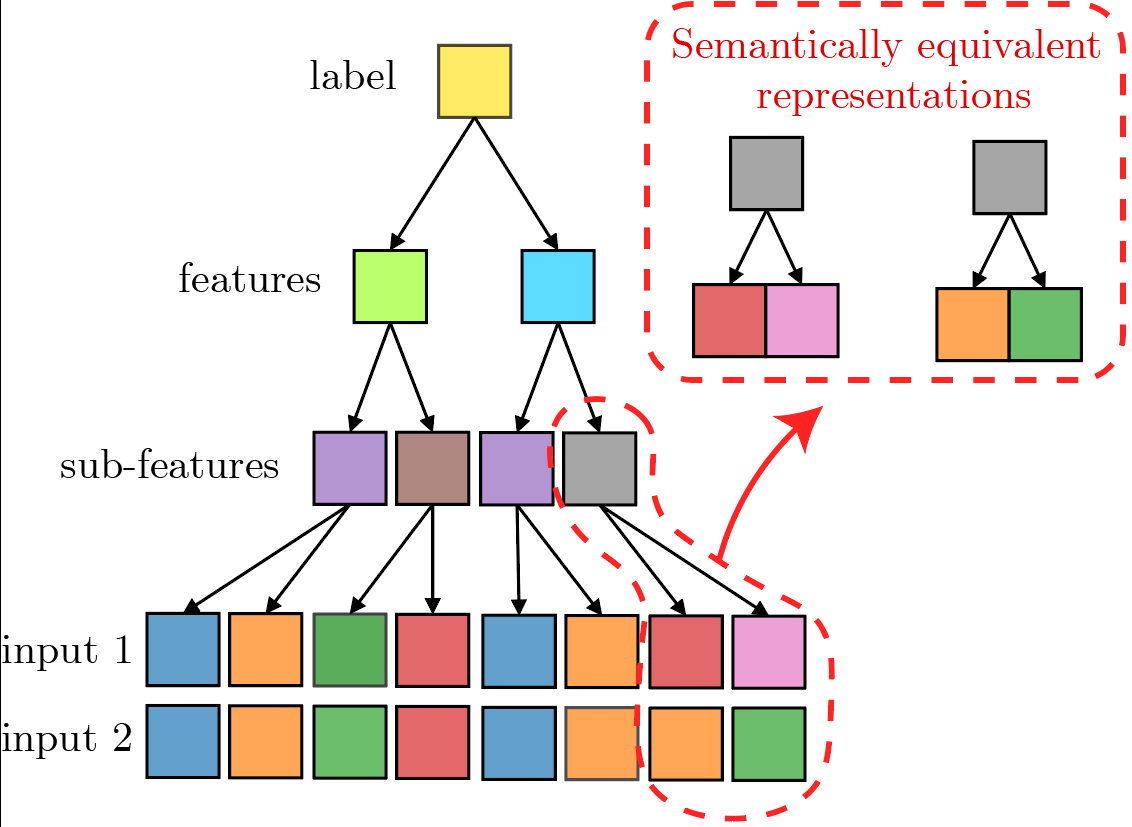
Sampling from the RHM
To generate data, for a given choice of \((v, n_c, m, L, s)\):
- Sample a set of frozen rules (the task);
- Sample a label;
- Sample a \(s\)-tuple of features out of the \(m\) possible, corresponding to that label;
- For each sampled feature, at each of the \(L\) levels, repeat point (3.)
At every level, semantically equivalent representations exist.
How many points do neural networks need to learn these tasks?
Simple neural networks are cursed
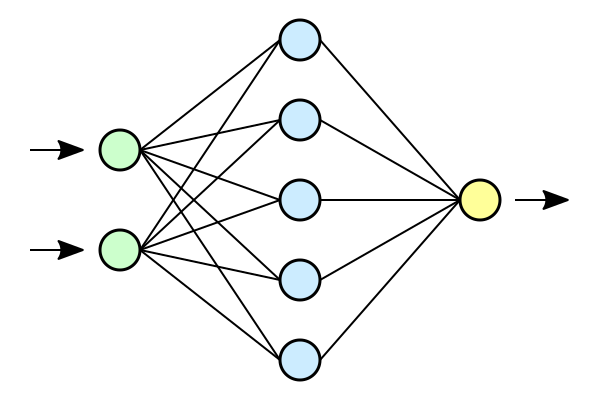
Training a one-hidden-layer fully-connected neural network
with gradient descent to fit a training set of size \(P\).
- The sample complexity is proportional to the maximal training set size \(P_\text{max}\);
- \(P_\text{max}\) grows exponentially with the input dimension \(\rightarrow\) curse of dimensionality.
original
rescaled \(x-\)axis
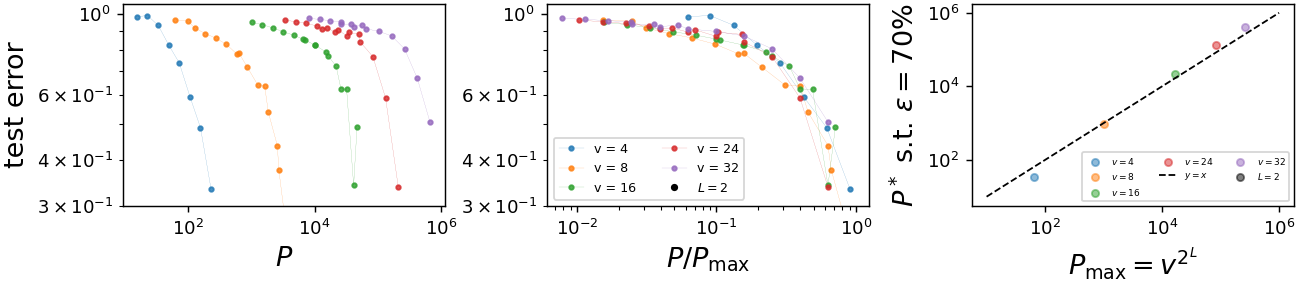
Deep neural networks beat the curse
Training a deep convolutional neural networks with \(L\)
hidden layers on a training set of size \(P\).
- The sample complexity:
- Power law in the the input dimension \(d=s^L\), curse is beaten!!
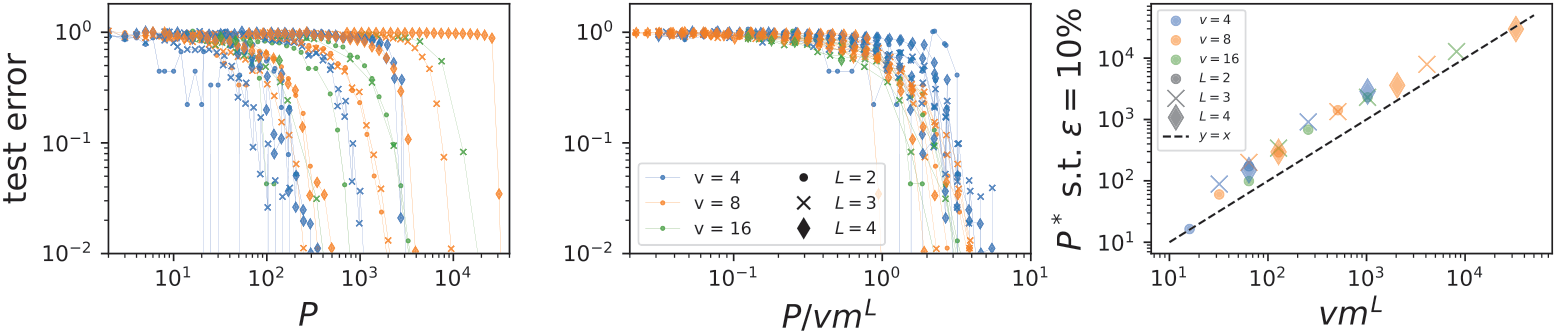
original
rescaled \(x-\)axis
Deep neural networks beat the curse
Training a deep convolutional neural networks with \(L\)
hidden layers on a training set of size \(P\).
- The sample complexity:
- Power law in the the input dimension \(d=s^L\), curse is beaten!!
original
rescaled \(x-\)axis
Can we understand DNNs success?
Are they learning the structure of the data?
Semantic Invariance indicates Performance
- Are the neural networks capturing the semantic invariance of the task to perform well?
- We can measure sensitivity to exchanges of semantically equivalent features in deep CNNs:
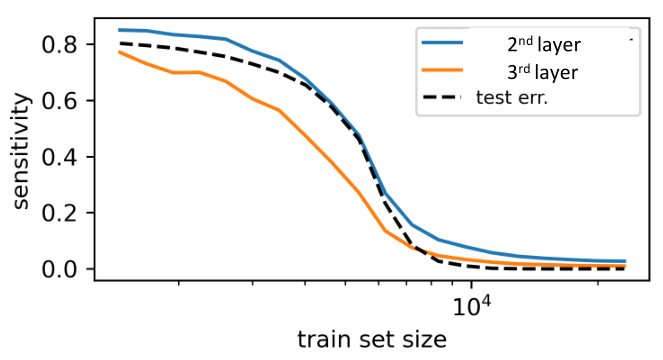
- Invariance and performance are strongly correlated!
- \(P^*\) is also the point at which invariance is learned.
How is semantic invariance learned?
Input-output correlations in the RHM
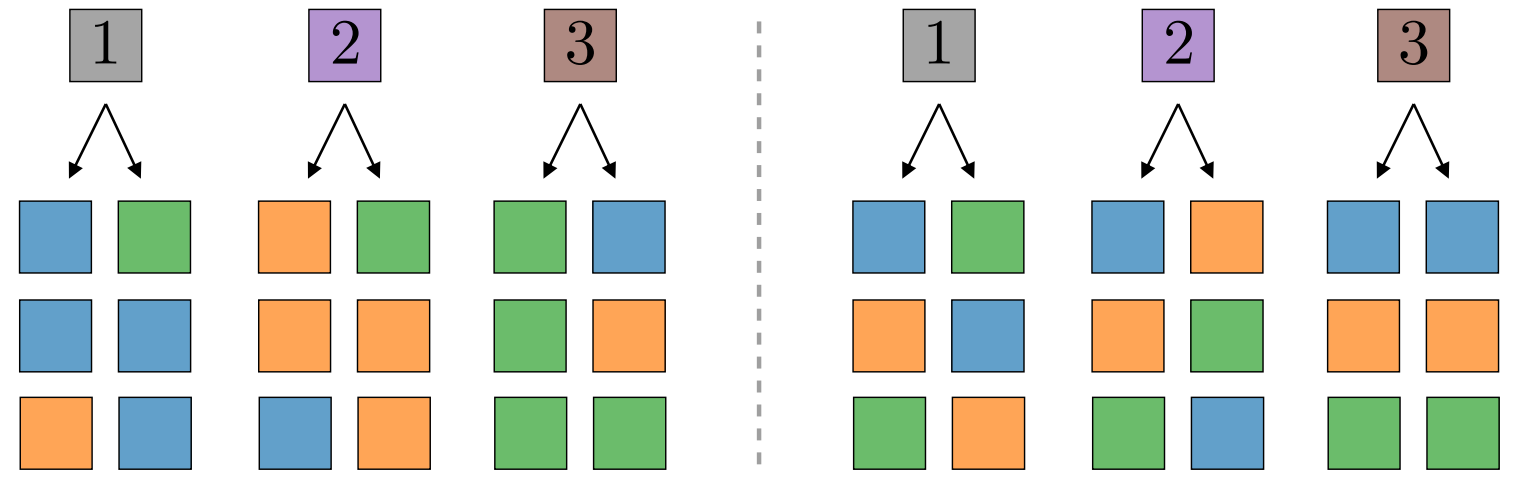
- Rules are chosen uniformly at random \(\rightarrow\) correlations exist between higher and lower-level features;
- For the rightmost input patch, (red; pink) and (orange; green) have the same correlation with the output;
- In general, correlations are the same for semantically equivalent tuples;
- Correlations can be exploited to learn semantic invariance!
- In RHM example: observing blue on the left \(\rightarrow\) class more likely to be "1";
- In real data: a wheel somewhere in the image makes the class more likely to be a vehicle.
\(P^*\) points are needed to measure correlations
- We can compute correlations (the signal) and show that 1-step layer-wise gradient descent learns invariant representation when training on all data;
- For a finite \(P\), correlations are estimated from empirical counterpart (sampling noise);
- Learning is possible starting from signal = noise, this gives:
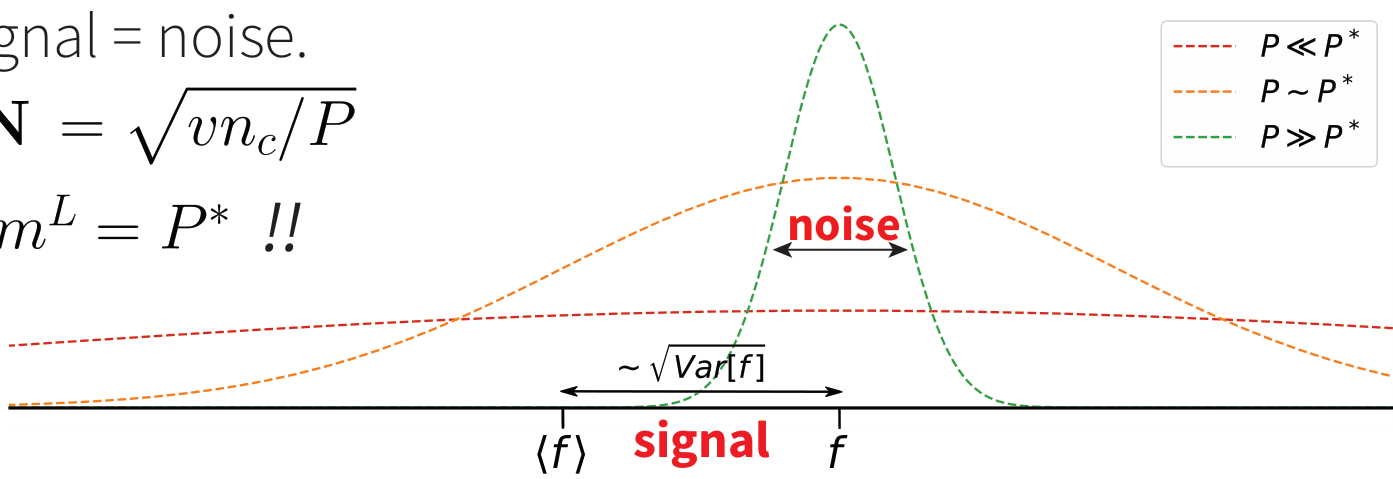
= sample complexity of DNNs!!
Input-label correlations predict sample complexity
At each level of the hierarchy, correlations exist between higher and lower level features.
Rules are chosen uniformly
at random:
correlated rule (likely)
uncorrelated rule (unlikely)
\(\alpha\) : class
\(\mu\) : low-lev. feature
\(j\) : input location
These correlations (signal) are given by the variance of $$f_j(\alpha | \mu ) := \mathbb{P}\{x\in\alpha| x_j = \mu\}.$$
For \(P < P_\text{max}\) , \(f\)'s are estimated from empirical counterpart (sampling noise).
Learning is possible starting from signal = noise.
We compute \(\mathbf{S}\sim \sqrt{v/m^L}\), \(\mathbf{N}\sim \sqrt{vn_c/P}\):
- Correlations are the same for semantically equivalent tuples
- They can be used to learn semantic invariance!
observe
Input-label correlations predict sample complexity
At each level of the hierarchy, correlations exist between higher and lower level features.
Rules are chosen uniformly
at random:
correlated rule (likely)
uncorrelated rule (unlikely)
\(\alpha\) : class
\(\mu\) : low-lev. feature
\(j\) : input location
These correlations (signal) are given by the variance of $$f_j(\alpha | \mu ) := \mathbb{P}\{x\in\alpha| x_j = \mu\}.$$
For \(P < P_\text{max}\) , \(f\)'s are estimated from empirical counterpart (sampling noise).
Learning is possible starting from signal = noise.
We compute \(\mathbf{S}\sim \sqrt{v/m^L}\), \(\mathbf{N}\sim \sqrt{vn_c/P}\):
What are correlations used for?
observe
From correlations to semantic invariance
- Input-output correlations are the same for sub-features with the same meaning:
- \(\rightarrow\) they can be exploited to learn semantic invariance!
- For layer-wise training, we can show that gradient descent can use correlations to learn invariant representations (skipping details).
- We can measure sensitivity to exchanges of semantically equivalent features in deep CNNs:
- Strong correlation between invariance and performance!
- \(P^*\) is also the point at which invariance is learned.
Input-label correlations predict sample complexity
At each level of the hierarchy, correlations exist between higher and lower level features.
Rules are chosen uniformly
at random:
correlated rule (likely)
uncorrelated rule (unlikely)
\(\alpha\) : class
\(\mu\) : low-lev. feature
\(j\) : input location
These correlations (signal) are given by the variance of $$f_j(\alpha | \mu ) := \mathbb{P}\{x\in\alpha| x_j = \mu\}.$$
For \(P < P_\text{max}\) , \(f\)'s are estimated from empirical counterpart (sampling noise).
Learning is possible starting from signal = noise.
We compute \(\mathbf{S}\sim \sqrt{v/m^L}\), \(\mathbf{N}\sim \sqrt{vn_c/P}\):
observe
To sum up
On hierarchical tasks:
- Simple (shallow) neural networks are cursed;
- Deep neural networks beat the curse;
- They do so by learning the semantic structure of the task;
- Semantic structure can be learned by exploiting in-out correlations;
- Correlations predict sample complexity.
Data invariances allow dimensionality reduction
Focus of Part I
Focus of Part II
Mossel '16, Poggio et al. '17, Malach and Shalev-Shwartz '18, '20 Petrini et al '23 (in preparation)
Bruna and Mallat '13, Ansuini et al. '19, Recenatesi et al. '19 Petrini et al. '21, Tomasini et al. '22
...
dog
face
paws
eyes
nose
mouth
ear
edges
text:
images:
- Dimensionality of the problem can be reduced by becoming invariant to aspects of the data irrelevant for the task:
-
Semantic invariance. Related to hierarchical structure of the task (higher-level features are a composition of lower-level features). Features can have different synonyms.
- Deformation invariance. The relevant features are sparse in space, their exact position does not matter.
-
Semantic invariance. Related to hierarchical structure of the task (higher-level features are a composition of lower-level features). Features can have different synonyms.
Data invariances allow dimensionality reduction
Focus of Part I
Focus of Part II
Mossel '16, Poggio et al. '17, Malach and Shalev-Shwartz '18, '20 Petrini et al '23 (in preparation)
Bruna and Mallat '13, Ansuini et al. '19, Recenatesi et al. '19 Petrini et al. '21, Tomasini et al. '22
...
dog
face
paws
eyes
nose
mouth
ear
edges
text:
images:
- Dimensionality of the problem can be reduced by becoming invariant to aspects of the data irrelevant for the task:
-
Semantic invariance. Related to hierarchical structure of the task (higher-level features are a composition of lower-level features). Features can have different synonyms.
- Deformation invariance. The relevant features are sparse in space, their exact position does not matter.
-
Semantic invariance. Related to hierarchical structure of the task (higher-level features are a composition of lower-level features). Features can have different synonyms.
Relative Stability to Diffeomorphisms indicates Performance in Deep Nets
Part II
Sparsity in space and stability to smooth deformations
Is it true or not?
Can we test it?
- We discussed DNNs learning features' meaning in a hierarchical manner;
- In real data, features are sparse in space:
exact features position is irrelevant;
-
Hypothesis: DNNs become invariant to exact feature position \(\rightarrow\) effectively reduce dimensionality of the problem
\(\rightarrow\) beat the curse of dimensionality.
Bruna and Mallat '13, Mallat '16
Plan:
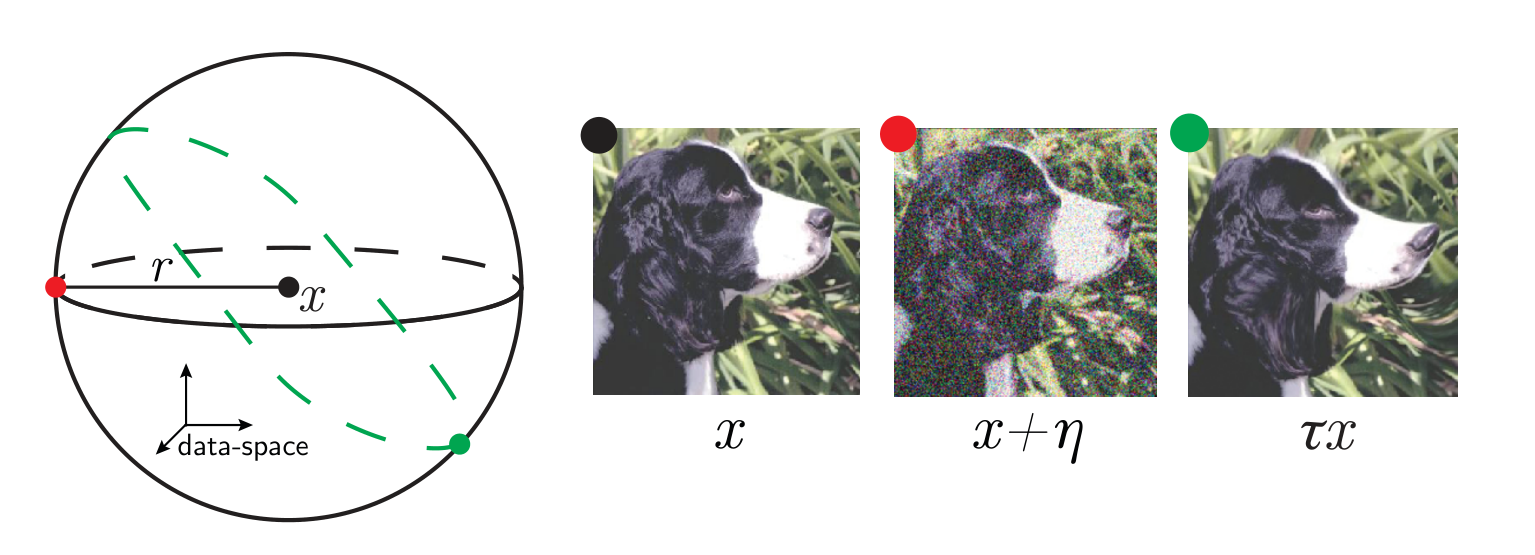
- Introduce a controlled way to deform images;
- Introduce a measure of deformation invariance of neural networks predictors;
- Test on real neural networks;
Max-entropy model of diffeomorphisms


-
Goal: deform images in a controlled way
- How to sample from a uniform distribution on all diffeomorphisms \( - \,\tau\, -\) that have the same norm \(\|\tau\|\)?
- Can be solved as a classical problem in physics where the norm takes the place of an energy, which can be controlled by introducing a temperature \(T\)

more deformed
Measuring deformation invariance


Invariance measure: relative stability
(normalized such that is =1 if no diffeo stability)
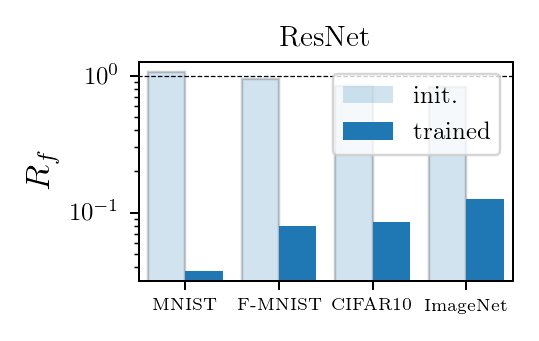
Good deep nets learn to become invariant
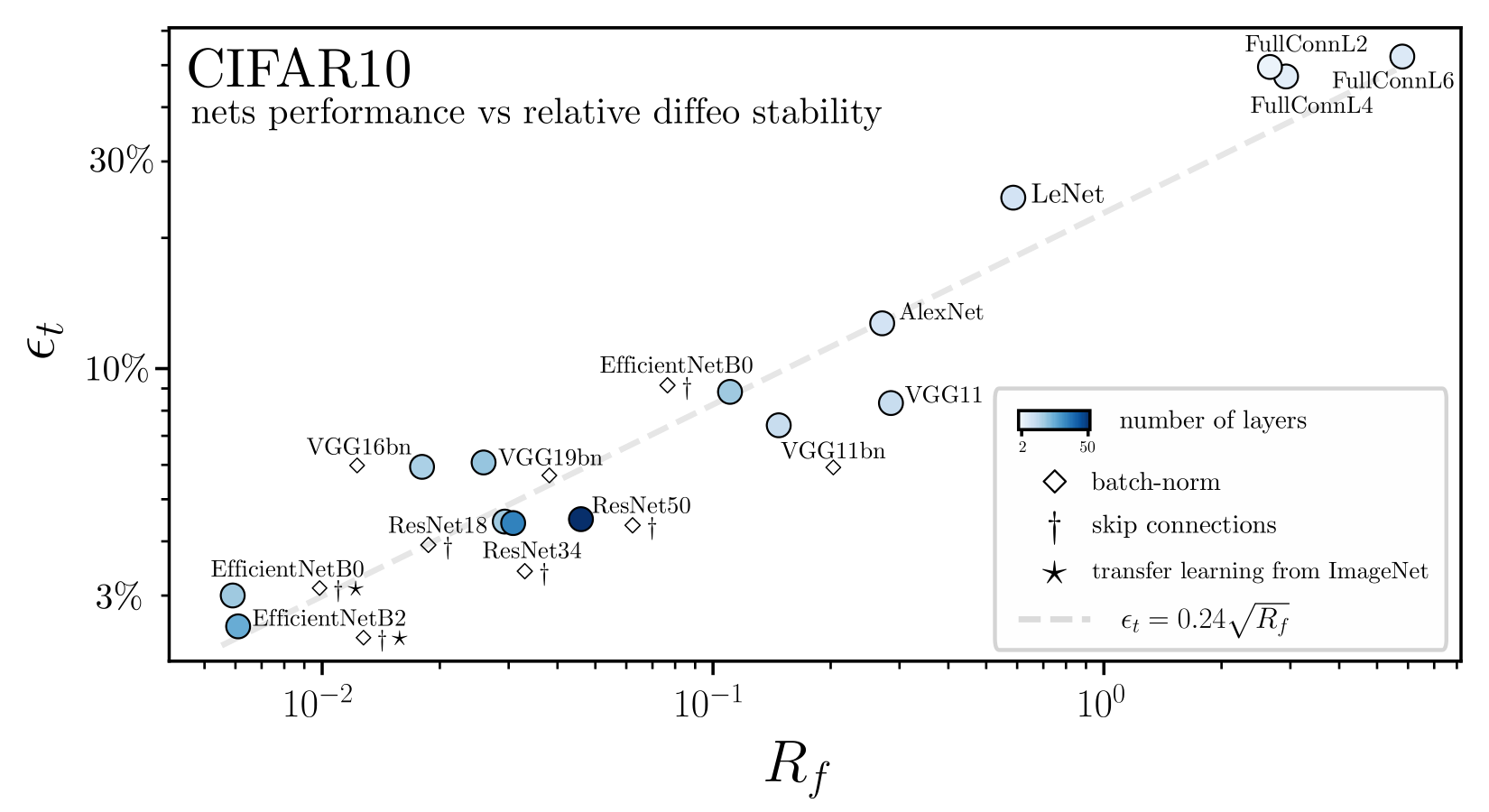
Results:
- At initialization (shaded bars) \(R_f \approx 1\), SOTA nets don't show stability to diffeo at initialization.
-
After training (full bars) \(R_f\) is reduced by one/two orders of magnitude consistently across datasets and SOTA architectures.
- By contrast, (2.) doesn't hold true for fully connected and simple CNNs for which \(R_f \sim 1\) before and after training.
Deep nets learn to become stable to diffeomosphisms!
Relationship with performance?
Relative stability to diffeomorphisms remarkably correlates with performance!




- Understanding deep learning performance boils down to understanding data invariances and how deep nets learn them;
- In the Random Hierarchy model, we understand relationship between emergence of invariant representation and performance;
- We predict sample complexity in terms of simple parameters: \(P^* \sim n_cm^L\). Gives rule of thumb to get sample complexity of real data;
-
Many future directions: e.g. use the model to study language capabilities of transformer architectures.
- For images, deformation stability seems necessary for performance;
- By which mechanisms is this stability achieved in deep nets?
- Combine the two invariances by adding a notion of space in RHM?
Conclusions and Perspectives
see Tomasini et al. '22
Thank you!
Pt. 1
Pt. 2
References
- E Mossel, Deep learning and hierarchal generative models (2016).
- T Poggio, H Mhaskar, L Rosasco, B Miranda, Q Liao, Why and when can deep-but not shallow-networks avoid the curse of dimensionality: a review. Int. J. Autom. Comput. 14, 503–519 (2017).
- E Malach, S Shalev-Shwartz, A provably correct algorithm for deep learning that actually works. arXiv preprint arXiv:1803.09522 (2018).
- E Malach, S Shalev-Shwartz, The implications of local correlation on learning some deep functions. Adv. Neural Inf. Process. Syst. 33, 1322–1332 (2020).
- QV Le, Building high-level features using large scale unsupervised learning in 2013 IEEE international conference on acoustics, speech and signal processing. (IEEE), pp. 8595–8598 (2013).
- J Bruna, S Mallat, Invariant scattering convolution networks. IEEE transactions on pattern analysis machine intelligence 35, 1872–1886 (2013).
- A Ansuini, A Laio, JH Macke, D Zoccolan, Intrinsic dimension of data representations in deep neural networks in Advances in Neural Information Processing Systems. pp. 6111–6122 (2019).
- S Recanatesi, et al., Dimensionality compression and expansion in deep neural networks. arXiv preprint arXiv:1906.00443 (2019).
- L Petrini, A Favero, M Geiger, M Wyart, Relative stability toward diffeomorphisms indicates performance in deep nets in Advances in Neural Information Processing Systems. (Curran Associates, Inc.), Vol. 34, pp. 8727–8739 (2021).
- UM Tomasini, L Petrini, F Cagnetta, M Wyart, How deep convolutional neural networks lose spatial information with training in Physics for Machine Learning at ICLR (2023).
- L Petrini, F Cagnetta, UM Tomasini, A Favero, M Wyart, A Quantitative Analysis of Sample Complexity in Deep Convolutional Neural Networks: The Random Hierarchy Model (2023), in preparation.